
Kafka速通
参考
0. 辨析
在 Kafka 中,一个消费者组(consumer group)可以消费多个主题(topics)。当一个主题被某个消费者组消费时,组内的一个消费者可以消费多个分区(partitions),但是一个分区只能被消费者组内的一个消费者消费。
具体来说:
- 消费者组消费多个主题:一个消费者组可以同时订阅和消费多个主题。消费者组内的消费者可以订阅不同的主题,并独立消费这些主题中的消息。
- 消费者消费多个分区:当一个主题被消费者组消费时,主题可能被分为多个分区。消费者组内的消费者可以分配到消费主题中的不同分区,从而实现并行处理消息的能力。一个消费者可以消费多个分区,但每个分区只能被消费者组内的一个消费者消费。
- 消费者组内的协调:Kafka 使用消费者组协调器(consumer group coordinator)来管理消费者组内各个消费者的分区分配情况。协调器负责确保每个分区只被消费者组内的一个消费者消费,以实现负载均衡和并行处理。
总之,一个消费者组可以消费多个主题,组内的消费者可以消费多个分区,但一个分区只能被消费者组内的一个消费者消费。这种设计可以有效地实现消息的并行处理和负载均衡,同时保证每条消息只被消费一次。
1. 基础概念
常见概念参考
注:kafka0.11之后,分区的offset存储从zookeeper移动到了kafka的partition
2. 实际使用(命令行)
2.1 前置准备
先开启zookeeper,后根据各自的配置文件(修改后的)挨个创建broker
2.2 创建topic
进入kafka的bin目录,通过以下指令创建/管理 topic:
./kafka-topics.sh

常用指令参数
zookeeper (必需),指定zookeeper
create 创建主题
topic 主题名字
list 全部主题
partitions 分区操作
replacation-factor 创建多少副本
replica-assignment 每个分区维护哪个副本: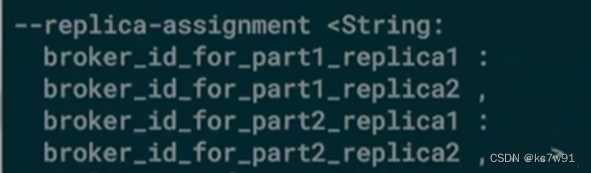
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic my_topic --replication-factor 3 --partitions 3 --replica-assignment 0:1,1:2,2:0
在这个示例中,–replica-assignment 0:1,1:2,2:0 指定了每个分区的副本分配情况。具体来说,分区 0 的副本应该存储在 Broker 1 上,分区 1 的副本应该存储在 Broker 2 上,分区 2 的副本应该存储在 Broker 0 上。
请注意,使用 replica-assignment 参数需要确保指定的副本分配是有效的,即每个副本都应该分配到一个活动的 Broker 上,并且应该考虑到数据的可靠性和负载均衡。在实际使用中,建议谨慎使用 replica-assignment,并确保了解其影响。
eg.
(1)创建topic
(2)创建消费者
kafka bin目录下执行:(使用kafka提供的consumer脚本)
(3)创建生产者
kafka bin目录下执行:(使用kafka提供的producer脚本,发送消息)
发现消费者端可以接收到:
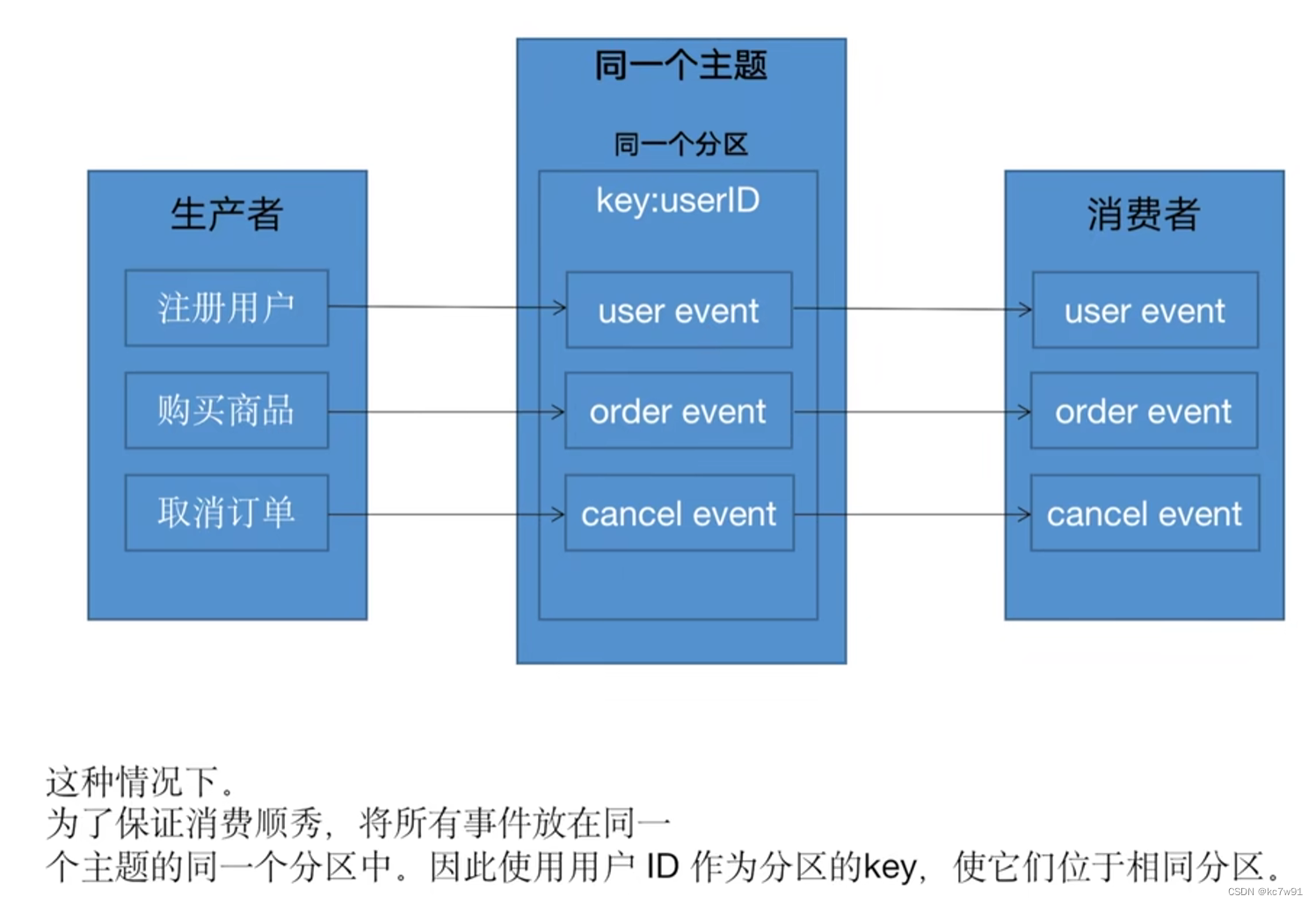
3. 消费顺序
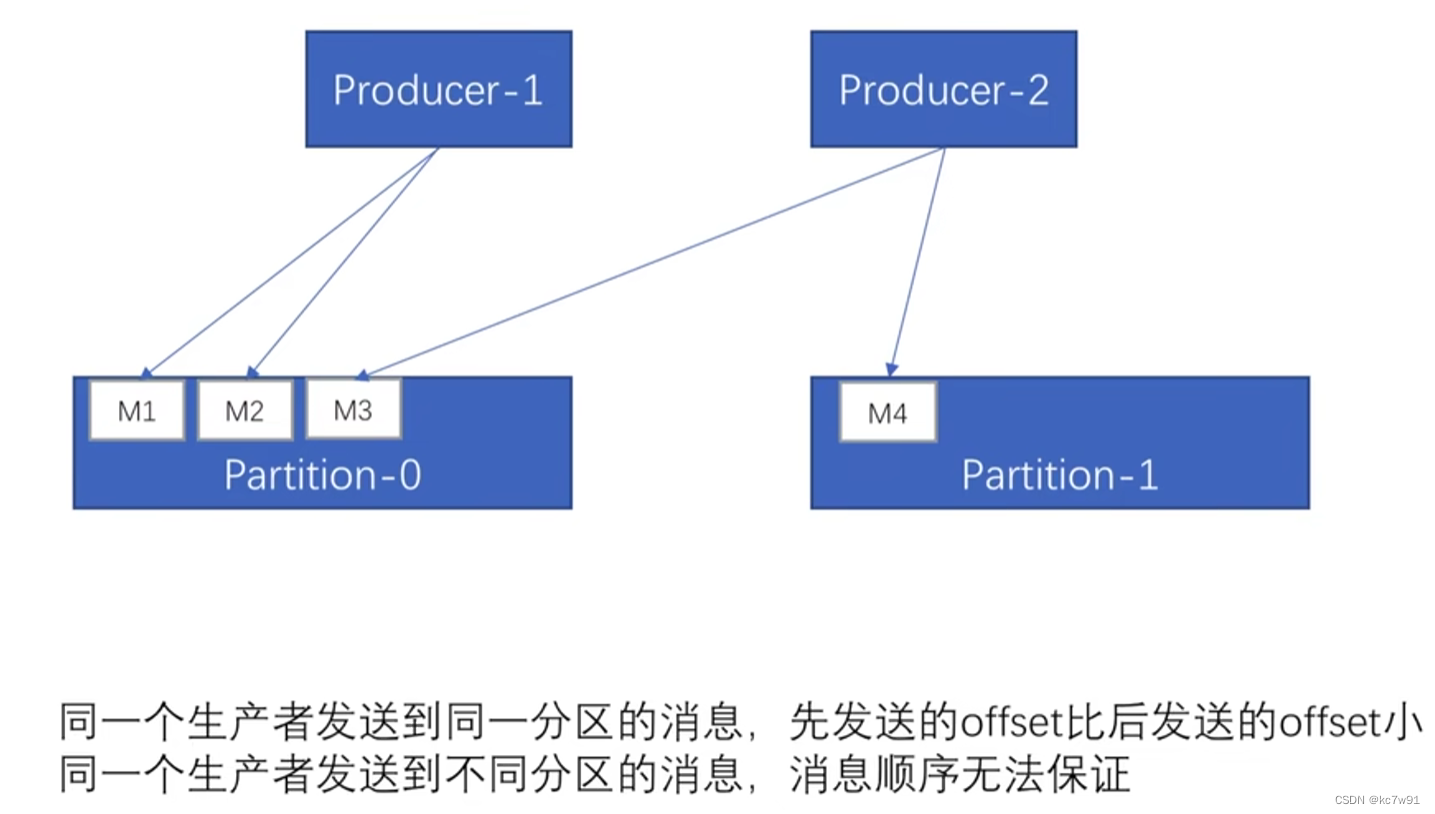
生产者1生产的两个消息发送到了同一个分区,这两条消息的消费顺序可以保证
生产者2生产的消息发送到了不同的分区,这两条消息的消费顺序不能保证
消费者端:一个消费者消费了多个分区,只能保证某个分区内消息消费的相对顺序
4. 重复消费与消息丢失

生产者端:
- 最多一次:发送失败也不重发(消息丢失)
- 最少一次:发送失败重试
消费者端:
- 最多一次:先提交offset再消费消息(消息丢失)
- 最少一次:先消费消息再提交offset(重复消费)
5. api使用
5.1 生产者send消息
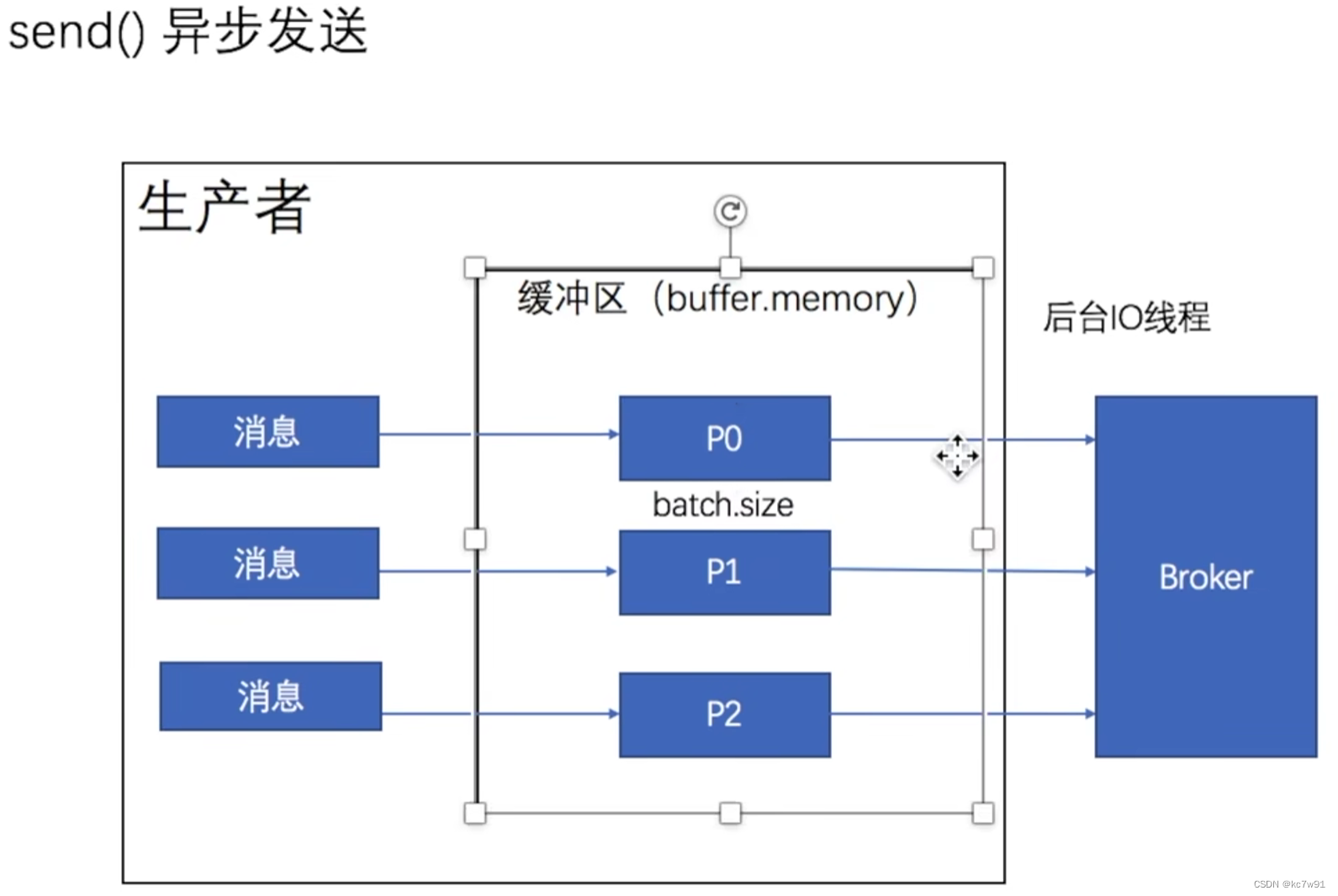
给每个分区都设置一个缓冲区。生产者发送消息到指定缓冲区后立即返回,不等待,后台io线程负责把消息写到broker中
5.1.1 异步发送
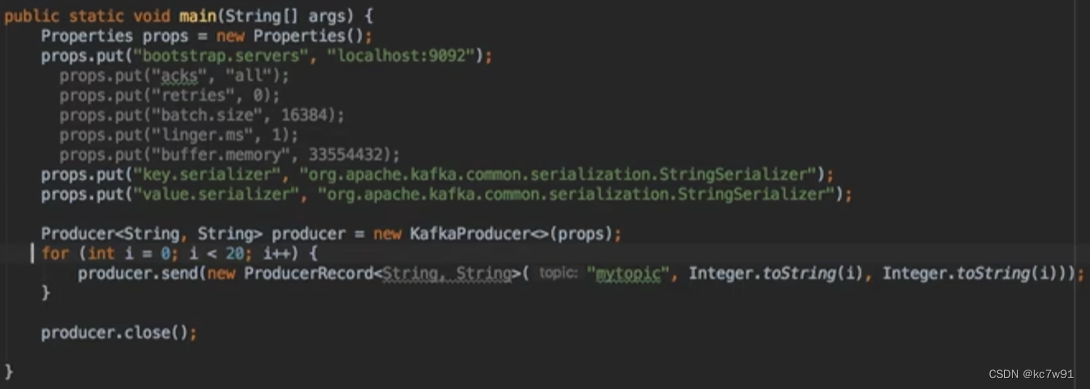
new ProducerRecord<String, String>(“mytopic”, Integer.toString(i), Integer.toString(i));
topic名称、键、值
泛型中的两个类别代指键值的类型
ProducerRecord是消息类型
5.1.2 同步发送

一条消息发送完才发送下一条消息
5.1.3 批量发送
在一秒内产生的消息一起发送/待发送的消息满足大小到了指定阈值就一起发送
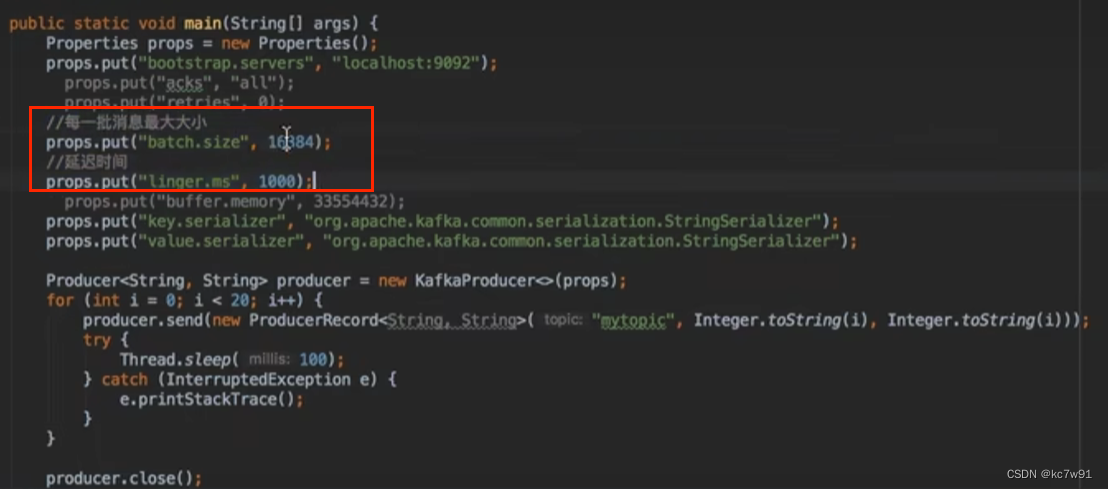
5.1.4 acks & retries
acks: 生产者发送的消息,被acks个leader&follower接收了,一般设置为all,默认为1
retires: 消息发送失败的重试次数
5.2 消费者consume消息


先开启自动提交,然后 props.put(“auto.commit.interval.ms”, “1000”);
这行代码设置了自动提交偏移量的时间间隔为 1000 毫秒,这意味着消费者将每隔 1 秒自动提交当前的消费偏移量
consumer.poll(100) 表示poll 方法是阻塞的,如果没有新消息到达,消费者将会在指定的超时时间100ms内等待
顺序:先拉取,再提交


逐条提交代码解析:
for循环:遍历所有涉及到的分区
获取该分区的
while(running){//尽可能多地拉取消息ConsumerRecords<String,String> records consumer.poll(Long.MAX_VALUE);for(TopicPartition partition : records.partitions()){//遍历所有涉及到的分区// 获取并遍历输出该分区的所有消息在分区中所处位置与具体值List<ConsumerRecord<String,String>> partitionRecords = records.records(partition);for(ConsumerRecord<String,String> record : partitionRecords){System.out.println(record.offset()+" "+ record.value());}// 获取当前分区的offset,即最后一条消息的offsetlong lastOffset = partitionRecords.get(partitionRecords.size()-1).offset();// 同步提交消费者的偏移量,将消费者当前的偏移量位置提交给 Kafka,以标记已经成功消费到的消息。
consumer.commitSync(Collections.singletonMap(partition,newOffsetAndMetadata(lastOffset +1)));}}

6. 精确一次
生产者:
开启幂等参数,只生产某消息一次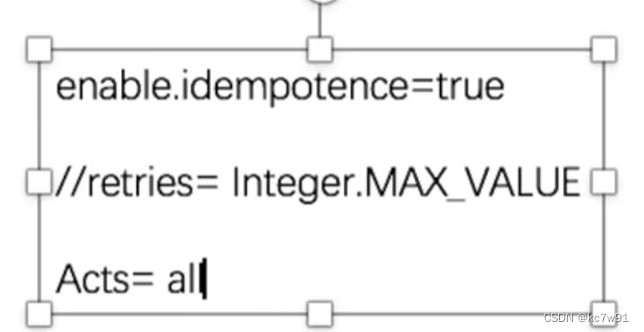
消费者:

7. 事务

kafka消费者端在默认的隔离级别下是可以读到消费者没有成功生产(提交)的数据的

解决:修改事务隔离级别

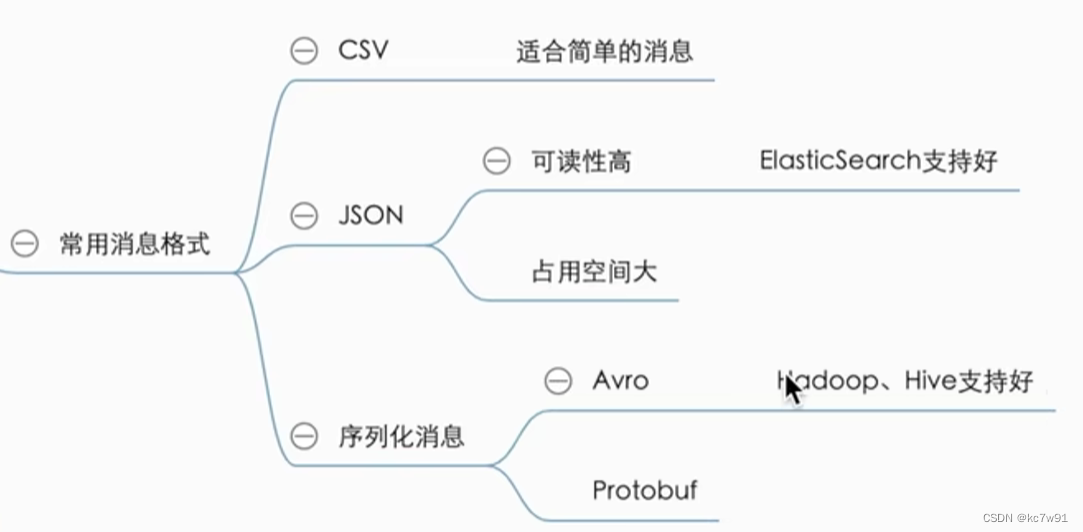
8. Avro序列化
把要传输的消息进行序列化与反序列化
实现跨平台、跨语言
以avro为例:
举例:要传输的数据是user
(1)定义配置文件,生成对应对象:
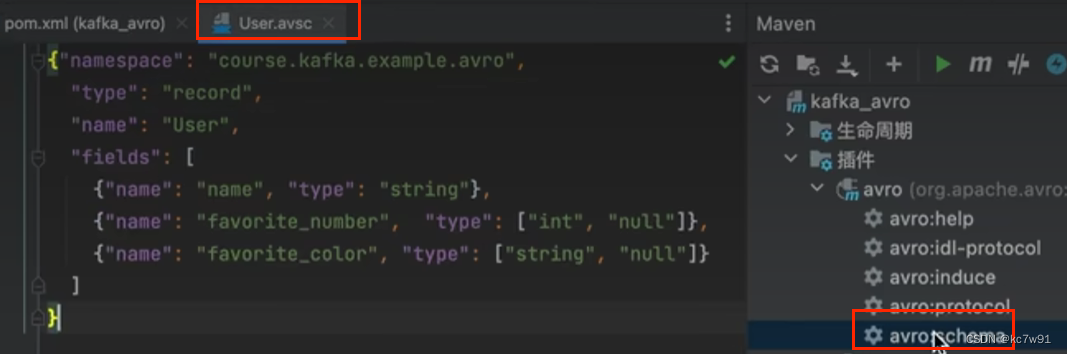
生成序列化的user(不能编辑):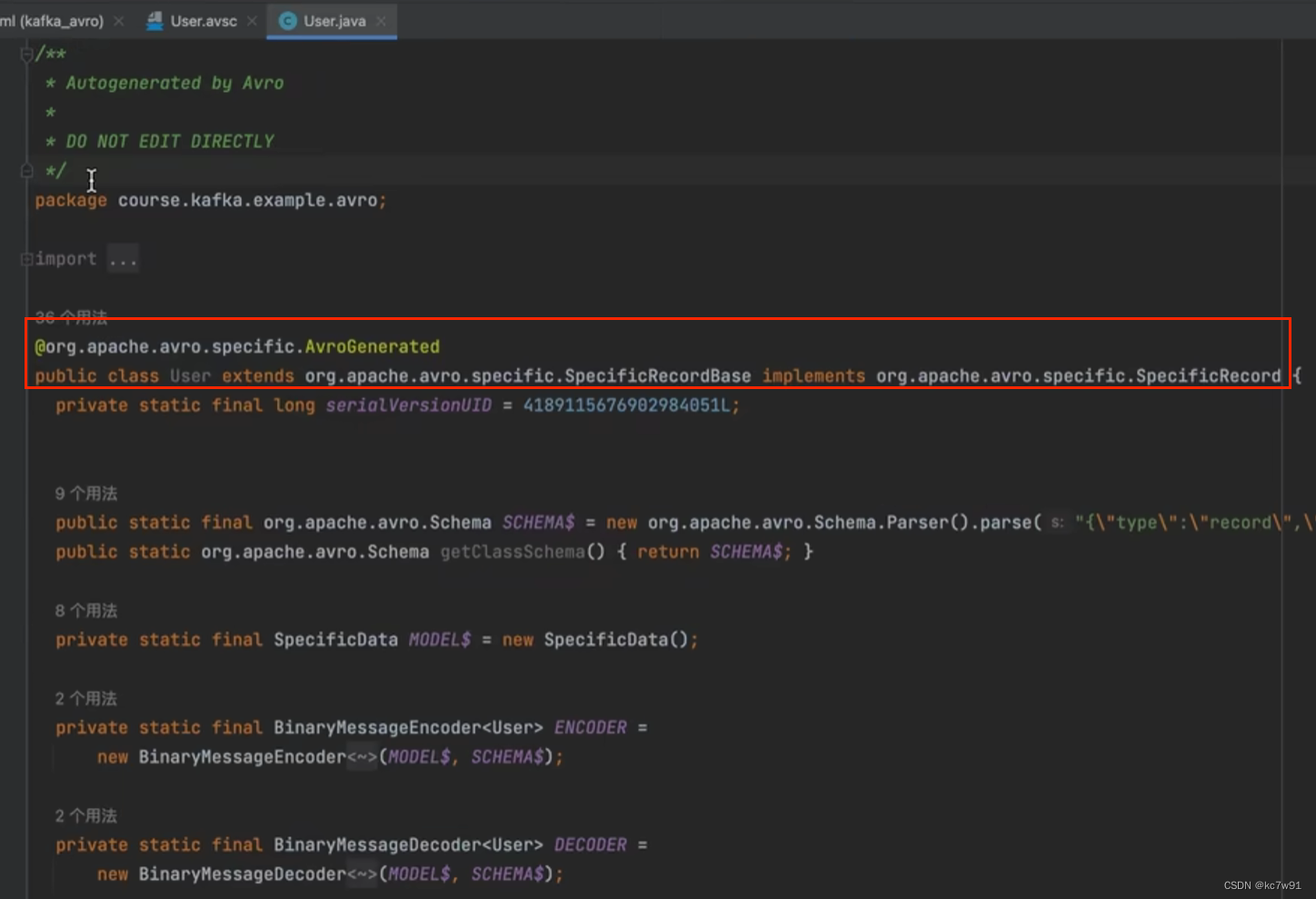
(2)生产者代码:
先定义序列化编码器
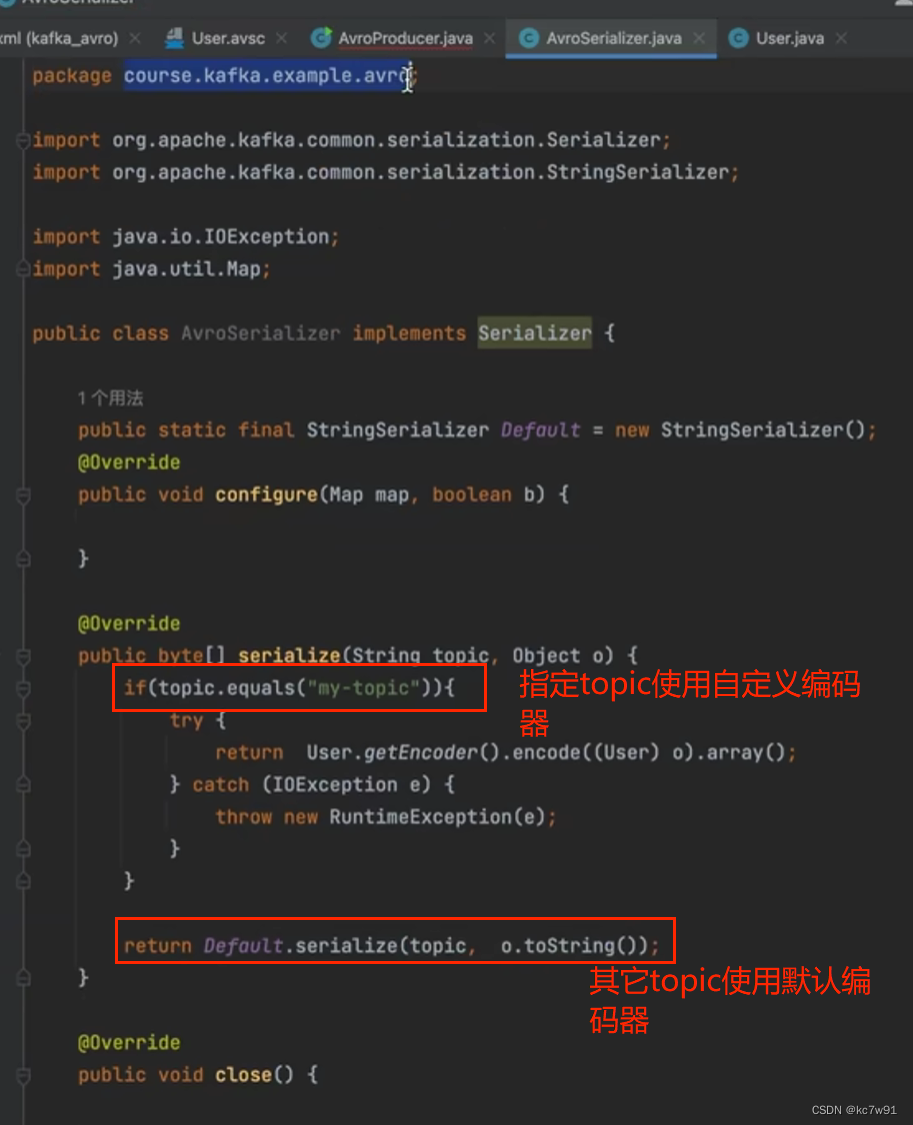
然后写生产者逻辑:
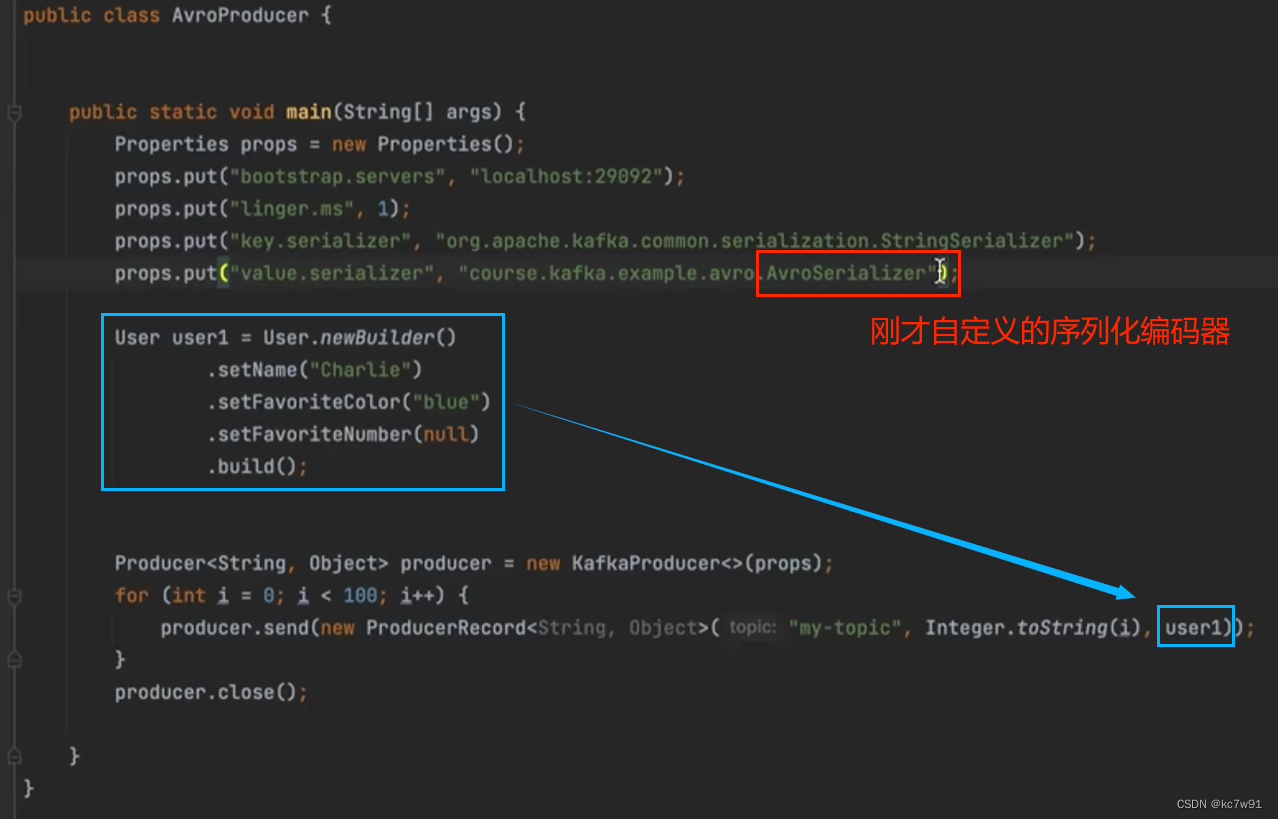
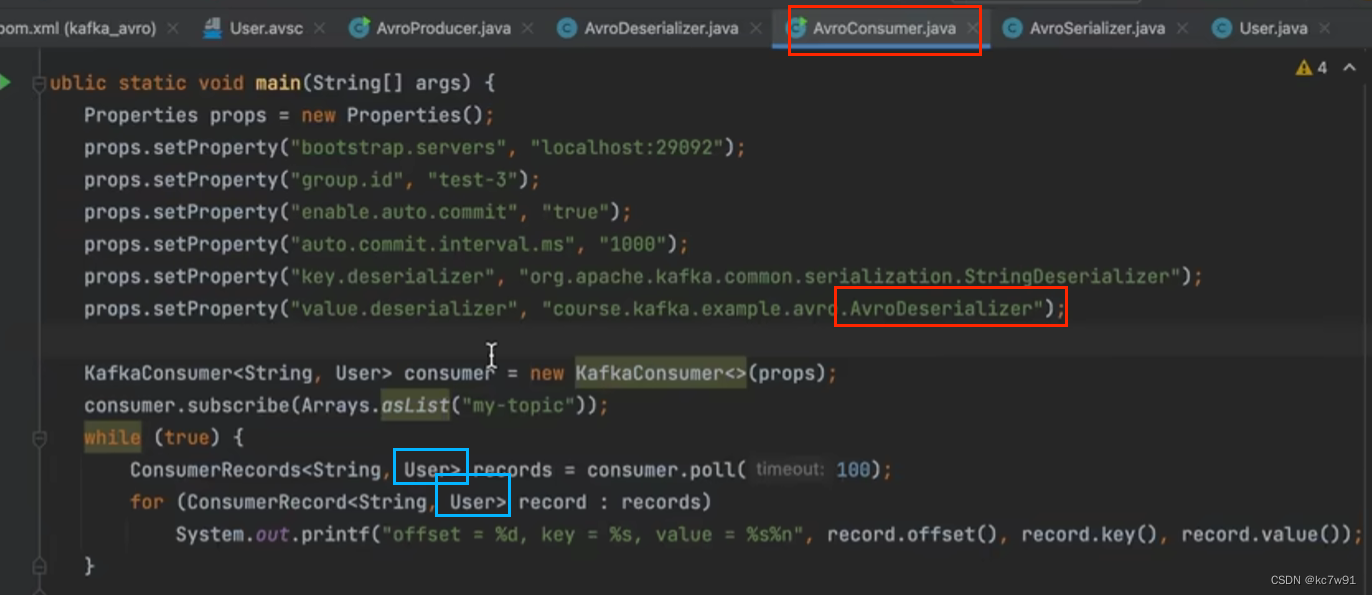
(3)消费者代码
先创建自定义序列化解码器
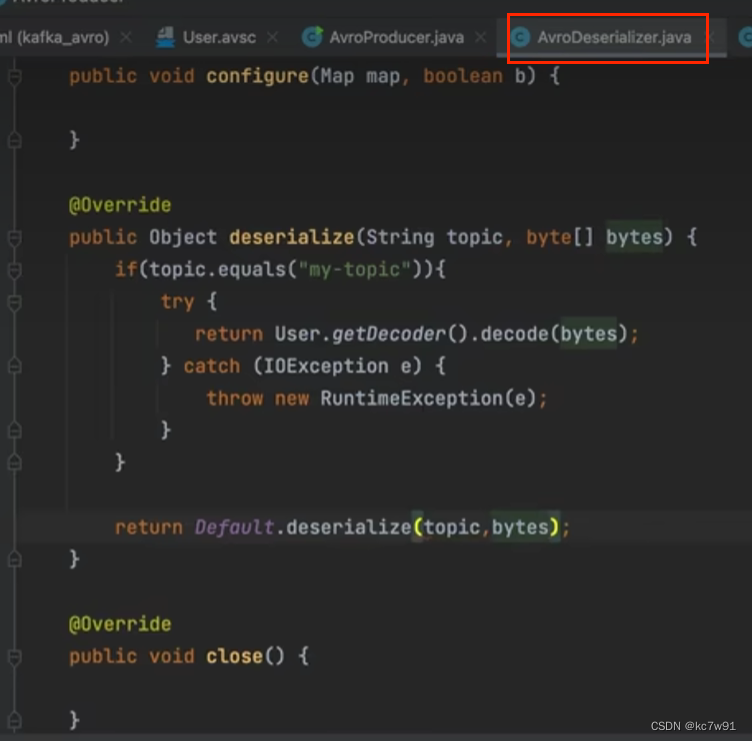
然后写消费者逻辑:
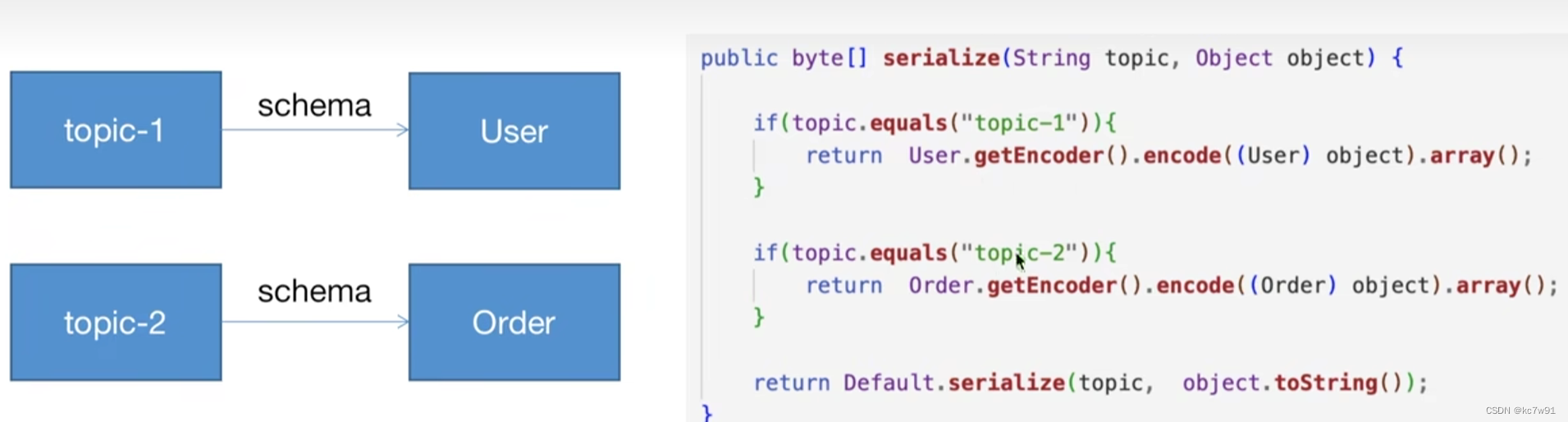
理想情况下一个topic对应一个schema
版权归原作者 kc7w91 所有, 如有侵权,请联系我们删除。