
引言:
今天是个好日子,日更动态养成习惯,日更博客你我他,北京时间 2023/1/29/10:09,今天阳光明媚,但是还是很冷,起床时间8:55,可以看出又早了那么一点点,今天为什么能起的更早了呢?原因就是,我听了一首五月天的歌,导致我激情澎湃,如下视屏,我给大家分享一下这首起床必备神曲,说实话,真好听,当然好听的歌就跟有趣的灵魂一样是千千万万的,就看你自己喜欢什么风格的,当然身为Jay的00后头号粉丝,Jay的地位是不可撼动的,但是在00年代,好听的歌真的是数不胜数,如果没怎么接触过00年代的歌的同学,可以去了解一下,你会发现你发现了一个音乐宝藏,接下来我的博客更新中,也会为大家分享一些我最近发现的好听的音乐,大家一起共享啊!
正式学习进程
上篇博客我们仔仔细细的讲解了一下进程的先导知识,了解了什么是操作系统,什么是冯诺依曼体系,还了解了很多的有关硬件的知识,所以现在让我们带着这些知识来正式的学习一下什么是进程吧!
1.复习操作系统
此我们把操作系统再理解一下,操作系统就是上层(用户)和下层(硬件)链接的桥梁,对下通过各种的驱动程序的控制与各种硬件取得联系,对上通过系统调用的方式对各种软件进行管理,从而提供用户所需的各种需求。
看到上述这段话,有的同学可能有所疑问,到底什么是驱动程序,什么是系统调用呢?
简述驱动程序和系统调用
1.1.驱动程序:首先驱动程序是包含在我们的操作系统中的,它的本质就是各种硬件的接口,不同的驱动程序可能其程序中包含的相应的硬件的属性是不一样的,所以不同的驱动程序也就发挥着不同的作用,所以驱动程序就相当是操作系统和硬件之间的桥梁。
如果有对驱动程序更加感兴趣的同学,可以参考下述链接:带你分分钟搞定驱动程序和操作系统之间的关系
1.2.系统调用:首先系统调用本质上是:操作系统将自己的一些接口暴露给用户,用户通过使用相应的接口来完成相应的需求。此处还会涉及到最初的二次开发封装成库的概念,什么是库,例如我们的语言库,就是通过对操作系统的某些接口进行封装进而形成的,所以我们使用各种语言(Java还是C++),本质上都只是在调用系统接口而已,俗称系统调用。并且我们封装成库的原因也就是跟生成相应的语言库一样,目的是为了让我们的编程变的更加的简单,通过库使用系统接口,高效。
总:便与开发
2.操作系统和进程的关系
操作系统和进程的关系是什么,我觉得我们应该可以直接想到管理和被管理的关系,当我们知道了操作系统和进程的大致关系之后,可以想到,那么在我们常用的操作系统(Windows)中,进程在哪里呢?如下图,我们先简单的看看进程到底长什么样子,是人还是鬼!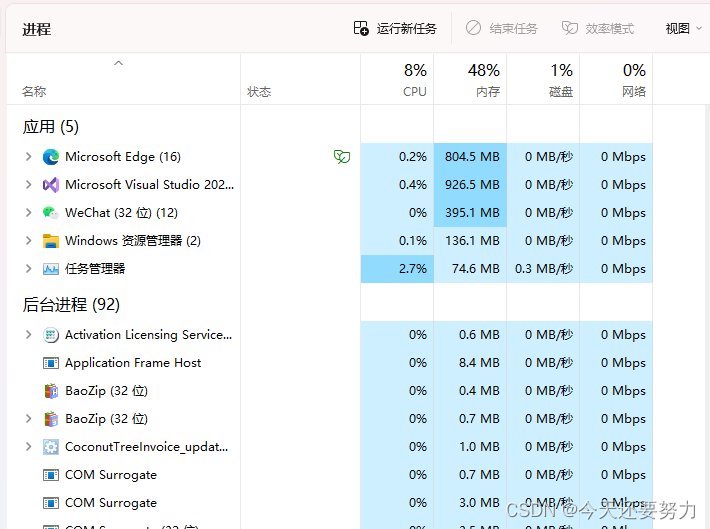
此时我们可以在左上角看到两个大大的字“进程”,可以看出,此时你的电脑后台中是有很多的各种各样的进程在运行的,也就可以理解成是你的操作系统中此时有着很多的进程在运行,综合管理和被管理的关系,此时我们可以得出,我们的进程是被我们的操作系统通过某些特殊的手段给管理着的,并且这个管理是有序的,正常的,安全的,高效的。
3.操作系统如何管理进程
为什么操作系统可以有序的,正常的,安全的,高效的管理进程呢?
此时对上句话提取关键词,不会错,就是那个连钟xx都能找到的管理二字。我们从管理入手,从而找到此问题的答案。什么是管理?我相信上篇博客可以给我们的答案,管理的本质就是:先描述,再组织,只要我们弄清楚了什么是管理,那么我们就搞清楚了上述问题,我们也就初步的了解了进程在操作系统中的一系列具体情况。简而言之,也就弄清楚了操作系统是如何管理进程。所以下述我们通过一个建模过程带大家搞定此问题。
文字建模:首先我相信大家都知道磁盘的概念和可执行文件(后缀 .obj)的概念,此时我们电脑中有一个可执行文件存储在磁盘中,当我们双击运行此文件时,我们的操作系统识别到此操作,于是通过文件系统驱动找到此文件,然后把此文件就给加载到了内存之中,此时我们的可执行文件也就加载到了内存之中。这里有的同学可能会有这样的理解(我的一个可执行文件被加载到了内存中之后就形成了一个进程了吗?)这个想法显然是不完全正确的(CPU说,我都还没上场,你们就结束啦!),所以只有当我们内存中的可执行文件被CPU调用,然后进过CPU的计算和控制之后,返回到内存并最终被我们的操作系统重新从内存中识别,然后运行到我们电脑的其它硬件或软件之上,此时我们才可以说我们形成了一个进程,此时也就可以在我们的显示屏上的任务资源管理器上看到该进程了。但此时有的小伙伴就有疑问了,说,我在从磁盘到内存的过程中,我的文件系统驱动器可以从磁盘中拿到指定的文件是因为我已经把该文件给包装好了并且自己找到点击了该文件,那当CPU从内存中获取该文件的时候,为什么不需要经过我的操作也可以准确、完整、快速的拿到该文件呢?并且当我在内存中存放了很多不同的可执行文件时,我的CPU是怎么区分这些数据,从而执行我想要执行的程序呢?
认识pcb
解决上述两个疑问,我们只需要引入pcb的概念就可以解决,pcb也叫task_struct,顾名思义,就是一个结构体,一个任务结构体,该结构体用来干嘛的呢?我相信我们在鹏哥C语言的时候,我们刚学习结构体的时候,我们都学习过 struct people 这样的结构体,当时这样的结构体是用来存储我们人的信息的结构体(例如:钟xx的姓名,身高,年龄,家庭地址等!)所以我们的task_struct的作用就是用来存储和文件的相关的属性和内容的(并且此处强调,文件 = 内容 + 属性),这样我把我的每一个我想要执行的文件通过操作系统加载到内存之后,有强迫症并且能干的内存就把这些文件一个一个的放到了相应的task_struct中,加载一个文件,内存就生成一个task_struct,这样就可以把加载到内存中的数据按照和我们磁盘中的数据一样,按照一个一个文件夹的样子对文件的属性和内容就行整理了,并且我们的内存还要对这些task_struct进行管理(并且此处强调,管理 = 先描述,再组织),因为我们已经用task_struct对文件的内容和属性描述好了,所以此时就只需要进行组织,我们的内存就完成了管理各种各样的文件的任务了,此时内存只要在每一个task_struct结构体中增加一个指针(也就是以单链表的形式),将这一个一个的task_struct结构体链接在一起,我们的内存就完成了管理工作,此时无论CPU想要获取那个数据,获取那个优先级高的数据,都可以说是很简单的就可以快速,完整的从内存中获取。当然这个获取的过程还是由我们的操作系统来完成的。
如果有同学不理解为什么CPU从内存获取数据需要经过操作系统,可以参考以下链接:
深入理解操作系统对硬件的管理
上述我们就完成了进程管理的文字建模过程,为了防止不好理解,我们来一幅图,帮助我们更好的理解进程管理的建模过程。
图形化建模: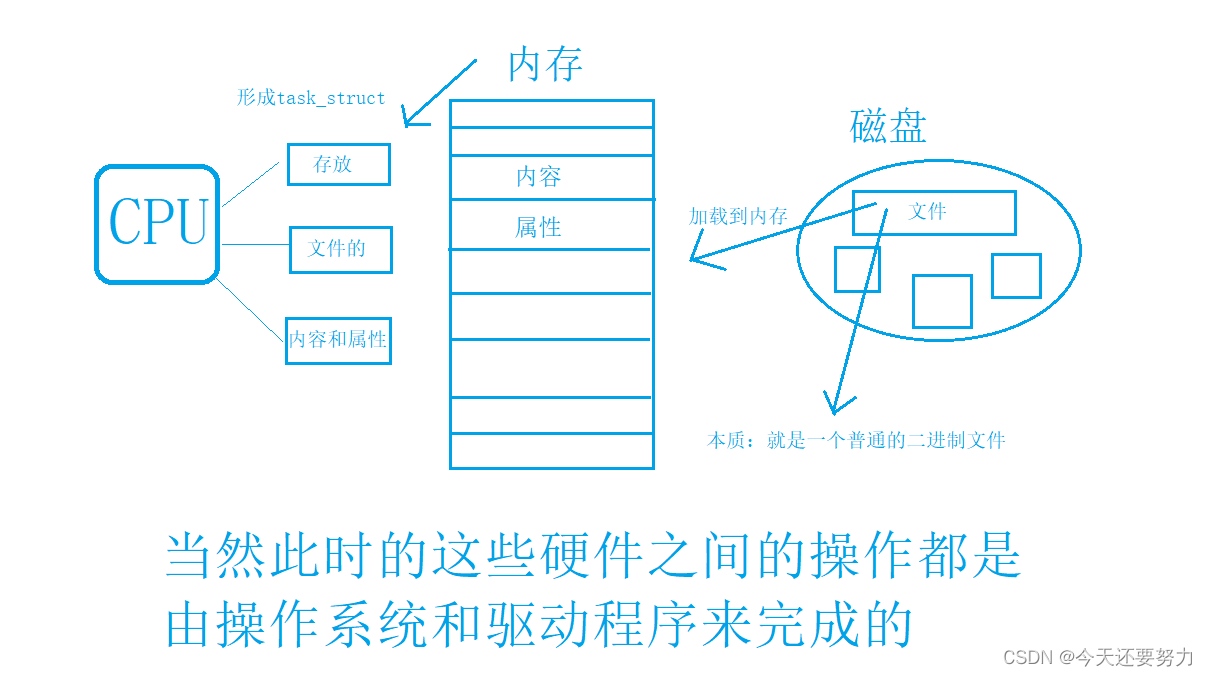
结合文字描述和图形结合,我们就可以更好的理解进程了,所以我们明白一个道理,就是在计算机中我们对进程的管理本质上还是我们在数据结构中学的有关的对链表的增删查改。
总:进程就是内核关于进程的相关数据结构和当前进程的代码和数据。
当然我相信很多同学对什么是进程的相关数据结构肯定是有一定的疑问的,其实进程相关的数据结构也就是我们上述讲到的pcb,所以我们这边对pcb进行一定的解释。
pcb就是一个用来方便我们管理进程的存储相关数据的属性的结构体
pcb/task_struct中的内容分类
标识符:描述本进程的唯一标识符,用来区别其它进程(学号)状态:任务状态,退出信号等。优先级:相对于其它进程的优先级程序计数器:程序中即将被执行的下一条指令的地址内存指针:包括程序代码和进程相关数据的指针,还有和其它进程共享的内存块的指针上下文数据:进程执行时处理器的寄存器中的数据I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。其它信息。总:在pcb中只有相应的属性,并没有具体的内容,我们是依靠属性去寻找我们具体的内容
了解了pcb的相关内容之后,我们紧接着去了Linux上真正的认识一下进程是什么。
在Linux中看进程
如何在Linux中看进程呢?
首先第一步,我们要生成一个可执行文件
例:下图中的myprocess文件就是一个可执行文件
有了这个可执行文件,我们只需要将它运行起来就行了
指令:./ myprocess 此时的 ./ 就是表示将myprocess这个可执行文件加载到我们的内存当中。加载到了内存当中,进过操作系统的一些列处理,我们就可以在我们相应的地方看到我们的进程了。
比如:在Windows中看进程我们需要打开的是任务资源管理器,然后才可以看见我们当前执行的进程
而:在我们的Linux中,我们看进程只需要用到ps指令就可以了,并且此时Windows中存放进程的地方叫任务资源管理器,而我们的Linux中存放进程的地方就是我们根目录下的proc目录(进程目录),如下图:
所以只要当我们的myprocess文件加载到了内存之后,我们输入指令: ps ajx我们就可以看到当前在根目录下的proc目录中的一切进程了,如图:
当然这也就是相当于是Windows中的任务资源管理器中的如下图片:
当然我们发现当前电脑中的进程是有非常多的,所以我们也可以选择不查看所有的进程,而是只看我们想看的进程。指令:ps axj | grep myprocess 表达的意思就是,把我的所有进程给存到管道文件中,然后我再从管道文件中筛选出我想看的文件的进程,如下图所示:
这样我就可以看到我们当前myprocess文件的进程了。
当然也可以这样操作,输入指令:ps axj | head -1 然后再打开特点的指令,这样我就可以看见第一行的属性和我们进程相关的信息了
完整指令:ps axj | head -1 && ps axj | grep myprocess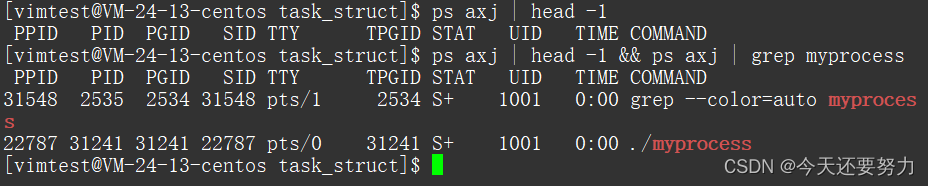
当然你也可以把myprocess进程之上的那个grep进程给去掉,去掉方法如图:因为grep也是进程,所以会一起显示出来,去掉指令:ps axj | grep myprocess | grep -v grep
并且当我们开启了两个myprocess文件进程时,进程时怎样的呢?现在让我们一起去看一看。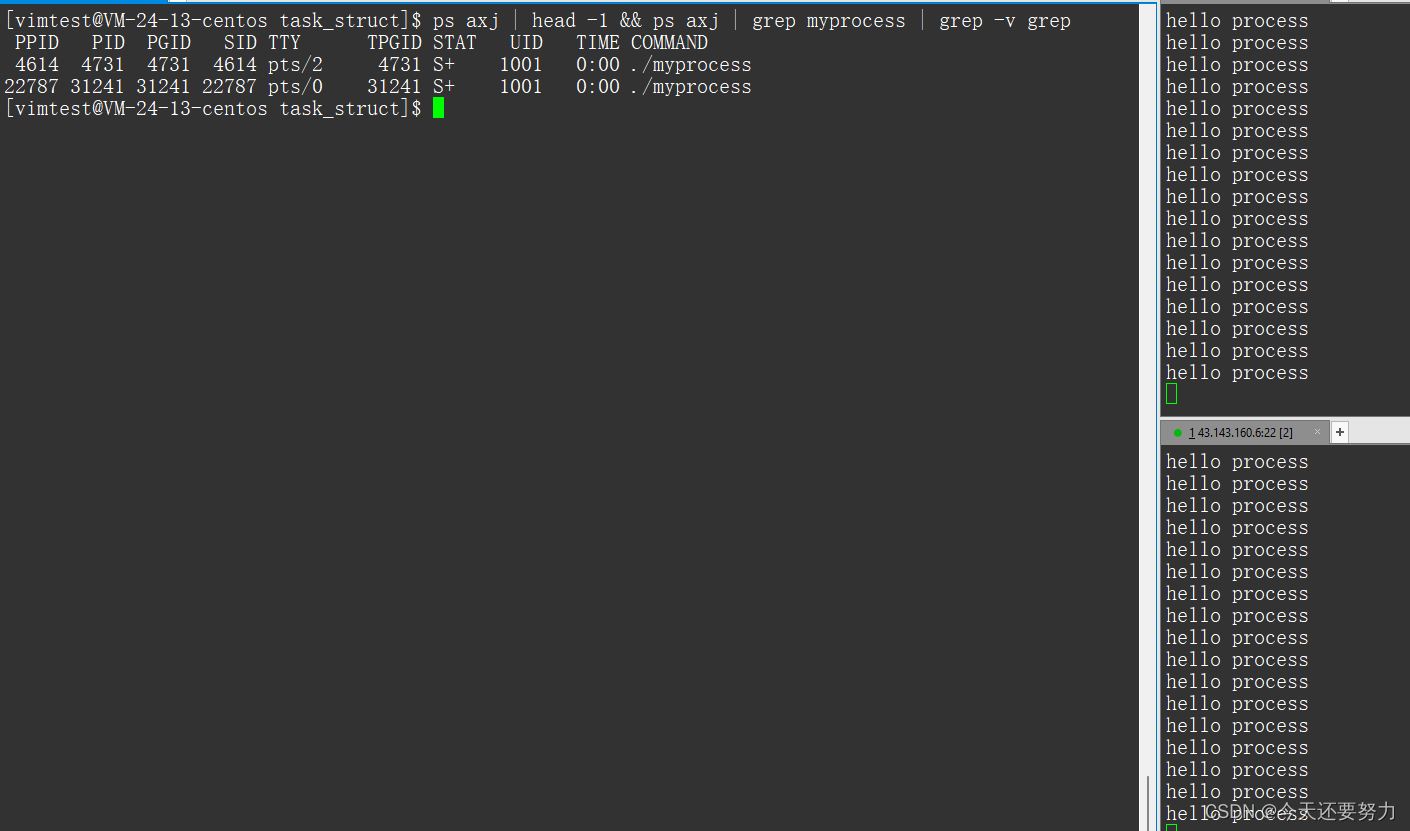
此时我们就看到了两个myprocess文件生成的对应的进程了。
并且此时我们从进程的属性内容中的PID来看,此时的两个进程并不是同一个进程,所以此时这边可以得出一个结论,就是每一个二进制文件加载到内存之后,都会有不同的PCB来管理这个进程。当然PID代表的就是进程的编号。
所以当我们此时知道了我们这两个进程的编号的时候,我们就可以前往我们根目录之下的,proc目录下,查看是否有此编号的进程了。
如图: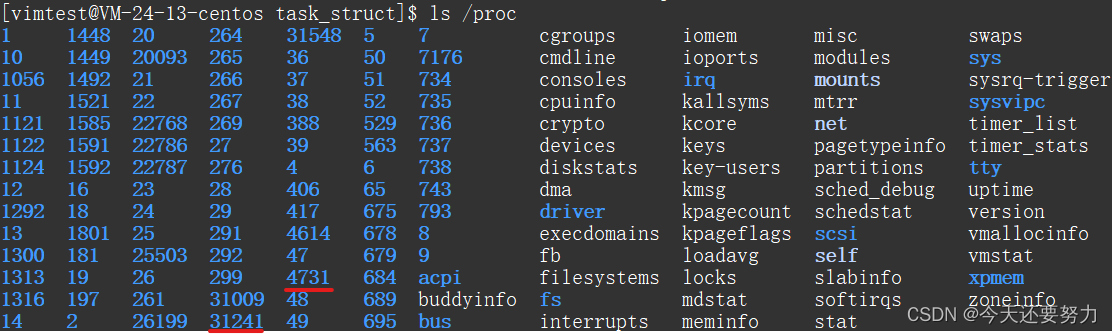
很明显此时我们就看到了我们的myprocess文件的两个进程的PID了(4731/31241)。
此时在proc目录中看见了我们的进程,我们此时就可以尝试进入该进程中看一看,这个进程中都有什么内容。如图:
其实这幅图中的内容也就是我们的PCB/task_struct结构体中存储的内容,我们的内存就是通过这个形式来管理我们的进程的。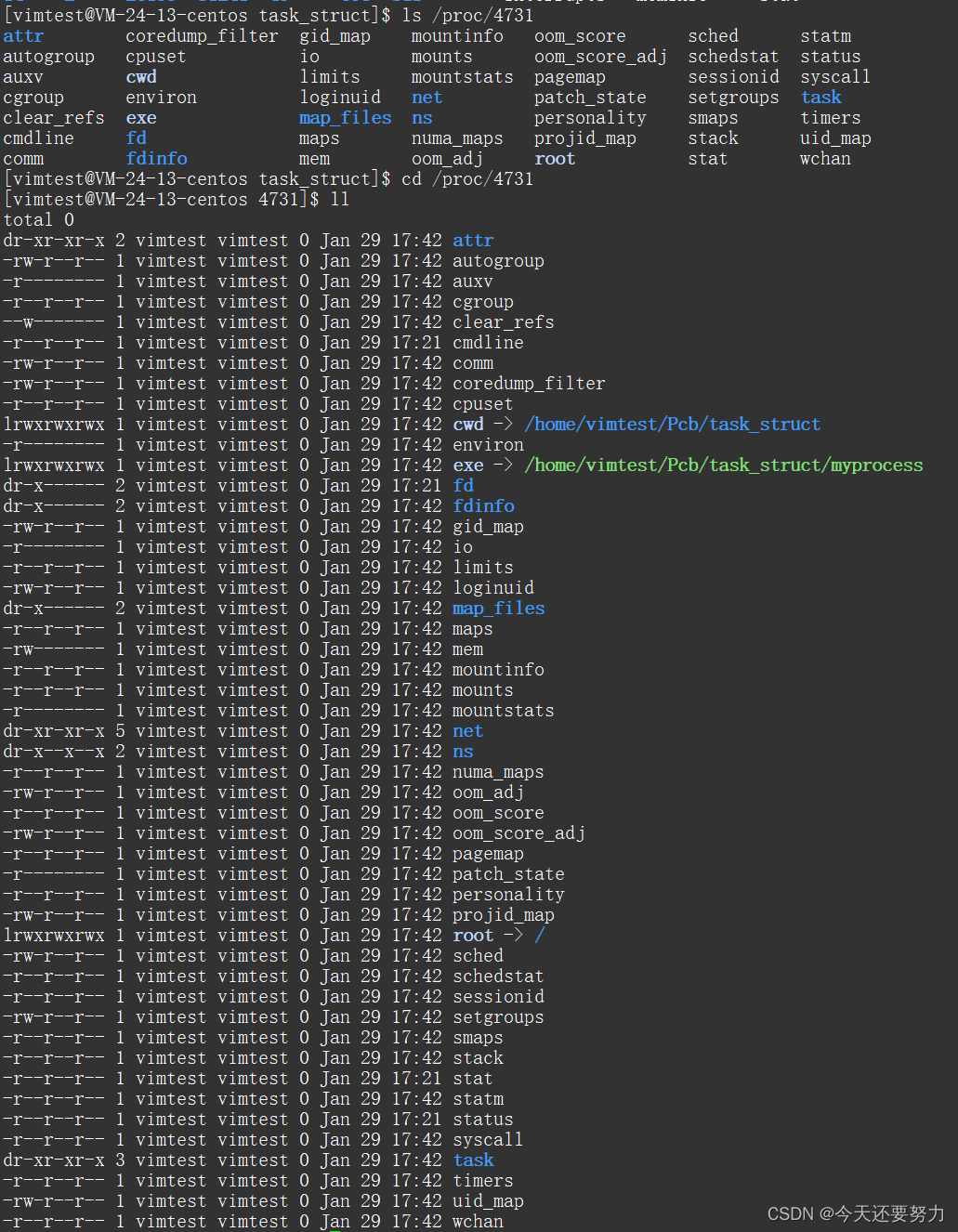
虽然我们对大部分的内容都不认识,但是总归就是PCB中的相关的属性,并且此时我们发现我们还是可以看出exe和cwd属性,这两个属性就是我们的文件目录。
从pid入手父子进程概念

此时我们运用一个系统调用的接口,**#include<sus/types.h>,使用这个接口我们来使用我们的函数getpid(),这样我们就可以直接获得该代码文件变成进程之后的pid了。
运行如图: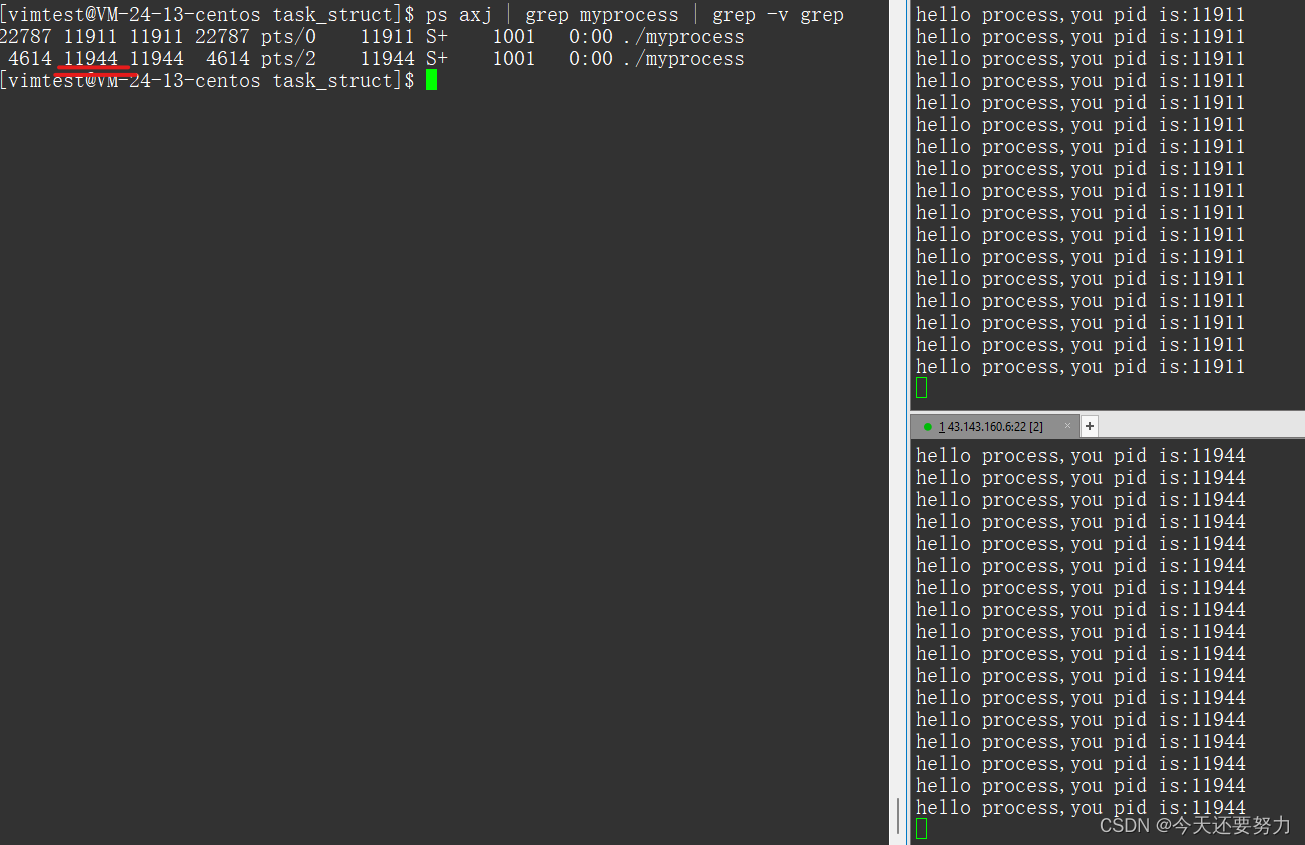
此时我们从图中基于上述得出的结论,我们可以得出我们的代码运行起来的进程和代码文件运行起来的进程是同一个进程。并且发现,同一文件运行多次,得到的进程并不相同**。
深入父子进程(bash)
我们按照上述原理,通过getppid()的方式来获得此进程的一个父进程,并且此时通过对进程的执行和停止,我们可以发现,不管我们进程本身的pid怎么变,但是该进程的父进程是不会变的。
如图: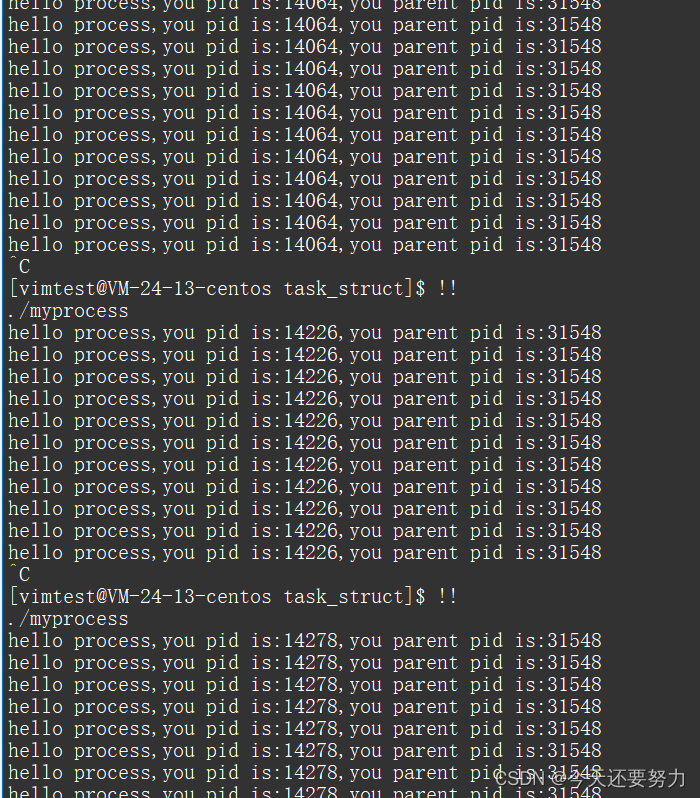
所以此时我们很好奇我们的父进程为什么不会改变呢?我们通过指令,搜索一下pid为31548的进程到底是什么,如图:
此时我们可以发现,pid为31548的时候一个叫bash的东西,相信大家都知道shell外壳的概念,shell外壳就是我们和Linux操作系统沟通的桥梁,然而bash就是我们CentOS系统中的shell外壳,所以我们的命令行就是我们的bash,我们把我们的指令传送给bash,bash再传给Linux内核,这就是我们使用Linux操作系统的原理,所以我们的任何进程的父进程都是我们的bash。但是此时好奇的同学就会问了,为什么所有进程的父进程都是bash呢?
因为此时我们想要使用Linux内核,就必须依靠bash,但是bash怕我们的程序或者指令是有问题的,一但有问题,容易传送错误的信息给Linux内核,容易导致系统崩溃,所以我们的bash每次在执行指令的时候,都会创建一个子进程去执行这个指令,通过这个子进程来保证不会出错,从而使我们的Linux操作系统变的更加的安全,稳定了。这也就是为什么所有进程的父进程都是bash的原因。所以还可以说,除了bash进程,别的进程都是子进程。特殊除外。
总:bash就是我们的命令行解释器,本质上也是一个进程,并且是所有进程的父进程。
自我创建子进程
从上述的知识中,我们可以发现,我们只要把可执行文件写入内存形成进程之后,这个进程就是一个子进程了,然后有的同学就会问,那这个进程有什么用呢?我们并不能控制这个进程啊。但是其实上我们是可以控制子进程的,例如:我们可以通过系统调用fork函数来自我创建一个子进程。
我们通过相应的代码来实现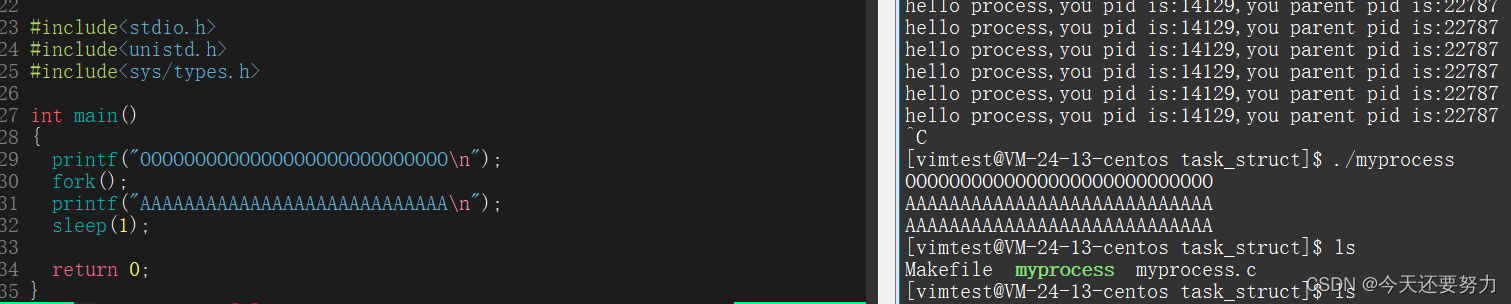
从上图我们可以看出因为有了fork函数的调用,我们此时打印的时候多打印了一行A字符,从这个现象,此时我们可以进行一个简单的猜想,就是我的程序在执行完打印O之后,此时的myprocess文件形成的进程,它因为fork函数的原因,又生成了一个子进程,此时就有了两个子进程在执行该代码,所以导致A被打印了两次。所以我们为了证明如上的猜想,我们引入pid的概念来进一步的了解,如图: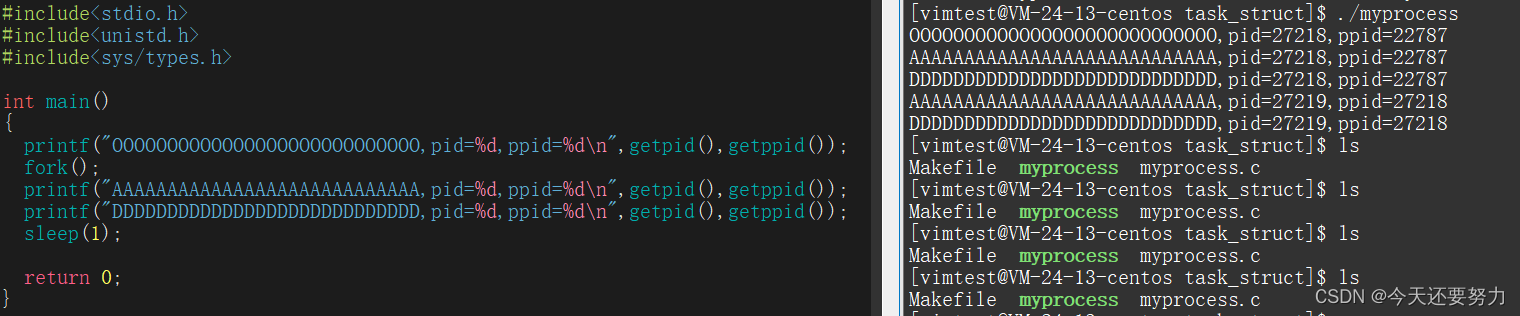
此时从我们右图的输出内容我们可以发现,我们的pid之前的关系,我们自身创建的进程,成为了此文件进程的子进程,也就是bash的孙进程的意思。
总:不仅只有bash可以创建子进程,我们自己也可以创建子进程。
fork函数的深度理解和认识虚拟地址

通过这幅图,我们可以理解到,我们不仅看到了两条打印,我们还看到了两个返回值,一个是0,一个是pid,并且我们还看到了两个一模一样的地址。
所以此时我么就有了两个问题,为什么会有两个返回值?为什么有两个地址,并且这地址是同一块地址?
所以我们可以猜想问题一,因为有两个进程,所以有两个返回值,并且因为一个有实际pid,一个没有实际pid。猜想问题二,就是两个数据公用同一块内存。
所以问题的答案到底是什么呢?
我们先来解决第一个问题,如下代码: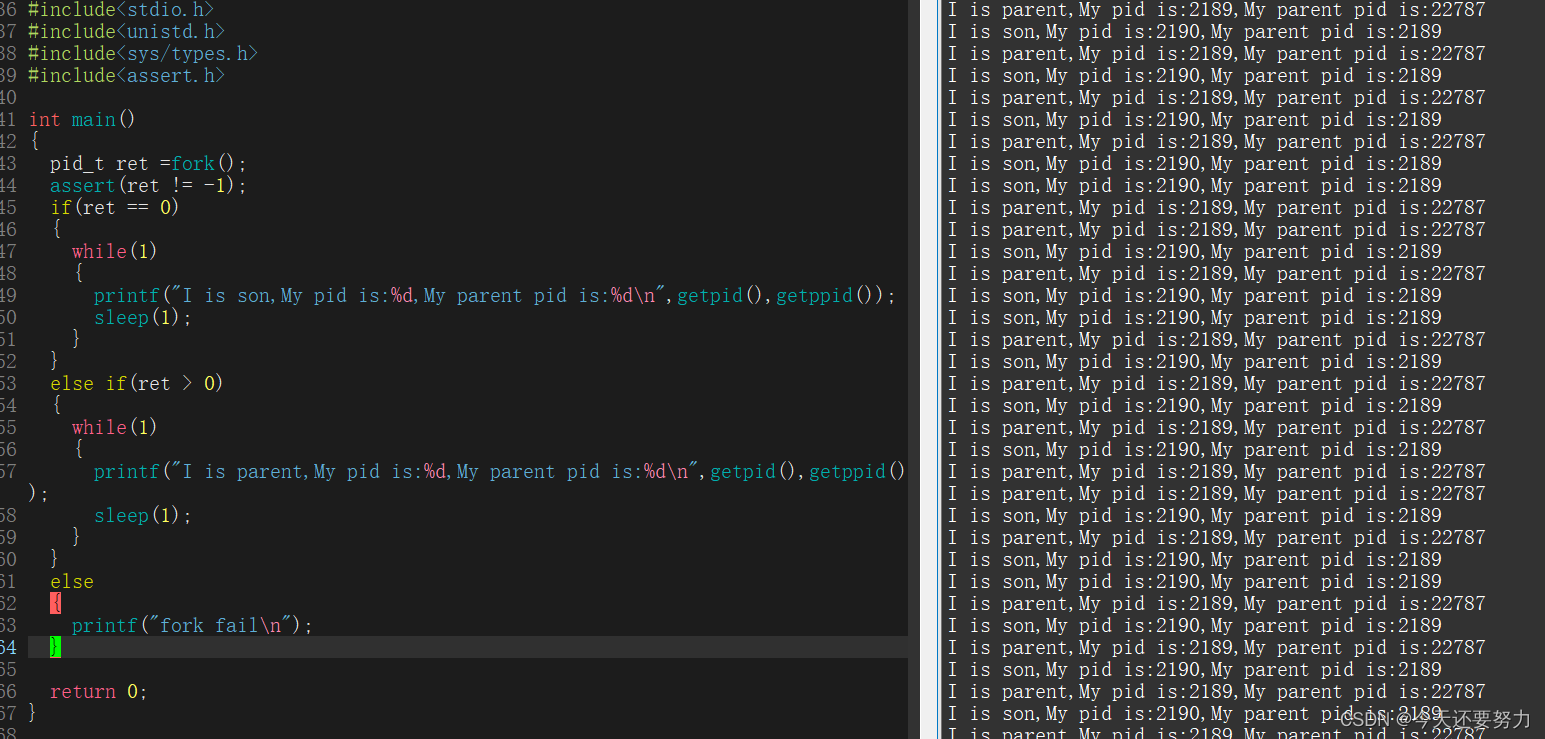
根据图片,从我们的代码和我们的打印,发现,我们的if语句和我们的else if语句是可以同时执行的,并且我们的两个while语句也是可以同时执行的,这是为什么呢?
原因还是因为,我们此时有两个进程,所以我们有两个执行流,有两个执行流,我们就可以执行两个相背的理论了,所以我们的猜想一是正确的,有两个执行流就会有两个返回值。
所以这里我们通过上述现象,我们可以总结一下fork函数:
fork之后,执行流会变成两个执行流fork之后,谁先执行由调度器决定****fork之后,代码是共享的,通常我们就是通过if和else if来进行执行流的分流
解决第一个问题之后,第二个问题就涉及到了我们的虚拟地址的理解,此时这个虚拟地址我们目前认识一下有这个东西存在就行,详细的我们以后在学。
父进程如何创建子进程
如图: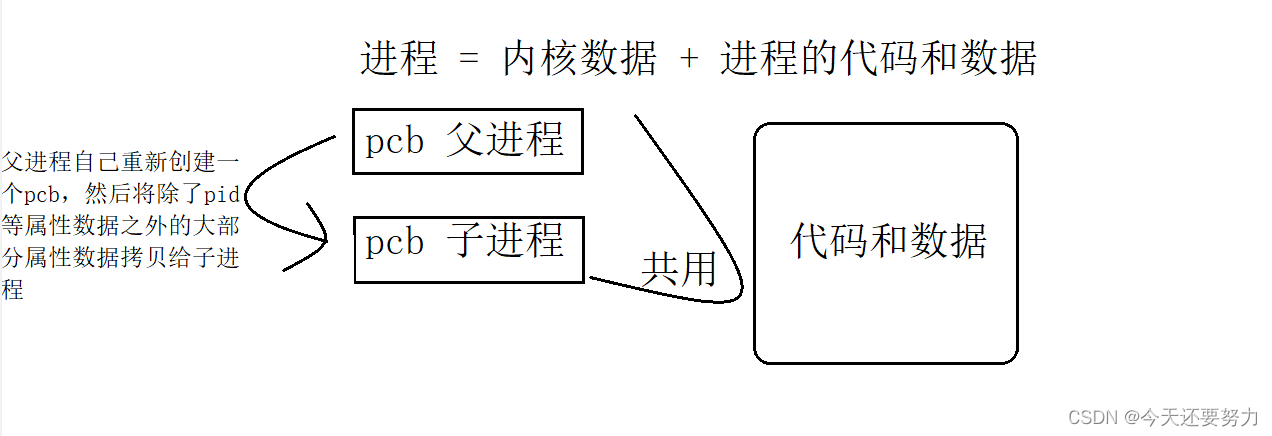
并且我们根据自己的使用电脑的常识,我们可以知道我们的进程是具有独立性的。并且我们通过我们的代码也可以证明我们的进程是具有独立性的,例如:父进程改变一个值,子进程不变(与写时拷贝有关)。
清楚进程指令:kill -9 pid
总:进程具有独立性
Linux中有关注释的相关知识
批量化注释:在命令模式下,Ctrl+v进入V-BLOCK模式,然后按住j(向下移动),选中区域,切换大写,输入i,在输入//,最后esc退出,就注释好了。
批量化取消注释:在命令模式下,Ctrl+v进入V-BLOCD模式,然后按住l(向上移动),选中区域,输入d。
取消注释:切换成小写,然后输入u。
总结:温故而知新,一定要反复理解现在学的知识和以前的知识。
版权归原作者 今天还要努力 所有, 如有侵权,请联系我们删除。