
Scala配置教程
IDEA配置Scala:教程
配置Spark运行环境
添加Spark开发依赖包(快捷键:Ctrl+Alt+Shift+S)


找到Spark安装目录下的jars文件夹,将整个文件夹导入

Spark编程环境配置完成

在com.tipdm.sparkDemo包下新建WordCount类并指定类型为object,编写spark程序实现单词计数器。
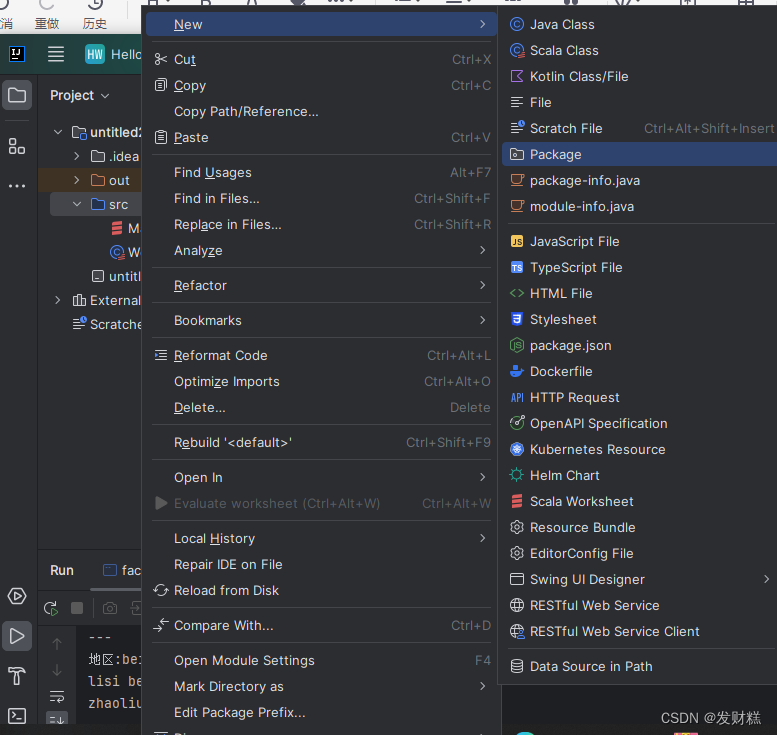




选择Dependencies勾选Scala-sdk-2.12.15和jars

添加Add Content root Root

选择jars点击ok

编写Spark程序
在Scala的基础上(教程)
1、包和导入
package com.tipdm.sparkDemo
import org.apache.spark.{SparkConf, SparkContext}
这里定义了一个包(
com.tipdm.sparkDemo
),并导入了
SparkConf
和
SparkContext
这两个类,它们都是Apache Spark的核心组件。
2、定义对象
object WordCount {
这里定义了一个单例对象
WordCount
。在Scala中,对象可以包含方法和字段,并且可以作为程序的入口点。
3、主函数
def main(args: Array[String]): Unit = {
这是程序的入口点,
main
函数。它接收一个字符串数组作为参数(通常用于命令行参数),并返回
Unit
(在Scala中,这相当于Java中的
void
)。
4、创建Spark配置和上下文
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
首先,创建一个
SparkConf
对象并设置应用程序的名称为"WordCount"。然后,使用这个配置创建一个
SparkContext
对象,它是Spark应用程序的入口点。
5、定义输入文件路径
val input = "C:\\Users\\John\\Desktop\\words.txt"
这里定义了一个字符串变量
input
,它包含了要读取的文件的路径。
6、单词计数逻辑
val count = sc.textFile(input).flatMap(x => x.split(" ")).map(
x => (x, 1)).reduceByKey((x, y) => x + y)
* `sc.textFile(input)`:从指定的路径读取文件,并返回一个RDD(弹性分布式数据集),其中每个元素是文件中的一行。
* `flatMap(x => x.split(" "))`:将每一行分割成单词,并扁平化结果。这意味着所有行的单词都会合并到一个单一的RDD中。
* `map(x => (x, 1))`:为每个单词映射一个键值对,其中键是单词,值是1。这表示每个单词都出现了一次。
* `reduceByKey((x, y) => x + y)`:对于具有相同键的所有值,执行reduce操作。在这里,它简单地将所有1相加,从而计算每个单词的出现次数。
7、输出结果
count.foreach(x => println(x._1 + "," + x._2))
使用
foreach
操作遍历结果RDD,并打印每个单词及其出现次数。
x._1
是键(单词),
x._2
是值(出现次数)。
整个程序会读取指定路径下的文件,计算每个单词的出现次数,并打印结果。这是一个使用Spark进行基本文本分析的常见示例。
words.txt放在桌面了所以路径为
C:\Users\John\Desktop\words.txt

words.txt文件内容为:
Hello World Our World
Hello BigData Real BigData
Hello Hadoop Great Hadoop
HadoopMapReduce
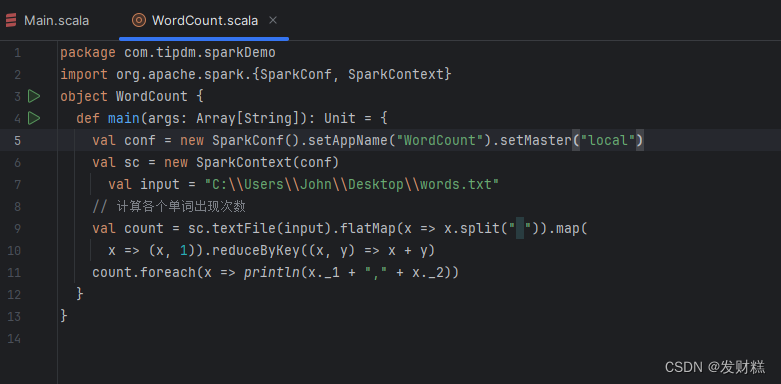
8、完整代码:
package com.tipdm.sparkDemo
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val input = "C:\\Users\\John\\Desktop\\words.txt"
// 计算各个单词出现次数
val count = sc.textFile(input).flatMap(x => x.split(" ")).map(
x => (x, 1)).reduceByKey((x, y) => x + y)
count.foreach(x => println(x._1 + "," + x._2))
}
}
运行成功

本文转载自: https://blog.csdn.net/zhangfafa_c/article/details/136719400
版权归原作者 发财糕 所有, 如有侵权,请联系我们删除。
版权归原作者 发财糕 所有, 如有侵权,请联系我们删除。