
1. 介绍
ZooKeeper是一个开源的分布式协调服务,为分布式系统提供高效的管理和协调机制。它被广泛应用于解决分布式系统中的各种共识问题,如配置管理、命名服务、分布式锁、分布式队列、选举算法等。以下是ZooKeeper在分布式系统中的重要性和应用场景:
重要性
- 一致性服务:ZooKeeper提供强一致性的数据模型,能够保证数据在分布式环境下的一致性。它采用了Paxos算法等技术,确保数据的原子性和顺序性。
- 分布式锁和同步:通过ZooKeeper,可以实现分布式系统中的锁和同步机制,确保多个节点对共享资源的互斥访问和同步操作。
- 配置管理:ZooKeeper可用于集中式管理配置信息,各个节点可以通过ZooKeeper获取最新的配置数据,实现配置的动态更新和统一管理。
- 命名服务:提供类似于目录树的结构,可以用于命名服务,帮助系统发现和定位各种服务和资源。
- 分布式协调和领导者选举:ZooKeeper提供了一套轻量级的协调机制,用于实现分布式系统中的领导者选举、Master/Slave模式等场景。
应用场景
- 分布式应用的配置管理:对于需要共享配置信息的分布式应用,ZooKeeper提供了一个可靠的配置中心,确保所有节点都能获取到最新的配置。
- 分布式锁和同步:在多个节点之间实现资源的互斥访问,如分布式任务调度、分布式缓存的缓存更新等。
- 分布式协调服务:例如,分布式集群中的领导者选举、Master/Slave模式的切换等场景。
- 分布式队列:通过ZooKeeper实现分布式队列,实现数据的有序处理和异步处理。
- 服务发现与注册:提供服务发现的功能,帮助系统在分布式环境下发现和定位各种服务。
2. ZooKeeper 架构
服务角色
- Leader(领导者):负责处理客户端的写请求(如创建、更新、删除数据等)。它确保所有写请求按顺序被处理,并将更改广播给所有服务器。
- Followers(追随者):复制Leader的数据状态,并处理客户端的读请求。它们参与投票选举Leader,并与Leader保持同步。
- Observer(观察者):类似于Follower,但不参与投票。Observer接收Leader的状态更改,但不参与投票过程。它们可以减轻Leader负载并提高读取性能。
数据模型
ZooKeeper的数据模型类似于文件系统的目录结构,由节点(Node)组成,每个节点称为ZNode。ZNode可以存储数据和元数据,并具有唯一的路径标识。
工作原理
一致性(Consistency):ZooKeeper保持强一致性,确保所有Follower和Observer的数据与Leader保持一致。当客户端写入数据时,Leader将更改广播给所有节点,并在超过半数节点确认后提交更改。
可用性(Availability):ZooKeeper的集群中,只要有半数以上节点是可用的,系统就可以继续提供服务。客户端可以从任何节点读取数据。
分区容错性(Partition Tolerance):ZooKeeper使用多数派机制(Quorum),确保在网络分区时集群能够正常工作。即使分区发生,只要超过半数节点仍然能够互相通信,系统就能继续服务。
Leader选举(Leader Election):ZooKeeper使用ZAB(ZooKeeper Atomic Broadcast)协议进行Leader选举。当Leader失效时,Followers会投票选举一个新的Leader。
数据同步(Data Synchronization):Leader负责接收客户端写入的请求,并将更改复制到Followers和Observers。这确保了数据的一致性和可用性。
ZooKeeper通过以上机制和算法确保了其高一致性、高可用性和分区容错性,为分布式应用提供了可靠的服务。其基于ZAB协议的工作方式使得ZooKeeper能够在分布式环境下有效地管理数据和协调系统的各项任务。
3. 安装和配置
下载 ZooKeeper
- 官方网站:访问 Apache ZooKeeper 下载页面,选择最新稳定版本的 ZooKeeper。
安装和配置
- 解压文件:将下载的 ZooKeeper 压缩包解压到本地文件夹。
- 配置文件:在 ZooKeeper 安装目录下,找到
conf文件夹,并复制zoo_sample.cfg文件为zoo.cfg。 - 编辑配置文件:使用文本编辑器打开
zoo.cfg文件,配置 ZooKeeper 的相关参数,如端口号、数据目录等。确保dataDir配置为合适的数据存储目录。
启动 ZooKeeper
- 启动服务:使用命令行进入 ZooKeeper 安装目录的
bin文件夹,并执行以下命令启动 ZooKeeper 服务:./zkServer.sh或者在 Windows 环境下执行:zkServer.cmd
验证和管理
- 验证服务:使用 ZooKeeper 客户端命令连接到 ZooKeeper 服务器,确保服务已启动。
./zkCli.sh -server localhost:2181如果连接成功,将会出现 ZooKeeper 命令行提示符。 - 管理和操作:通过命令行或 ZooKeeper 的 API 进行节点的创建、读取、更新和删除操作。例如:- 创建节点:
create /myNode myData- 读取节点:get /myNode- 更新节点:set /myNode newData- 删除节点:delete /myNode
停止和关闭
在命令行中执行以下命令关闭 ZooKeeper 服务:
./zkServer.sh stop
Windows 环境下执行:
zkServer.cmd stop
4. ZooKeeper 数据模型
数据结构和层次命名空间:
- 层次命名空间:ZooKeeper 组织为层次结构,类似于文件系统的目录结构,通过路径名来表示节点。
- znode:每个节点在层次结构中都是一个 znode,有唯一的路径标识。
节点类型和 Watcher 机制:
ZooKeeper 节点有不同的类型,包括持久节点、临时节点、持久顺序节点和临时顺序节点。Watcher 是一种事件通知机制,可在节点状态更改时接收通知。
- 节点类型:- 持久节点(Persistent Nodes):一旦创建,持久节点会一直存在,直到显式删除。- 临时节点(Ephemeral Nodes):与客户端会话关联,客户端断开连接时,临时节点会被删除。- 持久顺序节点(Persistent Sequential Nodes):与持久节点类似,但节点名称末尾会附加一个数字后缀,表示创建顺序。- 临时顺序节点(Ephemeral Sequential Nodes):与临时节点类似,节点名称末尾有数字后缀。
- Watcher 机制:客户端可以在节点上设置 Watcher,当节点状态发生变化(例如创建、删除、数据更新等)时,ZooKeeper 将触发 Watcher 事件通知客户端。
5. 分布式锁
分布式锁是一种用于在分布式系统中控制对共享资源访问的机制。ZooKeeper可以用于实现分布式锁,其基本思想是创建一个独占节点(即只允许一个客户端拥有的节点),并利用ZooKeeper的特性来确保每个时间只有一个客户端持有这个节点。
实现分布式锁的基本步骤
- 获取锁:客户端请求ZooKeeper创建临时顺序节点。
- 检查序号:客户端获取所有子节点并按序号排序。
- 判断锁拥有者:如果当前客户端的节点序号是最小的,表示获得锁;否则,监听次小节点,等待其删除。
- 释放锁:客户端释放节点(删除节点)。
代码示例(Java)
以下是使用 ZooKeeper 实现分布式锁的基本示例代码:
import org.apache.zookeeper.*;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class DistributedLock {
private final static String ZOOKEEPER_ADDRESS = "localhost:2181";
private final static String LOCK_PATH = "/myLock";
private ZooKeeper zooKeeper;
private String lockPath;
private CountDownLatch countDownLatch;
public DistributedLock() throws IOException, InterruptedException, KeeperException {
this.zooKeeper = new ZooKeeper(ZOOKEEPER_ADDRESS, 3000, null);
this.lockPath = zooKeeper.create(LOCK_PATH, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
public void lock() throws InterruptedException, KeeperException {
while (true) {
List<String> children = zooKeeper.getChildren("/", false);
children.sort(String::compareTo);
int index = children.indexOf(lockPath.substring(1));
if (index == 0) {
return; // 当前客户端持有最小节点,获取锁成功
}
String watchNode = "/" + children.get(index - 1);
final CountDownLatch latch = new CountDownLatch(1);
Stat stat = zooKeeper.exists(watchNode, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if (watchedEvent.getType() == Event.EventType.NodeDeleted) {
latch.countDown();
}
}
});
if (stat != null) {
latch.await(); // 等待次小节点删除事件
}
}
}
public void unlock() throws KeeperException, InterruptedException {
zooKeeper.delete(lockPath, -1);
zooKeeper.close();
}
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
DistributedLock distributedLock = new DistributedLock();
distributedLock.lock();
// 执行业务逻辑
distributedLock.unlock();
}
}
避免死锁
- 超时机制:为获取锁设置超时时间,超过指定时间仍未获得锁,则放弃获取锁。
- 节点删除监听:监听次小节点的删除事件,避免死锁等待。
在分布式系统中实现分布式锁时,需要注意网络波动、ZooKeeper集群状态等因素,以确保锁的可靠性和稳定性。
6. 选举机制
ZooKeeper使用ZAB(ZooKeeper Atomic Broadcast)协议实现分布式一致性,并在此基础上构建了领导者选举机制。在ZooKeeper中,节点可以是领导者(Leader)、追随者(Follower)或候选者(Candidate)。
选举机制基本流程
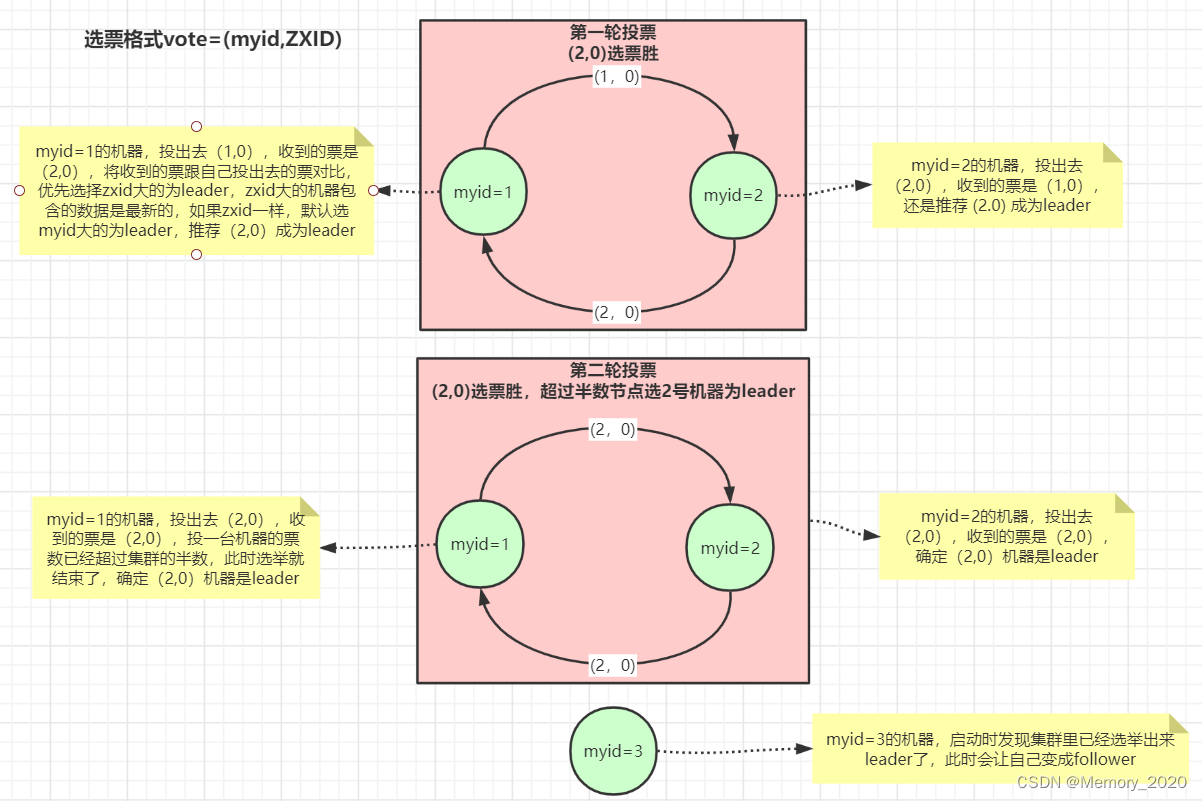
- 初始化:启动时所有节点都是候选者。
- 投票:每个候选者在一定时间内(选举超时时间)内向其他节点发送选举请求(投票请求),请求其他节点投票给自己。
- 投票结果:收到的第一个投票节点成为领导者,其他节点成为追随者。
- 心跳:领导者定期发送心跳以维持其地位,追随者则定期接收领导者的心跳。
选举代码示例
以下是一个基本的选举场景的代码示例,演示如何使用 ZooKeeper 实现领导者选举:
import org.apache.zookeeper.*;
public class LeaderElection implements Watcher {
private ZooKeeper zooKeeper;
private String zNode = "/election";
private String currentZNode;
public LeaderElection() throws Exception {
this.zooKeeper = new ZooKeeper("localhost:2181", 3000, this);
}
public void findLeader() throws Exception {
if (zooKeeper.exists(zNode, false) == null) {
currentZNode = zooKeeper.create(zNode, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
watchPreviousNode();
}
private void watchPreviousNode() throws Exception {
String previous = null;
for (String node : zooKeeper.getChildren(zNode, false)) {
if (currentZNode.equals(zNode + "/" + node)) {
break;
}
previous = node;
}
if (previous != null) {
zooKeeper.exists(zNode + "/" + previous, this);
}
}
@Override
public void process(WatchedEvent event) {
switch (event.getType()) {
case NodeDeleted:
try {
findLeader();
} catch (Exception e) {
e.printStackTrace();
}
break;
}
}
public static void main(String[] args) throws Exception {
LeaderElection leaderElection = new LeaderElection();
leaderElection.findLeader();
// 等待选举结果
Thread.sleep(Long.MAX_VALUE);
}
}
此示例中的代码模拟了候选者通过创建临时顺序节点并监视前一个节点的变化来实现领导者选举的基本过程。
ZooKeeper的选举机制可以确保系统的领导者是唯一的,并且在节点出现故障或网络问题时能够快速重新选举新的领导者,从而保障了分布式系统的可用性和稳定性。
7. 实战案例
在 Java 中使用 ZooKeeper 主要涉及到 ZooKeeper 的连接、会话管理、数据节点的创建、读取、更新和删除等操作。以下是使用 ZooKeeper 的基本步骤和示例代码:
引入 ZooKeeper 客户端依赖
在 Maven 项目中,需要在
pom.xml
文件中引入 ZooKeeper 客户端依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.7.0</version> <!-- 版本号根据需求进行更改 -->
</dependency>
创建 ZooKeeper 连接
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.WatchedEvent;
public class ZooKeeperExample {
private static final String ZOOKEEPER_HOST = "localhost:2181"; // ZooKeeper服务器地址和端口号
private static final int SESSION_TIMEOUT = 5000; // 会话超时时间
public static void main(String[] args) throws Exception {
ZooKeeper zooKeeper = new ZooKeeper(ZOOKEEPER_HOST, SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 处理 ZooKeeper 事件
System.out.println("Received event: " + event);
}
});
// 等待连接成功
while (zooKeeper.getState() != ZooKeeper.States.CONNECTED) {
Thread.sleep(1000);
}
// 连接成功后的操作
System.out.println("Connected to ZooKeeper");
// 进行节点操作等其他业务逻辑
// 例如:创建节点、读取节点、更新节点、删除节点等操作
// 关闭 ZooKeeper 连接
zooKeeper.close();
}
}
进行节点操作
以下是节点的基本操作示例:
- 创建节点:
// 创建一个持久节点
String path = "/testNode";
byte[] data = "Hello, ZooKeeper!".getBytes();
zooKeeper.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
- 读取节点:
// 读取节点数据
Stat stat = new Stat();
byte[] nodeData = zooKeeper.getData("/testNode", false, stat);
System.out.println("Node data: " + new String(nodeData));
- 更新节点:
// 更新节点数据
String newData = "Updated data";
zooKeeper.setData("/testNode", newData.getBytes(), stat.getVersion());
- 删除节点:
// 删除节点
zooKeeper.delete("/testNode", stat.getVersion());
注意事项
- 在实际使用中,请根据需求处理异常、关闭连接等情况。
- 使用 Watcher 监听 ZooKeeper 节点的变化。
- 请注意 ZooKeeper 的一致性、可用性和分区容错性等特性。
以上代码示例仅为基础操作,实际应用中可能会涉及更多复杂的场景和功能。后面有时间会再跟大家分享一下Zookeeper选举Leader源码分析的内容
版权归原作者 Memory_2020 所有, 如有侵权,请联系我们删除。