
系列文章目录
spark第一章:环境安装
spark第二章:sparkcore实例
spark第三章:工程化代码
spark第四章:SparkSQL基本操作
文章目录
前言
接下来我们学习SparkSQL他和Hql有些相似。Hql是将操作装换成MR,SparkSQL也是,不过是使用Spark引擎来操作,效率更高一些
一、添加pom
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.2.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.2.3</version>
以上是这次博客需要的所有依赖,一次性全加上。
二、常用操作
一共这么多,挨个讲解一下
1.类型转换
SparkSQL中有三种常用的类型,RDD之前说过就不说了。
DataFrame
Spark SQL 的 DataFrame API 允许我们使用 DataFrame 而不用必须去注册临时表或者生成 SQL 表达式。DataFrame API 既有 transformation 操作也有 action 操作。
DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了
SparkSql_Basic.scala
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkSql_Basic {
def main(args: Array[String]): Unit ={
// 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()import spark.implicits._
// val df: DataFrame = spark.read.json("datas/user.json")
// df.show()
//DataFrame => SQL
// df.createOrReplaceTempView("user")
// spark.sql("select age from user").show()
//DtaFrame => DSL
// 在使用DataFrame时,如何涉及到转换操作,需要引入转换规则
// df.select("age","username").show()
// df.select($"age"+1).show()
// df.select('age+1).show()
// DataSet
// DataFrame 是特定泛型的DataSet
// val seq: Seq[Int]= Seq(1, 2, 3, 4)
// val ds: Dataset[Int]= seq.toDS()
// ds.show()
// RDD <=>DataFrame
val rdd=spark.sparkContext.makeRDD(List((1,"zhangsan",30),(2,"lisi",40)))
val df: DataFrame = rdd.toDF("id", "name", "age")
val rowRDD: RDD[Row]= df.rdd
// DataFrame <=> DatsSet
val ds: Dataset[User]= df.as[User]
val df1: DataFrame = ds.toDF()
// RDD <=> DataSet
val ds1: Dataset[User]= rdd.map {case(id, name, age)=>{
User(id, name, age)}}.toDS()
val userRDD: RDD[User]= ds1.rdd
// 关闭环境
spark.close()}case class User(id:Int,name:String,age:Int)}
2.连接mysql
SparkSQL提供了多种数据接口,我们可以通过JDBC连接Mysql数据库,我们先随便在数据库里边写点东西。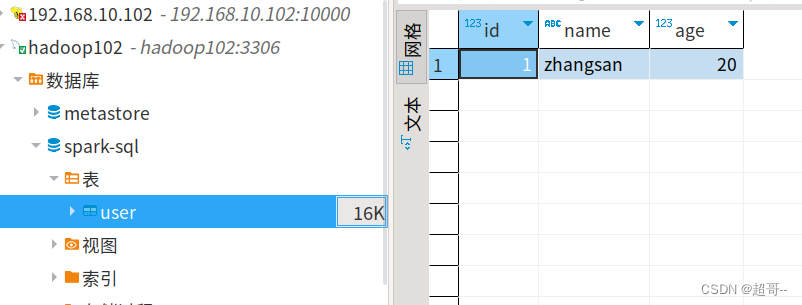
SparkSql_JDBC.scala
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object SparkSql_JDBC {
def main(args: Array[String]): Unit ={
// 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()import spark.implicits._
val df: DataFrame = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://hadoop102:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "user")
.option("useSSL","false")
.load()
df.show
df.write
.format("jdbc")
.option("url", "jdbc:mysql://hadoop102:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "user1")
.option("useSSL","false")
.mode(SaveMode.Append)
.save()
// 关闭环境
spark.close()}}
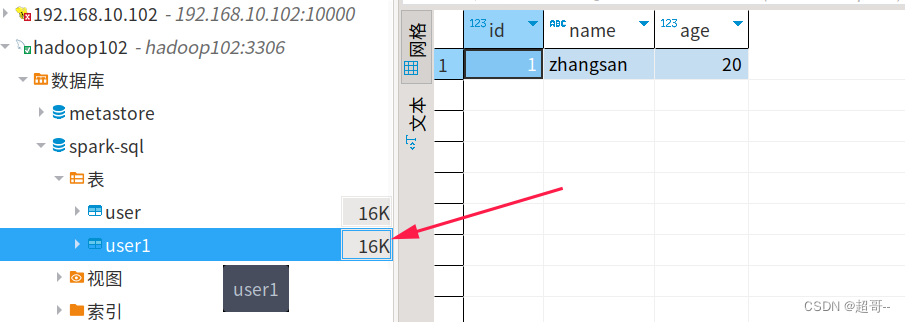
3.UDF函数
这个函数可以对简单的数据进行处理,但是比较局限.
这次我们从json文件读取数据
{"username":"zhangsan", "age":20}{"username":"lisi", "age":30}{"username":"wangwu", "age":40}
SparkSql_UDF.scala
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkSql_UDF {
def main(args: Array[String]): Unit ={
// 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()import spark.implicits._
val df: DataFrame = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
spark.udf.register("prefixName",(name:String)=>{"Name:" + name
})
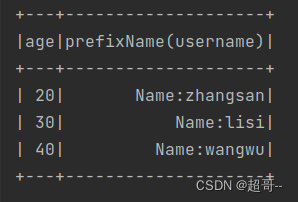
spark.sql("select age ,prefixName(username) from user").show()
// 关闭环境
spark.close()}}
4.UDAF函数
UDAF函数的处理能力就比UDF强大多了,可以完成一些更复杂的操作.
SparkSql_UDAF1.scala
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}import org.apache.spark.sql.{DataFrame, Encoder, Encoders, Row, SparkSession, functions}
object SparkSql_UDAF1 {
def main(args: Array[String]): Unit ={
// 创建SparkSQL的运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
val df: DataFrame = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
//计算平均年龄
spark.udf.register("ageAvg", functions.udaf(new MyAvgUDAF()))
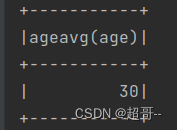
spark.sql("select ageAvg(age) from user").show()
// 关闭环境
spark.close()}case class Buff( var total:Long,var count:Long)
class MyAvgUDAF extends Aggregator[Long,Buff,Long]{
//初始值
override def zero: Buff ={
Buff(0L,0L)}
//更新缓冲区
override def reduce(buff: Buff, in: Long): Buff ={
buff.total=buff.total+in
buff.count=buff.count+1
buff
}
//合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff ={
buff1.total=buff1.total+buff2.total
buff1.count=buff1.count+buff2.count
buff1
}
//计算结果
override def finish(buff: Buff): Long ={
buff.total/buff.count
}
//缓冲区编码操作
override def bufferEncoder: Encoder[Buff]= Encoders.product
//输出的编码操作
override def outputEncoder: Encoder[Long]= Encoders.scalaLong
}}
还有一种方法,在Spark3已经不被官方推荐了,所以这里就不叙述了.
5.连接hive
首先我们在集群先,启动Hadoop和Hive
然后将jdbc的jar包放到hive的lib文件中
这个jar包在安装Hive环境时,使用过.
将虚拟机中的hive配置文件,hive-site.xml导出
放到idea的resource文件夹中,然后最好吧target文件夹删除,因为idea有可能从target中直接读取之前的数据,从而没有扫描hive-site.xml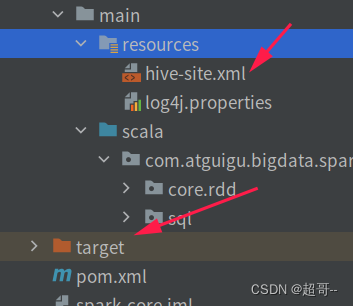
我们就做最简单的查询操作
SparkSql_Hive.scala
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object SparkSql_Hive {
def main(args: Array[String]): Unit ={
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSql")
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("show tables").show
// 关闭环境
spark.close()}}
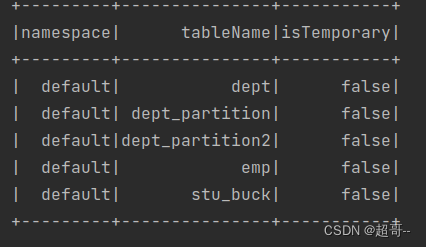
如果能查询hive中的数据库,代表成功.
总结
SparkSQL的常用操作基本就这些,至于项目吗,下次专门在写一次吧
版权归原作者 超哥-- 所有, 如有侵权,请联系我们删除。