

嘉宾 | 陈东东
出品 | CSDN云原生
2022年7月28日,中国信通院、腾讯云、FinOps产业标准工作组联合发起的《原动力x云原生正发声 降本增效大讲堂》系列直播活动第4讲如期举行,腾讯高级工程师陈东东分享了Caelus全场景在离线混部的实践案例。本文整理自陈东东的分享。

在离线混部背景及意义
各大权威机构的调研数据显示,在线资源利用率普遍很低,平均在15%左右。
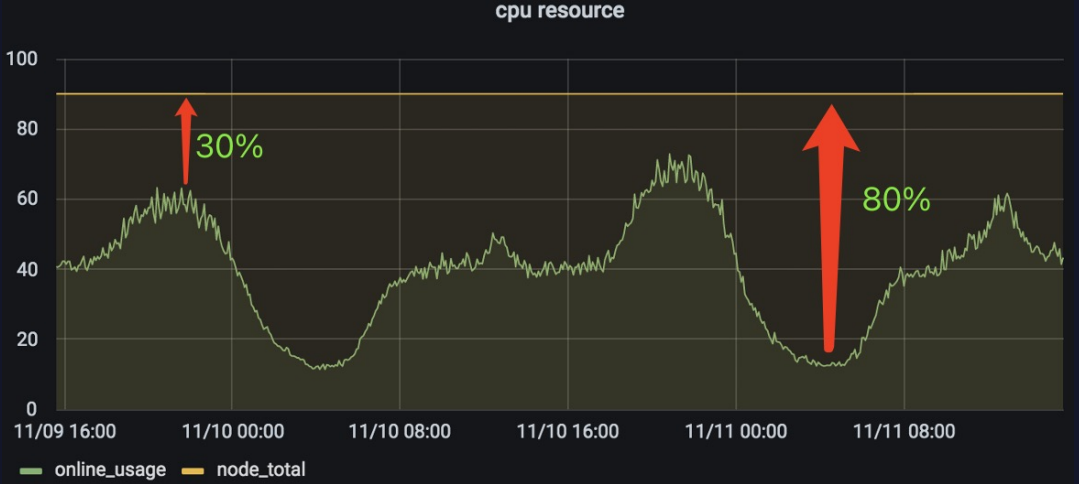
上图是某一在线CPU的使用曲线,在这里可以看出,在线资源使用的潮汐现象十分明显。业务方在申请资源时只能按照波峰时段的资源使用量进行申请,这就导致在波谷时段会有大量资源被浪费。
在线资源利用率低的原因可以概括为以下几点:
- 非容器化部署,未能利用整机资源;
- 业务容灾Buffer资源;
- 资源使用潮汐现象;
- 粗放的资源评估,占而不用;
- 业务之间相互隔离。
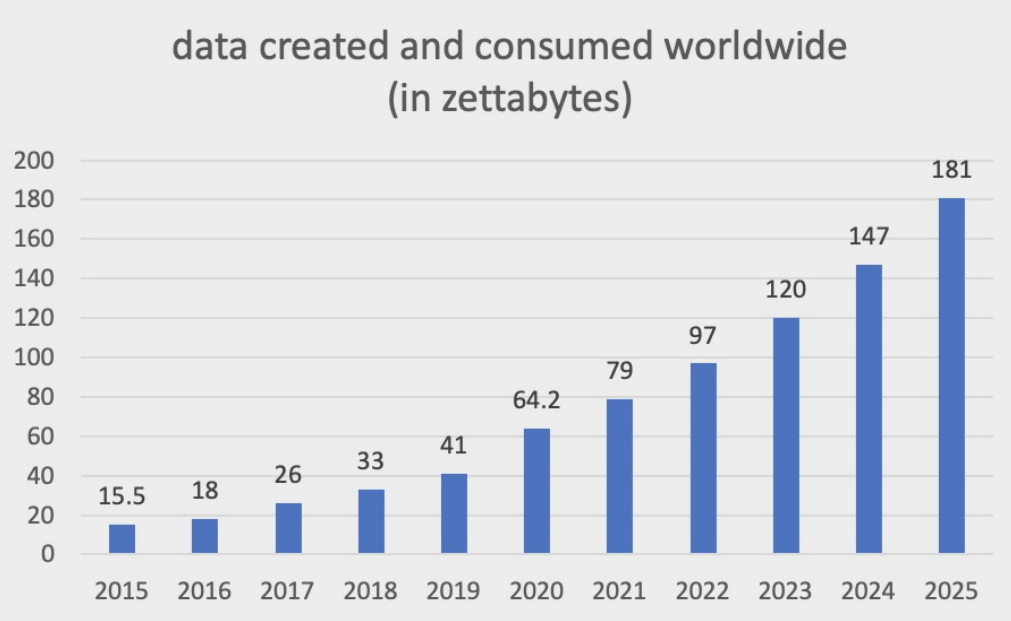
从上图可以看出,近年来我们对大数据的需求在逐步增高,这意味着我们需要投入更多成本来获取更多算力来对数据进行分析。离线作业运行时具有延迟不敏感、实时性不高、执行周期短等特点,利用该特点我们可以在在线任务的波谷时段混部离线任务,这为解决在线任务波谷时段有大量资源浪费提供了一种新的思路。
通过在离线混部,可以实现提升机器资源利用率、优化成本等目标,同时能够充分释放资源价值,降低能源消耗,助力双碳。
在离线混部现状痛点
在离线混部在落地过程中存在诸多痛点。
- 定制化- 技术栈定制化,不宜推广;- 平台升级需适配,维护成本高;- 混部场景单一,大部分混部系统只关注容器化场景,忽略了非容器化场景,部分混部方案依赖大数据任务云原生化改造,难以支持Hadoop场景。
- 资源价值挖掘不充分- 资源复用策略不够精细,利用率提升有限;- 离线失败率高,浪费算力资源。
- 技术深水区- 缺乏干扰检测与处理机制;- 缺乏完善的资源隔离机制;- 调度性能不满足离线高并发需求;- 缺乏容器热迁移机制,离线作业在资源受压制时只能被驱逐。

Caelus全场景在离线混部
Caelus是腾讯基于多年的混部经验打造的在离线混部系统,兼容多种在线和离线混部场景。
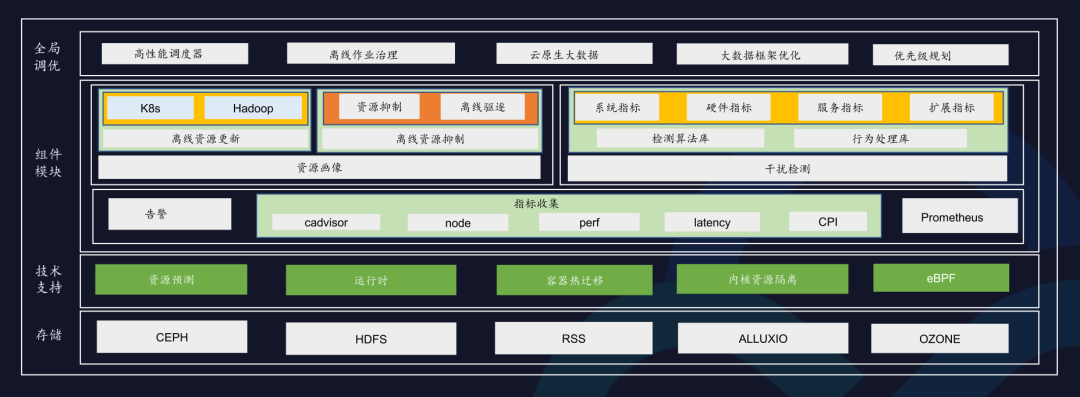
上图是在离线混部的架构图,可以看到,Caelus联动存储、内核、运行时、调度及离线框架等层面,在保障在线和离线服务质量的同时,最大化提升资源利用率。
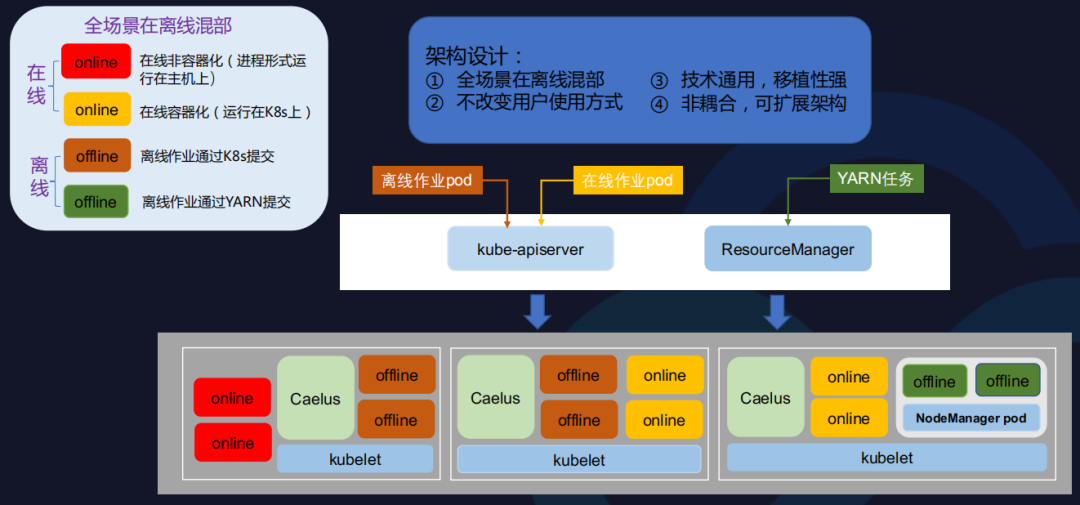
上图展示了Caelus全场景在离线混部。在线容器化已成为一种趋势,然而我们也要看到当前还有很多在线作业未容器化,这些在线作业可能还未来得及容器化,或不适合容器化。Caelus通过支持非容器化在线作业,可以打破混部在很多公司场景的限制。大数据任务是非常适合混部的,然而当前很多的大数据任务还是处于Hadoop生态,所占比例也非常高,针对这部分离线任务,Caelus也是要支持的。

在线服务质量保障关键技术与思考
为保证在线服务质量,Caelus采取了一些关键的技术手段。
多维度指标
为什么需要多维度指标呢?
- 混部资源使用状态,包括节点资源、在线资源、离线资源等;
- 业务运行健康度,在线是否受到影响、离线是否正常运行;
- 预测,短/长周期预测的数据来源;
- 干扰检测,在线干扰识别的对比依据。
此外,指标也需满足多维度、周期长、可溯源等要求,该如何实现呢?
- 多维度指标来源:Cadvisor、Node、eBPF、Perf、RDT、自定义指标。
- 集成TSDB事件序列存储- 本地存储,占用空间少,重启不影响;- 支持时间范围查询、效率高;- 支持Prometheus查询接口,方便溯源;- 支持表达式查询,数据统计更便捷。
预测
在混部过程中,预测可以指导我们为离线服务预留资源量,否则就只能根据历史经验对离线可用资源量进行预估。
- 离线资源配置过低,机器利用率提升有限;
- 离线资源配置过高,与在线资源产生竞争。
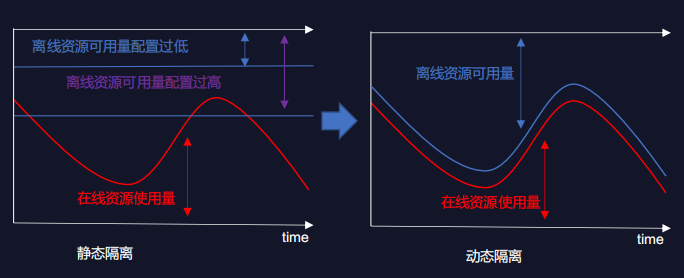
为了更好地保护在线资源服务,大多时候我们只在波谷时期部署离线任务,而不是24小时混部。动态预测可以使离线资源随在线资源量的变化而变化,在不挤占在线资源的前提下,实现资源利用率最大化。
预测有两种不同的方式。
全局考虑应用下所有实例资源使用情况,进行统一预测;新扩容机器根据历史数据立即获取到预测资源。
根据节点资源实际使用量预测,包括在线和系统进程;在线作业资源突变时,可以快速作出反应。
- 集中预测
- 分布式预测
一些常用的预测算法如下所示:
- 长周期预测:Prophet、Long short-term memory(LSTM);
- 短周期预测:VPA、Autopilot、AutoRegressive Integrated;
- 机器学习:Multilayer Perceptorn(MLP)。
干扰检测与处理
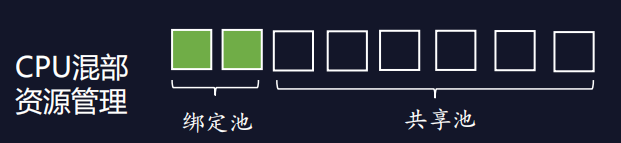
干扰检测与处理是混部的放大器****。以CPU资源管理为例,为了更好地保护在线业务,我们可以采用CPUset隔离核的方式,让离线任务只能运行在共享池,不允许复用绑定池资源。这会带来绑定池空闲资源无法被利用,而共享池资源被离线作业严重挤压问题。
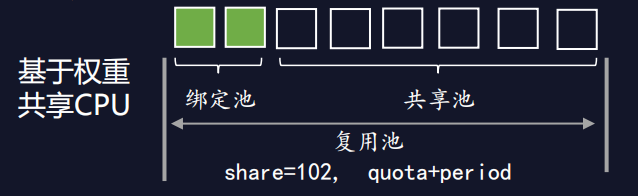
基于权重的共享CPU管理方式让离线应用可以复用所有空闲资源,同时调低离线任务的权重来降低对在线CPU资源的抢占,并采用quota与period结合的形式来限制离线业务对资源的使用。
在这种模式下,在线是不是一定不会受到干扰呢?答案是否定的。
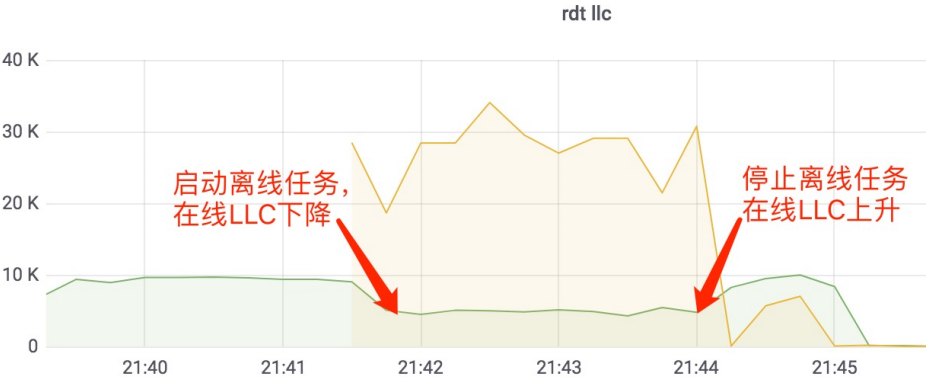
- 共享Cache和内存带宽等资源,在线应用仍会有影响;
- 资源隔离依赖某些硬件功能或系统配置,受场景限制;
- 内核版本低,隔离能力弱。
为了更好地保证在线服务质量,需要干扰检测与处理机制。该机制全方位实时检测在线是否受到干扰,并采取措施,如压制离线资源或驱逐离线任务,及时消除干扰。
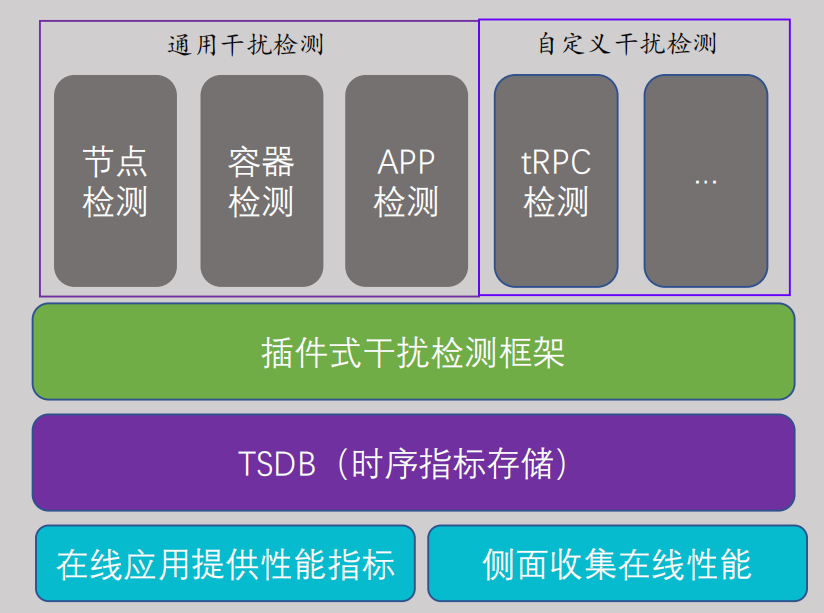
- 多维度指标收集:系统级别和业务级别;
- 时序数据库存储:指标数据长时间存储,便于周期性和多维度对比;
- 插件式干扰检测框架:灵活扩展,自定义检测插件。
混部资源管理方式
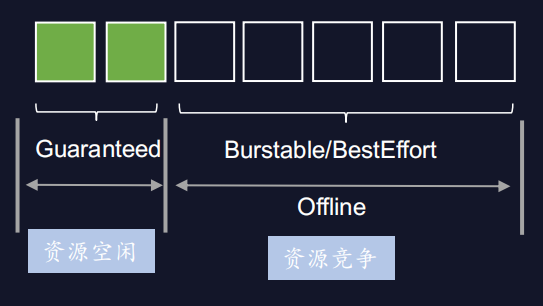
离线任务运行在在线机器上,复用在线机器的空闲资源,在云原生场景下应该如何管理离线资源呢?
以CPU资源为例,在云原生场景下,离线任务通过扩展资源提交,默认为BestEffort类型。
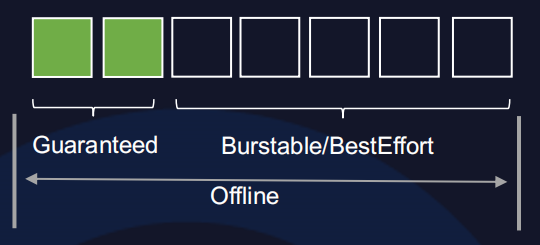
- CPU不能复用Guaranteed类型的空闲资源(CPU Manager开启Statics策略);
- 内存不能复用所有空闲内存(Kubelet开启QoSReserved策略);
对于离线任务只能复用部分空闲资源问题,我们考虑把离线进程放入独立cgroup目录下。我们可以通过周期性移动离线进程到独立cgroup目录下,但这种方式时效性差,尤其是离线任务在刚启动时若消耗大量CPU,这段时间的离线资源开销是不可控的。
基于此,我们采用拦截的方式,在离线任务创建时,让其进程直接放入独立cgroup目录(Offline目录)下。该目录独立于Kubelet管理范围,可复用全部空闲资源。拦截操作不入侵Kubernetes原生代码逻辑,具有兼容性强、方便移植的特点。
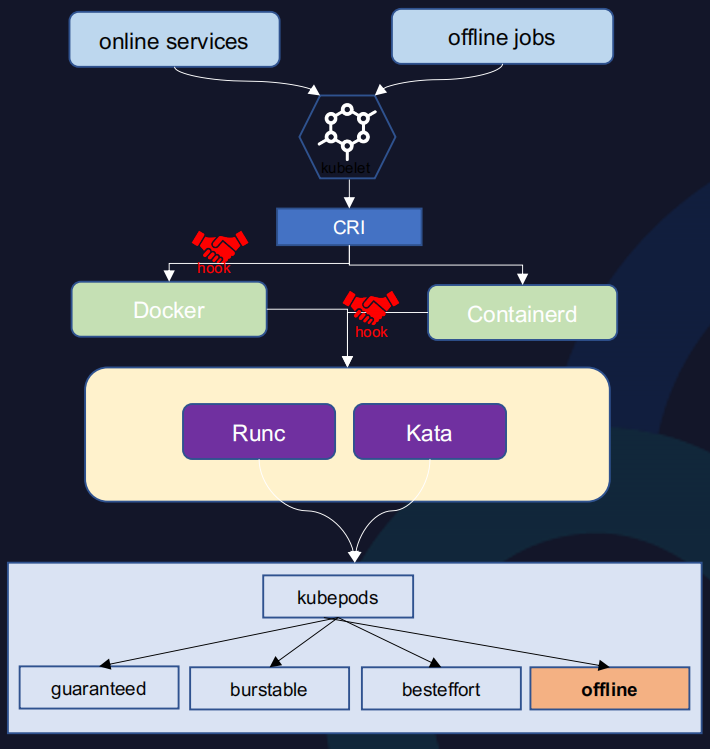
全维度资源隔离
资源隔离是混部的基础,全维度资源隔离能够避免离线在单一维度上的资源挤占对在线造成影响。
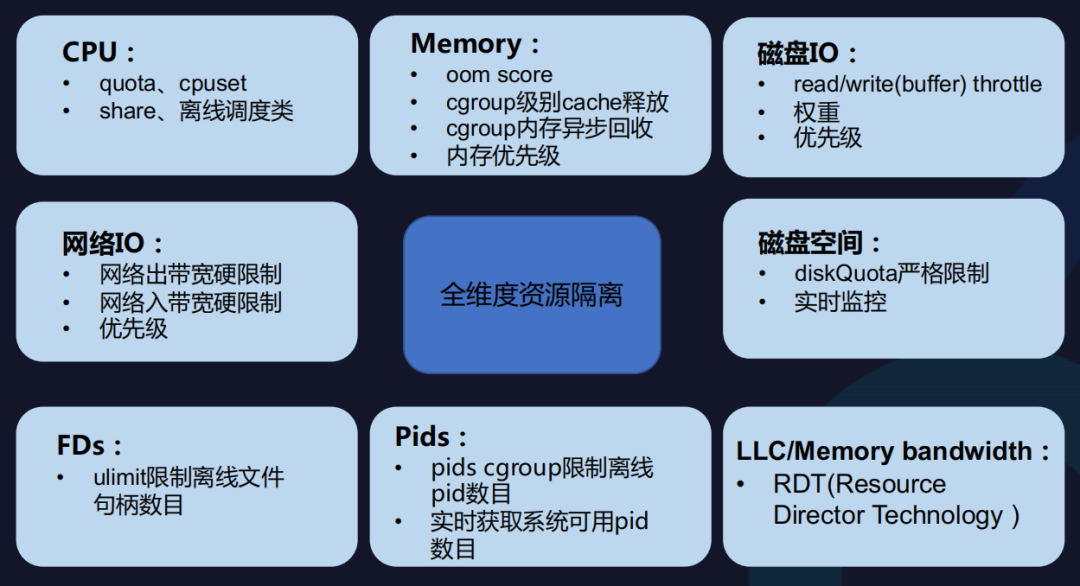
资源隔离要遵循两个原则。
- 离线资源严格限制,保障在线资源充裕;
- 在线高优先级抢占,实时满足在线资源需求。

离线服务质量保障技术及思考
离线高性能调度
混部离线任务主要是大数据任务,大数据任务多是短作业且数量大、并发度高,对调度要求非常高。
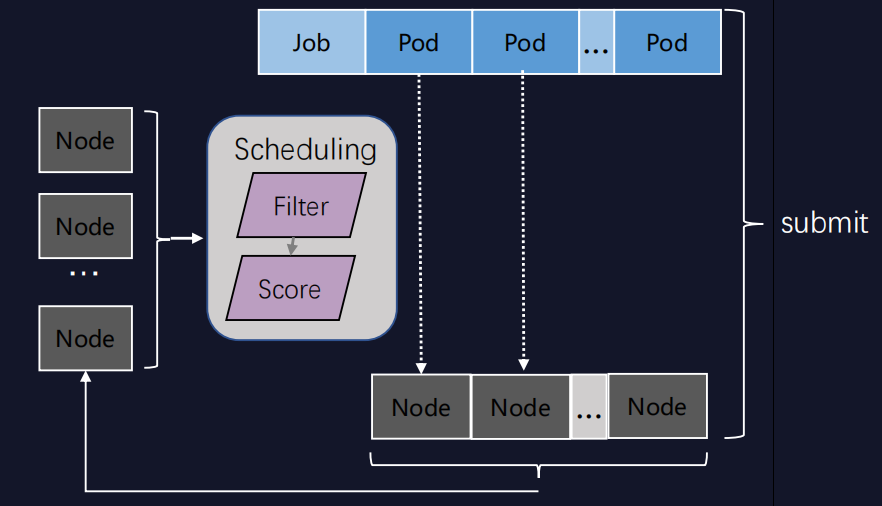
Kubernetes原生的调度逻辑面向在线业务,注重在线的调度功能,无法满足离线业务的性能需求。所以我们自研了离线调度器,采用批量调度方式,相较K8s原生调度器,有数量级的提升。
在离线任务填充满集群的情况下,若有大量在线任务需要调度,我们可以采用批量抢占的方式迅速抢占离线,从而大大提高在线调度的调度效率。在提升调度性能的同时,我们也通过插件式机制高效实现各种功能迭代。
混部场景下,在线调度和离线调度该如何协同呢?
若集群只有一个调度器,在线和离线调度逻辑集中在一起,会产生调度器逻辑复杂、调度性能易成为瓶颈等问题。
若采用多个调度器基于全局锁进行协调,调度器在进行调度前需要先获得锁,才能进行调度。这种方式并发度低、资源利用率低,故又被称为“悲观并发”。
当前,我们采用的是“多调度器+协调器”的方式进行调度,它也被称为基于共享状态的“乐观并发”。
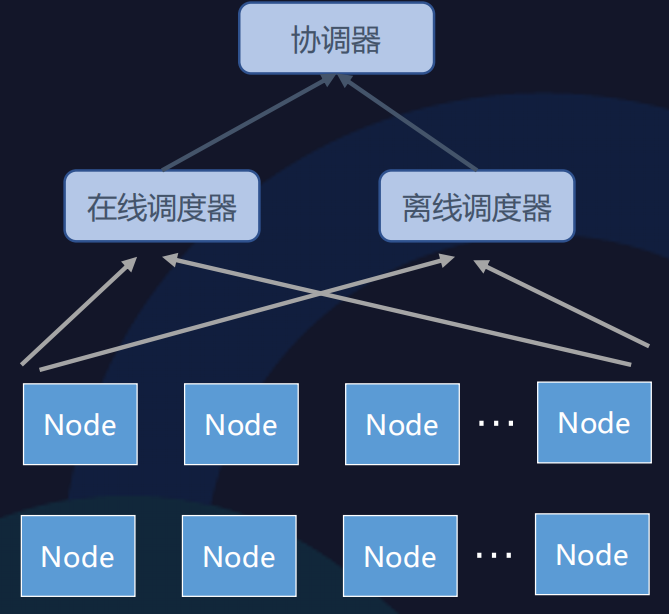
如上图所示,集群中不同的调度器单独进行调度,在绑定节点之前向协调器申请资源。协调器可以统筹协调调度,支持多调度器同时运行,且具有高效的冲突解决机制。多调度器+协调器架构能够兼顾在线调度的功能需求和离线调度的性能需求。
大数据任务混部服务质量保障
混部的离线任务包括大数据任务和AI训练任务,大数据任务当前可分为云原生大数据和Hadoop,Caelus原生支持云原生大数据。针对Hadoop场景下的大数据任务,我们采用YARN on K8s的方式,将NM(Node Manager)以容器化的方式运行在K8s上。
为了保证NM在容器中稳定地运行,我们也做了很多优化。如镜像热升级功能可以保证容器中的离线任务在NM Pod升级过程中继续保持运行。另外混部资源是动态变化的,所以RM(Resource Manager)端的资源也需要动态感知,热更新capacity功能可以在不重启NM进程的情况下,动态地更新NM在RM端的资源,从而减少因重启带来的资源开销。
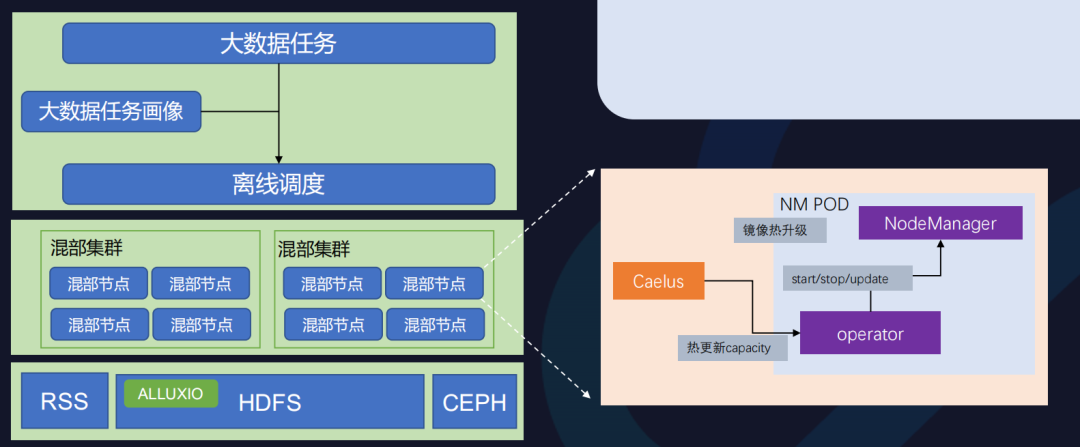
混部资源具有不稳定性,大数据任务若直接运行在混部资源上,会产生较高的失败率,导致无效算力。针对这类问题,我们在实践中总结出部分操作经验:
- 大数据任务画像;
- 大数据任务筛选;
- 存算分离;
- 存储加速;
- 云盘扩展;
- NM容器化适配。
容器热迁移
部分混部任务(如AI训练任务等)运行时间一般都比较长,多以小时或天为单位。若这种类型的离线任务被驱逐,需重新运行,成本开销大。尤其是当面临内存这种不可压缩资源受压制时,当前我们只能采用驱逐离线任务的策略。
容器热迁移可以很好地解决需长时间运行的离线任务被驱逐所产生的问题。
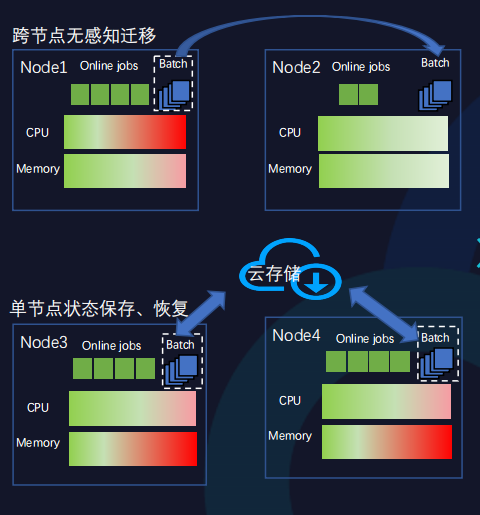
容器热迁移是指在保证离线任务正常运行的前提下,从一个节点迁移到另一个节点。
当前基于虚拟机的热迁移技术已经十分成熟,但基于容器的热迁移技术的探索及实践都较少。腾讯内部基于容器热迁移进行了诸多实践与优化,以内存迁移为例,常规的内存迁移是先停掉原节点离线任务,再将离线任务一次性迁移至目标节点后重新运行。这种方式会造成离线任务的中断时间较长,质量难以保证。
我们采取了诸多策略保障中断时间尽量短,如采用内存按需迁移,同时在迁移过程中,采用压缩、并发方式加大内存存储速率。另外,我们也探索更加均衡的迁移策略,如采用迭代迁移方式。

Caelus实践落地
目前,Caelus已在腾讯内部多个场景落地,涵盖广告业务,腾讯视频、新闻和QQ等娱乐社交业务,王者对战等游戏业务,还包括CEPH、HDFS等存储业务,HBase等数据库业务。在线场景包括容器化和非容器化,离线任务包括大数据和机器学习等任务。Caelus已经开源,欢迎大家积极贡献代码,一起助力Caelus在更多场景的落地。
开源地址:https://github.com/Tencent/caelus
【原动力×云原生正发声降本增效大讲堂】第一期聚焦在优秀实践方法论、资源与弹性、架构设计;第二期聚焦全场景在离线混部、K8s GPU资源效率提升、K8s资源拓扑感知调度主题,点击『此处』进入活动专题,带你体验云原生降本增效实践案例、了解如何解决企业用云痛点、掌握降本增效关键技能……
版权归原作者 CSDN云原生 所有, 如有侵权,请联系我们删除。