
大数据概述
在大数据这个概念兴起之前,信息系统存储数据的方法主要是我们熟知的关系型数据库,关系型数据库,关系型模型之父 Edgar F. Codd,在 1970 年 Communications of ACM 上发表了《大型共享数据库数据的关系模型》的经典论文,从此之后关系模型的语义设计达到了 40 年来普世、易于理解,语法的嵌套,闭环,完整。关系型数据库管理系统(RDBMS)就是基于关系模型在数据库领域所构建的传统数据库管理工具,例如大名鼎鼎m的Oracle、DB2、MySQL、PostgreSQL、SQLServer等。
作为早期的互联网、电子政务、商业管理、工业制造等行业领域,首先每天产生的数据量并不大,而且以高价值的结构化数据为主,例如:早期互联网Web1.0时代,一台SQLServer数据库就能支撑绝大多数的门户网站,一台小机搭配Oracle就能轻松应对在线金融业务系统;其次数据访问需求比较简单,主要是业务数据模型之间的关联设计,业务数据的插入、更新和删除,对于更复杂的数据需求主要还是对字段的分组查询形成多维统计和明细下钻。
但是这一切都被互联网的发展所打破,尤其是到了2010年移动互联网的爆发。大数据的名词和概念随着Google的定义席卷了全球,那么大数据最基本的一个特征就是信息服务所接收到的数据请求量非常庞大,这对于传统的RDBMS来讲是冲击性的。
举个例子:微博一个顶流明星关注的粉丝都是千万级以上,若按照关系型数据库的存储与查询方法来做一次明星内容推送,那么就需要按照明星ID查询到所有粉丝ID,给每个粉丝的关注者动态表增加一条明星新发布内容的ID,这对于关系型数据库来讲是极为恐怖的一次二级索引遍历事件和索引构建事件,而这种事件在微博业务里面每天都是高频次产生,另外B树索引会被千万级的索引量撑大得特别宽,这种遍历基本上就是疯狂的IO扫描。那么我们可以想象到,上亿次的发布,在成千上百亿的数据量中不断遍历,再强悍的关系型数据库都会瞬间崩溃。
上面主要提到的是互联网大平台的常见请求服务,数据库对于海量数据进行索引请求操作的恐怖性能需求,那么这些数据量在大数据概念兴起之后的骤然剧增是什么原因导致的呢?
主要因素就是互联网越来越普及,被连接的信息点越来越密,信息的传输和交流变得越来越通畅,例如:早期的金融、保险、电信等信息系统若要将数据汇集到管理中心,都是各个地区负责人对自身所辖数据库进行文件输出,然后再将文件定期上传到中心,最后由中心管理员统一汇总,这种方式最大的问题就是数据延迟很大,提交的数据质量总会因为不统一的规范而导致参差不齐的质量,尤其是汇聚到中心的数据,尽管体量庞大,但是不具有从起点到终点的全过程设计,因此数据的应用程度很低,这就导致了数据仓库变成了数据坟墓。
但是通过互联网、移动化,现在大量的业务从源头就开始了向一个中心平台服务的业务提交,数据汇聚,那么数据就实时地流动起来了,每天形成了大量的数据业务存储,这在金融、电信、保险、政府公共事业方面特别明显,例如:我们曾经做过的税务健康监测系统,每天都需要监测上百G的数据量,而这都是整个城市的公众在一个税务系统上进行税务业务办理所产生的庞大数据量,这就是大数据产生的一个重要因素。
大数据产生的另外一个因素就是城市基础设施、人、水源河流、天气环境、公路交通、工业设备、机房等活动状态可监测的对象,通过(生物)传感器、物联网的技术手段,采集了大量基于时间线的感应数据,这些数据最大的特征在于数据长期是稳定的走势,但是恰恰不稳定的数据是需要被重点监测,以达到及时预防,防止故障与灾难,因此我们可以理解这些数据大多数是低价值的,只有少量变异数据和具有挖掘出潜在关联关系的数据却又具有极高的价值,这个特色还特别体现在股票方面,例如:通过多支股票的走势进行数据挖掘,从它们的历史峰值和谷底中找到相似性的走势,再从相似性走势中预测可能发生的概率。
大数据技术描述
我们在上面的概述中其实心里就应该很清楚传统RDBMS数据库是难以支撑大数据场景,那么到底有哪些技术属于大数据技术,这些技术又起到什么作用呢?
回答这个问题之前,我们需要先搞清楚解决大数据业务需要的流程和步骤,在这个问题上的复杂度已经远远超过了传统数据库处理的场景,我们上面提到过传统数据库主要就是支撑在线业务数据的查询、写入和更新,但是大数据业务需要考虑的主要流程就是:采集、数据流处理、数据管道、存储、搜索、挖掘分析、查询服务和分析展示等
下图是个比较典型的大数据采集、传输、存储和分析的示意图:
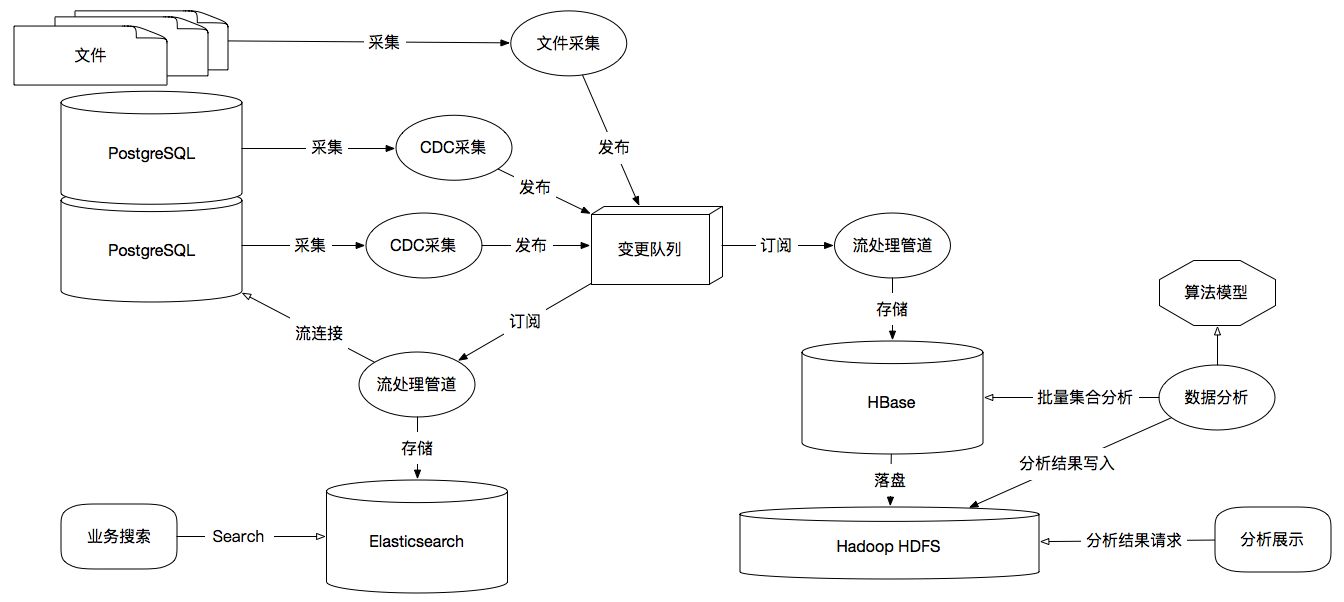
大数据计算流程示意图
在大数据中非常重要起点就是对于数据的采集,一般大数据主流程不会直接从用户端的请求服务中进行计算,我们将这个领域定位为OLTP,也就是由传统数据库或支撑海量数据写入的NoSQL来完成,然后我们通过采集工具从RDBMS、文件或NoSQL中进行采集同步,例如上图中:利用CDC(数据变更捕获),我们可以从PostgreSQL的逻辑复制中捕获WAL(预写日志文件)的数据变更,然后将变更数据发送到大数据平台,也可以从文件中采集获取,常见的采集工具有ELK的Filebeat、Logstash采集文件,Flume作为多源采集管道并集成HDFS,Canal采集MySQL Binlog,Flink CDC采集PostgresSQL WAL等。
数据流处理主要应用在数据传输实时性比较高的场景,我们常见的Flink、Storm、Spark Streaming都是为此场景而产生,在上图中我们可以看到流处理管道,起到了数据传输过程中非常重要的数据转换和数据写入作用,它们还能在流传输的过程中进行流库连接、流流连接进行二次加工,生成新的数据流,并在流转的过程中进行实时数据采样、过滤、转换、封装、清洗等多种实时处理操作。
数据流在中转过程中往往需要缓冲进队列,这在大数据的实时流处理中非常重要,例如:Kafka、RocketMQ,它们不仅形成了数据在上下游计算流转过程中的数据持久化所带来的数据可靠性,而且还能形成一对多的发布与订阅的扇形数据流转结构,这样就可以一个数据为多个计算服务所用,如上图中变更队列一方面可以由搜索管道来订阅,数据就流向了数据搜索引擎,另一方面可以由分析管道来订阅,数据流就流向了OLAP平台,另外队列保持了发生情况的前后一致性,那么我们存储的过程中就能轻松解决数据的时间线或事务问题。
大数据存储需要根据数据所适用的场景进行多种情况的构建,如上图中我们可以看到,若应用于搜索场景,那么最好的存储就是搜索引擎,例如:Elasticsearch、Solr,这些数据库都是典型的文档型数据库,基于文档树的结构存储,并对文档进行全文索引;若应用于OLAP场景,我们可以从图中看到使用到了HBase分布式KV数据库,它是完全遵循Google BigTable论文「PDF」的开源实现,基于列簇格式存储,行键排序,形成一个非常宽大的稀疏表,非常适合做在线统计处理和离线数据挖掘。
例如:我们前面提到的微博问题,对于HBase来说,一个行键、两个列簇、千万级稀疏列,明星(行键)、粉丝集合(列簇)、粉丝(列)或者明星(行键)、发布集合(列簇)、发布微博(列),我们总能快速的通过明星ID,扫描他的粉丝集合,获取千万粉丝进行推送,粉丝也能通过明星ID,定位到他的微博发布集合,快速找到最新发布的微博。这仅仅是面向高并发的实时聚合查询的一个案例。
上图中我们可以通过HBase完全承载PostgreSQL的结构化数据,还能通过数据管道结构化文件数据,在HBase列簇中形成统一的数据结构,上图的目的是从PostgreSQL中采集到车辆数据,文件中采集到车辆运行中的坐标数据,那么HBase中就能以车辆数据为行键,坐标数据为列簇与列,可以进一步分析不同时间点不同路段的拥堵情况。
同时我们从上图中可以看到HBase只是分布式的数据库引擎,真正数据落盘在了Hadoop HDFS,它是分布式文件系统,基于Google GFS 论文「PDF」的开源实现,提供了数据块的高可靠存储。
数据分析过程主要是分布式数据库海量数据的批量数据挖掘,我们往往需要一些支持MPP(大规模并行处理)的分布式计算框架来解决,例如:Spark、MapReduce、Tez、Hive、Presto等。这些处理引擎主要是以集群化的分布式并行计算将数据切分成多任务来解决,这样再超大规模的数据集合都可以被更多的计算节点切分而快速完成。
那么基于Spark的这样的大数据技术栈进行预测分析,就有了Spark MLlib这样的机器学习模型库,例如:我们要通过对一组海量进行一项顾客风险评测训练,预测某一位顾客购买某项保险项未来出现赔付的概率,那么就能通过MLlib的DecisionTree(决策树)算法,不断调整训练参数,去熵提纯集合,找到最佳的预测模型。
总结
作为大数据的应用与价值非常广泛,我们上面只是大数据整个生态体系的冰山一角,比如说:通过对广告投放数据的采集并写入时序数据库(TSDB),我们可以非常快速地在每秒百亿次的点击中,分析出每分钟每个投放网站的收益,投放平台为每个广告顾客创造的投放次数、展示次数、广告浏览时长等;
再比如说:我们通过日志数据跟踪,能将上千台服务器的日志进行分布式Track,那么我就能实时分析出一笔业务需要经历多少台服务器,经历了多少服务转发,在哪些服务上出现了延时,从而达到快速运维感知,尤其是面向公共事业、互联网电商、互联网金融无法容忍分钟级的故障导致的系统不可用,实时运维感知的作用就是刚性需求。
谈到信用卡机构、银行、保险行业,最重要的一项分析就是对顾客群体的预测分析,这在防欺诈、信用评级、贷款方面可以说大数据应用起到了无可替代的作用,我们需要通过数据挖掘、机器学习,将碎片化的不同数据集合,进行搜集、清洗、完善,建立数据分析算法模型,不断通过对海量数据的分析,参数优化,从数据中发现隐藏的关系,预测个体行为概率。
版权归原作者 守护石 所有, 如有侵权,请联系我们删除。