
我们在搭建hadoop中都会出现一些小小的问题,在伪分布式安装完Hadoop后,jps查看进程的时候缺三少两,今天解决的问题是6个进程中缺少了DataNode。
开启进程后,jps查询:
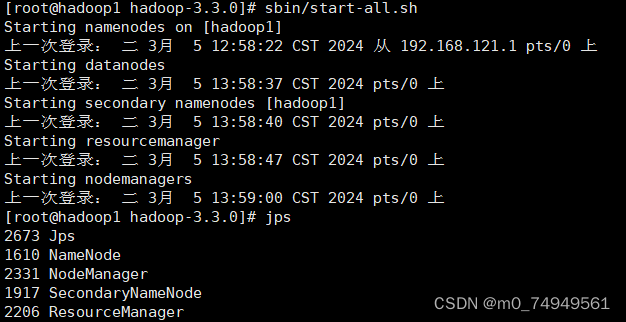
缺少DataNode的原因通常是:
这个一般是因为namenode进行了多次的格式化bin/hdfs namenode -format,导致namenode的clusterID和datanode的clusterID不同。然而dfs/data中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID 。这样,datanode和namenode之间的ID不一致。所以datanode进程“消失了”。
解决方法:
- **先关闭进程 **sbin/stop-all.sh
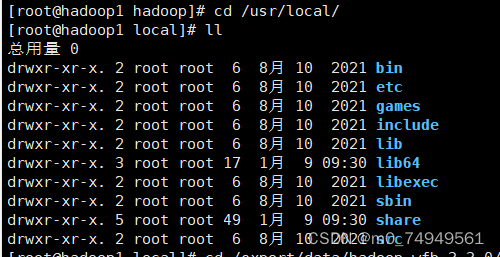
- 在hadoop安装目录下打开本地文件local
- 在hadoop目录下查看vi core-site.xml配置文件记住/export/data/Hadoop-wfb-3.3.0****这条路径(datanode和namenode的官方默认位置)


- 将/export/data/Hadoop-wfb-3.3.0在local目录下打开并查看,是否有dfs,并打开dfs.

- 打开dfs目录并在其目录查询name和data目录。
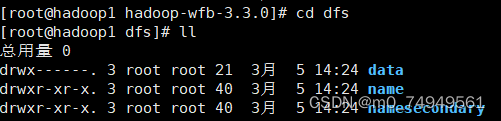
注意:****不管先打开目录data还是name都可以,要确保data/current/VERSION中的clusterID与name/current/VERSION中的clusterID相等即可。
(在这里我以先打开name目录开始演示)
- 接上命令操作,在dfs目录下首先打开name,然后在name目录中打开current目录。我们会在current中看见VERSION。(以下是我的操作)

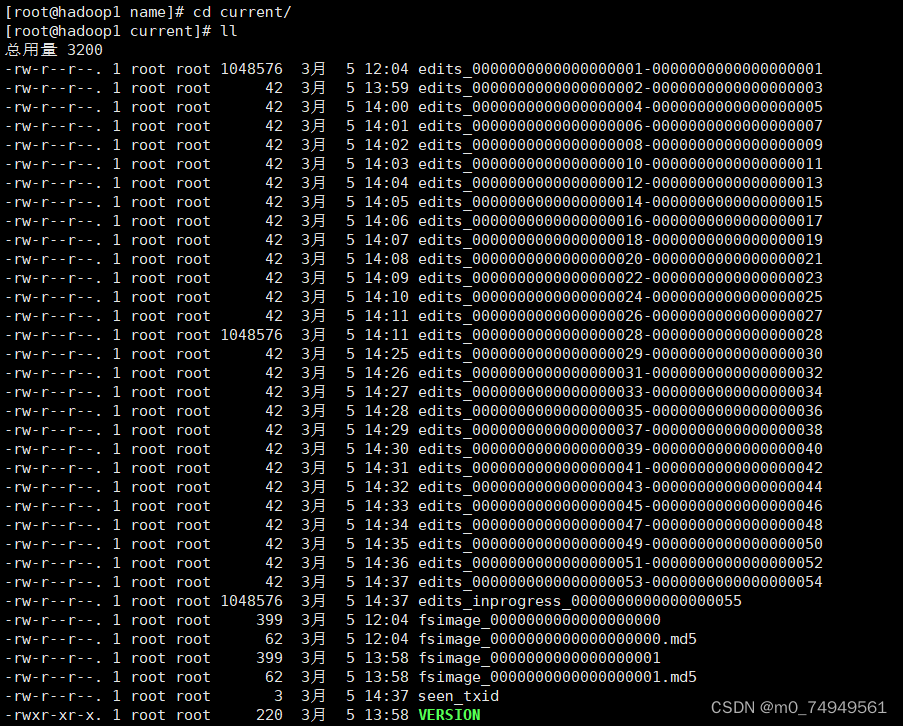
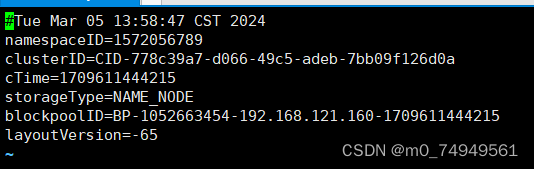
- 输入命令vi VERSION打开VERSION文件,复制VERSION文件中的clusterID。
** **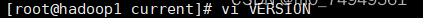
** **
- 复制完成之后点击esc,shift+:wq退出该文件,再次回到dfs目录。并在dfs目录下打开data,然后在data目录中打开current目录。在current中打开VERSION文件。
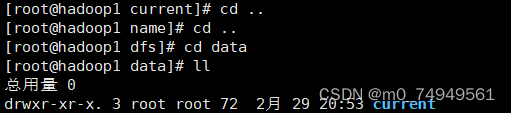

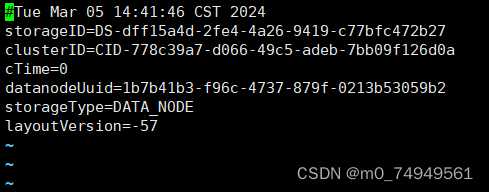
*9.将从name中VERSION文件中复制的clusterID,粘贴到data中VERSION文件中clusterID。要确保data/current/VERSION中的clusterID与name/current/VERSION中clusterID的值相等。*
*10. 粘贴完成之后点击esc,shift+:wq退出该文件。输入命令:cd /export/servers/wfb-hadoop/hadoop-3.3.0并切换到hadoop-3.3.0目录*

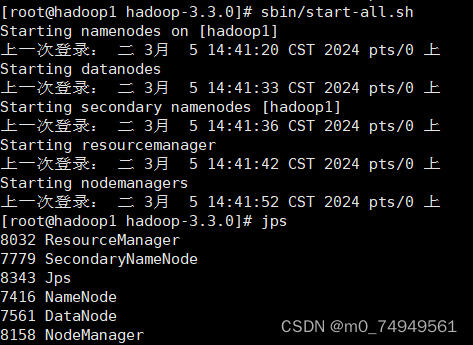
**11.**输入sbin/start-all.sh开启进程查看jps,可以看到DataNode进程已经出现。
本文转载自: https://blog.csdn.net/m0_74949561/article/details/136493003
版权归原作者 Asuncion007 所有, 如有侵权,请联系我们删除。
版权归原作者 Asuncion007 所有, 如有侵权,请联系我们删除。