
Lin等人的《网络中的网络(Network in Network, NiN)》一文,提出了一种特殊的卷积操作,它允许跨通道参数级联,通过汇聚跨通道信息来学习复杂的交互。他们将其称为“交叉通道参数池化层”(cross channel parametric pooling layer),并将其他操作与1x1卷积核进行卷积的操作相比较。
当时浏览一下细节,我从没想过我使用这样的操作,更不用说对其细节有任何的想法。但是通常是术语看起来很深奥,而概念本身并不是。在我了解背景和进行了一系列的测试以后,让我们一起来解开这个奇特但多用途的1x1卷积层的神秘面纱。
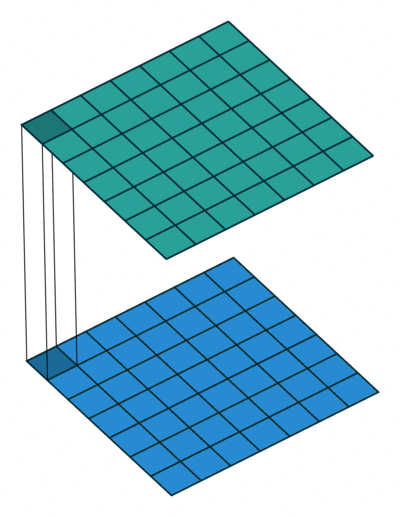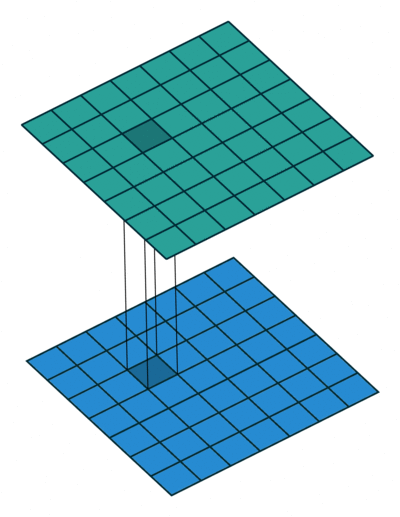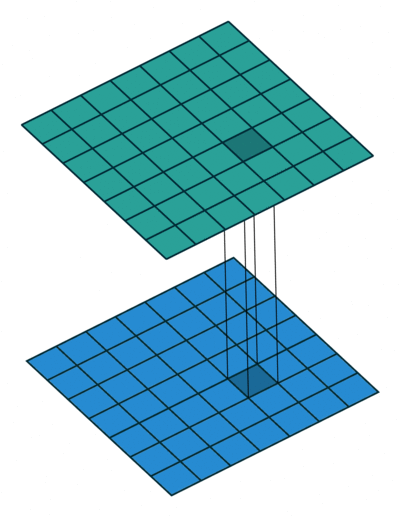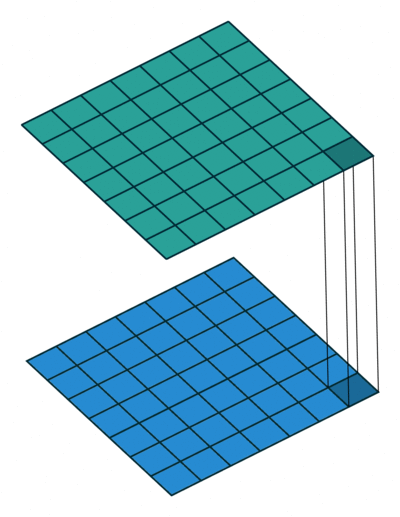
1 x1卷积
顾名思义,1x1卷积操作涉及到将输入与尺寸为1x1的过滤器进行卷积,通常使用0填充和步长为1。
举个例子,假设我们有一个(通用的)卷积层,输出一个形状张量(B, K, H, W),
B为批大小。K是卷积过滤器或核的数量,H、W为空间维度,即高、宽。
此外,我们指定了一个想要处理的过滤器大小,对于一个正方形过滤器可以使用单个数字,即size=3意味着一个3x3的过滤器。
deephub译者注:一般情况下,过滤器(filter)又可称为卷积核(kernel)。如果严谨的讲,卷积核就是由长和宽来指定的,是一个二维的概念,而过滤器是由长、宽和深度指定的,是一个三维的概念。过滤器可以看做是卷积核的集合,一般情况下可以通用,但是这里为了说明我们使用过滤器作为其统称,下面不做区分
将这个张量输入到带有F过滤器(零填充和跨度1)的1x1卷积层中,我们将获得形状(B,F,H,W)的输出,将过滤器尺寸从K更改为F。
现在,根据F是小于还是大于K,我们减小或增大了过滤器空间中输入的维数,而未进行任何空间变换(H,W不变)。所有这些就是使用1x1卷积运算!
但是,这与常规卷积操作有何不同?在常规的卷积运算中,我们通常会使用较大的过滤器大小,例如3x3或5x5(甚至7x7)内核,然后通常对输入进行某种填充,进而将H x W的空间尺寸转换为某些 H'x W'。
好处
在cnn中,我们经常使用某种池化操作来对卷积输出的激活映射进行空间下采样,以避免由于生成的激活图的数量增加使反向传播变得难以处理。这种问题是与CNN的深度成正比的。也就是说,一个网络越深,它产生的激活地图的数量就越大。如果卷积运算使用的是大型滤波器,如5x5或7x7滤波器,问题会进一步恶化(因为参数变多)。
空间下采样(通过池化)是通过在每一步减少输入的高度和宽度,沿空间维度聚合信息来实现的。虽然它在一定程度上保留了重要的空间特征,但在降采样和信息丢失之间确实存在权衡。底线是:我们只能在一定程度上使用。
1x1卷积可通过提供按过滤器的池化功能来解决此问题,它充当投影层,可跨通道池化(或投影)信息,并通过减少过滤器数量同时保留重要的,与功能相关的信息来降低尺寸。
这在谷歌的inception中被大量使用,他们说明如下:
以上模块的一个大问题(至少在这种简单的形式中是这样的)是,即使是少量的5x5卷积,在带有大量过滤器的卷积层之上也会变得非常昂贵。
这导致了提出这个体系结构的第二个想法:在计算需求会增加太多的地方进行尺寸缩减和投影。这种嵌入是成功的,即使是低维的嵌入也可能包含许多有关较大图像补丁的信息。除了用作减少计算量之外,它们还包括使用RELU激活,使其具有双重用途。
谷歌介绍了在昂贵的3x3和5x5卷积之前使用1x1卷积来减少计算量的方法。代替使用池化来降低空间维数,可以使用1x1卷积在滤波器维上进行降维。
Yann LeCun提供了一个有趣的思路,他将CNN中的完全连接层模拟为具有1x1卷积内核和完整连接表的简单卷积层。
实现
在讨论了这个概念之后,现在来看看一些实现,通过一些基本的PyTorch代码,很容易理解这些实现。
class OurConvNet(nn.Module):
def __init__(self):
super().__init__()
self.projection = None
# Input dims expected: HxWxC = 36x36x3
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1)
# Output dims: HxWxC = 36x36x32
# softconv is the 1x1 convolution: Filter dimensions go from 32 -> 1 implies Output dims: HxWxC = 36x36x1
self.softconv = nn.Conv2d(in_channels=32, out_channels=1, kernel_size=1, stride=1, padding=0)
def forward(self, input_data):
# Apply convolution
x = self.conv1(input_data)
# Apply tanh activation
x = torch.tanh(x)
# Apply the 1x1 convolution
x = self.softconv(x)
# Apply sigmoid activation
x = torch.sigmoid(x)
# Save the result in projection
self.projection = x
这里,我用softconv来表示1x1卷积。这是最近一个项目的代码片段,其中使用1x1卷积将信息投射到过滤器维度(本例中为32),并将其汇集到单个维度中。这给我的用例带来了三个好处:
- 将来自32个二维激活图(通过在输入上对前卷积层的滤镜进行卷积生成)中的信息投影到单个激活图(请记住,softconv层的输出的滤镜为dim = 1)。为什么需要这样的投影,下面的图片对此进行了说明。。
- 使用1x1卷积来减少维度,允许保持计算需求的检查。这是基于低维嵌入的理解,因为它在自然语言处理领域工作得很好。
- 提供了更好的可处理性,易于可视化的过滤器权重,将被学习,即能够回答什么层实际做了给定的输入和理解什么模型是学习。
此外,tanh和Sigmoid激活是实现细节,对于本例可以忽略。
为了深入了解可能使用1x1卷积的想法,我提供了一个在DEAP情感数据集上训练的模型中的用例,本例只为说明没有涉及很多细节。该模型经过训练可以预测来自面部视频(图像)的心率信号。在这里,使用1x1卷积层将来自32个滤镜(从先前的卷积中获得)的信息汇总到单个通道中,使模型可以创建一个蒙版,从而能够区分皮肤像素和非皮肤像素。虽然这个工作目前并不完善,但希望可以在这里看到使用1x1卷积的意义。

用作输入的面部图像。图像来自DEAP数据集

应用常规卷积层后32个滤波器的状态。

从softconv层获得的输出,其中32个过滤器被汇集到一个单一通道。
关键总结
1x1卷积可以看作是一个操作,在输入上应用一个1x1 x K大小的滤波器,然后加权生成F激活映射。
F > K会导致滤波器尺寸的增加,而F < K则会导致滤波器尺寸的减少。F的值很大程度上取决于项目的要求。降低维数可能有助于使事情更容易处理,并且可能有一个类似的用例,使用1x1卷积来增加滤波器的数量。
理论上使用这个操作,神经网络可以使用1x1卷积“选择”哪个输入“过滤器”来查看,而不是强制相乘。
引用
*[1] Stats StackExchange:*https://stats.stackexchange.com/questions/194142/what-does-1x1-convolution-mean-in-a-neural-network
[2] Google Inception Architecture: Going Deeper with Convolutions by Lin et al.
*[3] Article:*https://iamaaditya.github.io/2016/03/one-by-one-convolution/
[5] ”DEAP: A Database for Emotion Analysis using Physiological Signals”, S. Koelstra, C. Muehl, M. Soleymani, J.-S. Lee, A. Yazdani, T. Ebrahimi, T. Pun, A. Nijholt, I. Patras, IEEE Transactions on Affective Computing, vol. 3, no. 1, pp. 18–31, 2012