
现在假设有两个数据文件
file1.txtfile2.txt2018-3-1 a
2018-3-2 b
2018-3-3 c
2018-3-4 d
2018-3-5 a
2018-3-6 b
2018-3-7 c
2018-3-3 c2018-3-1 b
2018-3-2 a
2018-3-3 b
2018-3-4 d
2018-3-5 a
2018-3-6 c
2018-3-7 d
2018-3-3 c
上述文件 file1.txt 本身包含重复数据,并且与 file2.txt 同样出现重复数据,现要求使用 Hadoop 大数据相关技术对这两个文件进行去重操作,并最终将结果汇总到一个文件中。
一、MapReduce 的数据去重
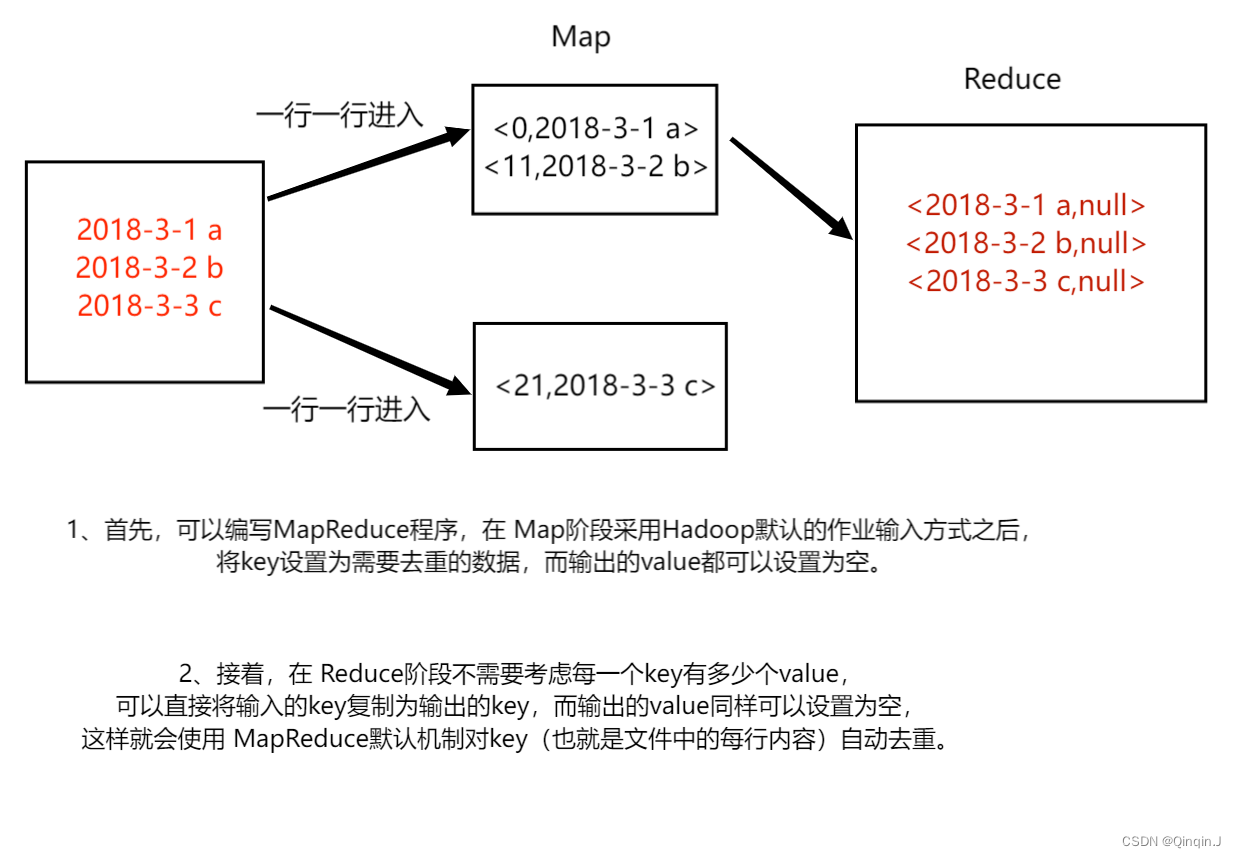
二、案例实现
1、Map 阶段实现
DedupMapper.java
package com.itcast.dedup;
//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class DedupMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
//重写Ctrl+o
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// <0,2018-3-1 a> <11,2018-3-2 b>
// NullWritable.get() 方法设置空值
context.write(value, NullWritable.get());
}
}
该代码的作用是为了读取数据集文件将 TextInputFormat 默认组件解析的类似 <0,2018-3-1 a> 键值对修改 <2018-3-1 a,null>
2、Reduce 阶段实现
DedupReducer.java
package com.itcast.dedup;
//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class DedupReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//<2018-3-1 a,null> <11,2018-3-2 b,null> <11,2018-3-3 c,null>
context.write(key,NullWritable.get());
}
}
该代码的作用仅仅是接受 Map 阶段传递来的数据,根据 Shuffle 工作原理,键值 key 相同的数据就不会被合并,因此输出数据就不会出现重复数据了。
3、Dtuver 程序主类实现
DedupDriver.java
package com.itcast.dedup;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class DedupDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//通过 Job 来封装本次 MR 的相关信息
Configuration conf = new Configuration();
//System.setProperty("HADOOP_USER_NAME","root");
//配置 MR 运行模式,使用 local 表示本地模式,可以省略
// conf.set("mapreduce.framework.name","local");
Job job = Job.getInstance(conf);
//指定 MR Job jar 包运行主类
job.setJarByClass(DedupDriver.class);
//指定本次 MR 所有的 Mapper Reducer 类
job.setMapperClass(DedupMapper.class);
job.setReducerClass(DedupReducer.class);
//设置业务逻辑 Mapper 类的输出 key 和 value 的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//设置业务逻辑 Reducer 类的输出 key 和 value 的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//使用本地模式指定处理的数据所在的位置
//{input2\*} 表示读取该路径下所有的文件
FileInputFormat.setInputPaths(job,"D:\\homework2\\Hadoop\\mr\\{input2\\*}");
//使用本地模式指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("D:\\homework2\\Hadoop\\mr\\output"));
//提交程序并且监控打印程序执行情况
boolean res = job.waitForCompletion(true);
//执行成功输出 0 ,不成功输出 1
System.exit(res ? 0 : 1);
}
}
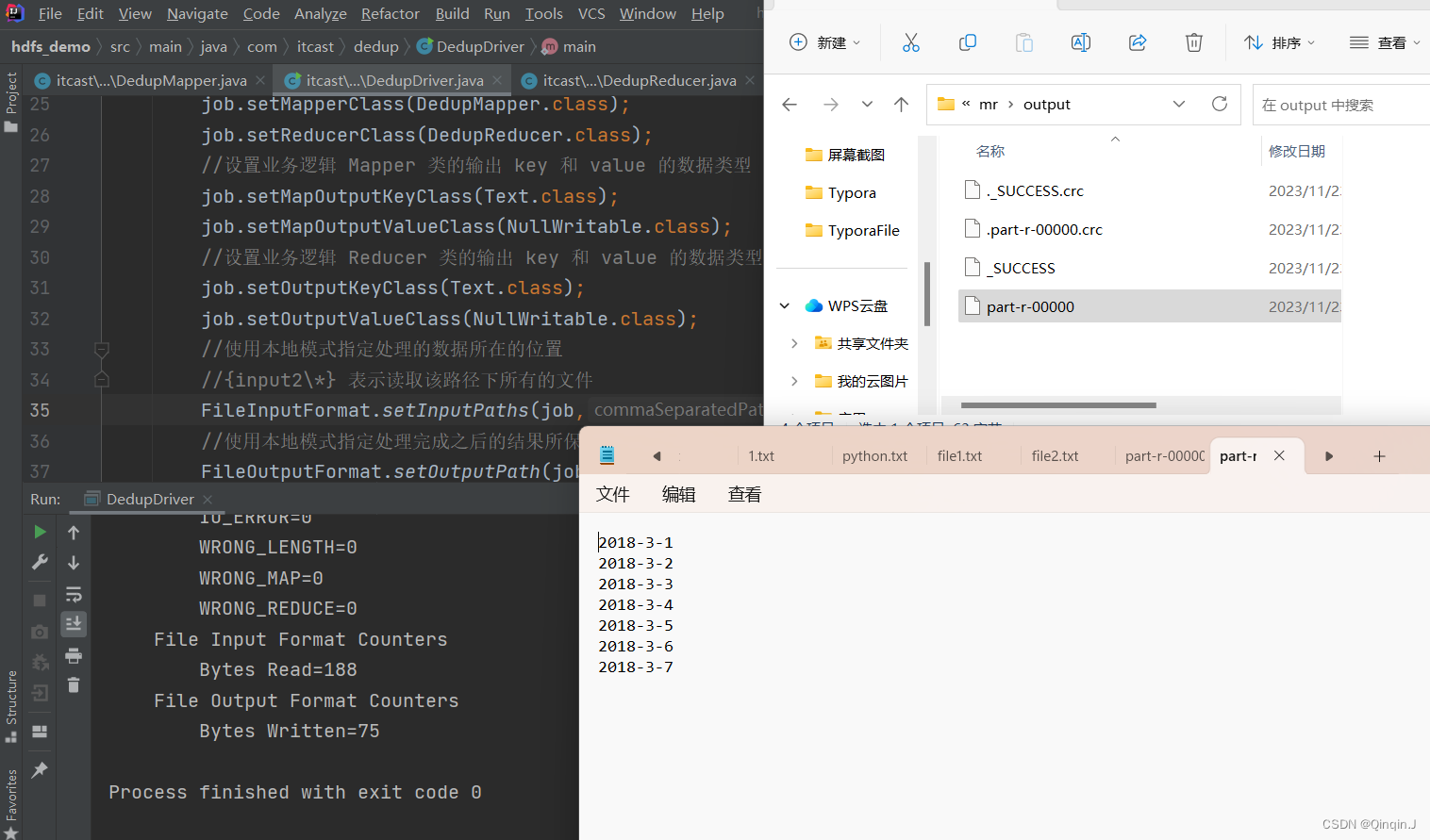
运行结果:

三、拓展
只要日期相同,就判定为相同,最后结果输出日期即可
只需要修改DedupMapper.java文件
package com.itcast.dedup;
//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class DedupMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
//重写Ctrl+o
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//输出日期
// 把 hadoop 类型转换为 java 类型(接收传入进来的一行文本,把数据类型转换为 String 类型)
String line = value.toString();
// 把字符串拆分为单词
String[] words = line.split(" ");
// 输出前面的内容
String wo = words[0];
context.write(new Text(wo), NullWritable.get());
}
}
运行结果:
本文转载自: https://blog.csdn.net/2202_75688394/article/details/134574630
版权归原作者 Qinqin.J 所有, 如有侵权,请联系我们删除。
版权归原作者 Qinqin.J 所有, 如有侵权,请联系我们删除。