
导言
在大数据的世界里,实时流处理已成为许多业务场景中的核心需求。而Apache Flink,作为一款开源的流处理框架,凭借其高效、可靠和灵活的特性,已经在实时计算领域一枝独秀了。

简介
Apache Flink是一个用于无界和有界数据流的开源流处理框架。它提供了一个统一的API来处理批量和流数据,使得开发者可以轻松地构建高效的实时数据处理应用。Flink的核心优势在于其低延迟、高吞吐量和容错性强的特点,适用于多种实时数据分析场景。
发展历史
Flink 最初来源于名为 Stratosphere 的欧洲学术研究项目,该项目始于2010年,由德国柏林工业大学以及其他欧洲大学的研究团队共同发起,专注于开发新一代的分布式数据处理系统。
2014年4月,Stratosphere 项目的代码被捐赠给Apache软件基金会,并在此基础上开始了孵化过程。不久之后,项目被重命名为Flink,这个名字在德语中有“快速、敏捷”的含义,这也体现了项目追求高效、灵活处理大数据的目标。
Flink的logo是一只彩色松鼠,象征着其速度和灵活特性。
到了2014年12月,Flink因其独特的能力和活跃的社区贡献,成功晋升为Apache软件基金会的顶级项目,标志着它正式成为开源大数据领域内受到广泛认可的项目。
自加入Apache以来,Flink在功能上不断完善和增强,增加了对流式窗口、CEP(复杂事件处理)等高级特性的支持,并在性能、稳定性、易用性等方面不断提升。
主要特征
Flink的核心特性:
- 事件时间处理:Flink提供了强大的事件时间处理机制,支持乱序事件的处理,能够确保数据的顺序性。
2.** 恰好一次语义**:通过精确的状态管理和检查点机制,Flink保证了数据处理的恰好一次语义,避免了数据丢失和重复处理。
高吞吐量和低延迟:Flink的设计目标是实现高吞吐量和低延迟的数据处理,使其适用于实时分析场景。
统一的批流处理:Flink提供了统一的API来处理批量数据和流数据,简化了数据处理逻辑。
应用场景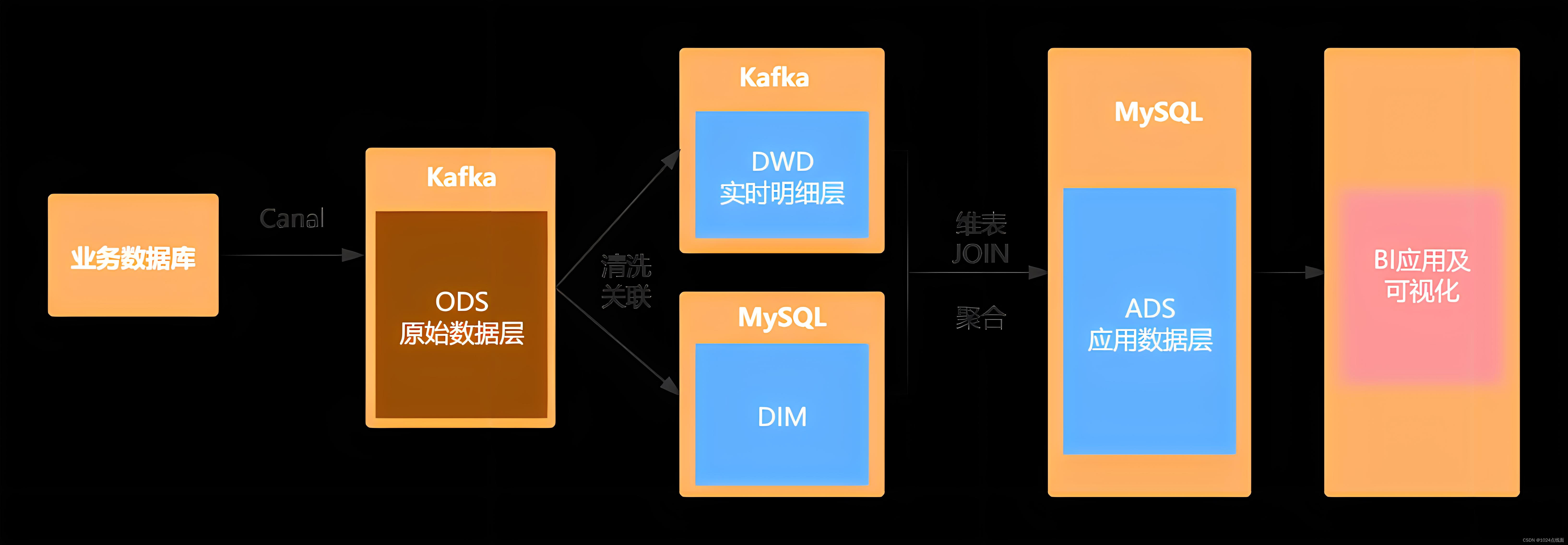
实时数据分析:Flink能够处理大规模的实时数据流,为业务提供实时的数据分析和决策支持。
实时日志分析:通过Flink处理服务器日志,可以实时监控系统的运行状态,及时发现和解决问题。
金融风控:在金融领域,Flink可用于实时监控交易数据,识别风险行为,保障资金安全。
物联网数据处理:物联网设备产生的海量数据可以通过Flink进行实时分析,为智能设备提供智能决策。
与Spark的对比
Flink和Spark是两位大数据处理领域的明星选手,各自有着独特的技术和设计理念。
- Spark:Spark更像是一个全能运动员,擅长批处理和实时流处理,但它对实时流的处理实际上是基于微批(Micro-batch)概念。这意味着Spark接收数据并不是严格意义上的逐条处理,而是每隔一定时间间隔形成一个小的数据批次进行计算,有点像是每分钟处理一次所有的新邮件而不是一封接一封地处理。
- Flink:相比之下,Flink更像是一位专门针对实时流处理的专业选手,它的设计理念是真正的事件驱动流处理,每一项数据进来就立刻进行处理,仿佛是实时接听并处理每一个电话一样。同时,Flink虽然主打流处理,但也具备良好的批处理能力,它可以无缝地将流视为无界批次进行处理。
结语
Apache Flink作为一款革新的大数据处理引擎,凭借其对流处理与批处理的统一视图、卓越的实时性和容错性、以及对事件时间处理的深入支持,已在业界树立起标杆。无论是应对瞬息万变的实时数据洪流,还是处理大规模的历史数据集,Flink均展现出强大而稳健的性能。
版权归原作者 1024点线面 所有, 如有侵权,请联系我们删除。