
你是否曾经好奇过,当你在网上购物或使用手机应用时,背后的数据是如何被存储和分析的?答案就在数据仓库中。本文将为你揭开数据仓库的神秘面纱,深入探讨其核心组成部分,以及这些组件如何协同工作,将海量数据转化为有价值的商业洞察。
目录
引言:数据仓库的魔力
想象一下,你正在经营一家全球性的电子商务公司。每天,成千上万的订单涌入,客户遍布全球各地,产品种类繁多。如何从这些看似杂乱无章的数据中,提取出有价值的信息,指导业务决策?这就是数据仓库发挥魔力的地方。
数据仓库就像是一个巨大的数据中枢,它将来自不同来源的数据整合在一起,经过清洗、转换和组织,最终呈现出一幅清晰的业务全景图。但是,要实现这一点,数据仓库需要依靠几个关键组件的紧密配合。
接下来,我们将深入探讨数据仓库的四大核心组成部分:
- 数据源和数据集成
- 数据存储
- 元数据管理
- 数据访问和分析工具

让我们开始这段探索数据仓库内部结构的奇妙旅程吧!
1. 数据源和数据集成:数据仓库的"进水口"
1.1 多样化的数据源
数据仓库的第一个关键组成部分是数据源。在我们的电子商务公司示例中,数据可能来自以下几个方面:
- 交易系统:记录每一笔订单的详细信息
- 客户关系管理(CRM)系统:存储客户的个人信息和互动历史
- 库存管理系统:跟踪产品库存和供应链信息
- 网站和移动应用:捕获用户行为数据,如浏览历史、点击流等
- 社交媒体平台:收集客户评论和反馈
- 外部数据源:如市场调研报告、竞争对手信息等
这些数据源的格式可能各不相同,有结构化的(如关系型数据库中的表格数据),也有半结构化的(如JSON或XML格式的日志文件),还有非结构化的(如客户评论文本)。
1.2 数据集成:ETL过程
将这些杂乱的数据转化为有意义的信息,需要经过一个被称为ETL(Extract, Transform, Load)的过程:
- 提取(Extract): 从各个源系统中提取数据
- 转换(Transform): 清洗、转换和整合数据
- 加载(Load): 将处理后的数据加载到数据仓库中
让我们通过一个具体的例子来说明ETL过程:
假设我们需要整合来自交易系统和CRM系统的数据,以分析客户购买行为。
import pandas as pd
from sqlalchemy import create_engine
# 连接到源数据库
transaction_db = create_engine('postgresql://user:password@localhost:5432/transaction_db')
crm_db = create_engine('mysql://user:password@localhost:3306/crm_db')# 提取数据
transactions = pd.read_sql("SELECT * FROM orders WHERE date >= '2023-01-01'", transaction_db)
customers = pd.read_sql("SELECT * FROM customers", crm_db)# 转换数据# 1. 统一日期格式
transactions['date']= pd.to_datetime(transactions['date'])# 2. 合并客户信息
merged_data = pd.merge(transactions, customers, on='customer_id', how='left')# 3. 计算客户总消费金额
customer_spending = merged_data.groupby('customer_id')['amount'].sum().reset_index()# 4. categorize客户defcategorize_customer(spend):if spend >1000:return'VIP'elif spend >500:return'Regular'else:return'Occasional'
customer_spending['category']= customer_spending['amount'].apply(categorize_customer)# 连接到数据仓库
data_warehouse = create_engine('postgresql://user:password@localhost:5432/data_warehouse')# 加载数据到数据仓库
customer_spending.to_sql('customer_segments', data_warehouse, if_exists='replace', index=False)
在这个例子中,我们:
- 从交易系统提取了订单数据
- 从CRM系统提取了客户数据
- 将日期格式统一化
- 合并了交易和客户数据
- 计算了每个客户的总消费金额
- 根据消费金额对客户进行了分类
- 最后将处理后的数据加载到数据仓库中
这个过程看似简单,但在实际的大规模数据仓库中,ETL过程可能要处理数百个数据源,涉及复杂的业务规则和数据质量检查。因此,许多公司会使用专门的ETL工具来管理这个过程,如Apache NiFi、Talend或Informatica。
1.3 实时数据集成:从批处理到流处理
随着业务对实时数据的需求增加,传统的批量ETL过程正在向实时或近实时的数据集成方式演变。这种方式通常被称为ELT(Extract, Load, Transform)或流式ETL。
在ELT模式下,数据首先被提取并直接加载到数据仓库或数据湖中,然后在目标系统中进行转换。这种方法的优势在于可以更快地获取原始数据,并且可以根据需要灵活地进行转换。
以下是一个使用Apache Kafka和Apache Flink进行实时数据集成的简化示例:
importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;publicclassRealTimeETL{publicstaticvoidmain(String[] args)throwsException{finalStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 配置Kafka消费者Properties properties =newProperties();
properties.setProperty("bootstrap.servers","localhost:9092");
properties.setProperty("group.id","test");FlinkKafkaConsumer<String> consumer =newFlinkKafkaConsumer<>("topic",newSimpleStringSchema(), properties);// 创建数据流DataStream<String> stream = env.addSource(consumer);// 数据转换DataStream<CustomerEvent> customerEvents = stream
.map(json ->parseJson(json))// 解析JSON.filter(event -> event.getType().equals("PURCHASE"))// 只处理购买事件.map(event ->enrichCustomerData(event));// 使用CRM数据丰富事件信息// 数据汇总DataStream<CustomerSegment> customerSegments = customerEvents
.keyBy(event -> event.getCustomerId()).window(TumblingEventTimeWindows.of(Time.hours(1))).aggregate(newCustomerSegmentAggregator());// 输出结果到数据仓库
customerSegments.addSink(newJdbcSink<>("INSERT INTO customer_segments (customer_id, total_spend, segment) VALUES (?, ?, ?)",newJdbcStatementBuilder<CustomerSegment>(){@Overridepublicvoidaccept(PreparedStatement statement,CustomerSegment segment)throwsSQLException{
statement.setString(1, segment.getCustomerId());
statement.setDouble(2, segment.getTotalSpend());
statement.setString(3, segment.getSegment());}},newJdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:postgresql://localhost:5432/data_warehouse").withDriverName("org.postgresql.Driver").withUsername("user").withPassword("password").build()));
env.execute("Real-time Customer Segmentation");}}
这个例子展示了如何:
- 从Kafka主题中消费实时购买事件数据
- 解析和过滤数据
- 使用CRM数据丰富事件信息
- 对数据进行时间窗口聚合,计算客户细分
- 将结果实时写入数据仓库
实时数据集成使得企业能够更快地对市场变化做出反应,例如实时调整定价策略,或者在客户正在浏览网站时推送个性化优惠。
1.4 数据质量管理
在数据集成过程中,确保数据质量至关重要。常见的数据质量问题包括:
- 缺失值
- 重复数据
- 不一致的格式(如日期格式不统一)
- 错误的数据类型
- 业务规则违反(如负数的价格)
为了解决这些问题,数据仓库通常会实施一系列数据质量检查和清洗规则。以下是一个使用Python的pandas库进行数据质量检查的示例:
import pandas as pd
import numpy as np
defcheck_data_quality(df):
issues =[]# 检查缺失值
missing_values = df.isnull().sum()if missing_values.any():
issues.append(f"发现缺失值:\n{missing_values[missing_values >0]}")# 检查重复行
duplicates = df.duplicated().sum()if duplicates >0:
issues.append(f"发现{duplicates}行重复数据")# 检查日期格式if'date'in df.columns:try:
pd.to_datetime(df['date'])except ValueError:
issues.append("日期列包含无效格式")# 检查数值列的范围
numeric_columns = df.select_dtypes(include=[np.number]).columns
for col in numeric_columns:if(df[col]<0).any():
issues.append(f"列'{col}'包含负值")# 检查分类变量的有效值if'category'in df.columns:
valid_categories =['A','B','C']
invalid_categories = df[~df['category'].isin(valid_categories)]['category'].unique()iflen(invalid_categories)>0:
issues.append(f"发现无效的分类值: {invalid_categories}")return issues
# 使用示例
df = pd.read_csv('sample_data.csv')
quality_issues = check_data_quality(df)if quality_issues:print("发现以下数据质量问题:")for issue in quality_issues:print(f"- {issue}")else:print("数据质量检查通过,未发现问题")
这个脚本展示了几种常见的数据质量检查:
- 检查缺失值
- 检查重复数据
- 验证日期格式
- 检查数值列的范围(例如,检测负值)
- 验证分类变量的有效值
在实际的数据仓库环境中,这些检查可能会更加复杂,并且会根据特定的业务规则进行定制。例如,可能需要检查跨表的数据一致性,或者验证复杂的业务逻辑。
此外,许多企业还会使用专门的数据质量工具,如Talend Data Quality、Informatica Data Quality或开源工具Great Expectations,这些工具提供了更全面和自动化的数据质量管理功能。
1.5 数据血缘和影响分析
随着数据仓库变得越来越复杂,理解数据的来源和流动变得至关重要。这就是数据血缘(Data Lineage)的概念。数据血缘追踪数据从源系统到最终报告的整个生命周期,帮助数据工程师和分析师理解:
- 数据的来源
- 数据经历了哪些转换
- 数据被哪些下游系统或报告使用
数据血缘不仅有助于排查问题,还可以进行影响分析,评估源系统或ETL流程的变更可能对下游系统产生的影响。
以下是一个使用Python构建简单数据血缘图的示例:
import networkx as nx
import matplotlib.pyplot as plt
defcreate_lineage_graph():
G = nx.DiGraph()# 添加节点
G.add_node("销售系统", node_type="source")
G.add_node("CRM系统", node_type="source")
G.add_node("ETL过程", node_type="process")
G.add_node("客户维度表", node_type="target")
G.add_node("销售事实表", node_type="target")
G.add_node("客户细分报告", node_type="report")
G.add_node("销售预测模型", node_type="analytics")# 添加边(数据流)
G.add_edge("销售系统","ETL过程")
G.add_edge("CRM系统","ETL过程")
G.add_edge("ETL过程","客户维度表")
G.add_edge("ETL过程","销售事实表")
G.add_edge("客户维度表","客户细分报告")
G.add_edge("销售事实表","客户细分报告")
G.add_edge("销售事实表","销售预测模型")return G
defvisualize_lineage(G):
pos = nx.spring_layout(G)
node_colors =['lightblue'if G.nodes[node]['node_type']=='source'else'lightgreen'if G.nodes[node]['node_type']=='process'else'orange'if G.nodes[node]['node_type']=='target'else'pink'if G.nodes[node]['node_type']=='report'else'lightgrey'for node in G.nodes()]
plt.figure(figsize=(12,8))
nx.draw(G, pos, with_labels=True, node_color=node_colors, node_size=3000, font_size=10, font_weight='bold', arrows=True)
plt.title("数据血缘图")
plt.axis('off')
plt.tight_layout()
plt.show()# 创建和可视化数据血缘图
lineage_graph = create_lineage_graph()
visualize_lineage(lineage_graph)# 进行影响分析defimpact_analysis(G, changed_node):
impacted_nodes =list(nx.dfs_preorder_nodes(G, source=changed_node))
impacted_nodes.remove(changed_node)# 排除起始节点return impacted_nodes
# 假设CRM系统发生变更
changed_system ="CRM系统"
impacted_nodes = impact_analysis(lineage_graph, changed_system)print(f"{changed_system}的变更可能影响以下组件:")for node in impacted_nodes:print(f"- {node}")
这个示例展示了如何:
- 使用networkx库创建一个简单的数据血缘图
- 可视化数据血缘,直观地展示数据流
- 进行基本的影响分析,确定某个组件变更可能影响的下游系统
 在实际的数据仓库环境中,数据血缘可能要复杂得多,可能需要专门的工具如Collibra、Informatica Enterprise Data Catalog或Apache Atlas来管理。这些工具不仅可以自动捕获和可视化复杂的数据流,还可以进行更深入的影响分析和治理。
在实际的数据仓库环境中,数据血缘可能要复杂得多,可能需要专门的工具如Collibra、Informatica Enterprise Data Catalog或Apache Atlas来管理。这些工具不仅可以自动捕获和可视化复杂的数据流,还可以进行更深入的影响分析和治理。
通过实施数据血缘和影响分析,数据工程师可以:
- 更快地定位和解决数据问题
- 评估变更的潜在影响,减少意外中断
- 确保合规性,追踪敏感数据的使用
- 优化数据流程,识别冗余或低效的数据流
总结一下,数据源和数据集成是数据仓库的基础,它们负责将分散的、异构的数据转化为一致的、可用的信息。通过ETL/ELT过程、数据质量管理和数据血缘分析,我们确保了进入数据仓库的数据是准确、及时和可追溯的。
接下来,让我们探讨数据仓库的第二个核心组成部分:数据存储。
2. 数据存储:数据仓库的"心脏"
数据存储是数据仓库的核心,它决定了如何组织和管理大量的结构化和半结构化数据。与传统的操作型数据库不同,数据仓库的存储结构设计着眼于快速的复杂查询和分析性能。
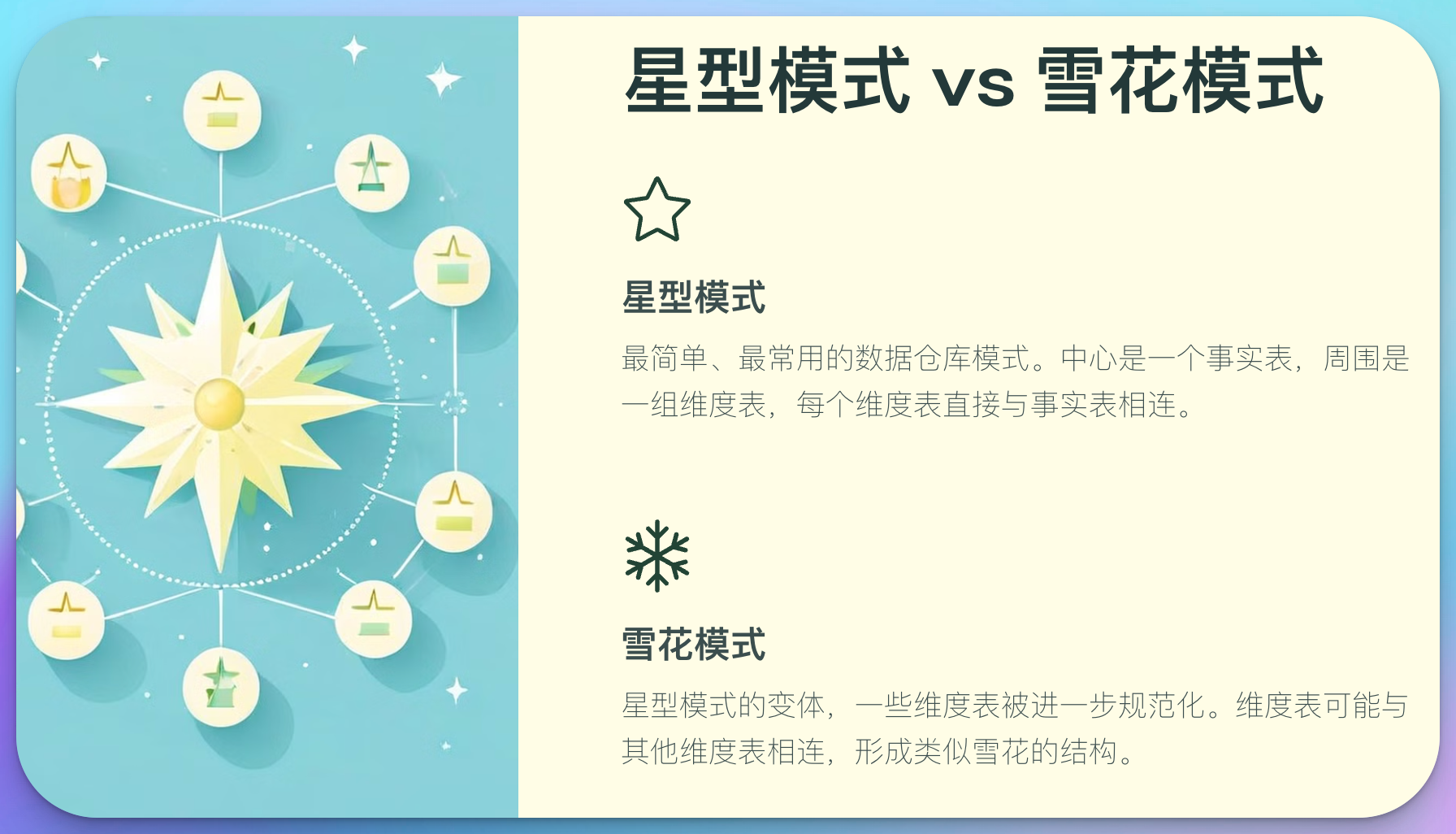
2.1 数据模型:星型模式vs雪花模式
在数据仓库中,最常见的两种数据模型是星型模式(Star Schema)和雪花模式(Snowflake Schema)。这两种模型都是围绕事实表和维度表构建的。
- 事实表:包含业务过程的数值度量(如销售额、数量等)
- 维度表:包含描述性属性(如产品类别、客户信息、时间等)
星型模式
星型模式是最简单和最常用的数据仓库模式。在这种模式中:
- 中心是一个事实表
- 围绕事实表的是一组维度表
- 每个维度表直接与事实表相连
让我们以一个电子商务数据仓库为例,展示一个简单的星型模式:
-- 创建日期维度表CREATETABLE dim_date (
date_key INTPRIMARYKEY,dateDATE,
day_of_week VARCHAR(10),monthVARCHAR(10),
quarter INT,yearINT);-- 创建产品维度表CREATETABLE dim_product (
product_key INTPRIMARYKEY,
product_id VARCHAR(20),
product_name VARCHAR(100),
category VARCHAR(50),
brand VARCHAR(50),
unit_price DECIMAL(10,2));-- 创建客户维度表CREATETABLE dim_customer (
customer_key INTPRIMARYKEY,
customer_id VARCHAR(20),
customer_name VARCHAR(100),
email VARCHAR(100),
city VARCHAR(50),
country VARCHAR(50));-- 创建销售事实表CREATETABLE fact_sales (
sale_key INTPRIMARYKEY,
date_key INT,
product_key INT,
customer_key INT,
quantity INT,
total_amount DECIMAL(12,2),FOREIGNKEY(date_key)REFERENCES dim_date(date_key),FOREIGNKEY(product_key)REFERENCES dim_product(product_key),FOREIGNKEY(customer_key)REFERENCES dim_customer(customer_key));
这个星型模式的优点是:
- 简单直观,易于理解和查询
- 查询性能通常很好,因为只需要很少的表连接
- 适合OLAP(联机分析处理)操作
雪花模式
雪花模式是星型模式的变体,其中一些维度表被进一步规范化。在雪花模式中:
- 维度表可能与其他维度表相连
- 形成一个类似雪花的结构
让我们扩展之前的例子,将产品维度规范化为雪花模式:
-- 创建产品类别维度表CREATETABLE dim_product_category (
category_key INTPRIMARYKEY,
category_name VARCHAR(50));-- 创建品牌维度表CREATETABLE dim_brand (
brand_key INTPRIMARYKEY,
brand_name VARCHAR(50),
manufacturer VARCHAR(100));-- 修改产品维度表CREATETABLE dim_product (
product_key INTPRIMARYKEY,
product_id VARCHAR(20),
product_name VARCHAR(100),
category_key INT,
brand_key INT,
unit_price DECIMAL(10,2),FOREIGNKEY(category_key)REFERENCES dim_product_category(category_key),FOREIGNKEY(brand_key)REFERENCES dim_brand(brand_key));
雪花模式的优点是:
- 减少数据冗余,节省存储空间
- 维护一致性更容易,因为每个属性只在一个地方存储
- 提供更细粒度的维度分析
然而,雪花模式也有一些缺点:
- 查询可能需要更多的表连接,影响性能
- 结构更复杂,不如星型模式直观
 选择星型模式还是雪花模式取决于具体的业务需求、查询模式和性能考虑。许多实际的数据仓库实现会在这两种模式之间寻找平衡,称为混合模式。
选择星型模式还是雪花模式取决于具体的业务需求、查询模式和性能考虑。许多实际的数据仓库实现会在这两种模式之间寻找平衡,称为混合模式。
2.2 分区和分桶
随着数据量的增长,表的大小可能变得非常大,影响查询性能。分区和分桶是两种常用的技术来改善大表的性能。
分区(Partitioning)
分区是将大表根据某个列(通常是日期)分割成更小的、更易管理的部分。每个分区可以看作是表的一个独立子集。
以我们的销售事实表为例,我们可以按月分区:
-- 在Hive中创建分区表CREATETABLE fact_sales (
sale_key INT,
product_key INT,
customer_key INT,
quantity INT,
total_amount DECIMAL(12,2))
PARTITIONED BY(yearINT,monthINT)
STORED AS PARQUET;-- 插入数据到分区INSERTINTO fact_sales PARTITION(year=2023,month=8)SELECT sale_key, product_key, customer_key, quantity, total_amount
FROM staging_sales
WHEREYEAR(sale_date)=2023ANDMONTH(sale_date)=8;
分区的好处包括:
- 查询性能提升:只需扫描相关分区而不是整个表
- 更容易管理数据生命周期:可以轻松地删除或归档旧的分区
分桶(Bucketing)
分桶是将数据基于某列的哈希值分配到固定数量的桶中。这有助于在大表上更均匀地分布数据,并可以提高某些类型查询的性能。
-- 在Hive中创建分桶表CREATETABLE fact_sales (
sale_key INT,
date_key INT,
product_key INT,
customer_key INT,
quantity INT,
total_amount DECIMAL(12,2))CLUSTEREDBY(customer_key)INTO32 BUCKETS
STORED AS ORC;
分桶的优势包括:
- 提高某些连接操作的效率
- 为抽样查询提供更好的性能

2.3 列式存储vs行式存储
传统的关系型数据库使用行式存储,而现代数据仓库通常采用列式存储或两者的结合。
行式存储
在行式存储中,一行中的所有列数据被存储在一起。这对于写入密集型的OLTP(联机事务处理)系统很有效,因为插入操作只需要写入一个位置。
| sale_id | date | product_id | quantity | amount |
|---------|------------|------------|----------|--------|
| 1 | 2023-08-01 | P001 | 2 | 100.00 |
| 2 | 2023-08-01 | P002 | 1 | 50.00 |
列式存储
在列式存储中,每一列的数据被存储在一起。这对于分析型查询非常有效,因为:
- 只需要读取查询所需的列
- 更好的压缩率,因为相同类型的数据存储在一起
列式存储的逻辑表示:
sale_id: [1, 2]
date: [2023-08-01, 2023-08-01]
product_id: [P001, P002]
quantity: [2, 1]
amount: [100.00, 50.00]
许多现代数据仓库和大数据技术如Apache Parquet、ORC(Optimized Row Columnar)以及某些MPP(大规模并行处理)数据库默认使用列式存储。
以下是使用Apache Spark读取Parquet文件并进行查询的示例:
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder \
.appName("Parquet Example") \
.getOrCreate()# 读取Parquet文件
df = spark.read.parquet("path/to/sales.parquet")# 注册为临时视图
df.createOrReplaceTempView("sales")# 执行查询
result = spark.sql("""
SELECT product_id, SUM(amount) as total_sales
FROM sales
WHERE date >= '2023-01-01'
GROUP BY product_id
ORDER BY total_sales DESC
LIMIT 10
""")# 显示结果
result.show()
这个查询在列式存储中会非常高效,因为:
- 它只需要读取
product_id,amount和date列 date列的过滤可以快速跳过不相关的数据块amount列的聚合操作可以利用向量化计算
2.4 数据压缩
数据压缩是数据仓库中另一个重要的存储优化技术。好的压缩可以:
- 减少存储成本
- 减少I/O,提高查询性能

不同的列式存储格式通常内置了高效的压缩算法。例如,Parquet使用了以下压缩技术:
- 运行长度编码(RLE):对于重复值很多的列非常有效
- 位打包:对于基数低的列(如枚举类型)很有效
- 字典编码:对于文本列很有效
- 通用压缩算法:如Snappy, Gzip, LZO等
以下是使用PySpark写入压缩的Parquet文件的示例:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DecimalType
# 创建SparkSession
spark = SparkSession.builder \.appName("Parquet Compression Example") \
.getOrCreate()# 定义schema
schema = StructType([
StructField("sale_id", StringType(),False),
StructField("date", StringType(),False),
StructField("product_id", StringType(),False),
StructField("quantity", IntegerType(),False),
StructField("amount", DecimalType(10,2),False)])# 创建示例数据
data =[("1","2023-08-01","P001",2,100.00),("2","2023-08-01","P002",1,50.00),# ... 更多数据 ...]# 创建DataFrame
df = spark.createDataFrame(data, schema)# 写入压缩的Parquet文件
df.write.parquet("path/to/compressed_sales.parquet", compression="snappy")# 读取并验证
read_df = spark.read.parquet("path/to/compressed_sales.parquet")
read_df.show()
在这个例子中,我们使用了Snappy压缩算法,它提供了良好的压缩率和解压缩速度的平衡,适合大多数数据仓库场景。
2.5 数据分层

在设计数据仓库存储时,一个常见的最佳实践是实施数据分层。典型的数据分层结构包括:
- 原始数据层(Raw Data Layer):也称为登陆区或暂存区- 存储来自源系统的原始数据,不做任何转换- 目的是快速加载数据,保留历史记录
- 基础数据层(Foundation Layer):也称为集成层或规范化层- 对原始数据进行清洗、标准化和集成- 解决数据质量问题,统一数据格式
- 核心数据层(Core Layer):也称为数据仓库层- 存储经过建模的、面向主题的数据- 通常使用星型或雪花模式组织数据
- 访问层(Access Layer):也称为数据集市层- 为特定的业务线或部门创建定制的数据视图- 可能包含预聚合的数据或OLAP多维数据集
以下是一个简化的Spark SQL脚本,展示了如何实现这种分层结构:
from pyspark.sql import SparkSession
from pyspark.sql.functions import*
spark = SparkSession.builder.appName("Data Layering Example").getOrCreate()# 1. 原始数据层
raw_sales = spark.read.format("csv").option("header","true").load("raw_sales_data.csv")
raw_sales.createOrReplaceTempView("raw_sales")# 2. 基础数据层
foundation_sales = spark.sql("""
SELECT
CAST(sale_id AS INT) AS sale_id,
TO_DATE(sale_date, 'yyyy-MM-dd') AS sale_date,
UPPER(product_id) AS product_id,
CAST(quantity AS INT) AS quantity,
CAST(amount AS DECIMAL(10,2)) AS amount
FROM raw_sales
WHERE sale_id IS NOT NULL AND sale_date IS NOT NULL
""")
foundation_sales.createOrReplaceTempView("foundation_sales")# 3. 核心数据层
core_sales = spark.sql("""
SELECT
s.sale_id,
d.date_key,
p.product_key,
s.quantity,
s.amount
FROM foundation_sales s
JOIN dim_date d ON s.sale_date = d.date
JOIN dim_product p ON s.product_id = p.product_id
""")
core_sales.createOrReplaceTempView("core_sales")# 4. 访问层
monthly_sales_summary = spark.sql("""
SELECT
d.year,
d.month,
p.category,
SUM(s.quantity) AS total_quantity,
SUM(s.amount) AS total_amount
FROM core_sales s
JOIN dim_date d ON s.date_key = d.date_key
JOIN dim_product p ON s.product_key = p.product_key
GROUP BY d.year, d.month, p.category
""")
monthly_sales_summary.write.mode("overwrite").saveAsTable("monthly_sales_summary")
这种分层方法提供了几个关键优势:
- 数据血缘更加清晰
- 更容易管理数据访问权限
- 提高了数据仓库的可维护性和可扩展性
- 支持不同用户群体的多样化需求
2.6 数据湖与数据仓库的融合

随着大数据技术的发展,许多组织开始采用数据湖来补充或部分替代传统的数据仓库。数据湖允许存储各种格式的数据(结构化、半结构化和非结构化),而不需要预先定义模式。
数据湖和数据仓库的融合导致了新的架构模式,如:
- 数据湖仓(Data Lakehouse):结合了数据湖的灵活性和数据仓库的管理能力
- Lambda架构:同时处理批处理和流处理数据
- Kappa架构:使用流处理引擎统一处理所有数据
以下是一个使用Delta Lake(一种开源存储层,为数据湖带来ACID事务)的简单示例,展示了数据湖仓的概念:
from pyspark.sql import SparkSession
from delta import*# 创建SparkSession,启用Delta Lake支持
spark = SparkSession.builder \
.appName("Delta Lake Example") \
.config("spark.jars.packages","io.delta:delta-core_2.12:1.0.0") \
.config("spark.sql.extensions","io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog","org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()# 读取原始数据
raw_data = spark.read.csv("raw_data.csv", header=True)# 写入Delta表
raw_data.write.format("delta").save("/path/to/delta/table")# 读取Delta表
delta_df = spark.read.format("delta").load("/path/to/delta/table")# 执行更新操作from delta.tables import*
deltaTable = DeltaTable.forPath(spark,"/path/to/delta/table")# 更新数据
deltaTable.update(
condition ="product_id = 'P001'",set={"price":"price * 1.1"})# 执行时间旅行查询
df_at_version_1 = spark.read.format("delta").option("versionAsOf",1).load("/path/to/delta/table")# 查看表的历史
deltaTable.history().show()
这个例子展示了Delta Lake如何为数据湖带来事务支持、更新能力和时间旅行等传统数据仓库的特性,同时保留了数据湖的灵活性。
总结一下,数据存储是数据仓库的核心组件,它决定了如何有效地组织和管理大量数据。通过选择适当的数据模型、使用分区和分桶策略、采用列式存储和压缩技术、实施数据分层,以及融合数据湖的概念,我们可以构建一个高性能、可扩展且灵活的数据存储系统,为数据分析和决策支持提供坚实的基础。
接下来,让我们探讨数据仓库的第三个核心组成部分:元数据管理。
3. 元数据管理:数据仓库的"大脑"
元数据,简单来说就是"关于数据的数据"。在数据仓库中,元数据管理扮演着至关重要的角色,它就像是数据仓库的"大脑",协调和控制着整个系统的运作。良好的元数据管理可以提高数据的可发现性、可理解性和可信度,从而增强数据仓库的整体价值。
3.1 元数据的类型
在数据仓库中,我们通常关注三种类型的元数据:
- 技术元数据:- 描述数据的技术特征- 例如:表结构、列数据类型、索引、分区信息等
- 业务元数据:- 描述数据的业务含义和上下文- 例如:数据定义、业务规则、数据所有者、数据敏感度等
- 操作元数据:- 描述数据仓库的运行状况和使用情况- 例如:ETL作业执行记录、数据加载时间、查询性能统计等

3.2 元数据仓库
为了有效管理这些元数据,许多组织会建立一个专门的元数据仓库。元数据仓库集中存储和管理所有与数据仓库相关的元数据,为数据治理、数据质量管理和数据血缘分析提供基础。
以下是一个简化的元数据仓库模型示例:
-- 创建数据资产表CREATETABLE data_assets (
asset_id INTPRIMARYKEY,
asset_name VARCHAR(100),
asset_type VARCHAR(50),
owner VARCHAR(100),
description TEXT,
created_date DATE,
last_updated DATE);-- 创建列信息表CREATETABLE column_info (
column_id INTPRIMARYKEY,
asset_id INT,
column_name VARCHAR(100),
data_type VARCHAR(50),
is_nullable BOOLEAN,
description TEXT,FOREIGNKEY(asset_id)REFERENCES data_assets(asset_id));-- 创建数据血缘表CREATETABLE data_lineage (
lineage_id INTPRIMARYKEY,
source_asset_id INT,
target_asset_id INT,
transformation_rule TEXT,FOREIGNKEY(source_asset_id)REFERENCES data_assets(asset_id),FOREIGNKEY(target_asset_id)REFERENCES data_assets(asset_id));-- 创建业务规则表CREATETABLE business_rules (
rule_id INTPRIMARYKEY,
asset_id INT,
rule_name VARCHAR(100),
rule_definition TEXT,FOREIGNKEY(asset_id)REFERENCES data_assets(asset_id));-- 创建作业执行记录表CREATETABLE job_execution_log (
execution_id INTPRIMARYKEY,
job_name VARCHAR(100),
start_time TIMESTAMP,
end_time TIMESTAMP,statusVARCHAR(20),
records_processed INT,
error_message TEXT);
这个简化的模型展示了如何组织不同类型的元数据。在实际实现中,元数据仓库的模型可能会更加复杂,包含更多的实体和关系。
3.3 元数据管理工具
虽然可以自建元数据管理系统,但很多组织选择使用专门的元数据管理工具。这些工具通常提供了丰富的功能,如自动元数据抽取、数据血缘可视化、数据目录服务等。一些流行的元数据管理工具包括:
- Apache Atlas
- Collibra
- Alation
- Informatica Enterprise Data Catalog
- AWS Glue Data Catalog
以下是使用Apache Atlas API进行元数据管理的Python示例:
import requests
import json
ATLAS_URL ="http://localhost:21000/api/atlas/v2"
HEADERS ={"Content-Type":"application/json","Accept":"application/json"}defcreate_table_entity(table_name, columns, database_name="default"):
entity ={"entity":{"typeName":"hive_table","attributes":{"name": table_name,"qualifiedName":f"{database_name}.{table_name}@cluster","description":f"Table {table_name} in {database_name} database","owner":"data_team","columns": columns
}}}
response = requests.post(f"{ATLAS_URL}/entity", headers=HEADERS, data=json.dumps(entity))return response.json()defget_lineage(guid):
response = requests.get(f"{ATLAS_URL}/lineage/{guid}", headers=HEADERS)return response.json()# 创建表元数据
columns =[{"typeName":"hive_column","attributes":{"name":"id","dataType":"int"}},{"typeName":"hive_column","attributes":{"name":"name","dataType":"string"}},{"typeName":"hive_column","attributes":{"name":"age","dataType":"int"}}]
result = create_table_entity("users", columns)print("Created table metadata:", result)# 获取数据血缘
lineage = get_lineage(result["guid"])print("Table lineage:", lineage)
这个例子展示了如何使用Apache Atlas的API创建表元数据和获取数据血缘信息。在实际应用中,你可能需要更复杂的逻辑来处理认证、错误处理等。
3.4 数据目录
数据目录是元数据管理的一个重要应用。它为数据消费者(如数据分析师、数据科学家)提供了一个中心化的平台,用于发现、理解和访问数据资产。一个好的数据目录应该提供以下功能:
- 数据资产搜索2. 数据资产详情查看
- 数据血缘可视化
- 数据质量评分
- 数据使用统计
- 数据访问请求流程
 以下是一个简化的数据目录前端界面的React组件示例,展示了如何实现数据资产搜索和详情展示功能:
以下是一个简化的数据目录前端界面的React组件示例,展示了如何实现数据资产搜索和详情展示功能:
import React, { useState, useEffect } from 'react';
import { Input, Table, Modal, Descriptions } from 'antd';
import { SearchOutlined } from '@ant-design/icons';
const DataCatalog = () => {
const [searchTerm, setSearchTerm] = useState('');
const [dataAssets, setDataAssets] = useState([]);
const [selectedAsset, setSelectedAsset] = useState(null);
const [isModalVisible, setIsModalVisible] = useState(false);
useEffect(() => {
// 在实际应用中,这里应该调用后端API获取数据资产
setDataAssets([
{ id: 1, name: 'users', type: 'table', owner: 'user_team' },
{ id: 2, name: 'orders', type: 'table', owner: 'order_team' },
{ id: 3, name: 'products', type: 'table', owner: 'product_team' },
]);
}, []);
const columns = [
{ title: 'Name', dataIndex: 'name', key: 'name' },
{ title: 'Type', dataIndex: 'type', key: 'type' },
{ title: 'Owner', dataIndex: 'owner', key: 'owner' },
];
const handleSearch = (value) => {
setSearchTerm(value);
// 在实际应用中,这里应该调用后端API进行搜索
};
const handleRowClick = (record) => {
setSelectedAsset(record);
setIsModalVisible(true);
};
return (
<div>
<Input
placeholder="Search data assets"
prefix={<SearchOutlined />}
onChange={(e) => handleSearch(e.target.value)}
style={{ marginBottom: 16 }}
/>
<Table
columns={columns}
dataSource={dataAssets}
onRow={(record) => ({
onClick: () => handleRowClick(record),
})}
/>
<Modal
title="Data Asset Details"
visible={isModalVisible}
onCancel={() => setIsModalVisible(false)}
footer={null}
>
{selectedAsset && (
<Descriptions bordered>
<Descriptions.Item label="Name">{selectedAsset.name}</Descriptions.Item>
<Descriptions.Item label="Type">{selectedAsset.type}</Descriptions.Item>
<Descriptions.Item label="Owner">{selectedAsset.owner}</Descriptions.Item>
{/* 在实际应用中,这里应该显示更多详细信息 */}
</Descriptions>
)}
</Modal>
</div>
);
};
export default DataCatalog;
这个React组件展示了一个简单的数据目录界面,允许用户搜索数据资产并查看详情。在实际应用中,你需要将其与后端API集成,添加更多功能如数据血缘图、数据质量评分等。
总结一下,元数据管理是数据仓库的"大脑",它不仅提供了对数据资产的全面了解,还为数据治理、数据质量管理和数据血缘分析提供了基础。通过实施强大的元数据管理系统和数据目录,组织可以显著提高数据的可发现性、可理解性和可信度,从而充分发挥数据仓库的价值。
最后,让我们简要介绍数据仓库的第四个核心组成部分:数据访问和分析工具。
4. 数据访问和分析工具:数据仓库的"出口"
数据访问和分析工具是数据仓库的"出口",它们使得最终用户能够从数据仓库中提取价值。这些工具大致可以分为以下几类:
- SQL查询工具: 如MySQL Workbench, pgAdmin, DBeaver等。
- BI(商业智能)工具: 如Tableau, Power BI, Looker等。
- 数据科学工具: 如Jupyter Notebook, RStudio等。
- 自定义应用: 使用各种编程语言和框架开发的定制化应用。
这些工具允许用户以不同的方式和不同的深度访问和分析数据仓库中的数据,从而支持从日常报告到高级数据科学项目的各种需求。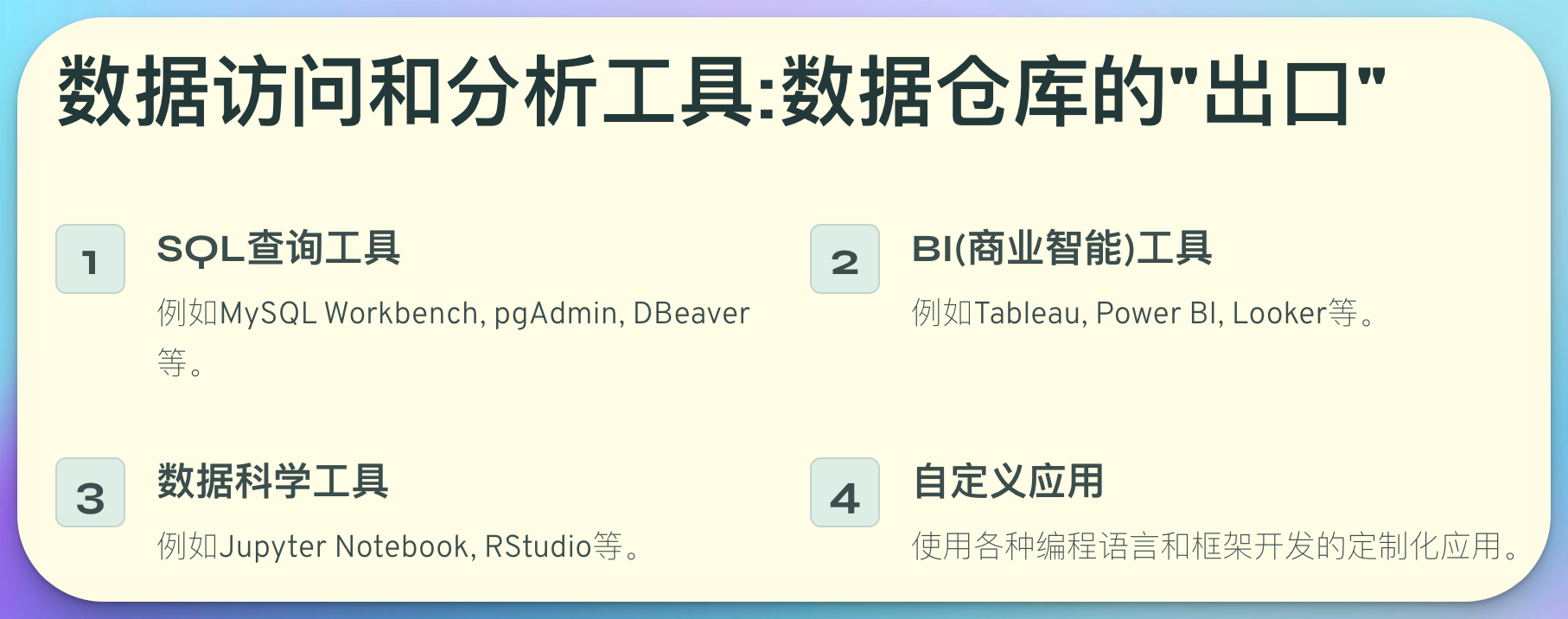
例如,以下是使用Python的SQLAlchemy库连接到数据仓库并执行查询的示例:
from sqlalchemy import create_engine, text
import pandas as pd
# 创建数据库连接
engine = create_engine('postgresql://username:password@host:port/database')# 执行SQL查询
query = text("""
SELECT
p.category,
DATE_TRUNC('month', s.sale_date) as month,
SUM(s.quantity) as total_quantity,
SUM(s.amount) as total_amount
FROM
sales s
JOIN products p ON s.product_id = p.product_id
WHERE
s.sale_date >= '2023-01-01'
GROUP BY
p.category, DATE_TRUNC('month', s.sale_date)
ORDER BY
p.category, month
""")with engine.connect()as conn:
result = pd.read_sql(query, conn)# 使用pandas进行进一步分析print(result.head())# 计算每个类别的总销售额
category_total = result.groupby('category')['total_amount'].sum().sort_values(descending=True)print("\nTop categories by total sales:")print(category_total)# 绘制销售趋势图import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))for category in result['category'].unique():
category_data = result[result['category']== category]
plt.plot(category_data['month'], category_data['total_amount'], label=category)
plt.xlabel('Month')
plt.ylabel('Total Sales Amount')
plt.title('Sales Trend by Category')
plt.legend()
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
这个示例展示了如何连接到数据仓库,执行SQL查询,然后使用Python的数据分析库(如pandas和matplotlib)进行进一步的分析和可视化。
结语:
通过深入探讨数据仓库的四大核心组成部分:数据源和数据集成、数据存储、元数据管理以及数据访问和分析工具,我们可以看到现代数据仓库是如何将海量、复杂的数据转化为有价值的业务洞察的。每个组成部分都扮演着重要的角色,共同构成了一个强大、灵活且高效的数据管理和分析系统。
随着技术的不断发展,数据仓库也在持续演进。从传统的企业数据仓库到新兴的云数据仓库,再到数据湖仓等混合架构,组织有了更多选择来构建适合自己需求的数据基础设施。无论采用何种具体实现,理解这些核心组成部分及其相互关系,对于设计、实施和管理成功的数据仓库项目至关重要。
版权归原作者 数据小羊 所有, 如有侵权,请联系我们删除。