
2.1 数据调研
2.1.1业务调研
数据仓库是要涵盖所有业务领域,还是各个业务领域独自建设,业务领域内的业务线也同样面临着这个问题。所以要构建大数据数据仓库,就需要了解各个业务领域、业务线的业务有什么共同点和不同点,以及各个业务线可以细分为哪几个业务模块,每个业务模块具体的业务流程又是怎样的。业务调研是否充分,将会直接决定数据仓库建设是否成功。
2.1.2需求调研
了解业务系统的业务后不等于说就可以实施数仓建设了,还需要收集数据使用者的需求,及找分析师、运营人员、产品人员等了解他们对数据的诉求。通常需求调研分下面两种途径:
- 根据与分析师、运营人员、产品人员的沟通获取需求。
- 对现有报表、数据进行研究分析获取数据建设需求。
2.1.3数据调研
前期需要做好数据探查工作,需要了解数据库类型,数据来源,全量数据情况及数据每年增长情况,更新机制;还需要了解数据是否结构化,是否清洗,是接口调用还是直接访问库,有哪些类型的数据,数据结构之怎样的。
2.2 数据采集
2.2.1 日志数据
2.2.1.1埋点日志
- 浏览日志(h5,web,app)
- 点击日志(h5,web,app)
2.2.1.2服务日志
- 应用访问日志
- 接口调用日志
2.2.1.3 NG日志
(h5,web,app)
2.2.1.4采集字段
account string,
appId string,
appVersion string,
carrier string,
deviceId string,
deviceType string,
eventId string,
ip string,
latitude double,
longitude double,
netType string,
osName string,
osVersion string,
properties map<string,string>,
releaseChannel string,
resolution string,
sessionId string,
timeStamp bigint
......
2.2.2 业务数据
- Mysql
- MongoDB
- Oracle
2.2.3 爬虫数据
- 竞品数据
- 维表数据
2.2 ETL
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据
2.2.1 数据抽取(Extract)
主要是从业务库把数据抽取到数据仓库或者把日志采集到数据仓库
2.2.1.1 业务数据抽取
2.2.1.1.1****前言
sqoop和datax作为2款优秀的数据同步工具,备受数据开发人员喜爱,如何选择也是件非常头疼的事,下面就这两种工具来分析分析吧...
**2.2.1.1.2 **sqoop
sqoop 是 apache 旗下一款“Hadoop中的各种存储系统(HDFS、HIVE、HBASE) 和关系数据库(mysql、oracle、sqlserver等)服务器之间传送数据”的工具。
导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等 Sqoop 的本质还是一个命令行工具。
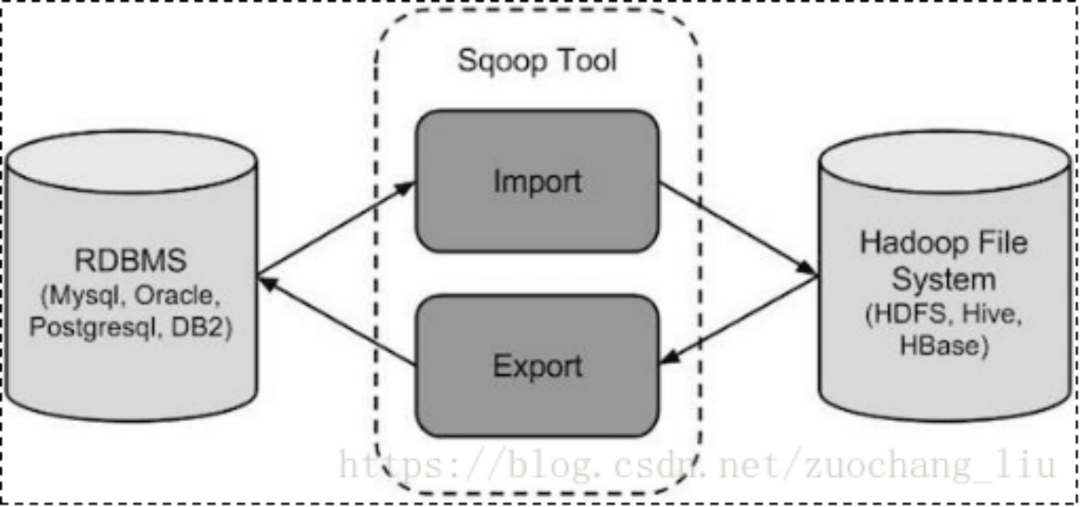
底层工作机制
将导入或导出命令翻译成 MapReduce 程序来实现
在翻译出的 MapReduce 中主要是对InputFormat 和
OutputFormat 进行定制
sqoop import \
--connect jdbc:mysql://hadoop:3306/mysql \
--username root \
--password 123456 \
--table order_info \
--target-dir /user/project/t_order_info \
--fields-terminated-by '\t' \
--split-by order_id \
-m 2
**2.2.1.1.3 **datax
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
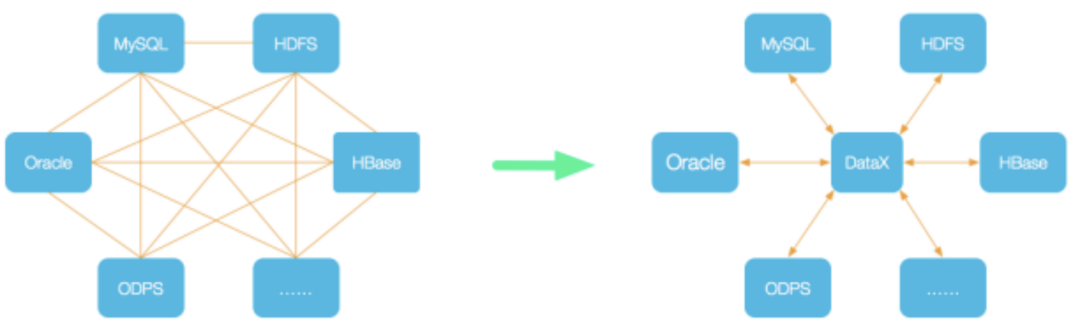
2核心架构

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
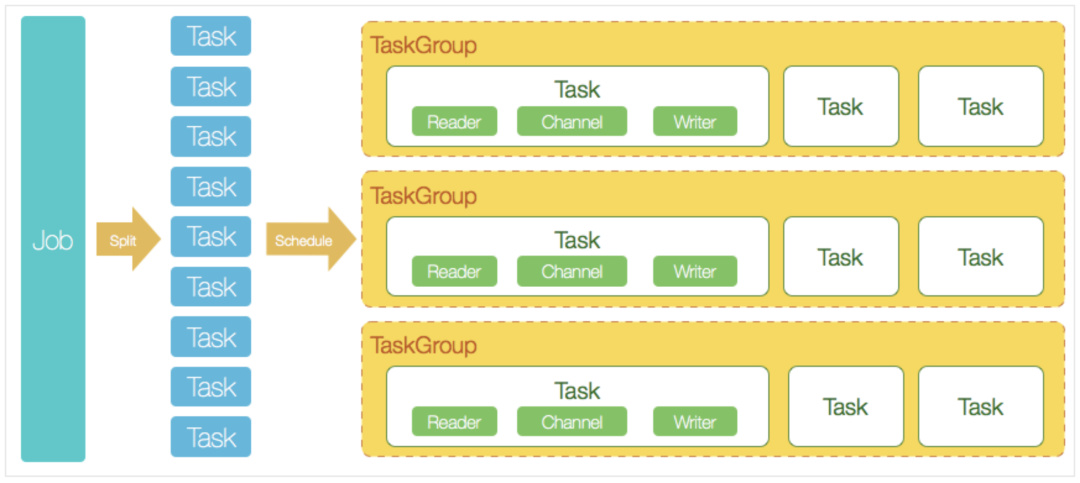
核心模块介绍
DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。DataX的调度决策思路是:
DataXJob根据分库分表切分成了100个Task。
根据20个并发,DataX计算共需要分配4个TaskGroup。
4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
下面以datax抽取mysql数据写入hdfs为例:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": ['id',
'name'
],
"where":"gmt_created>='$bizdate' and gmt_created<DATE_ADD('$bizdate',INTERVAL 1 DAY)",
"splitPk": "id",
"connection": [{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://xxx:port",
"fileType": "orc",
"path": "/user/hive/warehouse/writerorc.db/orcfull",
"fileName": "xxx",
"column": [{
"name": "id",
"type": "BIGINT"
},
{
"name": "name",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "GZIP"
}
}
}]
}
}
** 2.2.1.1.4对比**
功能
datax
sqoop
运行模式
单进程多线程
mr
hive读写
单机压力大
扩展性好
分布式
不支持
支持
运行信息
运行时间,数据量,消耗资源,脏数据稽核
不支持
流量控制
支持
不支持
社区
开源不久,不太活跃
活跃
** 2.2.1.1.5总结**
对于sqoop和datax,如果只是单纯的数据同步,其实两者都是ok的,但是如果需要集成在大数据平台,还是比较推荐使用datax,原因就是支持流量控制,支持运行信息收集,及时跟踪数据同步情况。
附:
(有很多朋友私信问datax能操作哪些数据库或者文件,以下把datax各子工程贴出来了,下面有的就是支持的,否则就需要二次开发了)
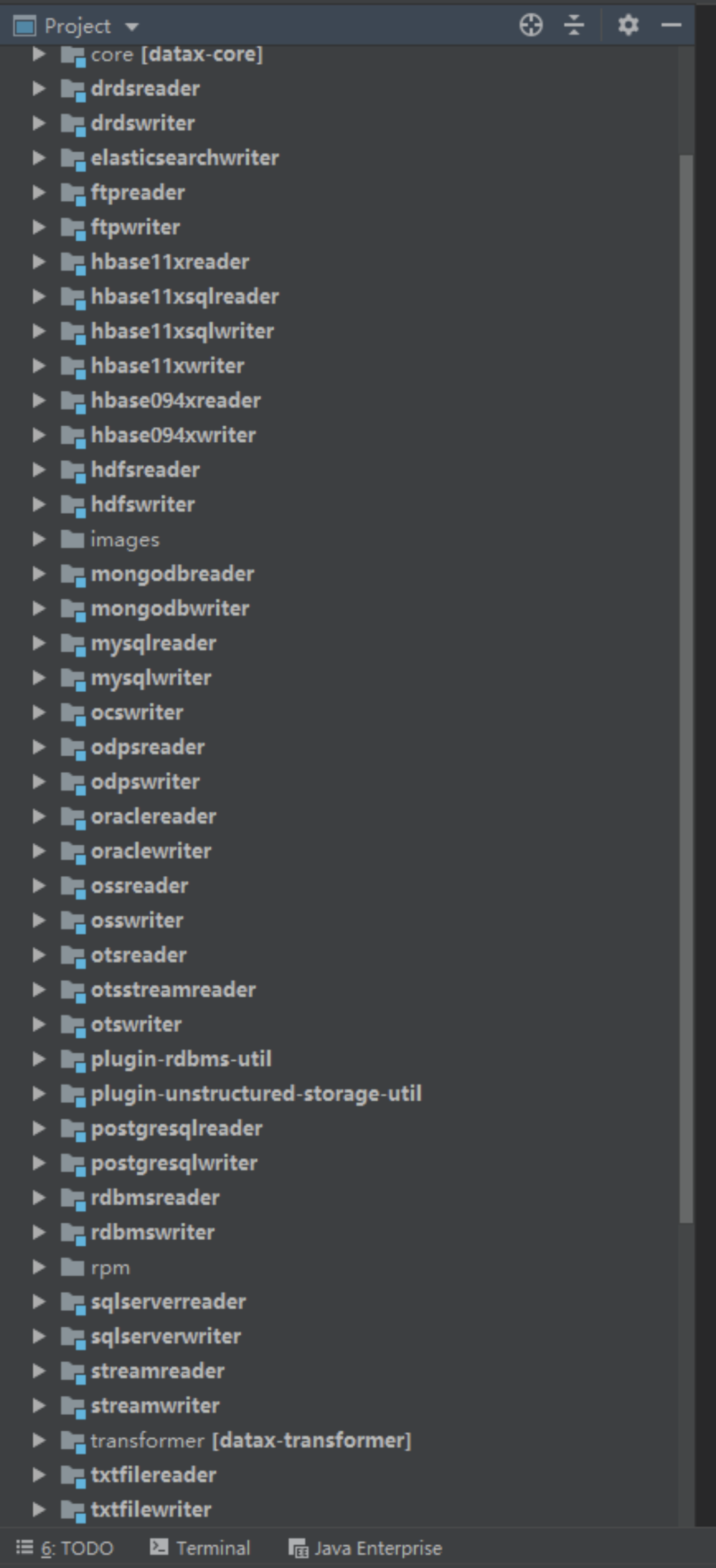
2.2.1.2 日志采集
2.2.1.2.1 flume
Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务。flume具有高可用,分布式和丰富的配置工具,其结构如下图所示:
Flume:是一个数据采集工具;可以从各种各样的数据源(服务器)上采集数据传输(汇聚)到大数据生态的各种存储系统中(Hdfs、hbase、hive、kafka);
开箱即用!(安装部署、修改配置文件)
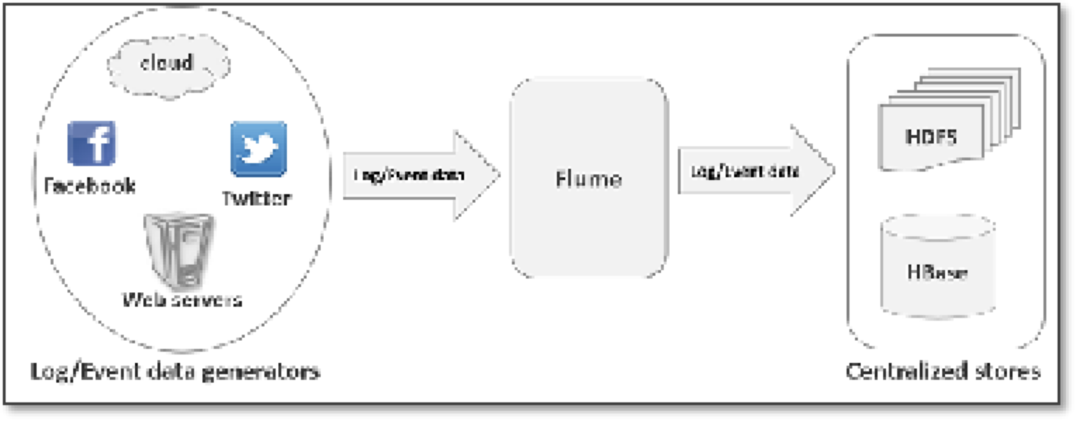
Flume是一个分布式、可靠、和高可用的海量日志采集、汇聚和传输的系统。
Flume可以采集文件,socket数据包(网络端口)、文件夹、kafka、mysql数据库等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中
一般的采集、传输需求,通过对flume的简单配置即可实现;不用开发一行代码!
Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道。
对于每一个Agent来说,它就是一个独立的守护进程(JVM),它负责从数据源接收数据,并发往下一个目的地,如下图所示:
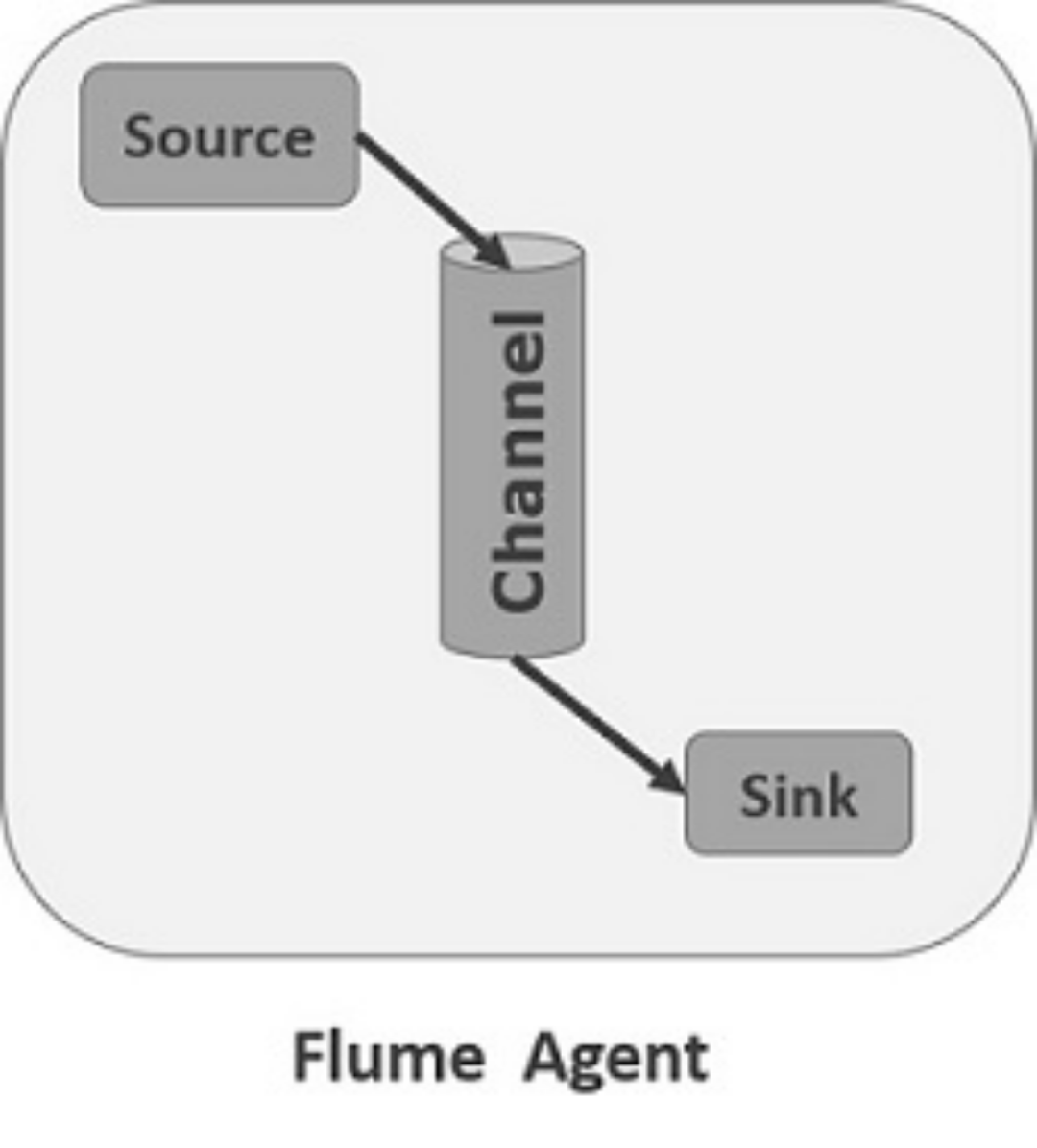
每一个agent相当于一个数据(被封装成Event对象)传递员,内部有三个组件:
Source:采集组件,用于跟数据源对接,以获取数据;它有各种各样的内置实现;
Sink:下沉组件,用于往下一级agent传递数据或者向最终存储系统传递数据
Channel:传输通道组件,用于从source将数据传递到sink
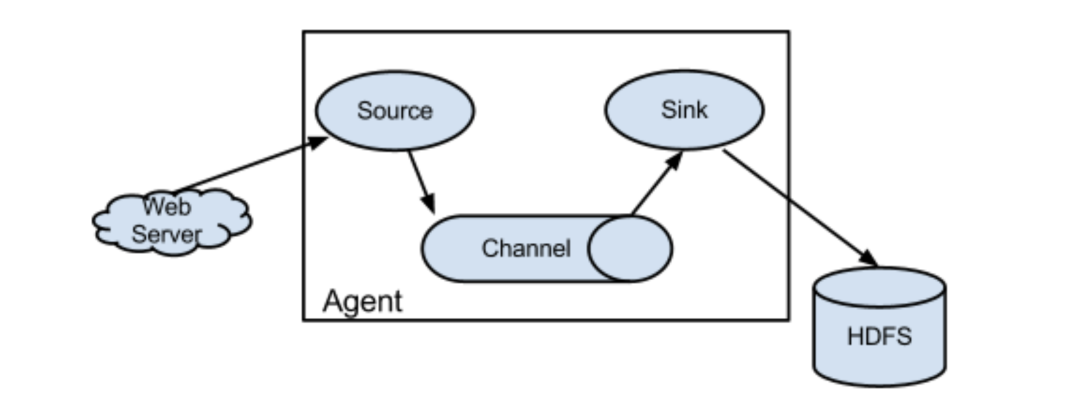
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
根据需求,首先定义以下3大要素
采集源,即source——监控文件内容更新 : exec ‘tail -F file’
下沉目标,即sink——HDFS文件系统 : hdfs sink
Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
配置文件编写:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
Describe/configure tail -F source1
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /home/hadoop/logs/access_log
agent1.sources.source1.channels = channel1
#configure host for source
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
Describe sink1
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path =hdfs://hadoop1:9000/weblog/flume-collection/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
2.2.1.2.2 logstash
Logstash是一个开源的服务器端数据处理管道,它可以同时从多个源中提取数据,对其进行转换,然后将其发送其他存储。
主要由input filter和output组成
原始日志文件:
[2019-01-14 00:02:11] [INFO] - com.test.pushTest(PushMessageExecutor.java:103) - 消息推送结果:响应状态(200)、状态描述(成功。)、响应反馈()、请求响应耗时(232ms),deviceToken:7b64436eeea34a3ab4e0873b0682ad98e,userId:1659034,auId:null,
globalMessageId:2d09f8d389524c1f9c66b61,appId:p_ios,title:null,subTitle:null,alertBody:请及时查阅。.
配置文件demo:
input {
file {
path => "/data/liuzc/test_log/*"
type => "aa"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
multiline {
pattern => "%{DATESTAMP}"
negate => true
what => "previous"
}
if [type] == "aa" {
grok {
match => {
"message" => "\[%{DATA:time_local}\] \[%{LOGLEVEL:log_level}\] - %{NOTSPACE:pushExecute} - %{NOTSPACE:apns_push_result},deviceToken:%{NOTSPACE:deviceToken},userId:%{NOTSPACE:userId},auId:%{NOTSPACE:auId},globalMessageId:%{NOTSPACE:globalMessageId},appId:%{NOTSPACE:appId},title:%{NOTSPACE:title},subTitle:%{NOTSPACE:subTitle},alertBody:%{NOTSPACE:alertBody}"
}
}
} else {
grok {
match => {
"message" => "%{DATESTAMP:time_local} %{LOGLEVEL:log_level}"
}
}
}
#ruby {
code => '
event["datestr"] = event["@timestamp"].time.getlocal("+08:00").strftime "%Y-%m-%d"
event["hours"] = event["@timestamp"].time.getlocal("+08:00").strftime("%H").to_i
'
}
date {
match => ["time_local", "yy/MM/dd-HH:mm:ss.SSS"]
}
}
output {
stdout{codec=>"rubydebug"}
}
解析结果:
{
"message" => "[2019-01-14 00:02:11] [INFO] - com.test.pushTest(PushMessageExecutor.java:103) - 消息推送结果:响应状态(200)、状态描述(成功。)、响应反馈()、请求响应耗时(232ms),deviceToken:7b64436eeea34a3ab4e0873b0682ad98e,userId:1659034,auId:null,globalMessageId:2d09f8d389524c1f9c66b61,appId:p_ios,title:null,subTitle:null,alertBody:请及时查阅。.",
"@version" => "1",
"@timestamp" => "2019-01-17T01:16:06.468Z",
"host" => "xy1",
"path" => "/data/liuzc/test_log/test-2019-01-14.log",
"type" => "aa",
"time_local" => "2019-01-14 00:02:11",
"log_level" => "INFO",
"pushExecute" => "com.test.pushExecute(PushMessageExecutor.java:103)",
"apns_push_result" => "消息推送结果:响应状态(200)、状态描述(成功。)、响应反馈()、请求响应耗时(232ms)",
"deviceToken" => "7b64436eeea34a3ab4e0873b0682ad98e",
"userId" => "1659034",
"auId" => "null",
"globalMessageId" => "2d09f8d389524c1f9c66b61",
"appId" => "p_ios",
"title" => "null",
"subTitle" => "null",
"alertBody" => "请及时查阅。."
}
Logstash grok在线验证地址:
2.2.1.2.3 对比
- Logstash和flume都能作为日志采集工具
- Logstash是由ruby开发,flume使用java语言开发
- Logstash每起一个进程,默认占用1G内存,如果进程起的多的话给应用服务器带来很大的压力
2.2.2 数据清洗转换(Cleaning、Transform)
数据清洗的任务是过滤那些不符合要求的数据
数据转换的任务主要进行不一致的数据转换、数据粒度的转换,以及一些业务规则的计算。
2.2.2.1 数据清洗
- 单位统一,比如金额单位统一为元
- 字段类型统一
- 注释补全
- 空值用默认值或者中位数填充
- 时间字段格式统一,如2020-10-16,2020/10/16,20201016统一格式为2020-10-16
- 过滤没有意义的数据
2.2.2.2 数据转换
下面会介绍模型建设
2.2.3 数据加载(load)
数据同步到其他存储系统,如mysql,hbase
2.3 数据存储
数据存储在hdfs,包含元数据和主数据的存储
2.4 数据应用
- 数据同步到mysql提供接口
- 数据同步到需求方mysql库直接调用
- 数据同步到kylin(olap)做预计算,为需求方提供数据做多维分析
- 数据同步到hbase提供接口服务
- 数据同步到pg提供数据
- 用户画像
- 推荐系统
- 运营系统
- 报表系统
- 业务系统
- BI可视化
2.5 简单架构

版权归原作者 code36 所有, 如有侵权,请联系我们删除。