
1.kibana操作
1.1查询所有
// 查询所有
GET /indexName/_search
{"query":{"match_all":{}}}
1.2.全文检索查询
常见的全文检索查询包括:
- match查询:单字段查询
- multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件
match查询语法如下:
GET/indexName/_search
{"query":{"match":{"FIELD":"TEXT"}}}
mulit_match语法如下:
GET/indexName/_search
{"query":{"multi_match":{"query":"TEXT","fields":["FIELD1"," FIELD12"]}}}
match查询示例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OAxvKsZd-1644301793606)(assets/image-20210721170455419.png)]](https://img-blog.csdnimg.cn/eaa5786be25147ad94af84a2a4f826f0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
multi_match查询示例: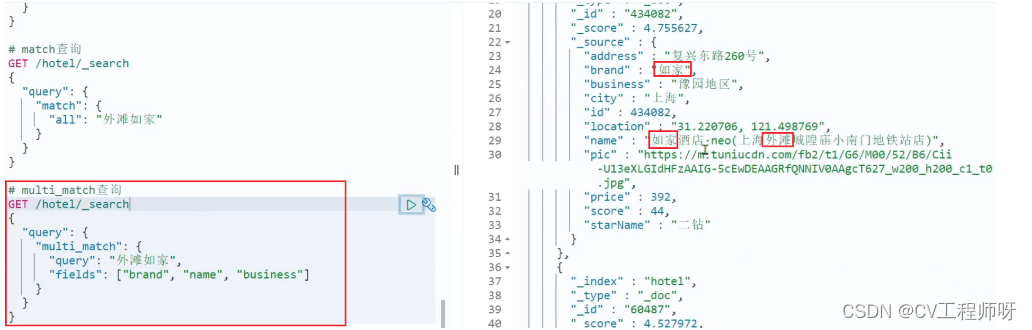
1.3精准查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询
- range:根据值的范围查询
1.3.1.term查询
因为精确查询的字段搜是不分词的字段,因此查询的条件也必须是不分词的词条。查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。如果用户输入的内容过多,反而搜索不到数据。
语法说明:
// term查询GET/indexName/_search
{"query":{"term":{"FIELD":{"value":"VALUE"}}}}
示例:
当我搜索的是精确词条时,能正确查询出结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9tjTOfPk-1644301917796)(assets/image-20210721171655308.png)]](https://img-blog.csdnimg.cn/7e3a3c9b074c43d7ba730333eebd6290.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
但是,当我搜索的内容不是词条,而是多个词语形成的短语时,反而搜索不到:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ue0ORngS-1644301917797)(assets/image-20210721171838378.png)]](https://img-blog.csdnimg.cn/12bc3053fb3343cfa67ab432d655ee79.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
1.3.2.range查询
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
基本语法:
// range查询GET/indexName/_search
{"query":{"range":{"FIELD":{"gte":10,// 这里的gte代表大于等于,gt则代表大于"lte":20// lte代表小于等于,lt则代表小于}}}}
示例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NrYCOQiJ-1644301917798)(assets/image-20210721172307172.png)]](https://img-blog.csdnimg.cn/b46476848ae341e6ab4de597993c7265.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
1.4.地理坐标查询
1.4.1.矩形范围查询
矩形范围查询,也就是geo_bounding_box查询,查询坐标落在某个矩形范围的所有文档:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-musSFUBK-1644302076175)(assets/DKV9HZbVS6.gif)]
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
语法如下:
// geo_bounding_box查询GET/indexName/_search
{"query":{"geo_bounding_box":{"FIELD":{"top_left":{// 左上点"lat":31.1,"lon":121.5},"bottom_right":{// 右下点"lat":30.9,"lon":121.7}}}}}
这种并不符合“附近的人”这样的需求,所以我们就不做了。
1.4.2.附近查询
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。
换句话来说,在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:
语法说明:
// geo_distance 查询GET/indexName/_search
{"query":{"geo_distance":{"distance":"15km",// 半径"FIELD":"31.21,121.5"// 圆心}}}
示例:
我们先搜索陆家嘴附近15km的酒店:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7QGe6ZT1-1644302076177)(assets/image-20210721175443234.png)]](https://img-blog.csdnimg.cn/735bd9a0610d4495aba05f66e0aa0489.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
发现共有47家酒店。
1.5.复合查询
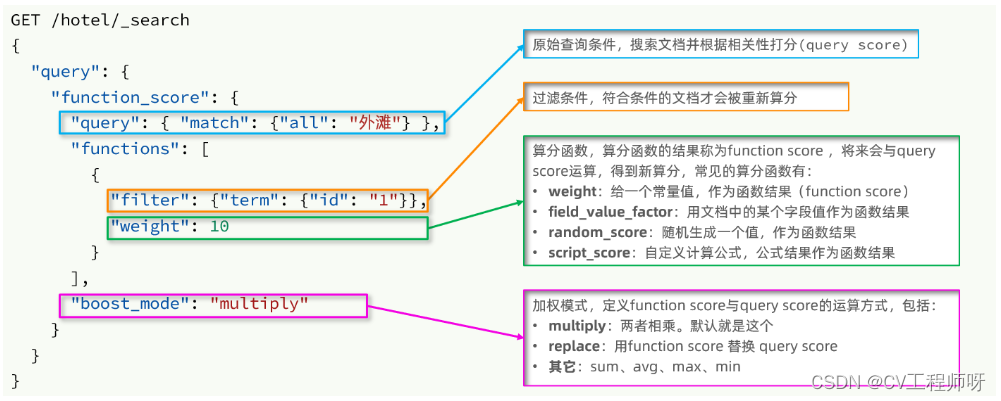
function score 查询中包含四部分内容:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数 - weight:函数结果是常量- field_value_factor:以文档中的某个字段值作为函数结果- random_score:以随机数作为函数结果- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括: - multiply:相乘- replace:用function score替换query score- 其它,例如:sum、avg、max、min
function score的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。

1.6.布尔查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
比如在搜索酒店时,除了关键字搜索外,我们还可能根据品牌、价格、城市等字段做过滤:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Axk6QnUZ-1644302320639)(assets/image-20210721193822848.png)]](https://img-blog.csdnimg.cn/e158716bb2c14900890542716b4bc9db.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用bool查询了。
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
- 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
- 其它过滤条件,采用filter查询。不参与算分
1)语法示例:
GET/hotel/_search
{"query":{"bool":{"must":[{"term":{"city":"上海"}}],"should":[{"term":{"brand":"皇冠假日"}},{"term":{"brand":"华美达"}}],"must_not":[{"range":{"price":{"lte":500}}}],"filter":[{"range":{"score":{"gte":45}}}]}}}
2)示例
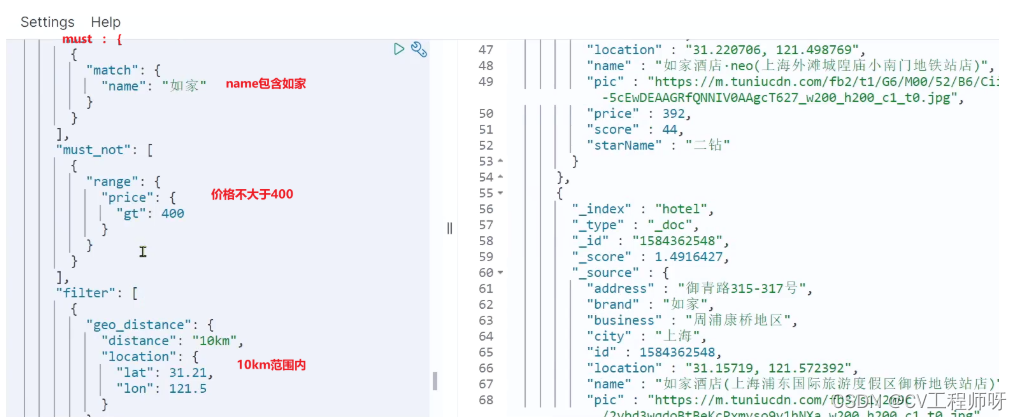
需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
分析:
- 名称搜索,属于全文检索查询,应该参与算分。放到must中
- 价格不高于400,用range查询,属于过滤条件,不参与算分。放到must_not中
- 周围10km范围内,用geo_distance查询,属于过滤条件,不参与算分。放到filter中
1.7排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
1.7.1.普通字段排序
keyword、数值、日期类型排序的语法基本一致。
语法:
GET/indexName/_search
{"query":{"match_all":{}},"sort":[{"FIELD":"desc"// 排序字段、排序方式ASC、DESC}]}
排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
示例:
需求描述:酒店数据按照用户评价(score)降序排序,评价相同的按照价格(price)升序排序
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CtGocVpt-1644367761772)(assets/image-20210721195728306.png)]](https://img-blog.csdnimg.cn/66c804d85e054ac4b3f1550ab2225069.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
1.7.2.地理坐标排序
地理坐标排序略有不同。
语法说明:
GET/indexName/_search
{"query":{"match_all":{}},"sort":[{"_geo_distance":{"FIELD":"纬度,经度",// 文档中geo_point类型的字段名、目标坐标点"order":"asc",// 排序方式"unit":"km"// 排序的距离单位}}]}
这个查询的含义是:
- 指定一个坐标,作为目标点
- 计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
- 根据距离排序
示例:
需求描述:实现对酒店数据按照到你的位置坐标的距离升序排序
提示:获取你的位置的经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/
假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A1w1ko7R-1644367761773)(assets/image-20210721200214690.png)]](https://img-blog.csdnimg.cn/8d4db11d7ef04537b46368ab17df6750.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
类似于mysql中的
limit ?, ?
1.8.分页
分页的基本语法如下:
GET/hotel/_search
{"query":{"match_all":{}},"from":0,// 分页开始的位置,默认为0"size":10,// 期望获取的文档总数"sort":[{"price":"asc"}]}
1.9高亮
1.9.1.高亮原理
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8CcRlQE5-1644368125339)(assets/image-20210721202705030.png)]](https://img-blog.csdnimg.cn/a8aeae1f56e04bd38f93c4a218c7ddeb.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
高亮显示的实现分为两步:
- 1)给文档中的所有关键字都添加一个标签,例如
<em>标签 - 2)页面给
<em>标签编写CSS样式
1.9.2.实现高亮
高亮的语法:
GET/hotel/_search
{"query":{"match":{"FIELD":"TEXT"// 查询条件,高亮一定要使用全文检索查询}},"highlight":{"fields":{// 指定要高亮的字段"FIELD":{"pre_tags":"<em>",// 用来标记高亮字段的前置标签"post_tags":"</em>"// 用来标记高亮字段的后置标签}}}}
注意:
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
示例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gGZeODOg-1644368125341)(assets/image-20210721203349633.png)]](https://img-blog.csdnimg.cn/1b53da9cdf75459a97da14a15746e50f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
2.Java代码实现
2.1查询所有
2.1.1发起查询请求
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ztjj9XEK-1644368545014)(assets/image-20210721203950559.png)]](https://img-blog.csdnimg.cn/6e339976ae2140a5959df37786be072e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
代码解读:
- 第一步,创建
SearchRequest对象,指定索引库名 - 第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等-query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL - 第三步,利用client.search()发送请求,得到响应
这里关键的API有两个,一个是
request.source()
,其中包含了查询、排序、分页、高亮等所有功能:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2WUUR8xl-1644368545015)(assets/image-20210721215640790.png)]](https://img-blog.csdnimg.cn/f7b37ca59dbc438f982006964b5c93ef.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
另一个是
QueryBuilders
,其中包含match、term、function_score、bool等各种查询:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wbkj7KNe-1644368545016)(assets/image-20210721215729236.png)]](https://img-blog.csdnimg.cn/1277212d59664cb88fb2c2720a285116.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
2.1.2.解析响应
响应结果的解析:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E11P20bn-1644368545017)(assets/image-20210721214221057.png)]](https://img-blog.csdnimg.cn/648bf4c77482459ca5b8fe14168590ff.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
elasticsearch返回的结果是一个JSON字符串,结构包含:
hits:命中的结果 -total:总条数,其中的value是具体的总条数值-max_score:所有结果中得分最高的文档的相关性算分-hits:搜索结果的文档数组,其中的每个文档都是一个json对象 -_source:文档中的原始数据,也是json对象
因此,我们解析响应结果,就是逐层解析JSON字符串,流程如下:
SearchHits:通过response.getHits()获取,就是JSON中的最外层的hits,代表命中的结果 -SearchHits#getTotalHits().value:获取总条数信息-SearchHits#getHits():获取SearchHit数组,也就是文档数组 -SearchHit#getSourceAsString():获取文档结果中的_source,也就是原始的json文档数据
2.1.3.完整代码
完整代码如下:
@TestvoidtestMatchAll()throwsIOException{// 1.准备RequestSearchRequest request =newSearchRequest("hotel");// 2.准备DSL
request.source().query(QueryBuilders.matchAllQuery());// 3.发送请求SearchResponse response = client.search(request,RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);}privatevoidhandleResponse(SearchResponse response){// 4.解析响应SearchHits searchHits = response.getHits();// 4.1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+ total +"条数据");// 4.2.文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历for(SearchHit hit : hits){// 获取文档sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json,HotelDoc.class);System.out.println("hotelDoc = "+ hotelDoc);}}
2.2match查询
全文检索的match和multi_match查询与match_all的API基本一致。差别是查询条件,也就是query的部分。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ii0rbJc9-1644368856399)(assets/image-20210721215923060.png)]](https://img-blog.csdnimg.cn/07f62506bc664a438cacd526548aabed.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_13,color_FFFFFF,t_70,g_se,x_16)
因此,Java代码上的差异主要是request.source().query()中的参数了。同样是利用QueryBuilders提供的方法:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z1jhaI49-1644368856401)(assets/image-20210721215843099.png)]](https://img-blog.csdnimg.cn/75a573e269d848deb6316f81ec27b849.png)
而结果解析代码则完全一致,可以抽取并共享。
完整代码如下:
@TestvoidtestMatch()throwsIOException{// 1.准备RequestSearchRequest request =newSearchRequest("hotel");// 2.准备DSL
request.source().query(QueryBuilders.matchQuery("all","如家"));// 3.发送请求SearchResponse response = client.search(request,RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);}
2.3.精确查询
精确查询主要是两者:
- term:词条精确匹配
- range:范围查询
与之前的查询相比,差异同样在查询条件,其它都一样。
查询条件构造的API如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2Pnb0OWT-1644368856401)(assets/image-20210721220305140.png)]](https://img-blog.csdnimg.cn/e7a3b0289ef44adfa78639878132c625.png)
2.4.布尔查询
布尔查询是用must、must_not、filter等方式组合其它查询,代码示例如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1qa35uiy-1644368856402)(assets/image-20210721220927286.png)]](https://img-blog.csdnimg.cn/2c4f78b2544e4dd9b9bd9b2fa176d4ba.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
可以看到,API与其它查询的差别同样是在查询条件的构建,QueryBuilders,结果解析等其他代码完全不变。
完整代码如下:
@TestvoidtestBool()throwsIOException{// 1.准备RequestSearchRequest request =newSearchRequest("hotel");// 2.准备DSL// 2.1.准备BooleanQueryBoolQueryBuilder boolQuery =QueryBuilders.boolQuery();// 2.2.添加term
boolQuery.must(QueryBuilders.termQuery("city","杭州"));// 2.3.添加range
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);// 3.发送请求SearchResponse response = client.search(request,RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);}
2.5.排序、分页
搜索结果的排序和分页是与query同级的参数,因此同样是使用request.source()来设置。
对应的API如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a8ZMhOPL-1644368856404)(assets/image-20210721221121266.png)]](https://img-blog.csdnimg.cn/721e98d6d11041188145197e10a45881.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
完整代码示例:
@TestvoidtestPageAndSort()throwsIOException{// 页码,每页大小int page =1, size =5;// 1.准备RequestSearchRequest request =newSearchRequest("hotel");// 2.准备DSL// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());// 2.2.排序 sort
request.source().sort("price",SortOrder.ASC);// 2.3.分页 from、size
request.source().from((page -1)* size).size(5);// 3.发送请求SearchResponse response = client.search(request,RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);}
3.6.高亮
高亮的代码与之前代码差异较大,有两点:
- 查询的DSL:其中除了查询条件,还需要添加高亮条件,同样是与query同级。
- 结果解析:结果除了要解析_source文档数据,还要解析高亮结果
3.6.1.高亮请求构建
高亮请求的构建API如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JLtv0YLT-1644368856405)(assets/image-20210721221744883.png)]](https://img-blog.csdnimg.cn/529832ebcab8486992d1573154ba8cea.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
上述代码省略了查询条件部分,但是大家不要忘了:高亮查询必须使用全文检索查询,并且要有搜索关键字,将来才可以对关键字高亮。
完整代码如下:
@TestvoidtestHighlight()throwsIOException{// 1.准备RequestSearchRequest request =newSearchRequest("hotel");// 2.准备DSL// 2.1.query
request.source().query(QueryBuilders.matchQuery("all","如家"));// 2.2.高亮
request.source().highlighter(newHighlightBuilder().field("name").requireFieldMatch(false));// 3.发送请求SearchResponse response = client.search(request,RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);}
3.6.2.高亮结果解析
高亮的结果与查询的文档结果默认是分离的,并不在一起。
因此解析高亮的代码需要额外处理:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gSjHUphK-1644368856406)(assets/image-20210721222057212.png)]](https://img-blog.csdnimg.cn/6cca313d3e8e4dc482689c1064f6826e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1blt6XnqIvluIjlkYA=,size_20,color_FFFFFF,t_70,g_se,x_16)
代码解读:
- 第一步:从结果中获取source。hit.getSourceAsString(),这部分是非高亮结果,json字符串。还需要反序列为HotelDoc对象
- 第二步:获取高亮结果。hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值
- 第三步:从map中根据高亮字段名称,获取高亮字段值对象HighlightField
- 第四步:从HighlightField中获取Fragments,并且转为字符串。这部分就是真正的高亮字符串了
- 第五步:用高亮的结果替换HotelDoc中的非高亮结果
完整代码如下:
privatevoidhandleResponse(SearchResponse response){// 4.解析响应SearchHits searchHits = response.getHits();// 4.1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+ total +"条数据");// 4.2.文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历for(SearchHit hit : hits){// 获取文档sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json,HotelDoc.class);// 获取高亮结果Map<String,HighlightField> highlightFields = hit.getHighlightFields();if(!CollectionUtils.isEmpty(highlightFields)){// 根据字段名获取高亮结果HighlightField highlightField = highlightFields.get("name");if(highlightField !=null){// 获取高亮值String name = highlightField.getFragments()[0].string();// 覆盖非高亮结果
hotelDoc.setName(name);}}System.out.println("hotelDoc = "+ hotelDoc);}}
版权归原作者 CV工程师呀 所有, 如有侵权,请联系我们删除。