
文章目录
一、前言
本文主要讲解kafka stream和kafka interceptor,kafka stream是一个实时的流客户端,可以从kafka-server某个topic取数据,也可以从发送数据到kafka-server某个topic,只要kafka-stream之后一直运行不停止,就可以一次建立连接,永远取kafka交互。工程中,只要集成了kafka stream的Java程序可以实时取到指定input-topic上的消息实体,且可以将消息加工之后,实时地将消息发送到output-topic。
kafka interceptor是一个在发送消息之前的拦截器,可以修改这个消息/记录的topic、partition、key、value、timestamp五个属性,而且拦截器还可以知道此消息是否发送成功。
kafka partition类似拦截器,也是在发送消息之前设置,可以自定义消息发送到哪个partition。springboot集成kafka和集成其他中间件一样,基本上导入pom依赖,配置好application.yaml文件,然后配置@Configuration修饰就好了。
本文源代码:kafka stream与interceptor、自定义partition、springboot集成kafka
二、Kafka四个核心API
第一篇博文中(解开Kafka神秘的面纱(一):kafka架构与应用场景),介绍过Kafka最重要的四个核心API是Producer API、Consumer API、Streams API、Connector API,四者的关系如下图: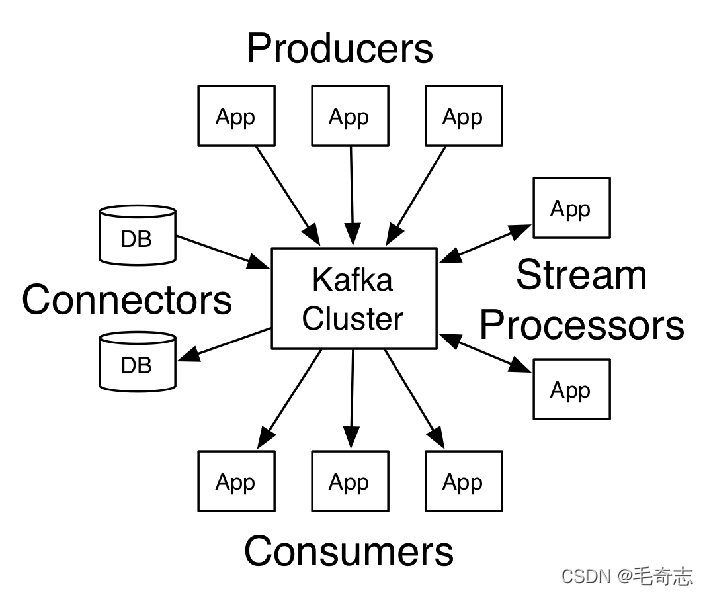
Producer API、Consumer API就是生产者和消费者,很容易理解,Connector API主要侧重kafka可以和其他数据源交互(各种关系型数据库和非关系型数据库),比较简单,本文介绍的是Streams API,主要包括stream和interceptor两个部分,就是上图右边的stream和processors。
kafka开发中,针对四种核心api,涉及到kafka的三个依赖存根。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.13</artifactId><version>2.1.1</version></dependency>
这是kafka核心包2.1.1是kafka的版本,2.13是这个kafka所依赖的scala版本。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.1.1</version></dependency>
这个是kafka客户端包,主要封装了producer consumer两个api。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>2.1.1</version></dependency>
这个是streams依赖,主要封装了stream interceptor依赖。
三、kafka stream
3.1 Kafka Streams概述
Kafka Streams是一个客户端库,用于构建任务关键型实时应用程序和微服务,其中输入输出数据存储在Kafka集群中。Kafka Streams结合了在客户端编写和部署标准Java和Scala应用程序的简单性以及Kafka服务器端集群技术的优势,使这些应用程序具有高度可扩展性,弹性,容错性,分布式等等。Kafka Streams具有如下特点:
(1) 功能强大:高扩展性,弹性,容错
(2) 轻量级:无需专门的集群,一个库,而不是框架
(3) 完全集成:100%的Kafka 0.10.0版本兼容,易于集成到现有的应用程序
(4) 实时性:毫秒级延迟、并非微批处理、窗口允许乱序数据、允许迟到数据
3.2 为什么要有Kafka Streams
为什么要引入kafka stream?因为kafka是一个流式存储系统(这里的流不要理解为Java IO流),每个消息由 index+value+timestamp 构成,但是不能直接用cat命令查看,如图:

因为是流式存储,如果想要在程序看到消息实体,需要使用kafka stream;而且之前kafka消费者是对生产者生产的消息直接消费,生产者生产什么样的消息,消费者就消费什么样的消息,如下图:

现在,如果有了kafka stream,不仅可以在程序中拿到消息实体,还可以在程序对消息加工之后,在交给消费者消费。
即之前是 kafka创建一个topic,然后生产者向这个topic发送消息,消费者从这个topic取消息,生产者生产什么消息,什么消息就存到topic的partition上,然后消费者原封不动的将指定名称的topic上面的消息取下来(kafka上消息不会删除,只是移动offset,默认七天后删除)。
现在是创建两个topic,input-topic和output-topic,并提供一个集成了kafka stream的Java程序,从input-topic取数据,然后加工数据,将加工好的数据放到output-topic上,最后启动生产者向 input-topic 上发送消息,启动消费者取 output-topic 上的消息,既然是从 output-topic 上取,取到的当然是经过 kafka stream 程序加工之后的消息。
eg: 之前rabbitmq消息是可以直接看到,但是现在kafka流式存储不行。
3.3 单词统计案例
以下是WordCountDemo示例代码的要点(为了方便阅读,使用的是java8 lambda表达式)。
第一步:启动zk和kafka
./zkServer.sh start
./bin/kafka-server-start.sh config/server.properties
第二步:准备输入主题并启动生产者
创建名为streams-plaintext-input的输入主题和名为streams-wordcount-output的输出主题:
创建一个输入topic
./bin/kafka-topics.sh --create --bootstrap-server 192.168.100.120:9092 --topic stream-plaintext-input --partitions 1 --replication-factor 1
创建一个输出topic并启用压缩,因为输出流是更改日志流
./bin/kafka-topics.sh --create --bootstrap-server 192.168.100.120:9092 --topic stream-wordcount-output --partitions 1 --replication-factor 1 --config cleanup.policy=compact
使用相同的kafka-topics工具描述创建的主题:
./bin/kafka-topics.sh --zookeeper 192.168.100.120:2181 --describe
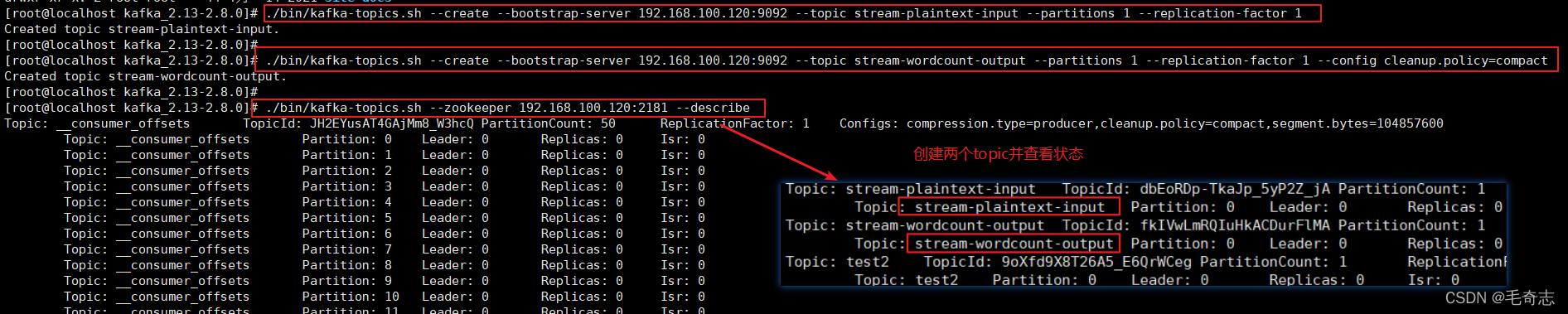
也可以直接查看两个topic是否创建好了
./bin/kafka-topics.sh --bootstrap-server 192.168.100.120:9092 --list
第三步:启动Wordcount应用程序
./bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
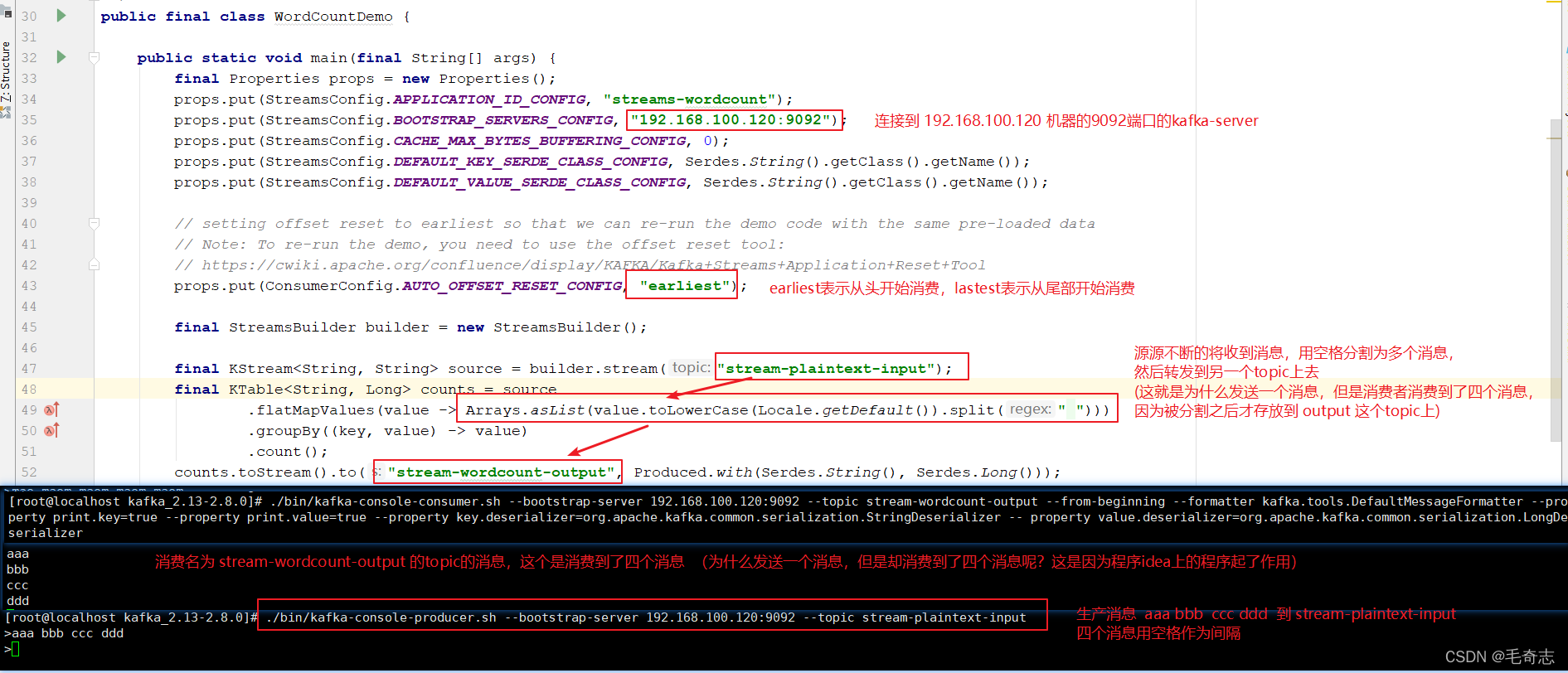
演示应用程序将从输入主题stream-plaintext-input读取,对每个读取消息执行WordCount算法的计算,并将其当前结果连续写入输出主题streams-wordcount-output。
注意:在kafka解压目录的libs包目录下,这里存在一个 kafka-stream-examples-2.8.0.jar,这个jar包就是kafka官方提供的一个演示kafka stream的examples,如下图:

这个jar包解压之后,里面有一个
org.apache.kafka.streams.examples.wordcount.WordCountDemo
类,这个类的作用是对生产者发送的消息统计,这个类监听的生产者topic是
streams-plaintext-input
,消费者topic是
streams-wordcount-output
,如下


直接在centos上运行
./bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
这个程序有时候会连不上 127.0.0.1:9092 本机kafka,我们可以将 kafka-stream-examples-2.8.0.jar 在自己电脑上解压,将 WordCountDemo 类单独拿出来,放在idea上运行,如下:
第四步:启动生产者和消费者
启动生产者:
./bin/kafka-console-producer.sh --bootstrap-server 192.168.100.120:9092 --topic stream-plaintext-input
启动消费者:
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.100.120:9092 --topic stream-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer -- property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
运行结果:
四、kafka interceptor
4.1 拦截器原理
Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。拦截器只是对于producer而言(一定不是针对consumer而言的,当消息已经到了消费阶段,这个消息早就存放到kafka-server了),interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。
同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor,如下:
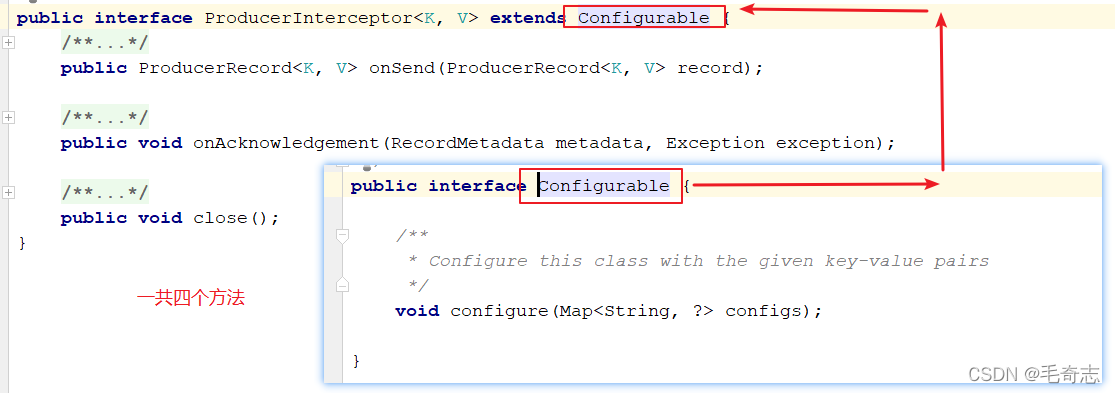
解释上面四个方法:
(1)configure(configs):获取配置信息和初始化数据时调用。
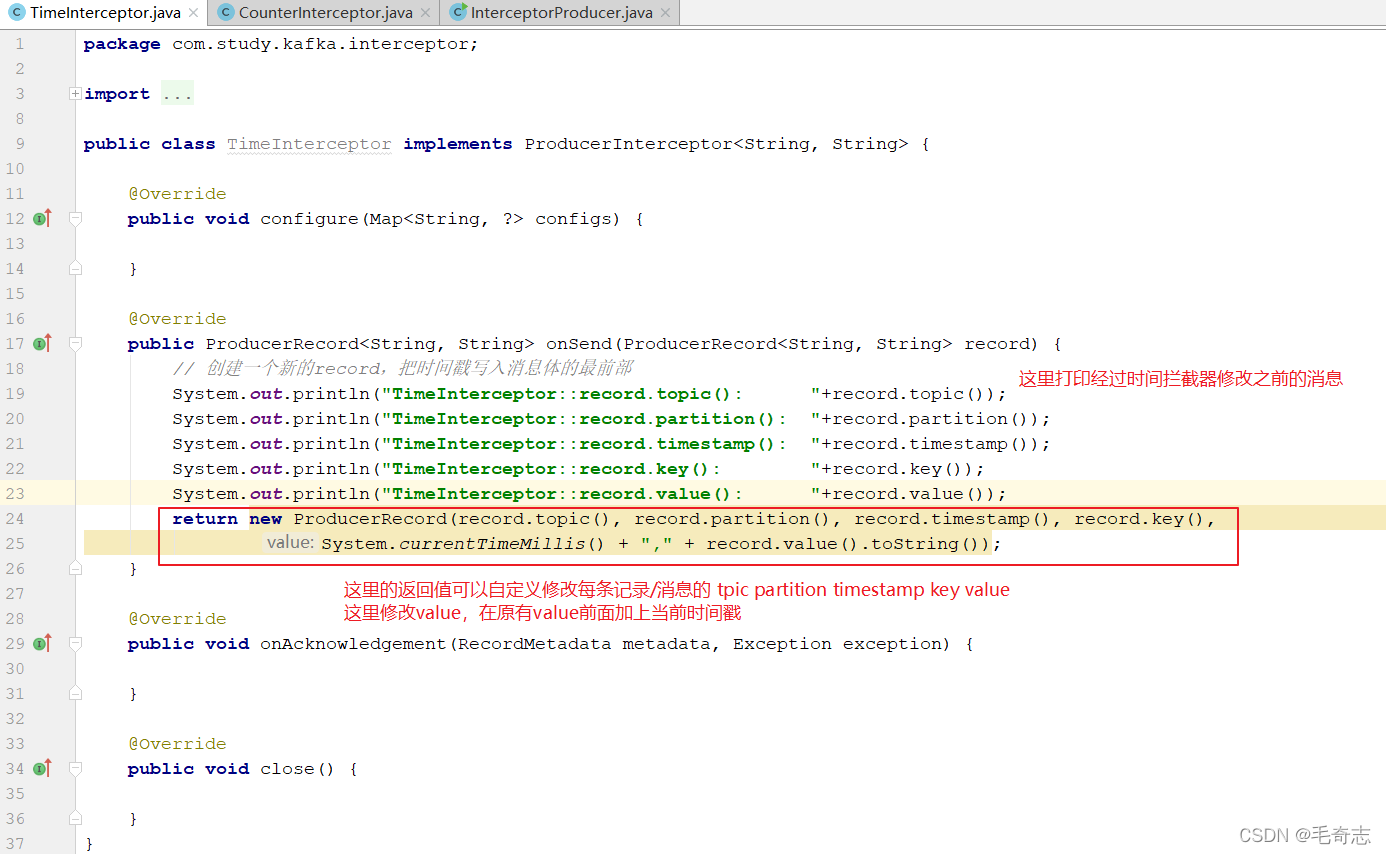
(2)onSend(ProducerRecord):该方法封装进KafkaProducer.send方法中,即它运行在用户主线程中。Producer 确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,包括topic partition index value timestamp但最好保证不要修改消息所属的topic和分区partition,否则会影响目标分区的计算。
(3)onAcknowledgement(RecordMetadata, Exception):该方法会在消息被应答或消息发送失败时调用,并且通常都是在producer回调逻辑触发之前。onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率。
(4)close:该方法用来关闭interceptor,主要用于执行一些资源清理工作。
如前所述,interceptor可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个interceptor,则producer将按照指定顺序调用它们,并仅仅是捕获每个interceptor可能抛出的异常记录到错误日志中而非在向上传递。这在使用过程中要特别留意。
interceptor和stream区别:stream是取input-topic的数据,加工数据之后,无法将加工之后的数据重新插入到input-topic中去,只能放到另一个output-topic中去,但是,有了interceptor之后,可以取input-topic的数据,加工数据之后,再将加工之后的数据重新插入到input-topic中去。而且,还可以定制化消息存放在某个partition,比如,可以将partition-0的消息拿出来,放到partition-1中去。
4.2 拦截器案例
4.2.1 需求
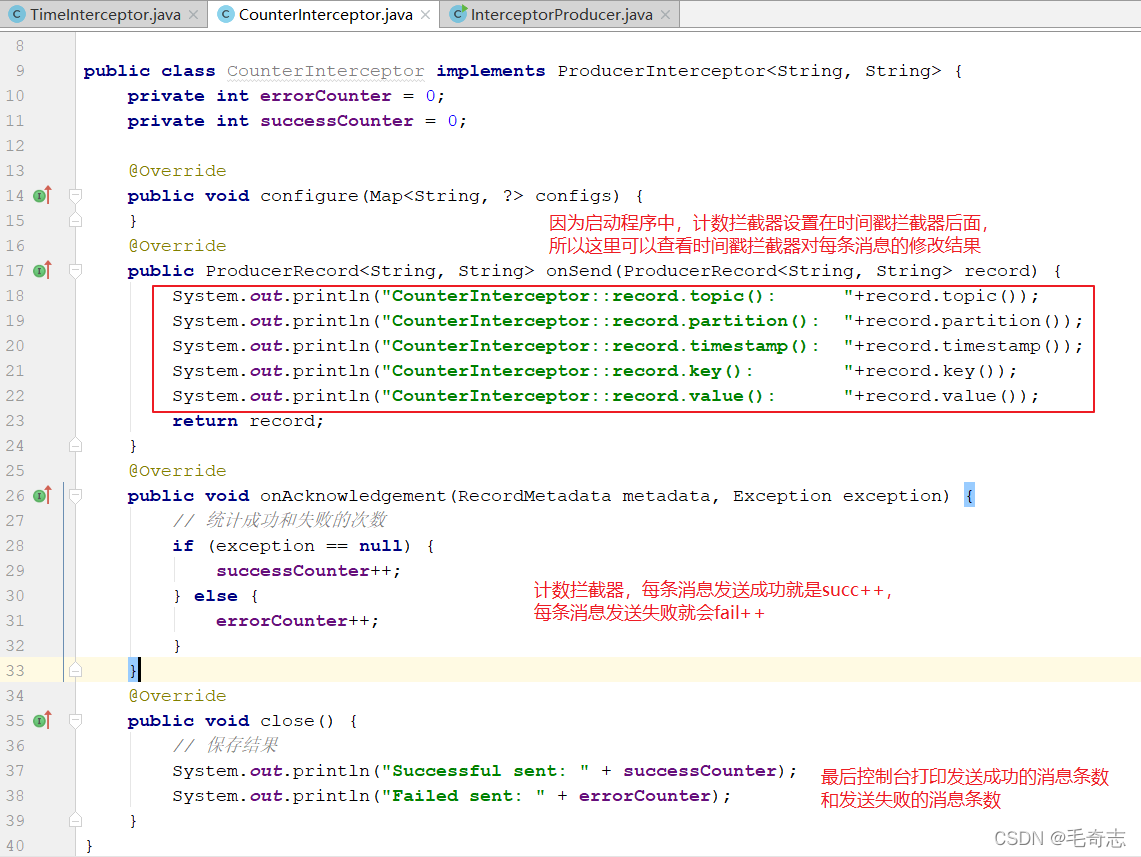
需求:实现一个简单的双interceptor组成的拦截链。第一个interceptor会在消息发送前将时间戳信息加到消息value的最前部;第二个interceptor会在消息发送后更新成功发送消息数或失败发送消息数,即
每条消息先到TimeInterceptor,然后再到CountInterceptor,最后在发送出去。
4.2.2 案例实操
涉及的类包括三个,两个拦截器和一个主程序
第一个程序:时间戳拦截器
public class TimeInterceptor implements ProducerInterceptor<String, String>
第二个程序:计数拦截器,统计发送消息成功和发送失败消息数,并在producer关闭时打印这两个计数器
public class CounterInterceptor implements ProducerInterceptor<String, String>
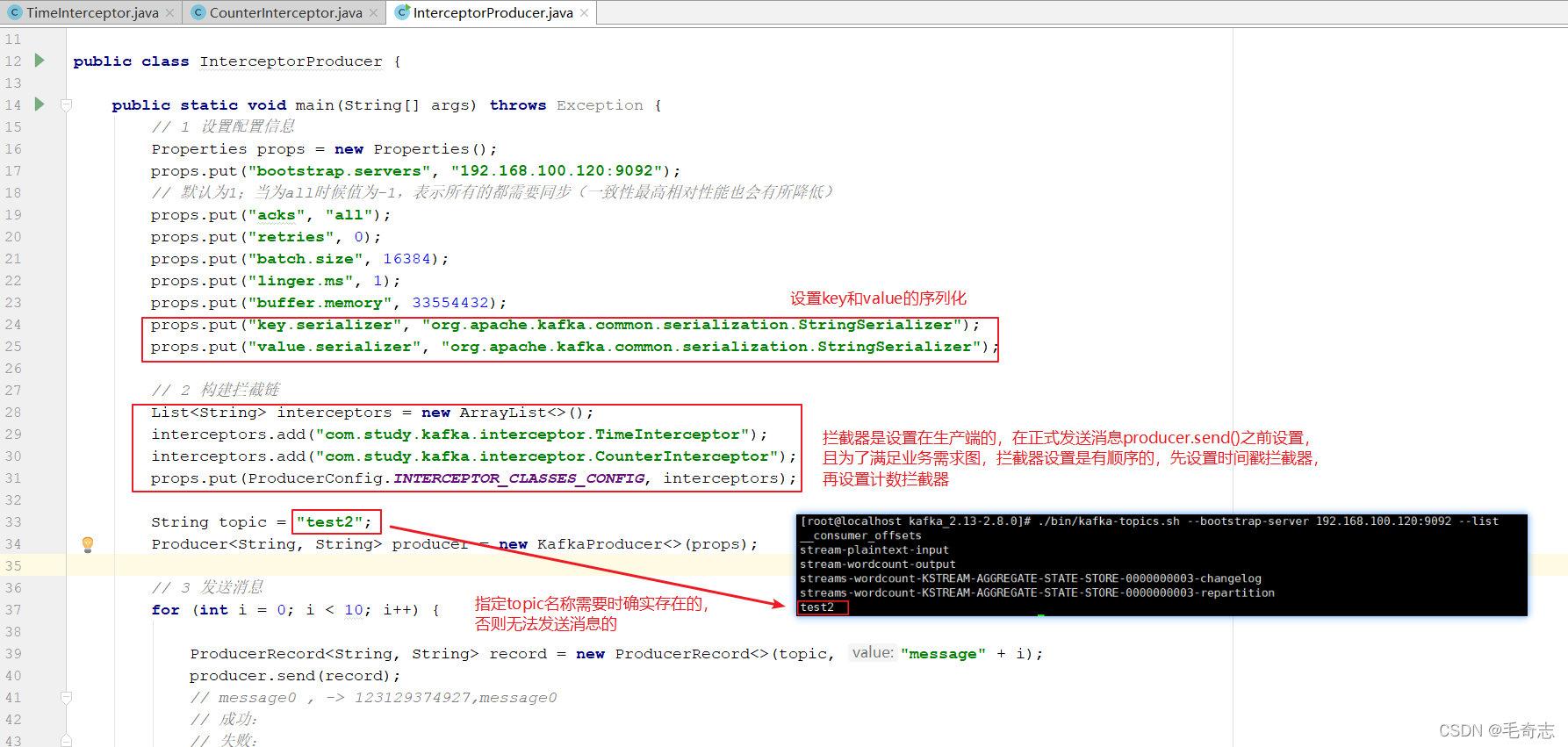
第三个程序:producer主程序
public class InterceptorProducer
4.2.3 测试
第一步:运行客户端InterceptorProducer主程序
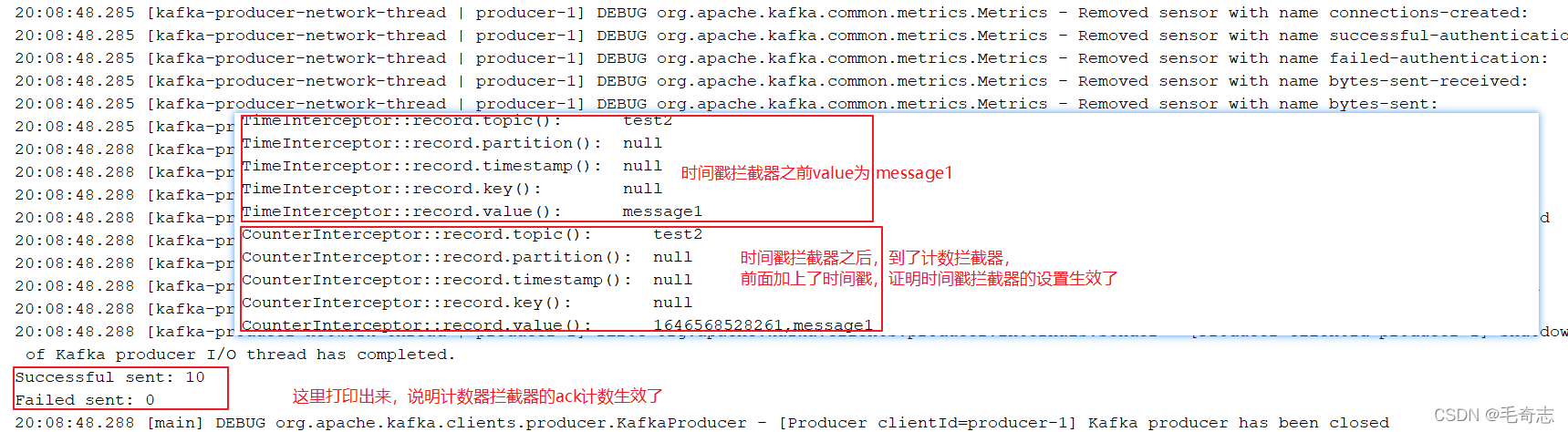
第二步:在kafka上启动消费者
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.100.120:9092 --topic test2 --from-beginning

4.3 kafka自定义分区
自定义分区和interceptor一样,也是生产端的,就是指定key的消息发送到某个partition。
如果一个topic拥有多个分区,但是,消息被发送给kafka的时候,只是指定了topic的名称,就是这条消息应该发送给哪个topic,消息消费也是指定topic的,partition这个概念是对客户端透明的,客户端生产消息和消费消息都不会涉及到。
那么,当一个topic拥有多个分区,某条消息具体存放到哪个partition上面呢?kafka有自己的默认规则,这个默认规则就在源码 DefaultPartitioner 类里面,如下图:
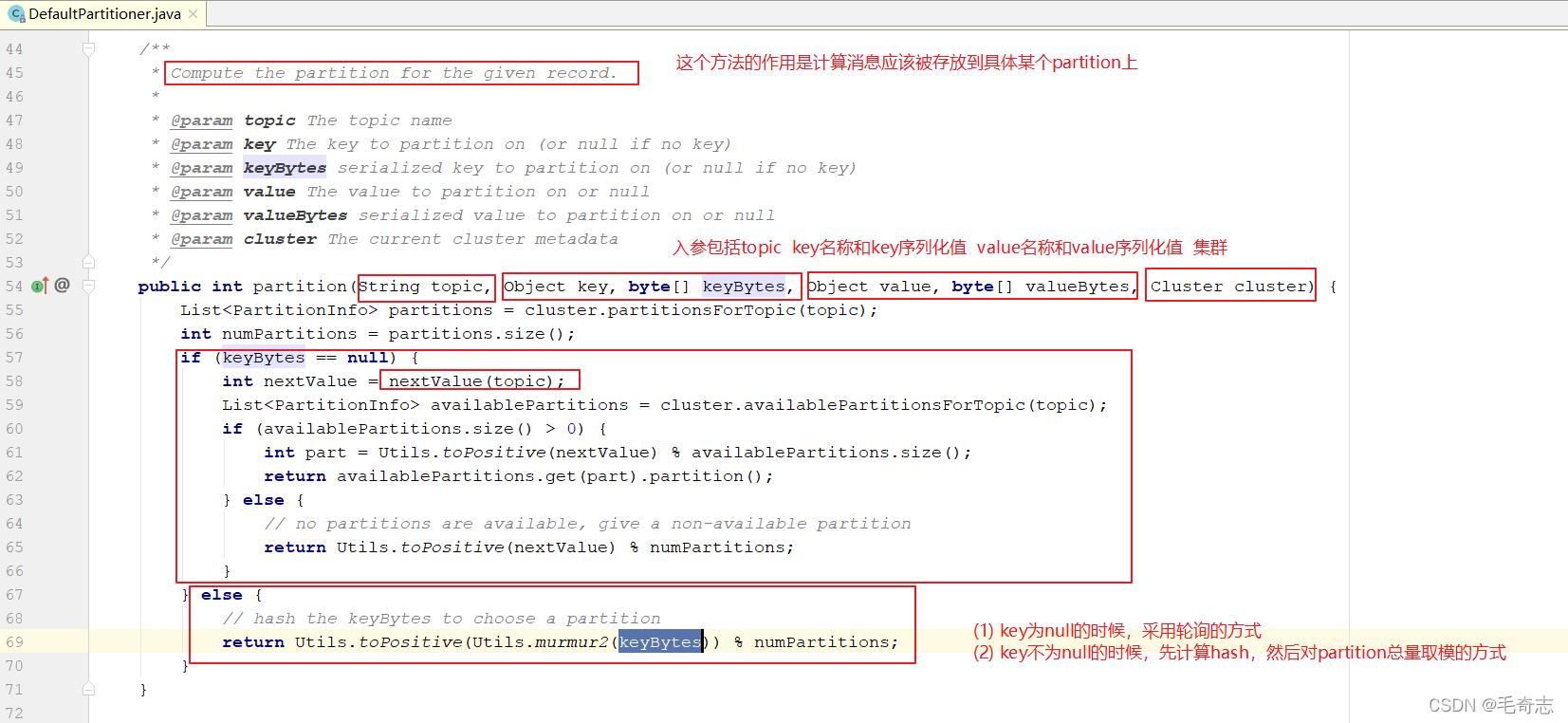
好了,现在我们可以实现Partitioner接口得到一个自定义的MyPartitioner类,然后
新建一个topic,名为test3,拥有三个partition
./bin/kafka-topics.sh --create --topic test3 --bootstrap-server 192.168.100.120:9092 --partitions 3 --replication-factor 1
./bin/kafka-topics.sh --bootstrap-server 192.168.100.120:9092 --list
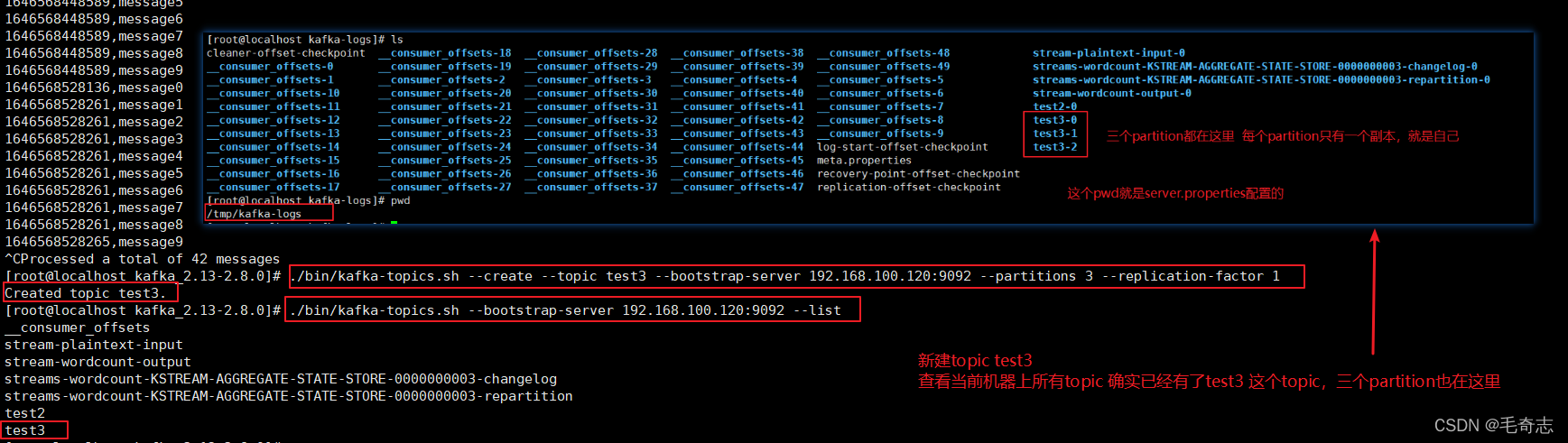
运行成功,自定义partition为1,10条消息都发送到了1上面去了
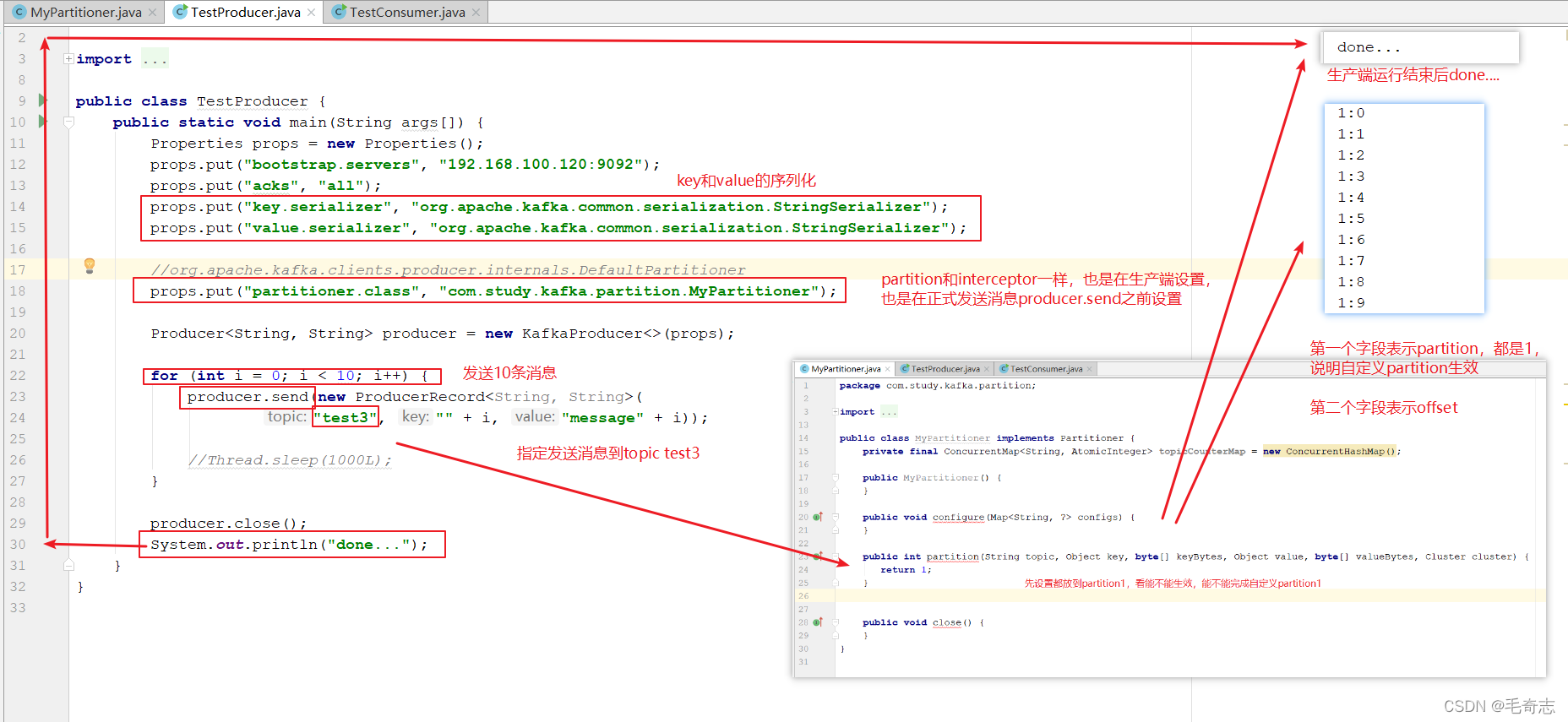
eg: interceptor 和 partion 都是生产端,所以都是在生产代码里面修改。
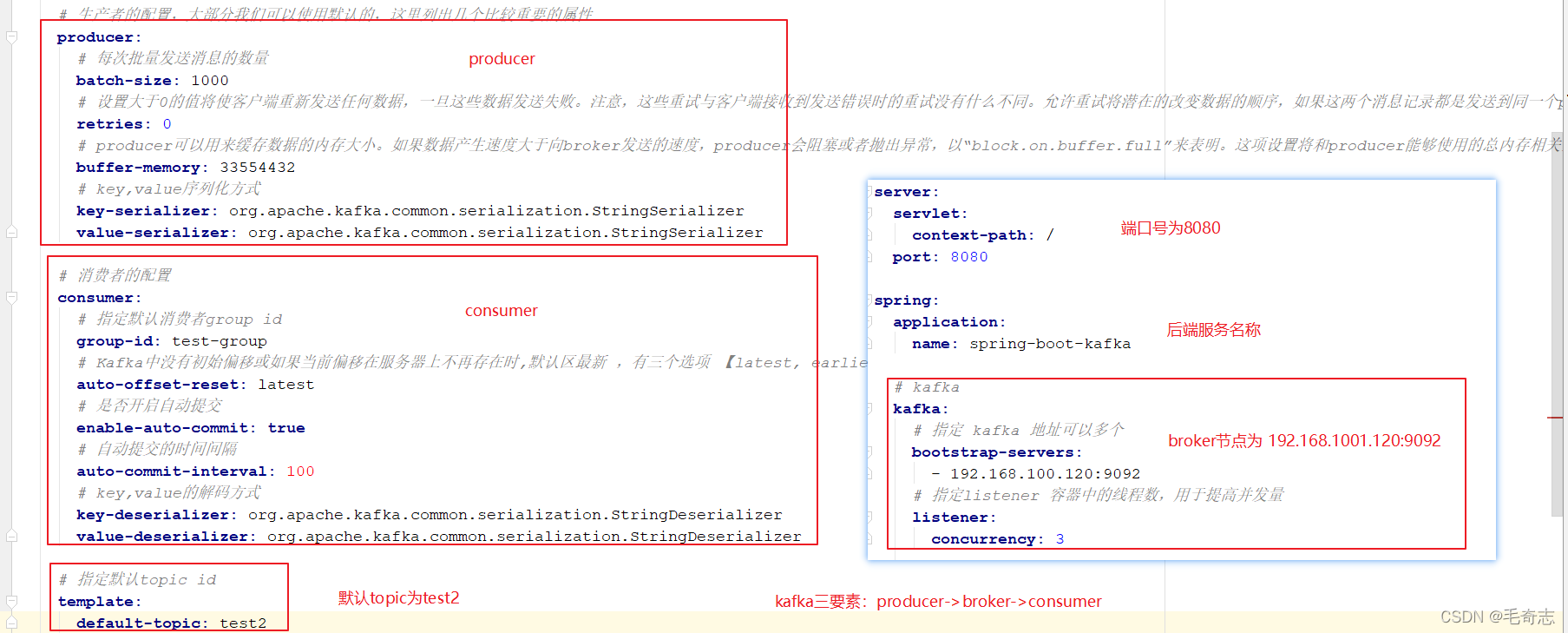
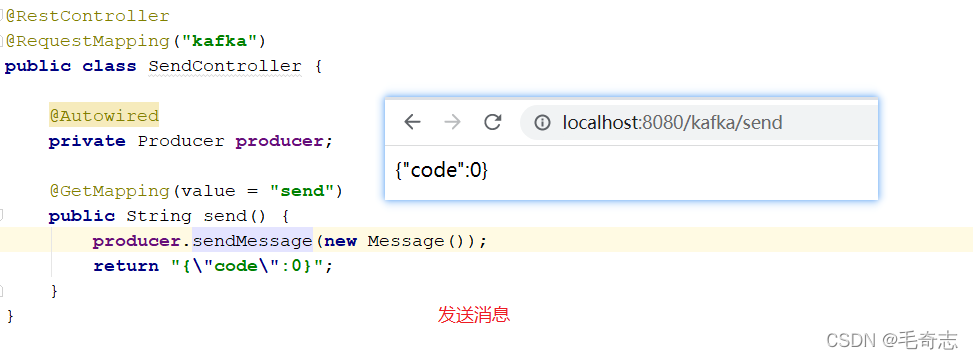
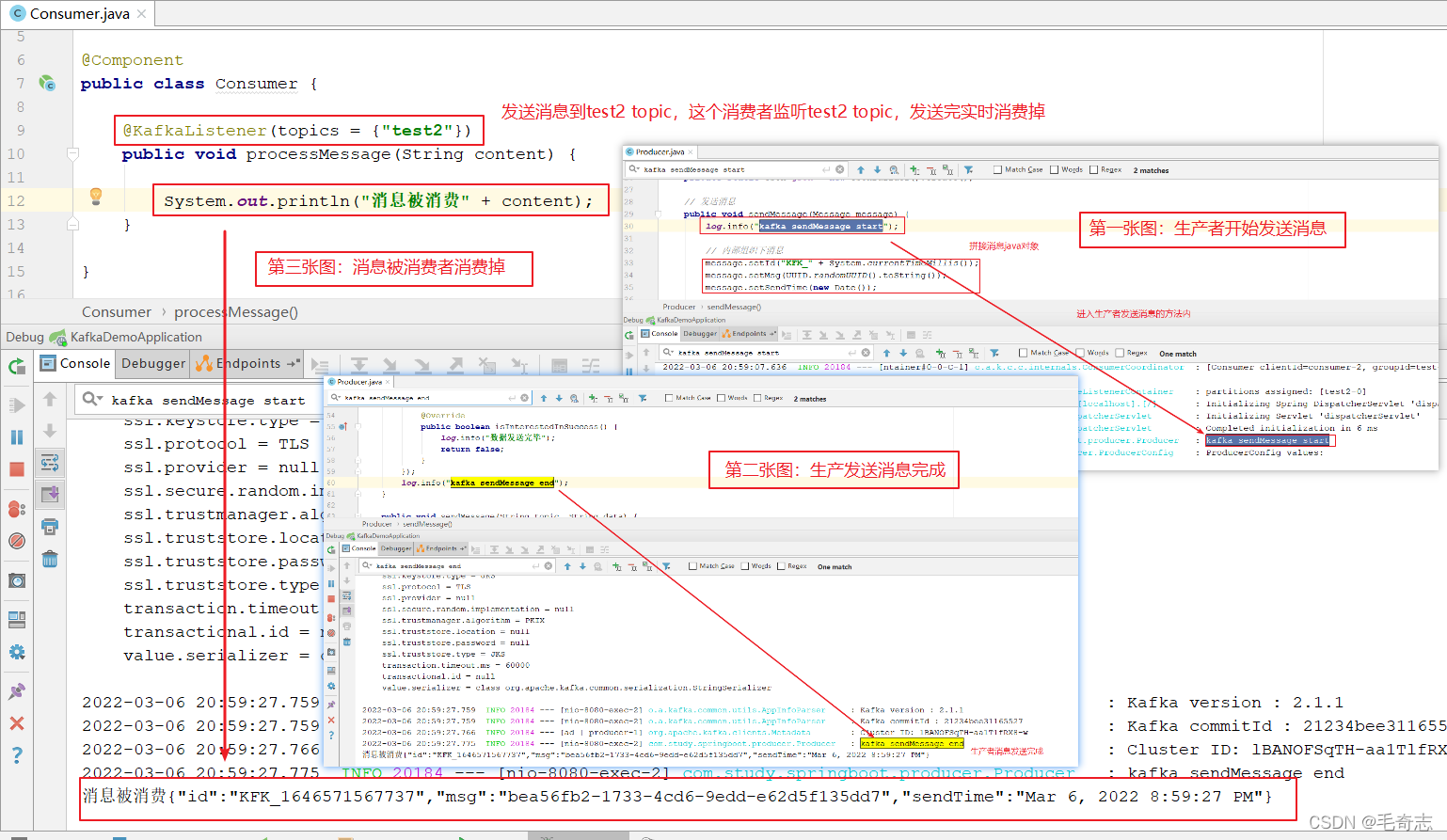
4.4 springboot集成kafka
四、尾声
本文主要介绍了kafka stream和kafka interceptor。
天天打码,天天进步!!
本文源代码:kafka stream与interceptor、自定义partition、springboot集成kafka
版权归原作者 毛奇志 所有, 如有侵权,请联系我们删除。