
一、需求及技术介绍
在**金融投资领域**,了解股票市场的历史资金数据对于制定投资策略和做出明智的决策至关重要。这些数据包含着股票的交易量、资金流向、持股比例等关键指标,能够为投资者提供有价值的参考和分析依据。
通过利用 **Selenium **模拟浏览器行为。编写了一个简单而强大的 Python 程序,自动爬取某个股票网站的历史资金数据。
1. 网站首页
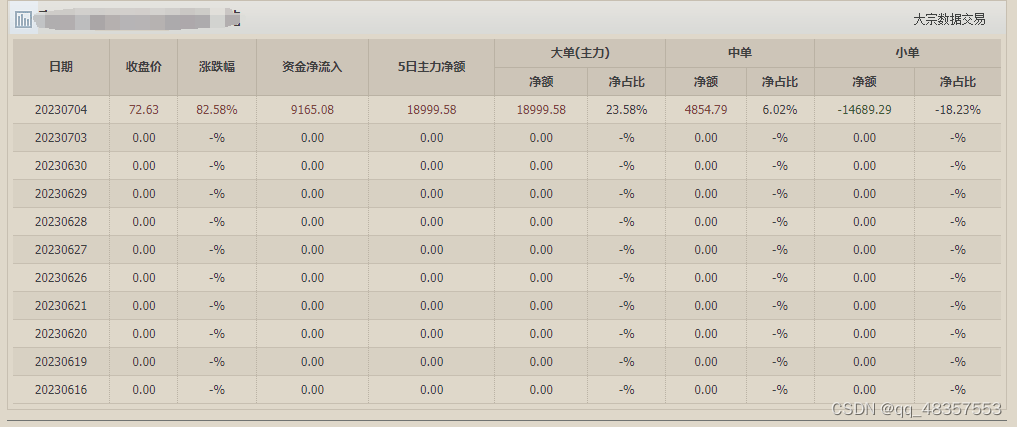
2. 爬取的表格数据
**Python **的优势在于其简洁而强大的语法,以及丰富的库和模块。这使得编写爬虫程序变得非常便捷。Python 提供了丰富的网络爬虫库,如 **Requests**、**Scrapy **和 **Selenium **等,使我们能够以最简单和高效的方式进行数据爬取。此外,**Python **的易读性和大量的文档资源,使得我们能够轻松理解和维护自己编写的爬虫程序。
**Selenium :**一个功能强大的自动化测试工具,它能够模拟用户在浏览器中的操作,如点击按钮、填写表单、获取页面内容等。通过使用 **Selenium**,我们能够以真实浏览器的方式访问网页,并提取所需的历史资金数据。而且Selenium 能够解决某些网站的动态反爬技术,如动态加载数据、异步请求等。
**Pandas **:Pandas的**read_html()**方法能迅速抓取到网页表格中的数据。Pandas 是一个强大的数据处理工具,它提供了各种功能和方法,用于数据的清洗、整理、筛选、计算统计指标等操作。使用 Pandas,我们可以轻松地对爬取到的数据进行进一步的处理,使其更易于理解和分析。
通过结合 **Selenium **和 **Python **的优势,我们可以轻松地获取股票网站的历史资金数据,并利用 Pandas 对数据进行处理和分析。这为金融投资者提供了强有力的工具,帮助他们更好地理解市场走势和做出明智的投资决策。无论是初学者还是经验丰富的投资者,都能从这个简单而实用的 **Python **程序中受益。
二、实现步骤
1. 导入必要的库和模块
import time
from selenium import webdriver
from selenium.common import StaleElementReferenceException
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from lxml import etree
import pandas as pd
2. 设置Pandas的显示格式
pd.set_option('display.max_columns', None) # 显示完整的列
pd.set_option('display.max_rows', None) # 显示完整的行
pd.set_option('display.expand_frame_repr', False)
注意,这些设置是全局的,将影响之后所有使用 Pandas 的代码中的 DataFrame 显示效果。
3. 创建 WebDriver 对象
def get_browser():
# 2.创建浏览器操作对象
path = Service('msedgedriver.exe')
# 不会自动关闭
options = webdriver.EdgeOptions()
options.add_argument(
'User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57')
# 使浏览器的window.navigator.webdriver的属性为false
# option.add_experimental_option('excludeSwitches',['enable-automation'])
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument("--headless") # 开启无界面模式
options.add_experimental_option('detach', False)
browser = webdriver.Edge(service=path, options=options)
return browser
上述代码封把获取WebDriver 对象的代码封装为**get_browser()**,降低代码冗余,供后面爬取数据使用。
4. 爬取及分析数据
4.1 过程分析
**4.1.1 **打开网页源代码,点击每个股票代码,爬取其对应的url,把所有url封装到一个集合中
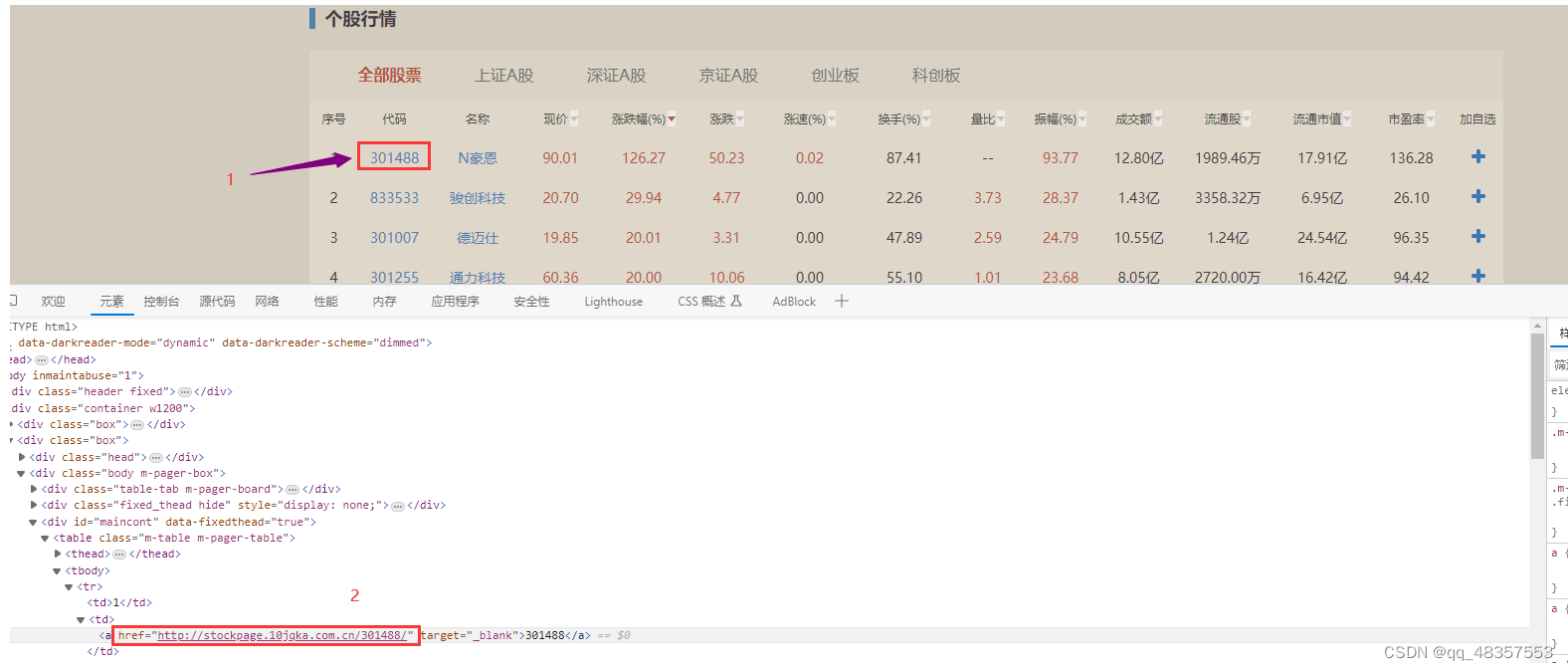
# 获取每页每个股票的url
def get_url_list(browser):
# 3.访问网站
url = 'http://q.10jqka.com.cn/#refCountId=www_50a1b74a_693'
browser.get(url)
# 获取总页数
page_info = browser.find_element(By.XPATH, '//span[@class="page_info"]').text
# 获取到的数据是 1/258 ,所以需要进行切割
page = int(page_info.split('/')[1])
list_all = []
i = 1
while (i < page + 2):
content = browser.page_source
time.sleep(1)
tree = etree.HTML(content)
# 获取href、名称、代码
url_list = tree.xpath('//div[@id="maincont"]//a[@target="_blank"]/@href')
# 转换为集合,去重
url_list = list(set([x for x in url_list]))
for x in url_list:
list_all.append(x)
try:
try:
# 下拉到页面底端
time.sleep(0.5)
js_buttom = "var q=document.documentElement.scrollTop=10000"
browser.execute_script(js_buttom)
# 获取下一页的按钮
next = browser.find_element(By.XPATH, '//*[text()="下一页"]')
time.sleep(1)
next.click()
except StaleElementReferenceException:
# 获取下一页的按钮
next = browser.find_element(By.XPATH, '//*[text()="下一页"]')
time.sleep(1)
next.click()
except:
break
print('当前为:第%d页' % i)
if (i == 258):
break
i = i + 1
list_all = list(set([x for x in list_all]))
return list_all
** 4.1.2** 点击每个股票代码会跳转到下面页面,然后我们通过XPATH定位到资金流向,并点击它。
find_element(By.XPATH, '//div[@id="in_menu"]//a[@stat="f10_sp_zjlx"]')
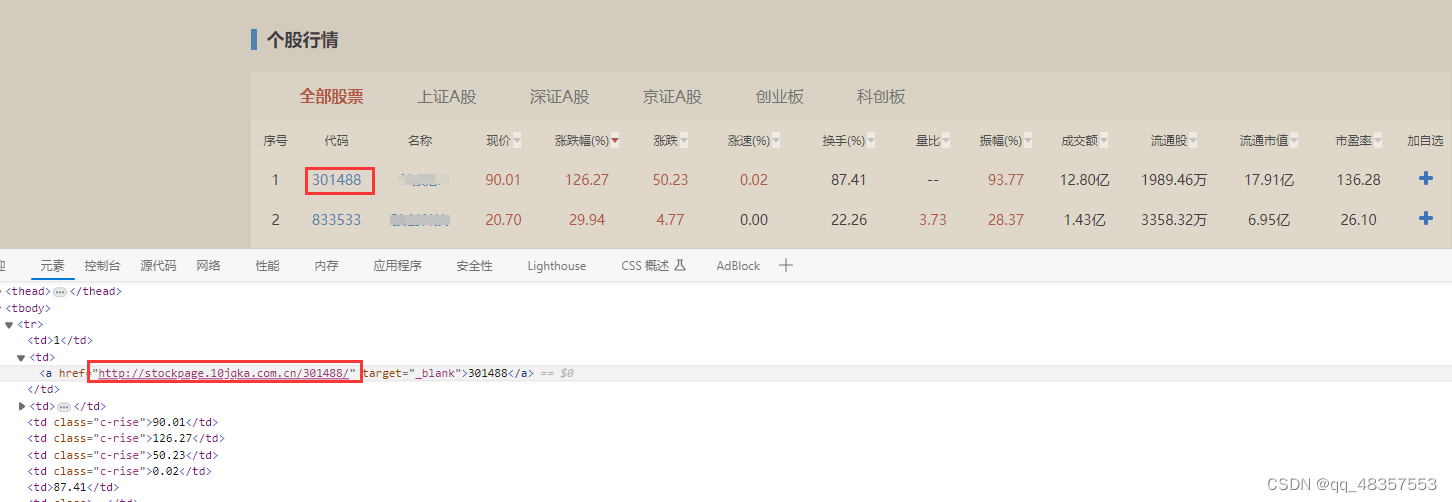
4.1.3 进入到点击资金流向之后的页面如下,此时表格的数据就是我们需要爬取的数据。
# 访问股票的url,点击资金流向,再获取当前url的页面源码,解析数据并写到csv中
def get_content(browser, url_list):
df1 = pd.DataFrame()
for url in url_list:
browser.get(url)
time.sleep(1)
button = browser.find_element(By.XPATH, '//div[@id="in_menu"]//a[@stat="f10_sp_zjlx"]')
button.click()
time.sleep(2)
# 下拉到页面底端
js_buttom = "var q=document.documentElement.scrollTop=10000"
browser.execute_script(js_buttom)
# 获取跳转后的url
new_url = browser.current_url
browser.get(new_url)
content = browser.page_source
time.sleep(1.5)
# 获取每页表格内容
df = pd.DataFrame()
df = df._append(pd.read_html(content), ignore_index=True)
# 清洗数据
# 重命名表格列名
df.columns = ["1", "日期", "收盘价", "涨跌幅", "资金净流入", "5日主力净额", "大单(主力) 净额",
"大单(主力) 净占比", "中单 净额", "中单 净占比", "小单 净额", "小单 净占比", "2", "3"]
# 删除指定索引的行
df.drop(index=[0, 1, 2, 3, 4, 5], axis=0, inplace=True)
# 删除最后两行、列名为1,2,3的列
df.drop(df.tail(2).index, inplace=True)
df.drop(["1", "2", "3"], axis=1, inplace=True)
# 格式化日期列
df['日期'] = df['日期'].apply(lambda x: format(int(x)))
# 根据日期去重
df.drop_duplicates(subset='日期', keep='first', inplace=True)
df.to_csv('data.csv', mode='a', header=True, index=None)
df1.to_csv('data.csv', mode='a')
5. 运行程序
if __name__ == '__main__':
browser = get_browser()
list_all = get_url_list(browser)
print(list_all)
get_content(browser=browser, url_list=list_all)
三、总结
本文介绍了使用 Selenium 和 Pandas 进行数据爬取和处理的方法。首先,通过使用 Selenium 的浏览器自动化功能,我们可以模拟人类的浏览行为,实现对动态网页和反爬机制的克服。Selenium 提供了丰富的功能,可以控制浏览器的打开、页面导航、元素定位、数据提取等操作,使得爬取网页数据变得更加简单和可靠。
希望本文对读者在数据爬取和处理方面有所帮助,为读者提供有价值的内容。祝你在数据爬取和处理的旅程中取得成功!
文末:本文仅供学习使用,不支持任何商业或投资用途!
本文转载自: https://blog.csdn.net/qq_48357553/article/details/131537689
版权归原作者 Jony.. 所有, 如有侵权,请联系我们删除。
版权归原作者 Jony.. 所有, 如有侵权,请联系我们删除。