
一、概念
2、应用场景
- 异步处理
- 系统解耦
- 流量削峰
- 日志处理
3、消息队列的两种模式
点对点模式
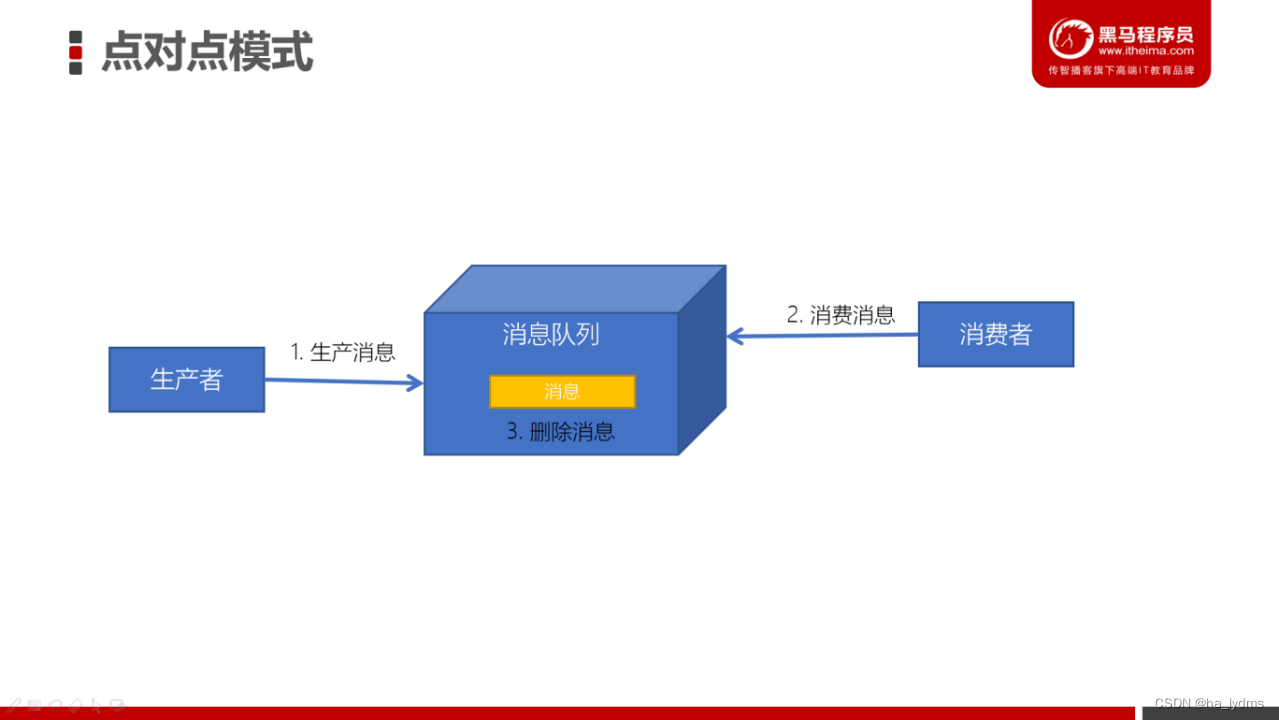
消息发送者生产消息发送到消息队列中,然后消息接收者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
点对点模式特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)。
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
发布订阅模式
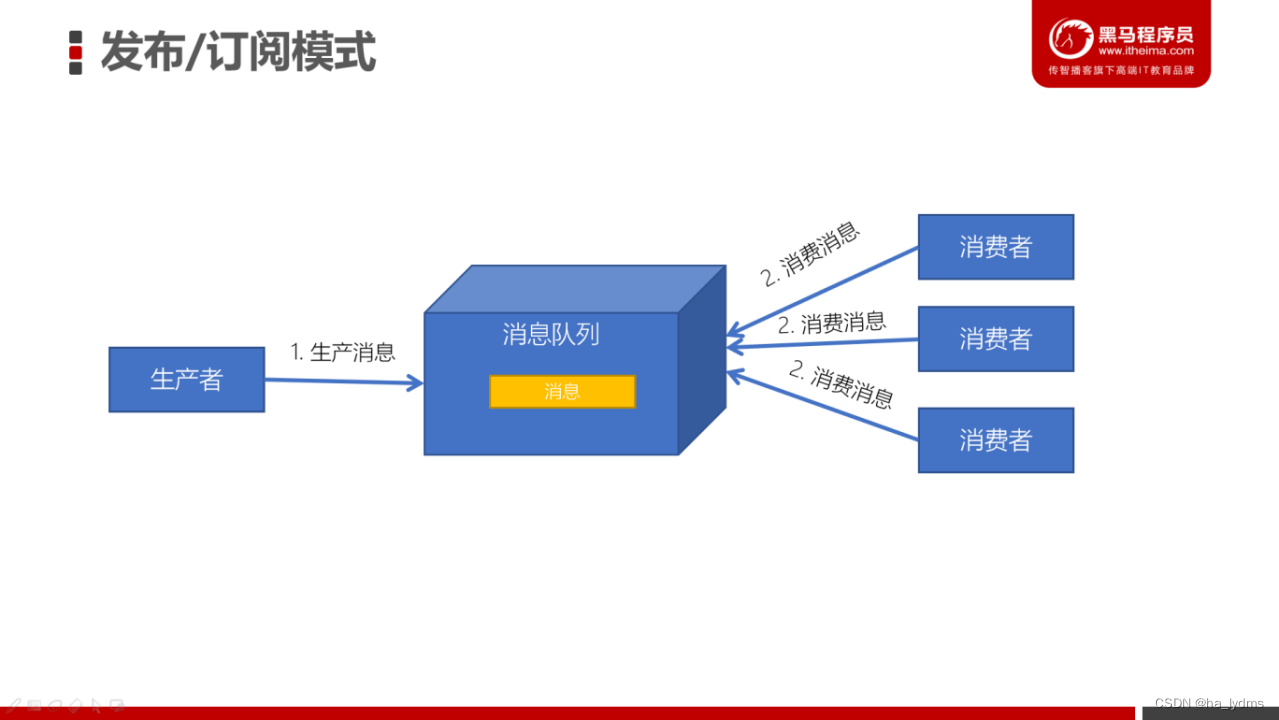
发布/订阅模式特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
4、Kafka
Apache Kafka是一个分布式流平台。一个分布式的流平台应该包含3点关键的能力:
- 发布和订阅流数据流,类似于消息队列或者是企业消息传递系统
- 以容错的持久化方式存储数据流
- 处理数据流
- Producers:可以有很多的应用程序,将消息数据放入到Kafka集群中。
- Consumers:可以有很多的应用程序,将消息数据从Kafka集群中拉取出来。
- Connectors:Kafka的连接器可以将数据库中的数据导入到Kafka,也可以将Kafka的数据导出到数据库中。
- Stream Processors:流处理器可以Kafka中拉取数据,也可以将数据写入到Kafka中。
5、Kafka优势
特性ActiveMQRabbitMQKafkaRocketMQ所属社区/公司ApacheMozilla Public LicenseApacheApache/Ali成熟度成熟成熟成熟比较成熟生产者-消费者模式支持支持支持支持发布-订阅支持支持支持支持REQUEST-REPLY支持支持-支持API完备性高高高低(静态配置)多语言支持支持JAVA优先语言无关支持,JAVA优先支持单机呑吐量万级(最差)万级十万级十万级(最高)消息延迟-微秒级毫秒级-可用性高(主从)高(主从)非常高(分布式)高消息丢失-低理论上不会丢失-消息重复-可控制理论上会有重复-事务支持不支持支持支持文档的完备性高高高中提供快速入门有有有无首次部署难度-低中高
二、架构
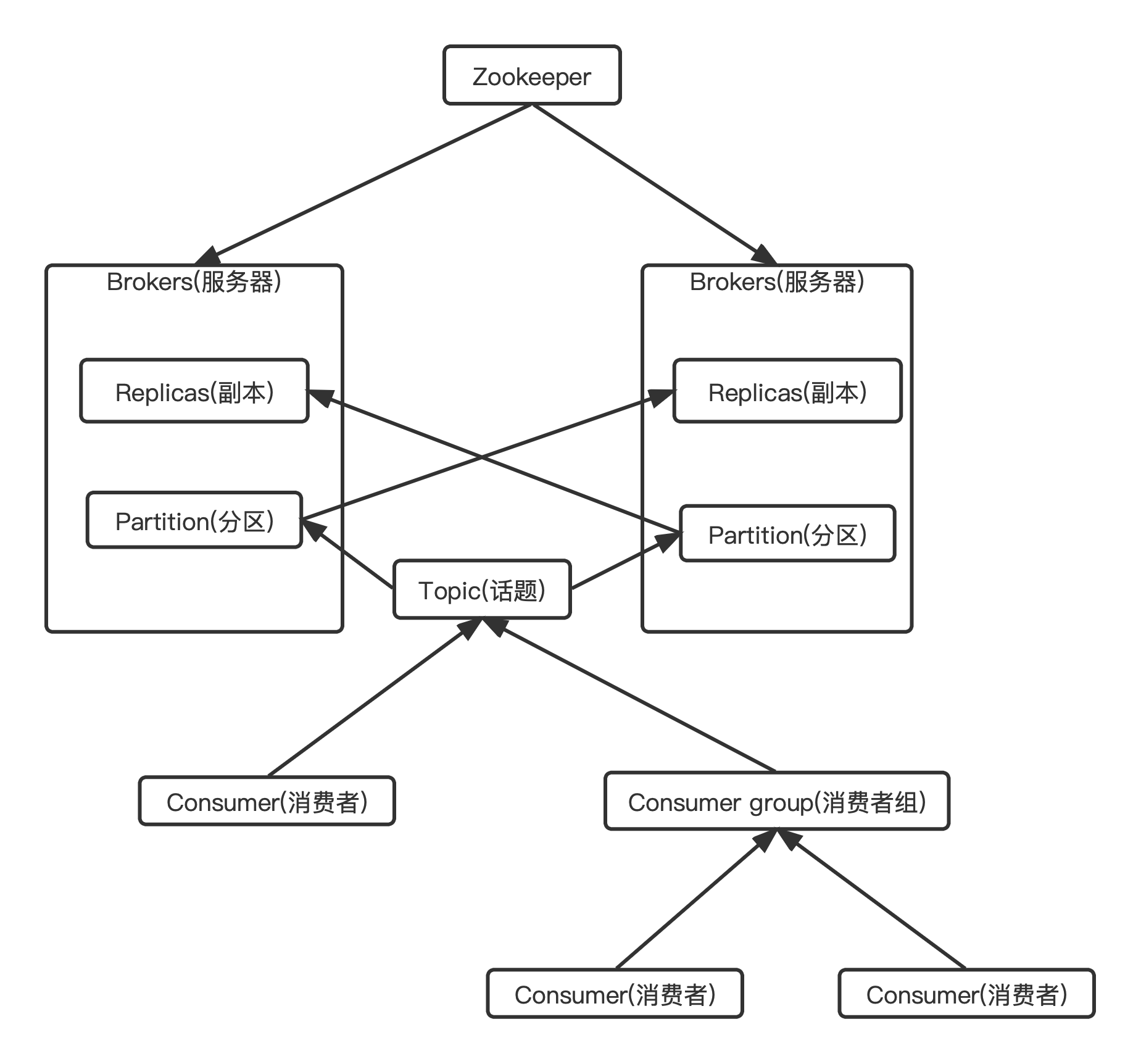
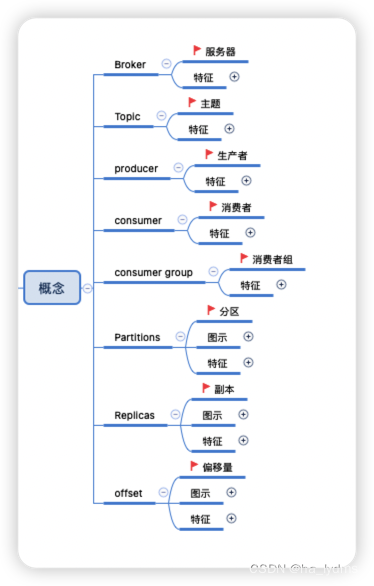
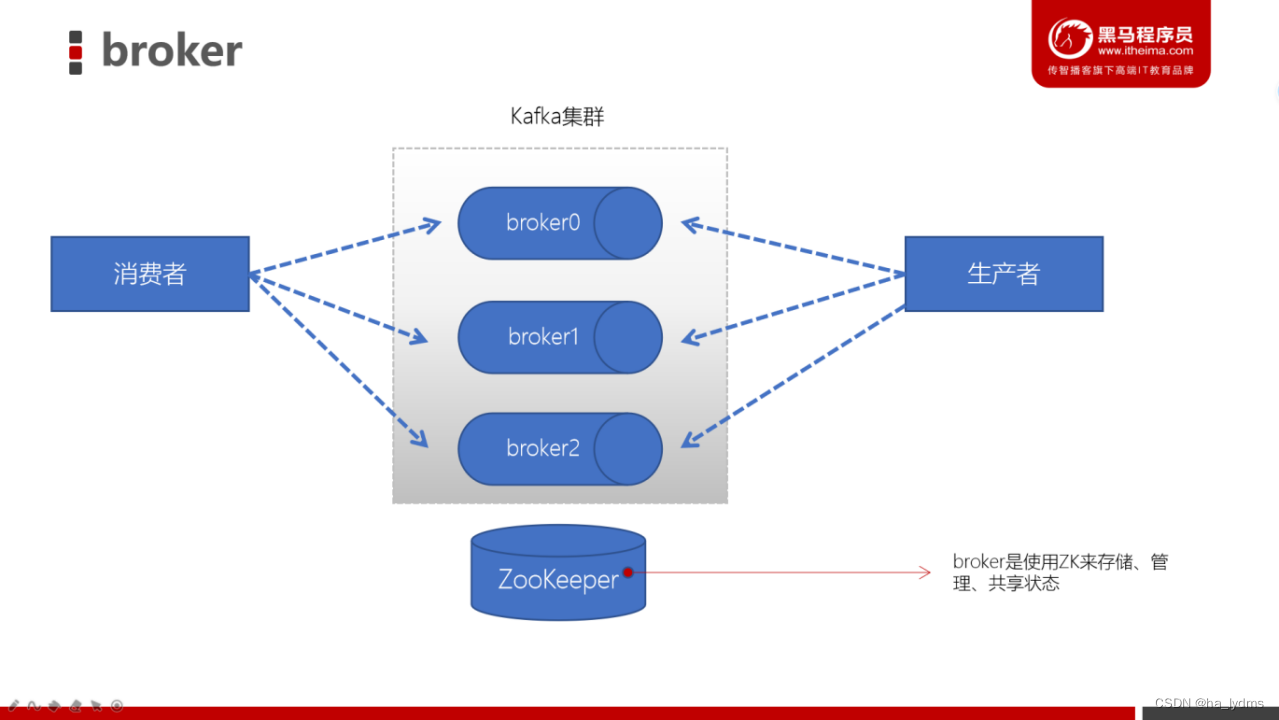
1、Zookeeper
- ZK用来管理和协调broker,并且存储了Kafka的元数据(例如:有多少topic、partition、consumer)
- ZK服务主要用于通知生产者和消费者Kafka集群中有新的broker加入、或者Kafka集群中出现故障的broker。
PS:Kafka正在逐步想办法将ZooKeeper剥离,维护两套集群成本较高,社区提出KIP-500就是要替换掉ZooKeeper的依赖。“Kafka on Kafka”——Kafka自己来管理自己的元数据
2、Broker(服务器)
服务器概念
- 一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错
- broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态
- 一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能
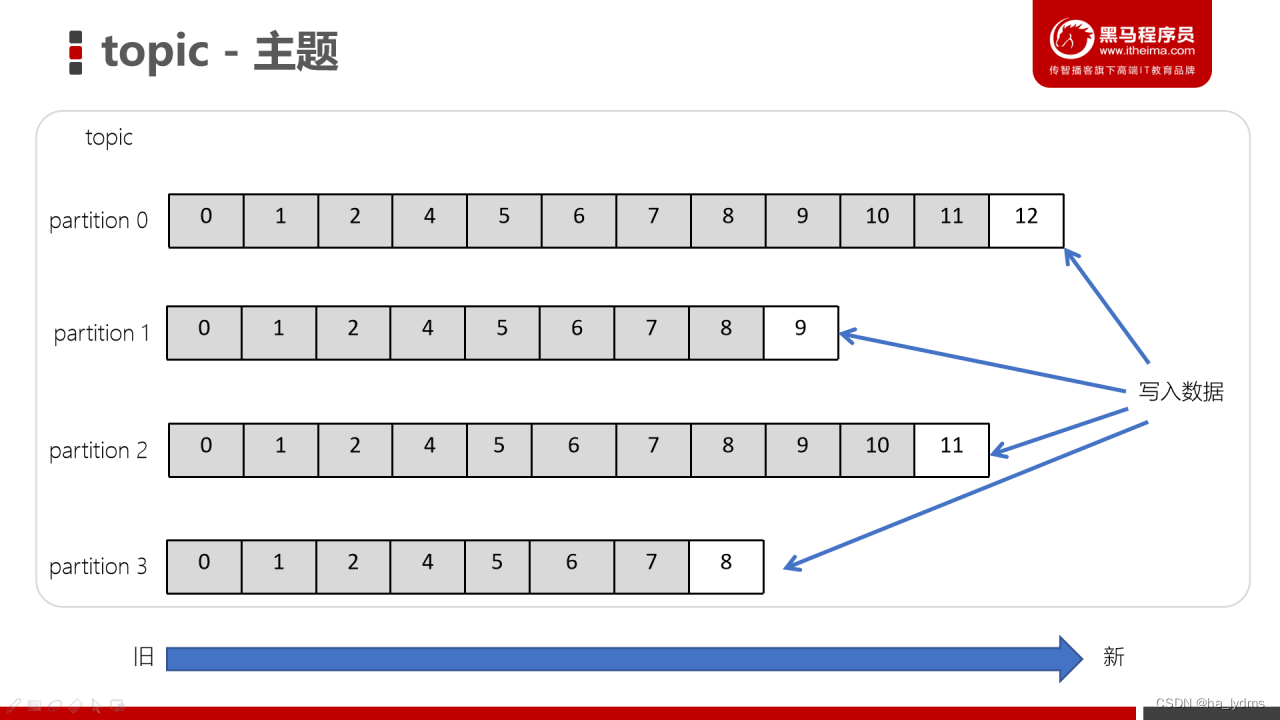
3、Topic(主题)
- 主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据
- Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制
- 在主题中的消息是有结构的,一般一个主题包含某一类消息
- 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
4、producer(生产者)
生产者负责将数据推送给broker的topic
5、consumer(消费者)
消费者负责从broker的topic中拉取数据,并自己进行处理
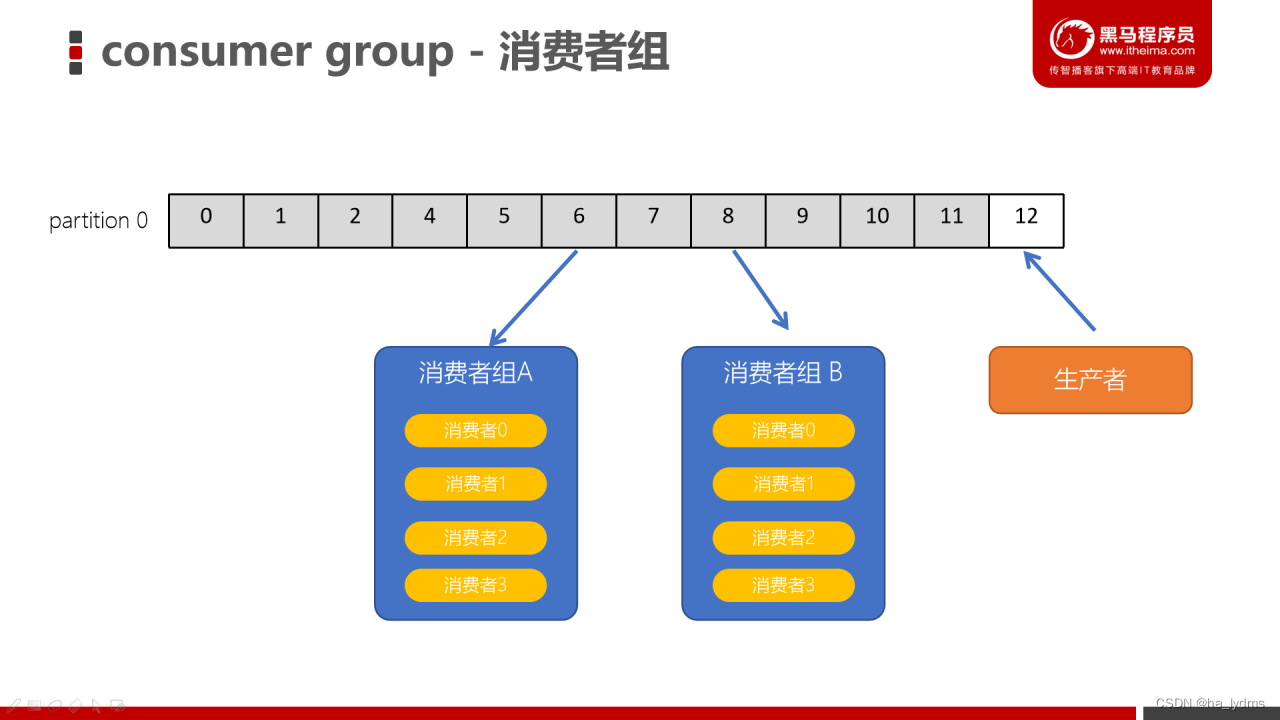
6、consumer group(消费者组)
- consumer group是kafka提供的可扩展且具有容错性的消费者机制
- 一个消费者组可以包含多个消费者
- 一个消费者组有一个唯一的ID(group Id)
- 组内的消费者一起消费主题的所有分区数据
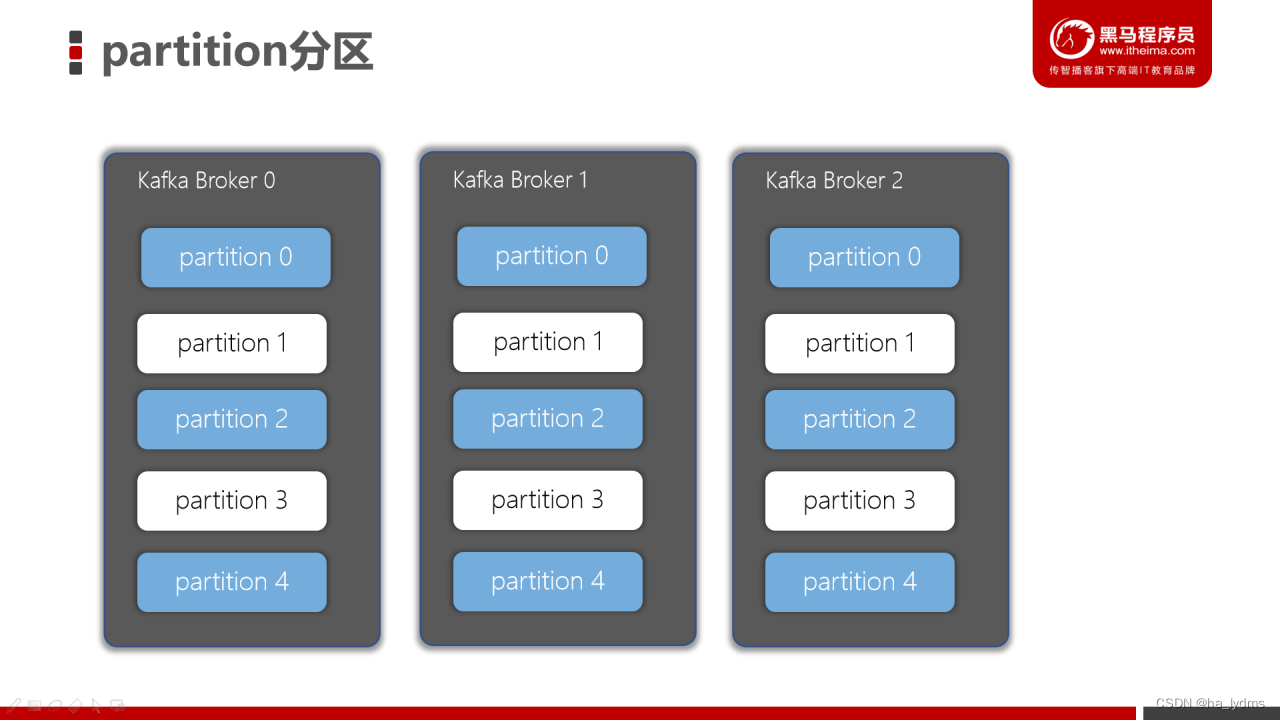
7、分区(Partitions)
在Kafka集群中,主题被分为多个分区。
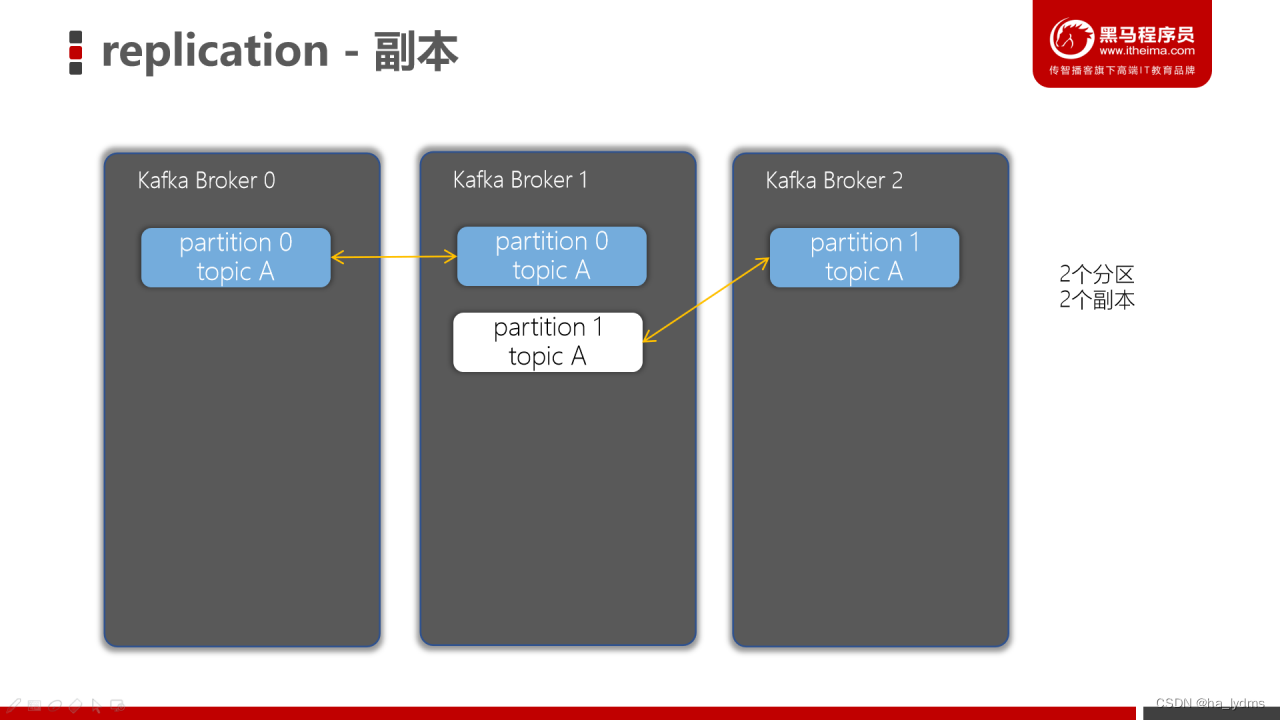
8、副本(Replicas)
- 副本可以确保某个服务器出现故障时,确保数据依然可用
- 在Kafka中,一般都会设计副本的个数>1
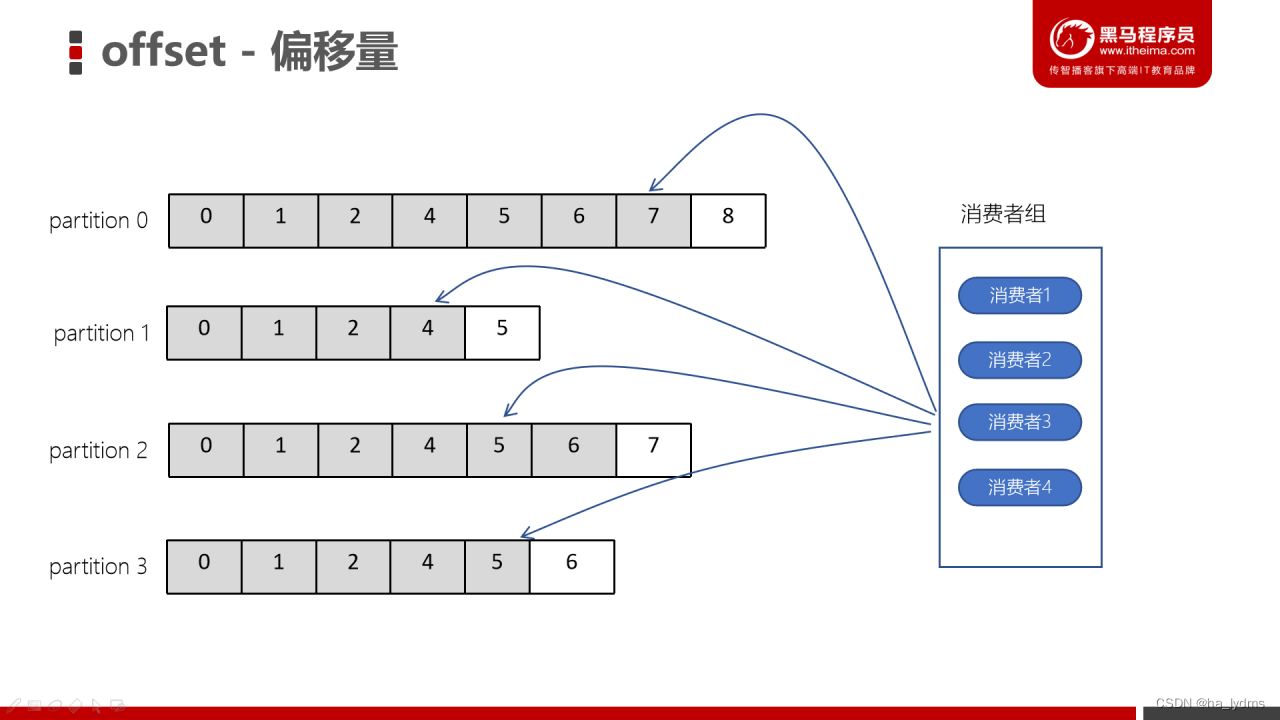
9、offset(偏移量)
- offset记录着下一条将要发送给Consumer的消息的序号
- 默认Kafka将offset存储在ZooKeeper中
- 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset
- 偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
三、幂等性
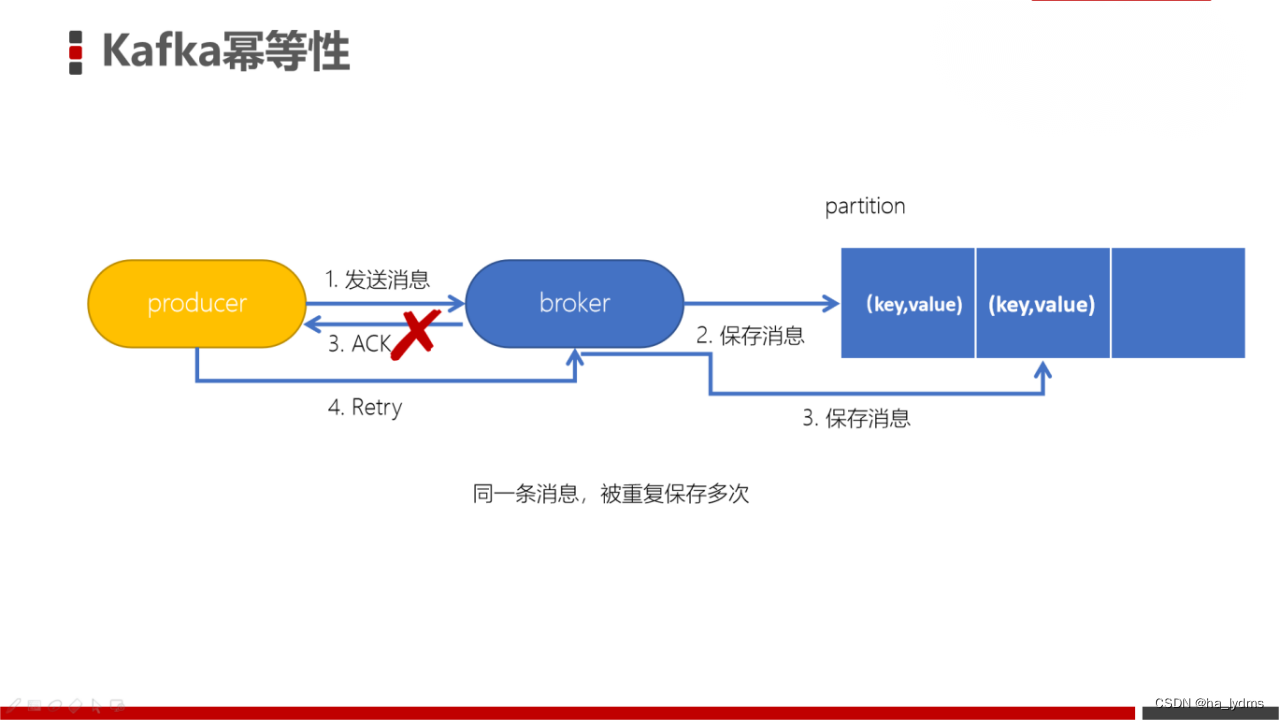
生产者生产消息时,如果出现retry时,有可能会一条消息被发送了多次,如果Kafka不具备幂等性的,就有可能会在partition中保存多条一模一样的消息。
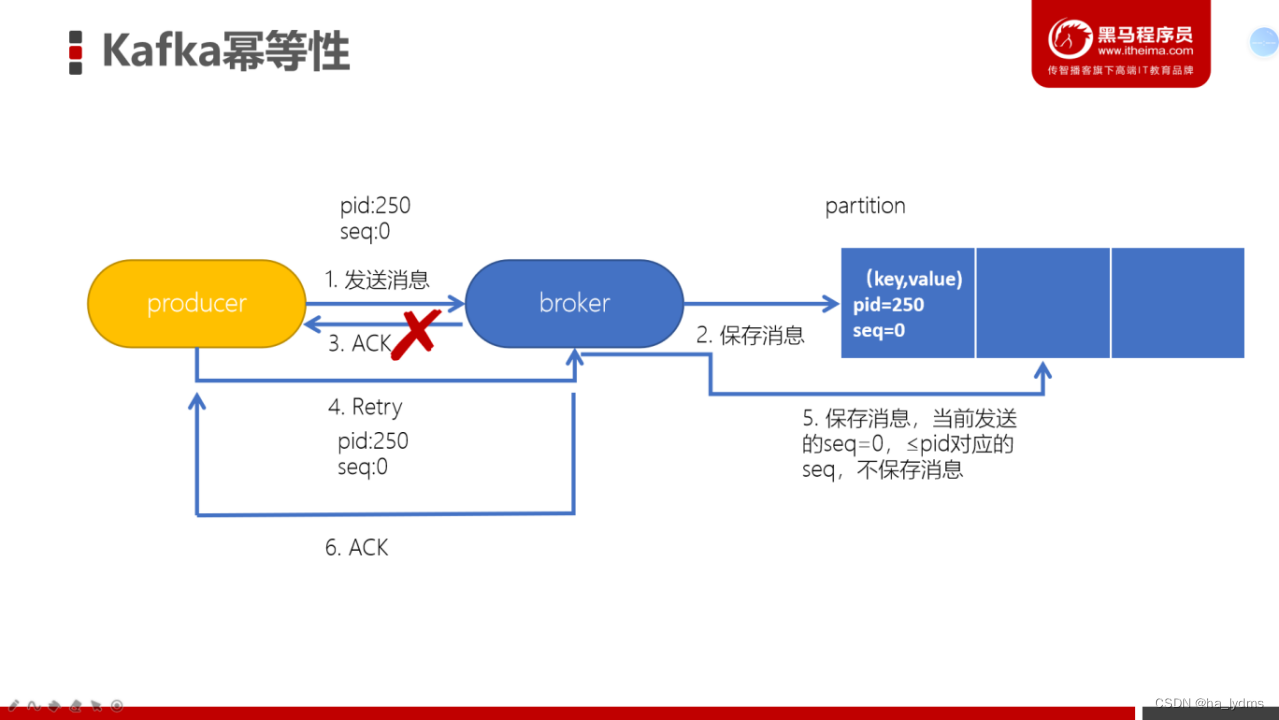
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
四、Kafka
1、事务
Kafka事务是2017年Kafka 0.11.0.0引入的新特性。类似于数据库的事务。Kafka事务指的是生产者生产消息以及消费者提交offset的操作可以在一个原子操作中,要么都成功,要么都失败。尤其是在生产者、消费者并存时,事务的保障尤其重要。(consumer-transform-producer模式)
Producer(生产者)接口中定义了以下5个事务相关方法:
- initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作
- beginTransaction(开始事务):启动一个Kafka事务。
- sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交。
- commitTransaction(提交事务):提交事务。
- abortTransaction(放弃事务):取消事务
生产者:
// 配置事务的id,开启了事务会默认开启幂等性
props.put("transactional.id","first-transactional");
消费者:
// 1. 消费者需要设置隔离级别
props.put("isolation.level","read_committed");// 2. 关闭自动提交
props.put("enable.auto.commit","false");
代码:
publicstaticvoidmain(String[] args){Consumer<String,String> consumer =createConsumer();Producer<String,String> producer =createProducer();// 初始化事务
producer.initTransactions();while(true){try{// 1. 开启事务
producer.beginTransaction();// 2. 定义Map结构,用于保存分区对应的offsetMap<TopicPartition,OffsetAndMetadata> offsetCommits =newHashMap<>();// 2. 拉取消息ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(2));for(ConsumerRecord<String,String>record: records){// 3. 保存偏移量
offsetCommits.put(newTopicPartition(record.topic(),record.partition()),newOffsetAndMetadata(record.offset()+1));// 4. 进行转换处理String[] fields =record.value().split(",");
fields[1]= fields[1].equalsIgnoreCase("1")?"男":"女";String message = fields[0]+","+ fields[1]+","+ fields[2];// 5. 生产消息到dwd_user
producer.send(newProducerRecord<>("dwd_user", message));}// 6. 提交偏移量到事务
producer.sendOffsetsToTransaction(offsetCommits,"ods_user");// 7. 提交事务
producer.commitTransaction();}catch(Exception e){// 8. 放弃事务
producer.abortTransaction();}}}
五、分区和副本机制
1、生产者写入策略
生产者分区写入策略:
- 轮训分区策略
- 随机分区策略
- 按Key分区分配策略
- 自定义分区策略
乱序问题
轮询策略、随机策略都会导致一个问题,生产到Kafka中的数据是乱序存储的。而按key分区可以一定程度上实现数据有序存储——也就是局部有序,但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
轮训分区
- 默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区
- 如果在生产消息时,key为null,则使用轮询算法均衡地分配分区
随机策略(不用)
随机策略,每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区。但后续轮询策略表现更佳,所以基本上很少会使用随机策略。
按key分配策略
按key分配策略,有可能会出现「数据倾斜」,例如:某个key包含了大量的数据,因为key值一样,所有所有的数据将都分配到一个分区中,造成该分区的消息数量远大于其他的分区。
自定义分区策略
2、消费者Rebalance(再平衡)机制
Kafka中的Rebalance称之为再均衡,是Kafka中确保Consumer group下所有的consumer如何达成一致,分配订阅的topic的每个分区的机制。
- 消费者组中consumer的个数发生变化。例如:有新的consumer加入到消费者组,或者是某个consumer停止了。
- 订阅的topic个数发生变化。消费者可以订阅多个主题,假设当前的消费者组订阅了三个主题,但有一个主题突然被删除了,此时也需要发生再均衡。
- 订阅的topic分区数发生变化
Rebalance的不良影响
- 发生Rebalance时,consumer group下的所有consumer都会协调在一起共同参与,Kafka使用分配策略尽可能达到最公平的分配
- Rebalance过程会对consumer group产生非常严重的影响,Rebalance的过程中所有的消费者都将停止工作,直到Rebalance完成
3、消费者分区分配策略
Range范围分配策略
Range范围分配策略是Kafka默认的分配策略,它可以确保每个消费者消费的分区数量是均衡的。
注意:Rangle范围分配策略是针对每个Topic的。
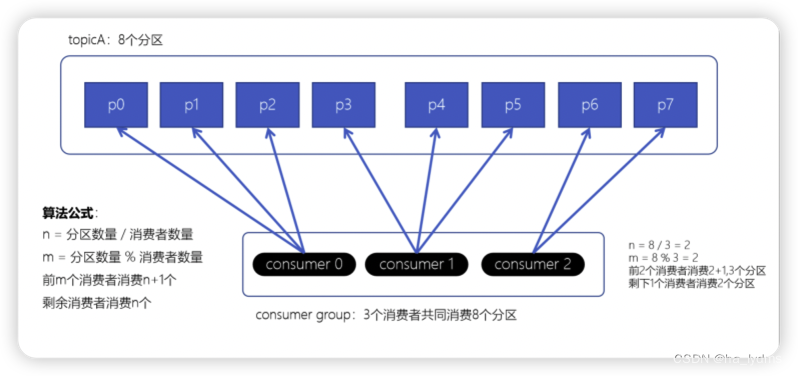
RoundRobin轮询策略
RoundRobinAssignor轮询策略是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序(topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区以此分配给每个消费者。
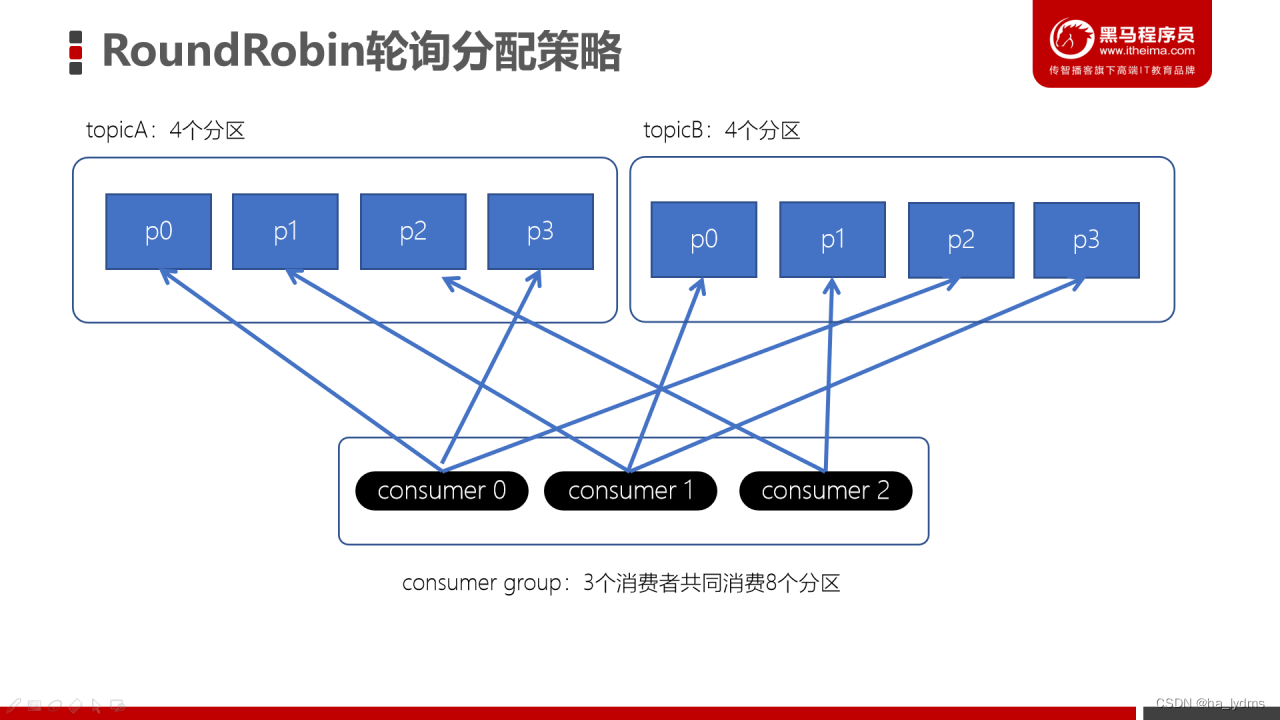
Stricky粘性分配策略
主要目的:
- 分区分配尽可能均匀。
- 在发生rebalance的时候,分区的分配尽可能与上一次分配保持相同。
没有发生rebalance时,Striky粘性分配策略和RoundRobin分配策略类似。如果consumer2崩溃了,此时需要进行rebalance。如果是Range分配和轮询分配都会重新进行分配。
粘性特点:
Striky粘性分配策略,保留rebalance之前的分配结果。这样,只是将原先consumer2负责的两个分区再均匀分配给consumer0、consumer1。这样可以明显减少系统资源的浪费,例如:之前consumer0、consumer1之前正在消费某几个分区,但由于rebalance发生,导致consumer0、consumer1需要重新消费之前正在处理的分区,导致不必要的系统开销。(例如:某个事务正在进行就必须要取消了)
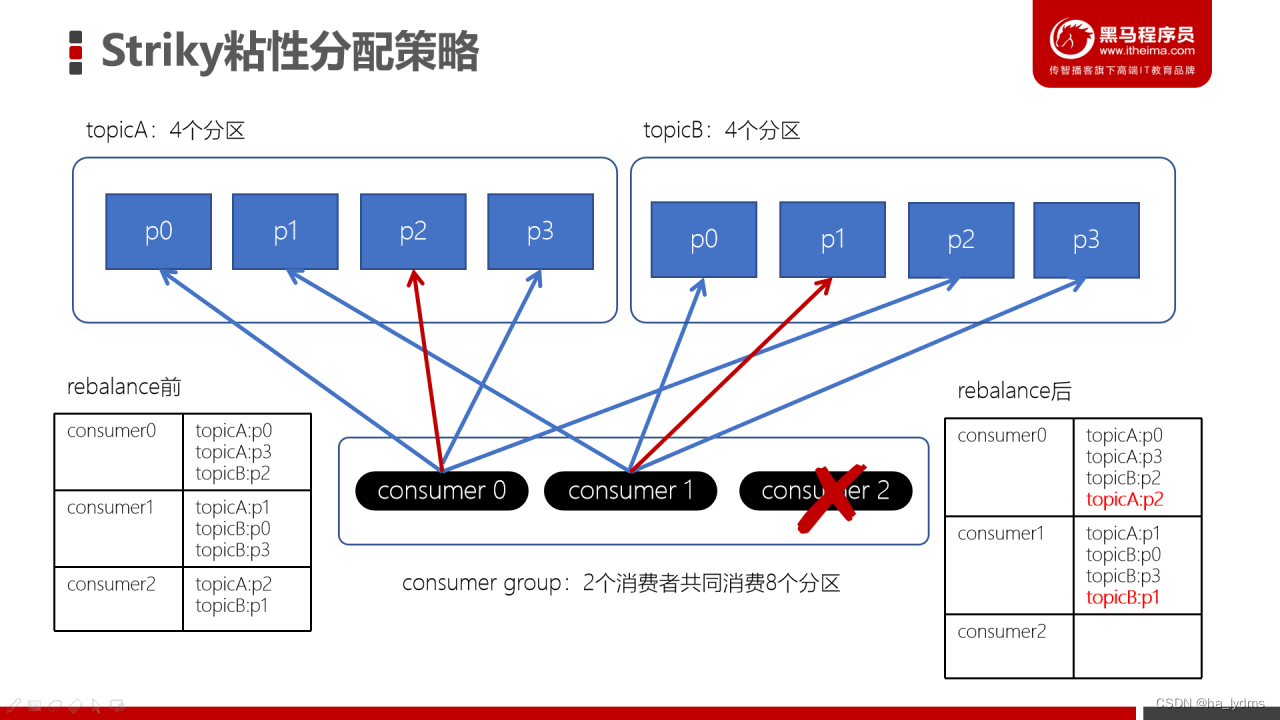
4、副本机制
副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以保障数据可用。因为在其他的Broker上的副本是可用的。
对副本关系较大的就是,producer配置的acks参数了,acks参数表示当生产者生产消息的时候,写入到副本的要求严格程度。它决定了生产者如何在性能和可靠性之间做取舍。
Properties props =newProperties();
props.put("bootstrap.servers","node1.itcast.cn:9092");
props.put("acks","all");
ACK=0:
ACK=1:
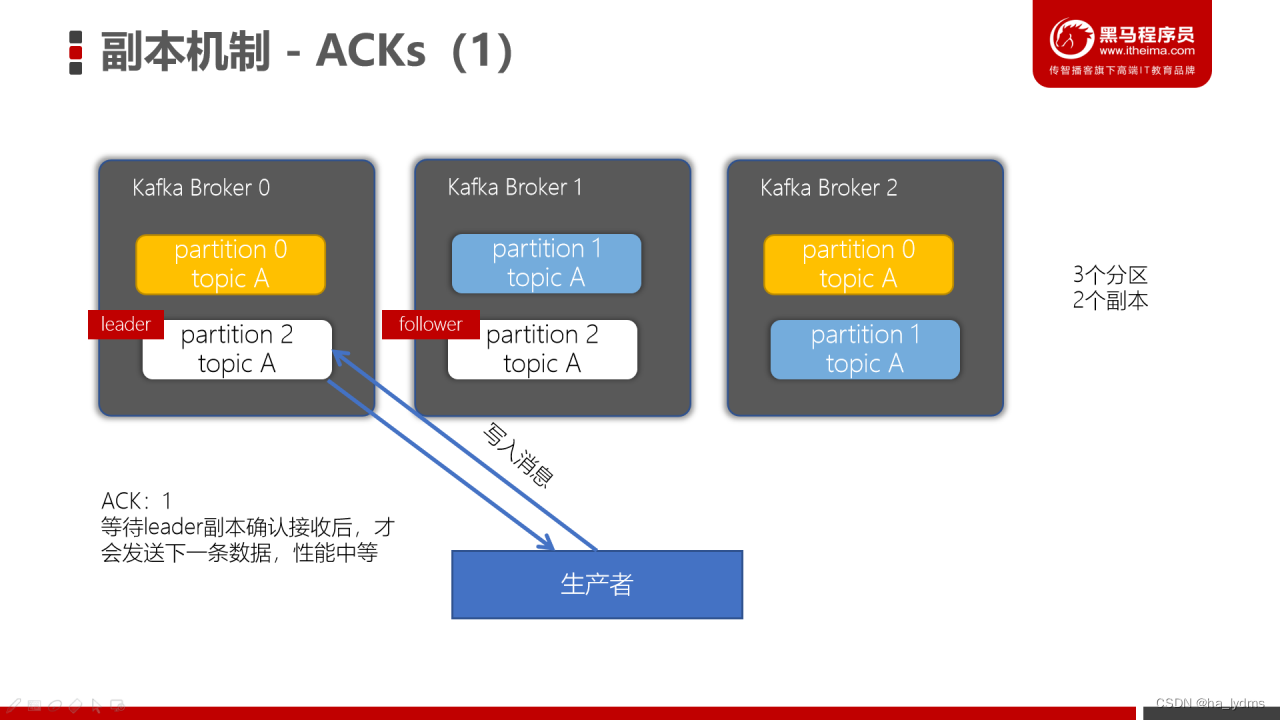
当生产者的ACK配置为1时,生产者会等待leader副本确认接收后,才会发送下一条数据,性能中等。
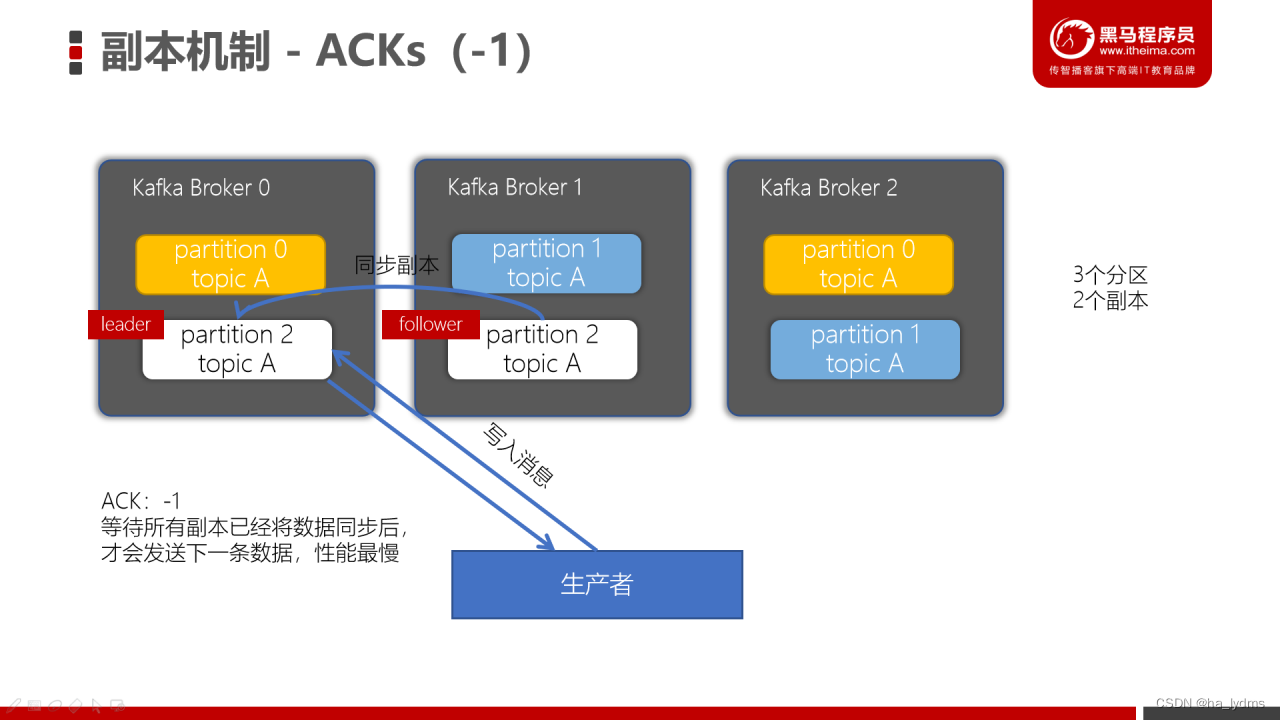
ACK=-1/all
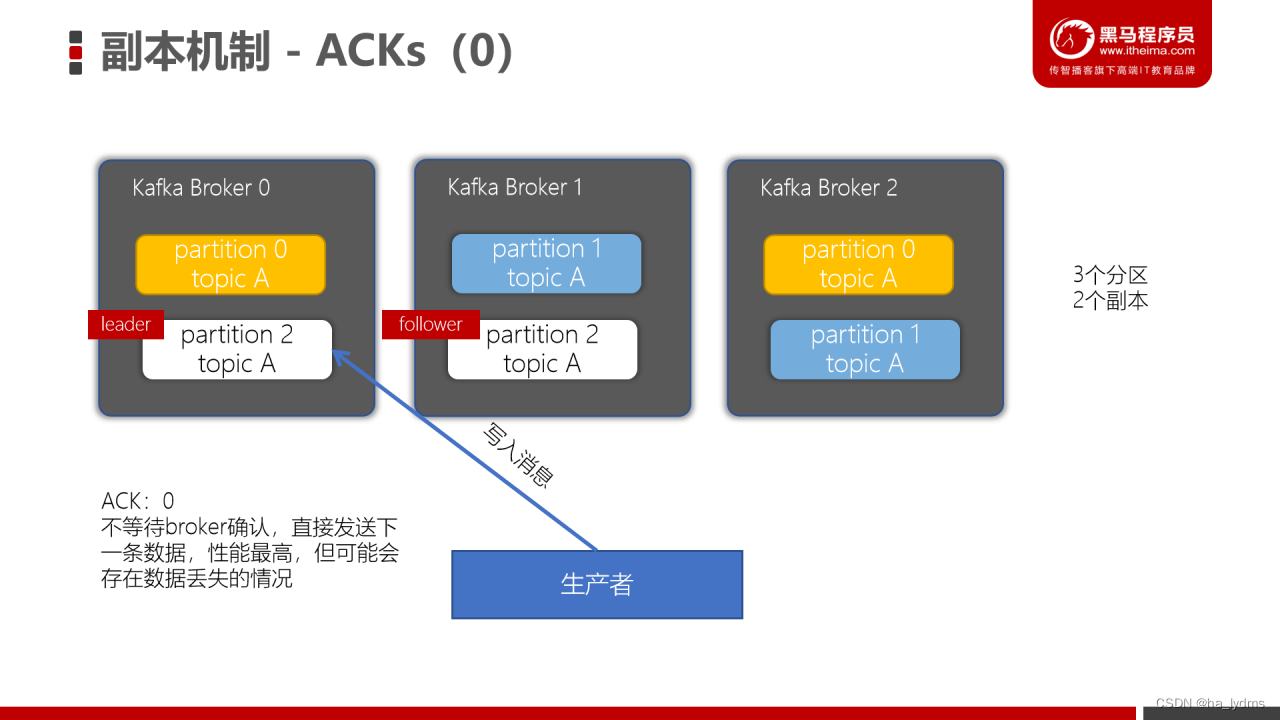
ACK=1:
ACK= -1/all:
*指标单分区单副本(ack=0)*单分区单副本(ack=1)****单分区单副本(ack=-1/all)**吞吐量165875.991109/s每秒16.5W条记录93092.533979/s 每秒9.3W条记录73586.766156 /s每秒7.3W调记录吞吐速率158.19 MB/sec88.78 MB/sec70.18 MB平均延迟时间192.43 ms346.62 ms438.77 ms最大延迟时间670.00 ms1003.00 ms1884.00 ms
六、高级(High Level)API与低级(Low Level)API
高级API
- 不需要执行去管理offset,直接通过ZK管理;也不需要管理分区、副本,由Kafka统一管理
- 消费者会自动根据上一次在ZK中保存的offset去接着获取数据
- 在ZK中,不同的消费者组(group)同一个topic记录不同的offset,这样不同程序读取同一个topic,不会受offset的影响
缺点
- 不能控制offset,例如:想从指定的位置读取。
- 不能细化控制分区、副本、ZK等。
低级API
通过使用低级API,我们可以自己来控制offset,想从哪儿读,就可以从哪儿读。而且,可以自己控制连接分区,对分区自定义负载均衡。而且,之前offset是自动保存在ZK中,使用低级API,我们可以将offset不一定要使用ZK存储,我们可以自己来存储offset。例如:存储在文件、MySQL、或者内存中。但是低级API,比较复杂,需要执行控制offset,连接到哪个分区,并找到分区的leader。
七、Kafka中数据清理
两种日志清理方式:
- 日志删除(Log Deletion):按照指定的策略直接删除不符合条件的日志。
- 日志压缩(Log Compaction):按照消息的key进行整合,有相同key的但有不同value值,只保留最后一个版本。
在Kafka的broker或topic配置中
配置项配置值说明log.cleaner.enabletrue(默认)开启自动清理日志功能log.cleanup.policydelete(默认)删除日志log.cleanup.policycompaction压缩日志log.cleanup.policydelete,compact同时支持删除、压缩
1、日志删除
日志删除是以段(segment日志)为单位来进行定期清理的。
定时删除
Kafka日志管理器中会有一个专门的日志删除任务来定期检测和删除不符合保留条件的日志分段文件。
这个周期可以通过broker端参数log.retention.check.interval.ms来配置,默认值为300,000,即5分钟。
日志分段的保留策略有3种
- 基于时间的保留策略。
- 基于日志大小的保留策略。
- 基于日志起始偏移量的保留策略。
1.1 基于时间的保留策略
指定如果Kafka中的消息超过指定的阈值,就会将日志进行自动清理:
- log.retention.hours
- log.retention.minutes
- log.retention.ms
优先级为 log.retention.ms > log.retention.minutes > log.retention.hours。
删除日志分段时:
- 从日志文件对象中所维护日志分段的跳跃表中移除待删除的日志分段,以保证没有线程对这些日志分段进行读取操作
- 将日志分段文件添加上“.deleted”的后缀(也包括日志分段对应的索引文件)
- Kafka的后台定时任务会定期删除这些“.deleted”为后缀的文件,这个任务的延迟执行时间可以通过file.delete.delay.ms参数来设置,默认值为60000,即1分钟。
1.2 基于于日志大小的保留策略
日志删除任务会检查当前日志的大小是否超过设定的阈值来寻找可删除的日志分段的文件集合。可以通过broker端参数 log.retention.bytes 来配置,默认值为-1,表示无穷大。如果超过该大小,会自动将超出部分删除。
注意:
log.retention.bytes 配置的是日志文件的总大小,而不是单个的日志分段的大小,一个日志文件包含多个日志分段。
1.3 基于日志起始偏移量保留策略
每个segment日志都有它的起始偏移量,如果起始偏移量小于 logStartOffset,那么这些日志文件将会标记为删除。
2、日志压缩(Log Compaction)
Log Compaction是默认的日志删除之外的清理过时数据的方式。它会将相同的key对应的数据只保留一个版本。
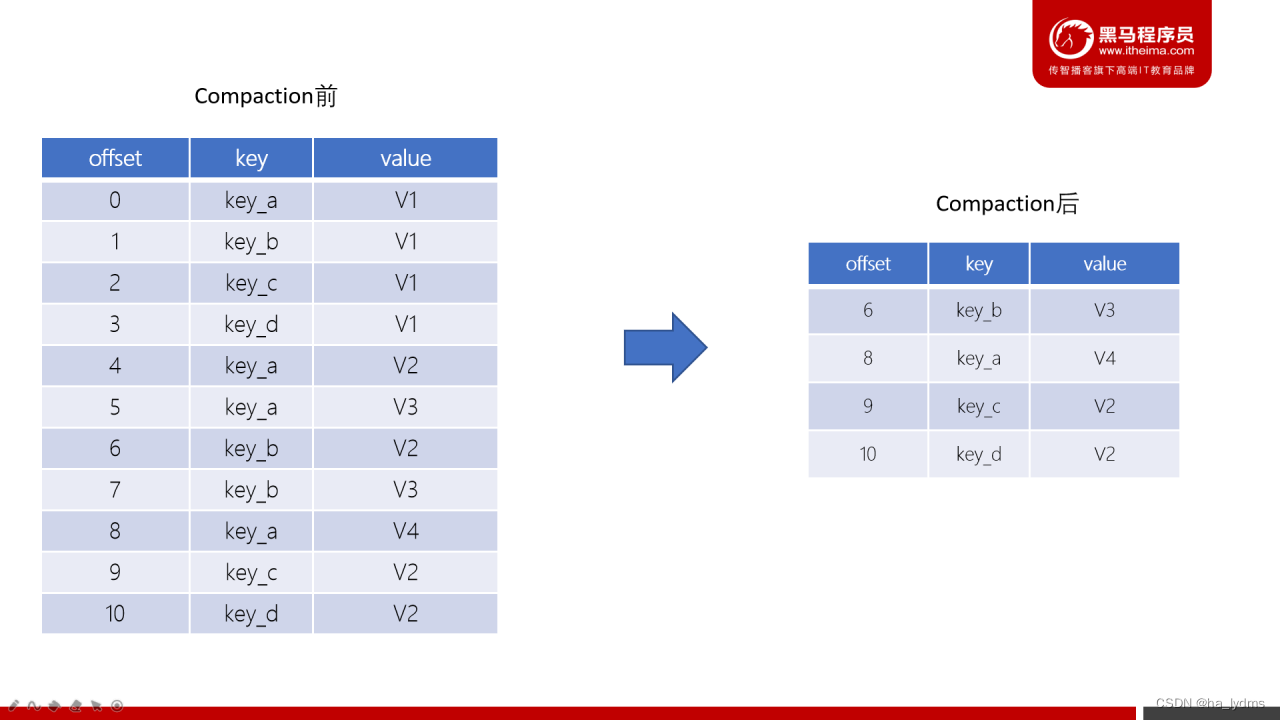
- Log Compaction执行后,offset将不再连续,但依然可以查询Segment
- Log Compaction执行前后,日志分段中的每条消息偏移量保持不变。Log Compaction会生成一个新的Segment文件
- Log Compaction是针对key的,在使用的时候注意每个消息的key不为空
- 基于Log Compaction可以保留key的最新更新,可以基于Log Compaction来恢复消费者的最新状态
八、Kafka配额限速机制(Quotas)
生产者和消费者以极高的速度生产/消费大量数据或产生请求,从而占用broker上的全部资源,造成网络IO饱和。有了配额(Quotas)就可以避免这些问题。Kafka支持配额管理,从而可以对Producer和Consumer的produce&fetch操作进行流量限制,防止个别业务压爆服务器。
1、限制producer(生产)端速率
为所有client id设置默认值,以下为所有producer程序设置其TPS不超过1MB/s,即1048576/s。
bin/kafka-configs.sh --zookeeper node1.itcast.cn:2181 --alter --add-config 'producer_byte_rate=1048576' --entity-type clients --entity-default
2、限制consumer(消费)端速率
对consumer限速与producer类似,只不过参数名不一样。
为指定的topic进行限速,以下为所有consumer程序设置topic速率不超过1MB/s,即1048576/s。
bin/kafka-configs.sh --zookeeper node1.itcast.cn:2181 --alter --add-config 'consumer_byte_rate=1048576' --entity-type clients --entity-default
3、取消Kafka的Quota配置
使用以下命令,删除Kafka的Quota配置
bin/kafka-configs.sh --zookeeper node1.itcast.cn:2181 --alter --delete-config 'producer_byte_rate' --entity-type clients --entity-default
bin/kafka-configs.sh --zookeeper node1.itcast.cn:2181 --alter --delete-config 'consumer_byte_rate' --entity-type clients --entity-default
九、Spring boot集成Kafka
1、pom依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
2、发送消息
@AutowiredprivateKafkaTemplate<String,String> kafkaTemplate;@RequestMapping("/userGets")publicObjectgets(){// send 第一个参数为topic的名称,第二个参数为我们要发送的信息
kafkaTemplate.send("topic.quick.default","1231235");return"发送成功";}
3、接收消息
@KafkaListener(topics ={"topic1"})publicvoidonMessage(ConsumerRecord<?,?>record){System.out.println(record.value());}
@KafkaListener(topics ={"topic2"})publicvoidgetMessage(ConsumerRecord<String,String>record){String key =record.key();String value =record.value();}
版权归原作者 ha_lydms 所有, 如有侵权,请联系我们删除。