

整理 | 王轶群
责编 | 王启隆
出品丨AI 科技大本营(ID:rgznai100)
与 OpenAI 对齐失败后,Jan Leike 选择与 Anthropic 对齐。
当地时间5月28日午间,OpenAI 的前首席安全研究员 Jan Leike 发布 X 动态宣布,他已加入曾经的竞争对手公司 Anthropic。
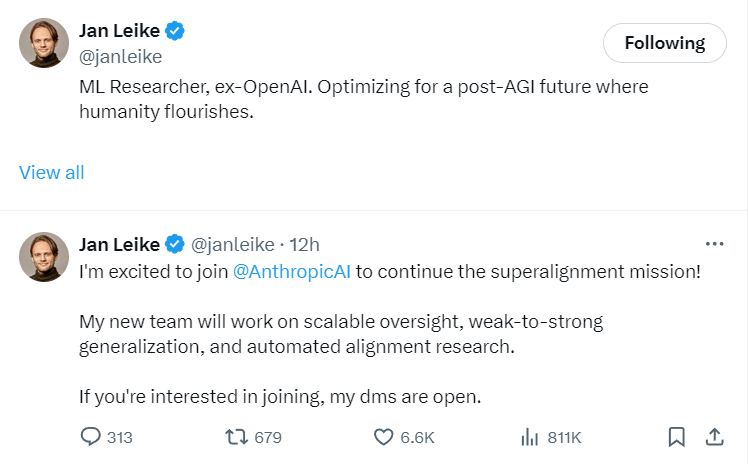
Jan Leike 表示:“我很高兴加入 Anthropic,继续超级对齐任务!我的新团队将致力于可扩展监督、弱到强泛化和自动对齐研究。如果您有兴趣加入,我的 DMS 是开放的。”
 据外媒 TechCrunch 援引知情人士消息,Leike 将直接向 Anthropic 的首席科学官 Jared Kaplan 汇报工作,而目前致力于可扩展监督(以可预测和理想的方式控制大规模人工智能行为的技术)的 Anthropic 研究人员将在 Leike 的团队成立后向其汇报工作。
据外媒 TechCrunch 援引知情人士消息,Leike 将直接向 Anthropic 的首席科学官 Jared Kaplan 汇报工作,而目前致力于可扩展监督(以可预测和理想的方式控制大规模人工智能行为的技术)的 Anthropic 研究人员将在 Leike 的团队成立后向其汇报工作。
此前,Jan Leike 曾是 OpenAI 旗下 Super Alignment(超级对齐)团队的安全主管。该团队成立于2023年,专注于人工智能的长期风险,其超级对齐技术旨在协助提升大模型的安全性。
Leike 加入竞争对手的团队,并非背叛,而是无奈之举。

太难了,在 OpenAI 搞不下去
两周前,Jan Leike 刚刚从 OpenAI 离职,紧跟着 OpenAI 联创兼 Super Alignment 首席科学家 Ilya Sutskever 宣布离职之后。仅在 Ilya Sutskever 和 Jan Leike 两员大将离职的几日后, OpenAI 便宣布解散该安全团队。
而在安全团队大变动的前一天,OpenAI 刚刚发布了震动 AI 界的“旗舰级”生成式人工智能模型 GPT-4o,该几乎改写了大模型交互定义,可以实时对音频、视觉和文本进行推理,语音响应时间短至232毫秒,与人类反应速度一致。
“光鲜的产品”背后,在 OpenAI 内部,安全的推进曾变得异常艰难。
在离职前,Leike 共同领导的超级对齐团队曾有一个雄心勃勃的目标,即在未来四年内解决控制超级智能 AI 的核心技术挑战,但经常发现自己受到 OpenAI 领导层的束缚。
Leike 在离职后曾爆料称,最近几年OpenAI已经不惜内部文化,把“吸引眼球的产品”放在安全准则之前,并表示超级对齐团队“在计算资源方面捉襟见肘”,完成这项关键研究“变得越来越困难”。
在 Ilya Sutskever 和 Jan Leike 之后掀起的 OpenAI 离职潮风波中,多位离职员工已爆料了 OpenAI 内部忽视 AGI 风险、超级对齐团队算力分配严重让位于新产品研发、忽视安全原则、超级对齐业务走投无路等状况。
此情此景,与一年前OpenAI 开300万+年薪招超级AI研究员、投20%总算力成立超级对齐团队的高调官宣,形成鲜明对比。
实际上,自从OpenAI发生第一轮宫斗、Sam Altman被罢免以来,整个OpenAI的情绪就开始不对劲。显然,Altman在合作伙伴关系和产品重点方面的发展方向,已经超出了大多数人能接受的程度。他的危险面目,正随着时间线的推移,逐渐暴露。
据 OpenAI 前董事会成员 Helen Toner 在“The Ted AI Show”播客节目中再次曝光的OpenAI宫斗细节,Sam Altman 在多场合提供了关于公司安全流程的不准确信息。这意味着董事会基本上不可能知道这些安全流程的运作情况如何,或者可能需要改变什么。
而与 Ilya Sutskever 相似, Helen Toner 本身也是倡导安全的离开 OpenAI 的前董事之一,目前 Toner 任乔治城大学安全与新兴技术中心战略总监。
2023年7月, 还在OpenAI 任职的 Ilya Sutskever 与 Jan Leike 撰写了一份 OpenAI 公告,涉及超级对齐的项目,警示道:虽然超级智能可以帮助解决世界上许多最重要的问题,但它也可能非常危险,并可能导致人类丧失权能,甚至导致人类灭绝。
对于在 OpenAI 离职,Leike 表示:“离开这份工作是我做过的最艰难的事情之一,因为我们迫切需要弄清楚如何引导和控制比我们聪明得多的人工智能系统。”
而目前,OpenAI 又在训练新的光鲜产品了。就在Leike宣布加入 Anthropic 继续超级对齐任务的当日,OpenAI 宣布其正在训练新的旗舰级人工智能大模型,这款模型将接替目前广泛用于ChatGPT的GPT-4技术。OpenAI 表示期望新模型能够“迈向下一个层次的能力”,并致力于构建AGI——一种能够执行人类大脑所有功能的机器。新模型预期将成为推动各种AI产品的核心,包括聊天机器人、类似于苹果Siri的数字助理、搜索引擎及图像生成器。
同时,颇具戏剧性的是,这一次的大模型训练伴随着一次所谓的安全动作。仅在 Leike 宣布离职后的两个小时后,OpenAI 宣布其董事会成立了安全与保障委员会。

OpenAI 在官网发文称,该安全与保障委员会,由董事 Bret Taylor(主席)、Adam D'Angelo、Nicole Seligman 和 Sam Altman(首席执行官)领导。该委员会将负责就 OpenAI 项目和运营的关键安全与保障决策向全体董事会提出建议,以探索如何处理新模型和未来技术可能带来的风险。该公司表示:“我们为能够打造并推出在能力和安全性上均处于行业领先的模型感到自豪,同时,我们欢迎在这一重要时刻展开充分的讨论。”该委员会将进行 90 天的评估,并将结果报告给董事会。OpenAI 计划采纳合适的建议,并在董事会审查后公开分享更新。
这一举动,是 OpenAI 在内部爆料和舆论压力下在安全问题上的及时转向,还是内部酝酿已久的另一种策略显露,90天后或许可以略见端倪。

意见不合成就 Anthropic
Jan Leike 的快速入职 Anthropic,并非匆忙之策,而是早有机缘。
扒一扒 Anthropic 的成立背景,就能看到,其创始人与 OpenAI的意见不合,一定程度上成就了今日的 Anthropic。
Anthropic 首席执行官 Dario Amodei ,之前曾担任 OpenAI 的研究副总裁。
Dario Amodei 在 OpenAI 成立之初,就被其“实现安全的通用人工智能(AGI)”这一初衷吸引。当时探索AI的可操纵、可解释性是OpenAI的研究方向之一,这正是Dario Amodei 所擅长的领域。
在OpenAI期间,Dario Amodei作为GPT-2、GPT-3的核心研发成员,在训练AI模型的过程中便着眼于在AI迅猛发展的过程保证其安全可控性,包括AI能反映了人类的价值观,能够解释AI决策背后的逻辑以及AI能够在不伤害人类的情况下学习。
然而,与此同时,大量的人力成本与训练成本开支消耗着这家公司的理想主义。当非盈利性的 OpenAI 在2019年接受了微软注资后,内部团队也逐渐出现了分裂。以 Dario Amodei 为代表的部分核心成员认为,随着 AI 模型的增大、算力的增强,AI 的安全性、可操纵、可解释性变得更加重要,而不是盲目迭代比GPT-3 更大的 AI 模型,应该把解决神经网络的“黑盒”问题放到更重要的位置。
在微软注资后,OpenAI 很快将上述问题还未解决的 GPT-3 交给微软来使用,OpenAI 的逐渐商业化以及对创始初心的背离。以 Dario Amodei 为代表的一群技术理想主义者不愿再与微软及商业化方向捆绑,想要重现 OpenAI 创始初衷。
2021年2月,Dario Amodei 和妹妹 Daniela 联手创立了 Anthropic,同时带走了10名前 OpenAI 员工。
 (Anthropic 创始人 Dario兄妹)
(Anthropic 创始人 Dario兄妹)
这10名员工,包括 GPT-3 论文第一作者Tom Brown、OpenAI 前政策负责人 Jack Clark,以及Gabriel Goh、Jared Kaplan、Sam McCandlish、Kamal Ndousse等。Anthropic 创始核心成员大部分来自于OpenAI原有团队,并在AI可解释性、AI 模型安全设计事故分析、引入人类偏好的强化学习等方面有颇深的造诣。
当时曾有媒体预测,面临安全核心成员出走的OpenAI可能在这些领域会逊色于Anthropic。而前 OpenAI 超级对齐团队领导者 Jan Leike 的加入,更会加剧这一倾向。
Anthropic旨在创造可操纵、可解释的人工智能系统,“当今的大型通用系统可以带来显著的好处,但也可能无法预测、不可靠和不透明:我们的目标是在这些问题上取得进展。”Dario Amodei曾对外表示,“Anthropic的目标是推进基础研究,让我们能够构建更强大、更通用、更可靠的人工智能系统,然后以造福人类的方式部署这些系统。”
承接创始人的意愿,Anthropic 经常将自己定位成为比 OpenAI 更注重安全的 AI 公司。目前,多个层面显示出, Leike 的团队与 OpenAI 最近解散的超级对齐团队的使命很相似。
Amodei 在与 OpenAI 发展方向产生分歧时,想要先解决的解决神经网络的“黑盒”问题,可以理解为能够将数据转变成其它东西一个算法,其中的问题在于,黑盒子在发现模式的同时,经常无法解释发现的方法。
此前,谷歌 AI Overviews 提供的“披萨上涂上胶水”“人每天应该至少吃一块小石头”等奇怪搜索答案,也是基于互联网数据输入的转化造成的输出失控。
而超级对齐是一种确保人工智能系统的行为与人类价值观和目标高度一致的技术和方法论。随着 AI 技术的发展,尤其是在决策能力和自主性方面,确保它们的行动不会偏离人类的最佳利益变得尤为重要。
目前,超级对齐的研究主要集中在如何通过算法和政策确保 AI 系统在接受训练和执行任务时能够理解并遵循人类的伦理标准。研究人员和工程师们正在探索多种机制,包括强化学习的修正、决策框架的伦理整合,以及交互式机器学习,这些方法都旨在提高 AI 系统对人类指导的响应性和适应性。
而Anthropic 公司的英文单词意思,就是有关人类的。技术如何在安全可控的条件下良性发展、造福人类,AI 理想如何不受制于商业利益,将是Anthropic 创始团队和新加入的 Leike 的重要课题。

AI 安全首当其冲,超级对齐前路漫漫
安全、监管,显然已成为 AI 行业的热点议题和首要批判点。
超级智能的机器可以替代人类执行一些复杂的职业任务,提高效率,优化决策。然而,正如所有强大的工具一样,AI 也引发了一系列担忧,其中最引人注目的可能就是关于它们是否会引发所谓的“技术奇点”——即AI超越人类智能,可能带来不可预测的后果,甚至是灾难性的全球风险。
在追求技术突破的同时,我们如何确保这些智能系统不仅遵循我们的价值观,还能促进社会整体的福祉?这就是超级对齐的用武之地,旨在引导 AI 的发展方向,确保技术进步能够在安全和伦理的框架内推进,从而避免潜在的负面影响。
而就在上周末,马斯克与 AI 领域先驱杨立昆就 AI 的安全监管问题在社交媒体 X 上发生了争吵,暴露了在人工智能风险上的关键分歧可能会导致科技界分裂。
两人截然不同的立场凸显了业界对 AI 未来发展监管路径的深刻分歧:
杨立昆表示,现在忧虑 AI 带来“生存风险”并急于监管还为时尚早。他认为,人工智能的安全性在于人类的设计与控制,并以涡轮喷气发动机为例,指出在确保高度可靠性后才广泛部署,AI 亦应遵循类似路径。杨立昆重申了他的“开放而非监管”立场,倡导开源和共享以促进技术的透明度与安全性。
而马斯克则以他特有的幽默风格回应:“Prepare to be regulated”(准备接受监管),暗示监管的必要性。作为一位积极的监管支持者,马斯克虽然对 AI 失控持有深切忧虑,但他并未放慢建立个人 AI 帝国的步伐。他强调,尽管监管“并不有趣”,但在 AI 可能“掌控一切”之前建立规则至关重要。随后,这场骂战逐渐上升到人身攻击的层次,火药味颇重。
 (网友表示请二位像绅士一样解决问题)
(网友表示请二位像绅士一样解决问题)
人类大佬之间,尚有激烈分歧,技术如何识别并对齐人类价值观?
在要求 AGI 与人类价值观对齐之前,首先要在人类自身形成统一共识,找到万物的底层逻辑,并应用与技术标准。这一共识,也包括对技术发展的认知以及对监管所持有的态度。
由此可见,在构建安全的 AGI 之前,还有诸多伦理及技术问题需要解决。
实现安全的AGI,道阻且长,然而如 Ilya Sutskever、Jan Leike、Dario Amodei 等先驱者,正在各自的领域全力以赴。
参考链接:
https://m.thepaper.cn/newsDetail_forward_27495059
https://mp.weixin.qq.com/s/WDMKya2LRkcKaF9jyvjC_w
https://baijiahao.baidu.com/s?id=1757259268935283497&wfr=spider&for=pc

开发者正在迎接新一轮的技术浪潮变革。由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的 2024 年度「全球软件研发技术大会」秉承干货实料(案例)的内容原则,将于 7 月 4 日-5 日在北京正式举办。大会共设置了 12 个大会主题:大模型智能应用开发、软件开发智能化、AI 与 ML 智能运维、云原生架构……详情👉:http://sdcon.com.cn/

版权归原作者 AI科技大本营 所有, 如有侵权,请联系我们删除。