
一、背景
首先,博主想问一个问题,如果你是计算机专业的学生,且处于大一或者大二的时候,是否会觉得学习的课程(例如:操作系统、计算机理论基础等等)很枯燥,很无聊,不实用呢?其实我相信大多数同学会有这样的感受,博主也不例外。博主在大一大二阶段,除了对编码很感兴趣,其他很重要的基础知识都觉得不实用,但是其实近段时间,博主在一次次拧螺丝的过程中,逐渐发现其实这些知识往往可能就是你写出好代码的基础,因为很多时候,在细节方面你需要考虑的东西很多。
博主本身是Java后端开发方向,因为各种原因,春招误打误撞的转向成Java游戏开发实习生。因为第一次写博客,可能会有出现错误,望指点。
二、起因
在实习过程中,大佬要我写一个工具类,这个工具类其实有点类似SQL可视化工具,其实就是想要展示当前连接数据库的所有库的所有表结构,并且生成Excel表格,供其他非技术人员参考,可以人工注释,且每一次重新生成不会覆盖人工注释内容(这不是很重要)。博主想出两种方法:
第一种是SHOW CREATE TABLE + 表名,去查出每张表的表结构,然后去解析建表语句。第二种是可以去查询information_schema的TABLES(表信息)、COLUMNS(属性信息)、STATISTICS(索引信息)。
而博主选择用第二种的原因是这样获取信息会相对简单,不用去解析建表语句,而且获取的信息相对会比较齐全。不过这样可能会需要查3条SQL语句,这样为了提高效率,果断用了多线程。
博主第一版使用ForkJoin去跑每一个Db库,去查每个库的所有表名,然后再继续new线程去查它的信息,然后映射成Java实体对象,然后回溯,收集完所有库的实体对象,再统一打印Excel。在跑出结果后沾沾自喜的提交作业。
第二天,大佬发来问候:“ForkJoin.commonPool() 这个线程池其实更多适用于CPU运算,而且这个是JDK自建的池,做IO操作容易阻塞JDK内部操作。”
什么!CPU运算?IO运算?这些名词是不是有点熟悉呢,没错!其实是涉及到我们之前学过的基础知识:CPU密集型和IO密集型。其实创建线程池也是很重要的,我们知道线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式, 这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险,出现OOM。那么如果要使用 ThreadPoolExecutor ,那就先来看看构造方法中的所有入参:
- corePoolSize : 核心线程数,当线程池中的线程数量为 corePoolSize 时,即使这些线程处于空闲状态,也不会销毁(除非设置 allowCoreThreadTimeOut)。
- maximumPoolSize : 最大线程数,线程池中允许的线程数量的最大值。
- keepAliveTime : 线程空闲时间,当线程池中的线程数大于 corePoolSize 时,多余的空闲线程将在销毁之前等待新任务的最长时间。
- workQueue : 任务队列
- unit : 线程空闲时间的单位。
- threadFactory : 线程工厂,线程池创建线程时使用的工厂。
- handler : 拒绝策略,因达到线程边界和任务队列满时,针对新任务的处理方法。
这么说可能有些难以理解,你可以结合下图进行参考:
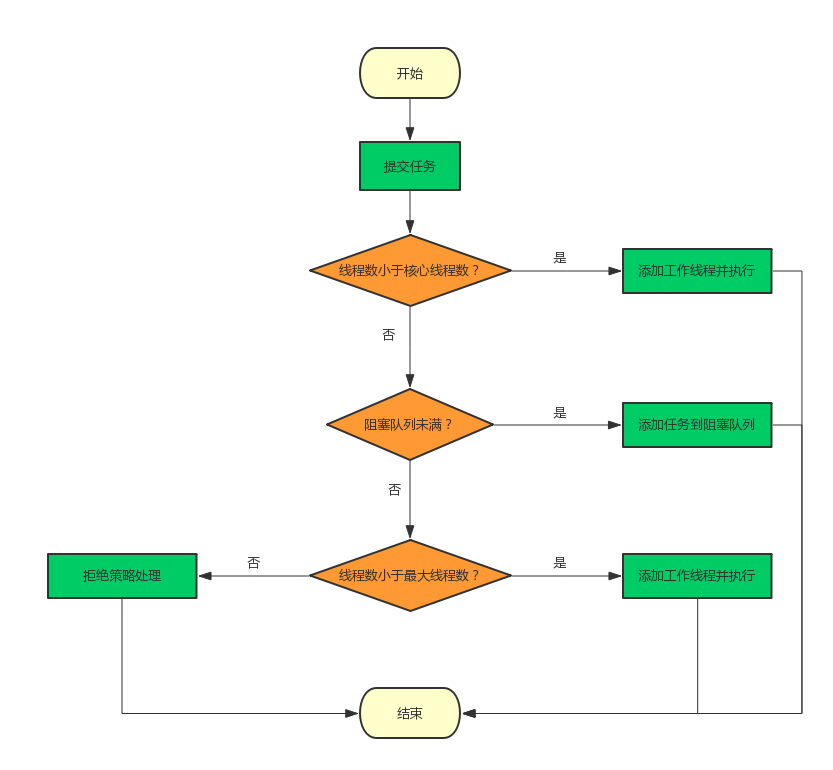
那么由此我们可以知道,当大量任务被放入线程池之后,先是被核心线程执行,多余的会被放进队列里,当队列满了之后才会创建额外的线程进行处理,再多就会采取拒绝策略。但这样真的能满足我们的所有需求吗?
三、任务的分类
正常来说,我们可以把需要处理的任务按照消耗资源的不同,分为两种:**
CPU密集型
和
IO密集型
**。
1、CPU 密集型
既然名字里带有
CPU
了,说明其消耗的主要资源就是 CPU 了。
具体是指那种包含大量运算、在持有的 CPU 分配的时间片上一直在执行任务、几乎不需要依赖或等待其他任何东西。这样的任务,在我的理解中,处理起来其实没有多少优化空间,因为处理时几乎没有等待时间,所以一直占有 CPU 进行执行,才是最好的方式。
唯一能想到优化的地方,就是当单个线程累计较多任务时,其他线程能进行分担,类似
fork/join框架
的概念。
2、IO 密集型
和上面一样,既然名字里带有
IO
了,说明其消耗的主要资源就是 IO 了。我们所接触到的 IO ,大致可以分成两种:**
磁盘IO
和
网络IO
**。
(1)磁盘 IO ,大多都是一些针对磁盘的读写操作,最常见的就是文件的读写,假如你的数据库、 Redis 也是在本地的话,那么这个也属于磁盘 IO。
(2)网络 IO ,这个应该是大家更加熟悉的,我们会遇到各种网络请求,比如 http 请求、远程数据库读写、远程 Redis 读写等等。
IO 操作的特点就是需要等待,我们请求一些数据,由对方将数据写入缓冲区,在这段时间中,需要读取数据的线程根本无事可做,因此可以把 CPU 时间片让出去,直到缓冲区写满。既然这样,IO 密集型任务其实就有很大的优化空间了(毕竟存在等待),那现有的线程池可以很好的满足我们的需求吗?答案是否定的。
回到正题,很明显博主的此次作业就是IO密集型任务,那么针对IO密集型任务,线程池又该如何优化呢?
还记得上面说的, ThreadPoolExecutor 针对多余任务的处理,是先放到等待队列中,当队列塞满后,再创建额外的线程进行处理。
也许再来看看 ThreadPoolExecutor 的 execute 方法,会让我们有一些思路:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 如果当前活跃线程数,小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 则优先创建线程
if (addWorker(command, true))
return;
c = ctl.get();
}
// 如果任务可以成功放入队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 如果不可以成功放入队列,则创建线程
else if (!addWorker(command, false))
// 如果无法继续创建线程,则拒绝任务
reject(command);
}
针对放入队列的操作,如果队列放入失败,线程池就会选择去创建线程了。因此,我们或许可以尝试自定义线程池,针对 offer 操作,做一些自定义处理。也就是将任务放入队列时,先检查线程池的线程数是否小于最大线程数,如果是,则拒绝放入队列,否则,再尝试放入队列中。如果你有看过 dubbo 或者 tomcat 的线程池,你会发现他们就有这样的实现方法。
四、解决方案
那么其实我们就可以在创建线程池时将corePoolSize与maximumPoolSize设置成相同,这样就可以实现在达到最大线程数之后再进入队列,最后队列满了之后拒绝。或者是自定义线程池去实现这样一种机制。
而对于corePoolSize或者maximumPoolSize这样一个数,我们又该如何去决定这个数的大小呢?
第一种:**CPU密集型**:最大线程数应该等于CPU核数+1,这样最大限度提高效率。而其实ForkJoinPool里面的线程,默认是服务器CPU的数目。
// 通过该代码获取当前运行环境的cpu核数
Runtime.getRuntime().availableProcessors();
第二种:**IO密集型**:主要是进行IO操作,执行IO操作的时间较长,这时CPU出于空闲状态,导致CPU的利用率不高。线程数为2倍CPU核数。当其中的线程在IO操作的时候,其他线程可以继续用CPU,提高了CPU的利用率。
第三种:**混合型**:如果CPU密集型和IO密集型执行时间相差不大那么可以拆分;如果两种执行时间相差很大,就没必要拆分了。
第四种(了解):在IO优化中,线程等待时间所占比越高,需要线程数越多;线程CPU时间占比越高,需要越少线程数。因此:
最佳线程数目 = ( (线程等待时间+线程CPU时间) / 线程CPU时间 ) * CPU数目
本文转载自: https://blog.csdn.net/Codehaoo/article/details/124083501
版权归原作者 Codehaoo 所有, 如有侵权,请联系我们删除。
版权归原作者 Codehaoo 所有, 如有侵权,请联系我们删除。