
文章目录
0 前言
🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 毕业设计 基于深度学习的新闻文本分类算法系统(源码+论文)
🥇学长这里给一个题目综合评分(每项满分5分)
难度系数:3分
工作量:3分
创新点:4分
🧿 项目分享:见文末!
1 项目运行效果
视频效果:
毕业设计 深度学习验证码识别
2 原理介绍
这里做一个简单的识别demo说明项目原理,实际项目比demo复杂一些。
在python爬虫爬取某些网站的验证码的时候可能会遇到验证码识别的问题,现在的验证码大多分为四类:
- 1、计算验证码
- 2、滑块验证码
- 3、识图验证码
- 4、语音验证码
学长这李主要写的就是识图验证码,识别的是简单的验证码,要想让识别率更高,识别的更加准确就需要花很多的精力去训练自己的字体库。
3 验证码识别步骤
1、灰度处理
2、二值化
3、去除边框(如果有的话)
4、降噪
5、切割字符或者倾斜度矫正
6、训练字体库
7、识别
这6个步骤中前三个步骤是基本的,4或者5可根据实际情况选择是否需要,并不一定切割验证码,识别率就会上升很多有时候还会下降
这篇博客不涉及训练字体库的内容,请自行搜索。同样也不讲解基础的语法。
用到的几个主要的python库: Pillow(python图像处理库)、OpenCV(高级图像处理库)、pytesseract(识别库)
3.1 灰度处理&二值化
灰度处理,就是把彩色的验证码图片转为灰色的图片。
二值化,是将图片处理为只有黑白两色的图片,利于后面的图像处理和识别
在OpenCV中有现成的方法可以进行灰度处理和二值化,处理后的效果:

# 自适应阀值二值化def_get_dynamic_binary_image(filedir, img_name):
filename ='./out_img/'+ img_name.split('.')[0]+'-binary.jpg'
img_name = filedir +'/'+ img_name
print('.....'+ img_name)
im = cv2.imread(img_name)
im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)#灰值化# 二值化
th1 = cv2.adaptiveThreshold(im,255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY,21,1)
cv2.imwrite(filename,th1)return th1
3.2 去除边框
如果验证码有边框,那我们就需要去除边框,去除边框就是遍历像素点,找到四个边框上的所有点,把他们都改为白色,我这里边框是两个像素宽
注意:在用OpenCV时,图片的矩阵点是反的,就是长和宽是颠倒的
代码:
# 去除边框defclear_border(img,img_name):
filename ='./out_img/'+ img_name.split('.')[0]+'-clearBorder.jpg'
h, w = img.shape[:2]for y inrange(0, w):for x inrange(0, h):if y <2or y > w -2:
img[x, y]=255if x <2or x > h -2:
img[x, y]=255
cv2.imwrite(filename,img)return img
效果

3.3 图像降噪
降噪是验证码处理中比较重要的一个步骤,我这里使用了点降噪和线降噪
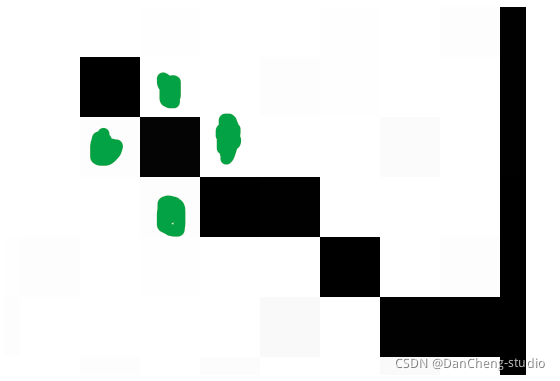
线降噪的思路就是检测这个点相邻的四个点(图中标出的绿色点),判断这四个点中是白点的个数,如果有两个以上的白色像素点,那么就认为这个点是白色的,从而去除整个干扰线,但是这种方法是有限度的,如果干扰线特别粗就没有办法去除,只能去除细的干扰线
# 干扰线降噪definterference_line(img, img_name):
filename ='./out_img/'+ img_name.split('.')[0]+'-interferenceline.jpg'
h, w = img.shape[:2]# !!!opencv矩阵点是反的# img[1,2] 1:图片的高度,2:图片的宽度for y inrange(1, w -1):for x inrange(1, h -1):
count =0if img[x, y -1]>245:
count = count +1if img[x, y +1]>245:
count = count +1if img[x -1, y]>245:
count = count +1if img[x +1, y]>245:
count = count +1if count >2:
img[x, y]=255
cv2.imwrite(filename,img)return img
点降噪的思路和线降噪的差不多,只是会针对不同的位置检测的点不一样,注释写的很清楚了
# 点降噪definterference_point(img,img_name, x =0, y =0):"""
9邻域框,以当前点为中心的田字框,黑点个数
:param x:
:param y:
:return:
"""
filename ='./out_img/'+ img_name.split('.')[0]+'-interferencePoint.jpg'# todo 判断图片的长宽度下限
cur_pixel = img[x,y]# 当前像素点的值
height,width = img.shape[:2]for y inrange(0, width -1):for x inrange(0, height -1):if y ==0:# 第一行if x ==0:# 左上顶点,4邻域# 中心点旁边3个点sum=int(cur_pixel) \
+int(img[x, y +1]) \
+int(img[x +1, y]) \
+int(img[x +1, y +1])ifsum<=2*245:
img[x, y]=0elif x == height -1:# 右上顶点sum=int(cur_pixel) \
+int(img[x, y +1]) \
+int(img[x -1, y]) \
+int(img[x -1, y +1])ifsum<=2*245:
img[x, y]=0else:# 最上非顶点,6邻域sum=int(img[x -1, y]) \
+int(img[x -1, y +1]) \
+int(cur_pixel) \
+int(img[x, y +1]) \
+int(img[x +1, y]) \
+int(img[x +1, y +1])ifsum<=3*245:
img[x, y]=0elif y == width -1:# 最下面一行if x ==0:# 左下顶点# 中心点旁边3个点sum=int(cur_pixel) \
+int(img[x +1, y]) \
+int(img[x +1, y -1]) \
+int(img[x, y -1])ifsum<=2*245:
img[x, y]=0elif x == height -1:# 右下顶点sum=int(cur_pixel) \
+int(img[x, y -1]) \
+int(img[x -1, y]) \
+int(img[x -1, y -1])ifsum<=2*245:
img[x, y]=0else:# 最下非顶点,6邻域sum=int(cur_pixel) \
+int(img[x -1, y]) \
+int(img[x +1, y]) \
+int(img[x, y -1]) \
+int(img[x -1, y -1]) \
+int(img[x +1, y -1])ifsum<=3*245:
img[x, y]=0else:# y不在边界if x ==0:# 左边非顶点sum=int(img[x, y -1]) \
+int(cur_pixel) \
+int(img[x, y +1]) \
+int(img[x +1, y -1]) \
+int(img[x +1, y]) \
+int(img[x +1, y +1])ifsum<=3*245:
img[x, y]=0elif x == height -1:# 右边非顶点sum=int(img[x, y -1]) \
+int(cur_pixel) \
+int(img[x, y +1]) \
+int(img[x -1, y -1]) \
+int(img[x -1, y]) \
+int(img[x -1, y +1])ifsum<=3*245:
img[x, y]=0else:# 具备9领域条件的sum=int(img[x -1, y -1]) \
+int(img[x -1, y]) \
+int(img[x -1, y +1]) \
+int(img[x, y -1]) \
+int(cur_pixel) \
+int(img[x, y +1]) \
+int(img[x +1, y -1]) \
+int(img[x +1, y]) \
+int(img[x +1, y +1])ifsum<=4*245:
img[x, y]=0
cv2.imwrite(filename,img)return img
效果:
其实到了这一步,这些字符就可以识别了,没必要进行字符切割了,现在这三种类型的验证码识别率已经达到50%以上了
3.4 字符切割
字符切割通常用于验证码中有粘连的字符,粘连的字符不好识别,所以我们需要将粘连的字符切割为单个的字符,在进行识别
字符切割的思路就是找到一个黑色的点,然后在遍历与他相邻的黑色的点,直到遍历完所有的连接起来的黑色的点,找出这些点中的最高的点、最低的点、最右边的点、最左边的点,记录下这四个点,认为这是一个字符,然后在向后遍历点,直至找到黑色的点,继续以上的步骤。最后通过每个字符的四个点进行切割
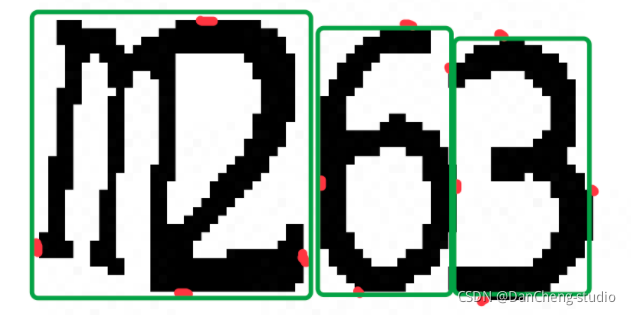
图中红色的点就是代码执行完后,标识出的每个字符的四个点,然后就会根据这四个点进行切割(图中画的有些误差,懂就好)
但是也可以看到,m2是粘连的,代码认为他是一个字符,所以我们需要对每个字符的宽度进行检测,如果他的宽度过宽,我们就认为他是两个粘连在一起的字符,并将它在从中间切割
确定每个字符的四个点代码:
defcfs(im,x_fd,y_fd):'''用队列和集合记录遍历过的像素坐标代替单纯递归以解决cfs访问过深问题
'''# print('**********')
xaxis=[]
yaxis=[]
visited =set()
q = Queue()
q.put((x_fd, y_fd))
visited.add((x_fd, y_fd))
offsets=[(1,0),(0,1),(-1,0),(0,-1)]#四邻域whilenot q.empty():
x,y=q.get()for xoffset,yoffset in offsets:
x_neighbor,y_neighbor = x+xoffset,y+yoffset
if(x_neighbor,y_neighbor)in(visited):continue# 已经访问过了
visited.add((x_neighbor, y_neighbor))try:if im[x_neighbor, y_neighbor]==0:
xaxis.append(x_neighbor)
yaxis.append(y_neighbor)
q.put((x_neighbor,y_neighbor))except IndexError:pass# print(xaxis)if(len(xaxis)==0|len(yaxis)==0):
xmax = x_fd +1
xmin = x_fd
ymax = y_fd +1
ymin = y_fd
else:
xmax =max(xaxis)
xmin =min(xaxis)
ymax =max(yaxis)
ymin =min(yaxis)#ymin,ymax=sort(yaxis)return ymax,ymin,xmax,xmin
defdetectFgPix(im,xmax):'''搜索区块起点
'''
h,w = im.shape[:2]for y_fd inrange(xmax+1,w):for x_fd inrange(h):if im[x_fd,y_fd]==0:return x_fd,y_fd
defCFS(im):'''切割字符位置
'''
zoneL=[]#各区块长度L列表
zoneWB=[]#各区块的X轴[起始,终点]列表
zoneHB=[]#各区块的Y轴[起始,终点]列表
xmax=0#上一区块结束黑点横坐标,这里是初始化for i inrange(10):try:
x_fd,y_fd = detectFgPix(im,xmax)# print(y_fd,x_fd)
xmax,xmin,ymax,ymin=cfs(im,x_fd,y_fd)
L = xmax - xmin
H = ymax - ymin
zoneL.append(L)
zoneWB.append([xmin,xmax])
zoneHB.append([ymin,ymax])except TypeError:return zoneL,zoneWB,zoneHB
return zoneL,zoneWB,zoneHB
切割粘连字符代码:
defcutting_img(im,im_position,img,xoffset =1,yoffset =1):
filename ='./out_img/'+ img.split('.')[0]# 识别出的字符个数
im_number =len(im_position[1])# 切割字符for i inrange(im_number):
im_start_X = im_position[1][i][0]- xoffset
im_end_X = im_position[1][i][1]+ xoffset
im_start_Y = im_position[2][i][0]- yoffset
im_end_Y = im_position[2][i][1]+ yoffset
cropped = im[im_start_Y:im_end_Y, im_start_X:im_end_X]
cv2.imwrite(filename +'-cutting-'+str(i)+'.jpg',cropped)
效果:

3.5 识别
识别用的是typesseract库,主要识别一行字符和单个字符时的参数设置,识别中英文的参数设置,代码很简单就一行,我这里大多是filter文件的操作
# 识别验证码
cutting_img_num =0forfilein os.listdir('./out_img'):
str_img =''if fnmatch(file,'%s-cutting-*.jpg'% img_name.split('.')[0]):
cutting_img_num +=1for i inrange(cutting_img_num):try:file='./out_img/%s-cutting-%s.jpg'%(img_name.split('.')[0], i)# 识别字符
str_img = str_img + image_to_string(Image.open(file),lang ='eng', config='-psm 10')#单个字符是10,一行文本是7except Exception as err:passprint('切图:%s'% cutting_img_num)print('识别为:%s'% str_img)
最后这种粘连字符的识别率是在30%左右,而且这种只是处理两个字符粘连,如果有两个以上的字符粘连还不能识别,但是根据字符宽度判别的话也不难,有兴趣的可以试一下
无需切割字符识别的效果:

需要切割字符的识别效果:

3.6 深度学习的验证码识别
- python库: tensorflow, opencv, pandas, gpu机器。
- 训练集: 10w 图片, 200step左右开始收敛。
- 策略: 切分图片,训练单字母识别。预测时也是同样切分。(ps:不切分训练及识别,跑了一夜,没有收敛)
- 准确率: 在区分大小写的情况下,单字母识别率98%, 整体识别率75%+。
数据集

数据集预处理
package com;import java.awt.Color;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.util.Random;import org.patchca.color.ColorFactory;import org.patchca.filter.predefined.CurvesRippleFilterFactory;import org.patchca.filter.predefined.DiffuseRippleFilterFactory;import org.patchca.filter.predefined.DoubleRippleFilterFactory;import org.patchca.filter.predefined.MarbleRippleFilterFactory;import org.patchca.filter.predefined.WobbleRippleFilterFactory;import org.patchca.service.ConfigurableCaptchaService;import org.patchca.utils.encoder.EncoderHelper;import org.patchca.word.RandomWordFactory;
public classCreatePatcha{
private static Random random = new Random();
private static ConfigurableCaptchaService cs = new ConfigurableCaptchaService();
static {// cs.setColorFactory(new SingleColorFactory(new Color(25,60,170)));
cs.setColorFactory(new ColorFactory(){@Override
public Color getColor(int x){int[] c = new int[3];int i = random.nextInt(c.length);for(int fi =0; fi < c.length; fi++){if(fi == i){
c[fi]= random.nextInt(71);}else{
c[fi]= random.nextInt(256);}}return new Color(c[0], c[1], c[2]);}});
RandomWordFactory wf = new RandomWordFactory();// wf.setCharacters("23456789abcdefghigklmnpqrstuvwxyzABCDEFGHIGKLMNPQRSTUVWXYZ");
wf.setCharacters("0123456789abcdefghigklmnopqrstuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ");
wf.setMaxLength(4);
wf.setMinLength(4);
cs.setWordFactory(wf);}
public static void main(String[] args) throws IOException {for(int i =0; i <100; i++){
switch (random.nextInt(5)){
case 0:
cs.setFilterFactory(new CurvesRippleFilterFactory(cs
.getColorFactory()));break;
case 1:
cs.setFilterFactory(new MarbleRippleFilterFactory());break;
case 2:
cs.setFilterFactory(new DoubleRippleFilterFactory());break;
case 3:
cs.setFilterFactory(new WobbleRippleFilterFactory());break;
case 4:
cs.setFilterFactory(new DiffuseRippleFilterFactory());break;}
OutputStream out = new FileOutputStream(new File(i +".png"));
String token = EncoderHelper.getChallangeAndWriteImage(cs,"png",
out);
out.close();
File f = new File(i+".png");
f.renameTo(new File("checkdata/"+ token +"_"+ i+".png"));
System.out.println(i+"验证码="+ token);}}}
训练
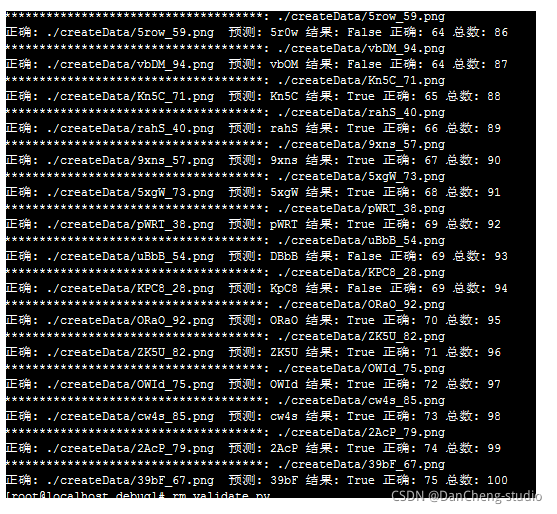
篇幅有限,更多详细设计见设计论文
4 最后
项目包含内容

完整详细设计论文
🧿 项目分享:见文末!
版权归原作者 Loop学长 所有, 如有侵权,请联系我们删除。