
docker
核心原理
docker的核心原理其实就是cgroup+namespace+unionfs 组合实现的隔离机制,资源控制等。
隔离机制
- 在容器进程启动之前重新挂载它的整个根⽬录“/”,⽤来为容器提供隔离后的执⾏环境⽂件系统
- 通过Linux Namespace 创建隔离,决定进程能够看到和使⽤哪些东⻄。
- 通过control groups 技术来约束进程对资源的使⽤
unionfs
首先看rootfs,rootfs 是Docker 容器在启动时内部进程可⻅的⽂件系统,即Docker容器的根⽬录。rootfs通常包含⼀个操作系统运⾏所需的⽂件系统,例如可能包含经典的类Unix操作系统中的⽬录系统,如/dev、/proc、/bin、/etc、/lib、/usr、/tmp及运⾏Docker容器所需的配置⽂件、⼯具等。
在传统的linux操作系统内核启动时,⾸先挂载⼀个只读(read-only)的rootfs,当系统检测器完整性之后,再将其切换为读写(read-write)模式。⽽在Docker架构中,当Docker daemon 为Docker容器挂载rootfs时,沿⽤的Linux内核启动时的⽅法,即将rootfs设为只读模式。在挂载完毕之后,利⽤联合挂载(union mount)技术在已有的只读rootfs上再挂载⼀个读写层。这样,可读写层处于Docker容docker器⽂件系统的最顶层,其下可能联合挂载了多个只读层,只有在Docker容器运⾏过程中⽂件系统发⽣变化是,才会把变化的⽂件内容写到可读写层,并且隐藏只读层中的⽼版本⽂件。
如图所示,还可以在rootfs之上继续挂载读写层,也可以挂载只读层(可以用于共享)。上层的修改不会影响到下层的只读层。而只读层的修改会同步到上层可写层
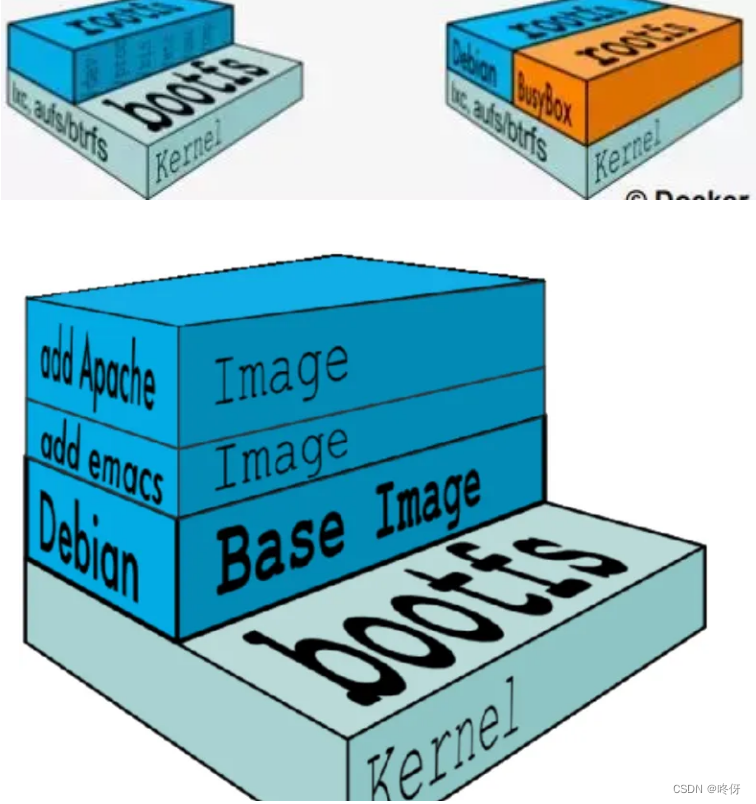
有了容器镜像“打包操作系统”的能⼒,这个最基础的依赖环境也终于变成了应⽤沙盒的⼀部分。这就赋予了容器所谓的⼀致性:⽆论在本地、云端,还是在⼀台任何地⽅的机器上,⽤户只需要解压打包好的容器镜像,那么这个应⽤运⾏所需要的完整的执⾏环境就被重现出来了
namespace
概念
是一种资源隔离技术,可以和c++里的namespace类比
- namespace 是 Linux 内核⽤来隔离内核资源的⽅式。通过 namespace 可以让⼀些进程只能看到与⾃⼰相关的⼀部分资源,⽽另外⼀些进程也只能看到与它们⾃⼰相关的资源,这两拨进程根本就感觉不到对⽅的存在。具体的实现⽅式是把⼀个或多个进程的相关资源指定在同⼀个 namespace 中。
- Linux namespaces 是对全局系统资源的⼀种封装隔离,使得处于不同 namespace 的进程拥有独⽴的全局系统资源,改变⼀个 namespace 中的系统资源只会影响当前 namespace ⾥的进程,对其他namespace 中的进程没有影响。
namespace解决了什么问题呢?
Linux 内核实现 namespace 的⼀个主要⽬的就是实现轻量级虚拟化(容器)服务。在同⼀个namespace 下的进程可以感知彼此的变化,⽽对外界的进程⼀⽆所知。这样就可以让容器中的进程产⽣错觉,认为⾃⼰置身于⼀个独⽴的系统中,从⽽达到隔离的⽬的。也就是说 linux 内核提供的namespace 技术为 docker 等容器技术的出现和发展提供了基础条件。
有哪些namespace
- Mount Namespace隔离了⼀组进程所看到的⽂件系统挂载点的集合,因此,在不同MountNamespace的进程看到的⽂件系统层次结构也不同
- UTS Namespace隔离了uname()系统调⽤返回的两个系统标示符nodename和domainname,在容器的上下⽂中,UTS Namespace允许每个容器拥有⾃⼰的hostname和NIS domain name,这对于初始化和配置脚本是很有⽤的,这些脚本根据这些名称来定制它们的操作
- IPC Namespace隔离了某些IPC资源(interprocess community,进程间通信)使划分到不同IPC Namespace的进程组通信上隔离,⽆法通过消息队列、共享内存、信号量⽅式通信
- PID Namespace隔离了进程ID号空间,不同的PID Namespace中的进程可以拥有相同的PID。PID Namespace的好处之⼀是,容器可以在主机之间迁移,同时容器内的进程保持相同的进程ID。PID命名空间还允许每个容器拥有⾃⼰的init(PID 1),它是 “所有进程的祖先”,负责管理各种系统初始化任务,并在⼦进程终⽌时收割孤⼉进程
- Network Namespace提供了⽹络相关系统资源的隔离,因此,每个Network Namespace都有⾃⼰的⽹络设备、IP地址、IP路由表、/proc/net⽬录、端⼝号等。
- User Namespace隔离了⽤户和组ID号空间,⼀个进程的⽤户和组ID在⽤户命名空间内外可以是不同的,⼀个进程可以在⽤户命名空间外拥有⼀个正常的⽆权限⽤户ID,同时在命名空间内拥有⼀个(root权限)的⽤户ID
命名空间查看
ls /proc/{PID}/ns
cgroup
cgroup全称是control groups被整合在了linux内核当中,把进程(tasks)放到组⾥⾯,对组设置权限,对进程进⾏控制。可以理解为⽤户和组的概念,⽤户会继承它所在组的权限。cgroups是linux内核中的机制,这种机制可以根据特定的⾏为把⼀系列的任务,⼦任务整合或者分离,按照资源划分的等级的不同,从⽽实现资源统⼀控制的框架,cgroup可以控制、限制、隔离进程所需要的物理资源,包括cpu、内存、IO,为容器虚拟化提供了最基本的保证,是构建docker⼀系列虚拟化的管理⼯具
解决如下问题
- 资源控制:cgroup通过进程组对资源总额进⾏限制。如:程序使⽤内存时,要为程序设定可以使⽤主机的多少内存,也叫作限额
- 优先级分配:使⽤硬件的权重值。当两个程序都需要进程读取cpu,哪个先哪个后,通过优先级来进⾏控制
- 资源统计:可以统计硬件资源的⽤量,如:cpu、内存…使⽤了多⻓时间
- 进程控制:可以对进程组实现挂起/恢复的操作,
cgroup设计到许多子系统,每种子系统可以进行不同的资源调控
1. cpu⼦系统:该⼦系统为每个进程组设置⼀个使⽤CPU的权重值,以此来管理进程对cpu的访
问。
2. cpuset⼦系统:对于多核cpu,该⼦系统可以设置进程组只能在指定的核上运⾏,并且还可以
设置进程组在指定的内存节点上申请内存。
3. cpuacct⼦系统:该⼦系统只⽤于⽣成当前进程组内的进程对cpu的使⽤报告
4. memory⼦系统:该⼦系统提供了以⻚⾯为单位对内存的访问,⽐如对进程组设置内存使⽤上
限等,同时可以⽣成内存资源报告
5. blkio⼦系统:该⼦系统⽤于限制每个块设备的输⼊输出。⾸先,与CPU⼦系统类似,该系统
通过为每个进程组设置权重来控制块设备对其的I/O时间;其次,该⼦系统也可以限制进程组
的I/O带宽以及IOPS
6. devices⼦系统:通过该⼦系统可以限制进程组对设备的访问,即该允许或禁⽌进程组对某设
备的访问
7. freezer⼦系统:该⼦系统可以使得进程组中的所有进程挂起
8. net-cls⼦系统:该⼦系统提供对⽹络带宽的访问限制,⽐如对发送带宽和接收带宽进程限制
运⾏⼀个docker容器,查看容器的cgroup 和 linux namespace
docker pull nginx
docker run -p80:80 -d nginx
cd /sys/fs/cgroup //查看cgroup ⼦系统变化 并找到其对应的PID
cd /proc/{PID}/ns //查看命名空间
ps-ef|grep nginx
例如
ps -ef |grep nginx
可以看到有哪些nginx进程
[root@localhost cpu]# ps -ef| grep nginx
root 1497614953013:59 ? 00:00:00 nginx: master process nginx -g daemon off;1011501014976013:59 ? 00:00:00 nginx: worker process
1011501114976013:59 ? 00:00:00 nginx: worker process
可以看到worker由master fork出来,那么看master是父进程是哪个,其实就是docker containerd shim 进程。
docker containerd shim 进程在宿主机中进程树大概是下面这样。属于docker进程组
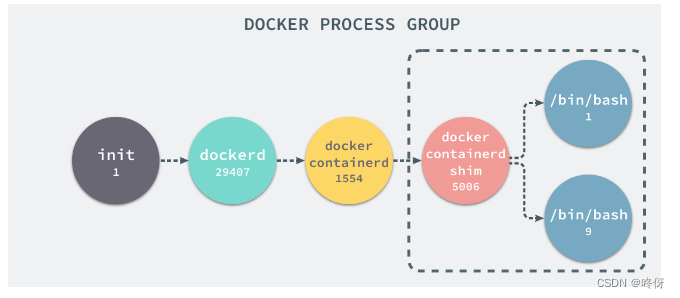
现在可以查看docker containerd shim 和 nginx master 和worker 的命名空间
#docker containerd shim 进程的ns
ll /proc/14953/ns
lrwxrwxrwx. 1 root root 0 Dec 1214:10 cgroup -> cgroup:[4026531835]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 net -> net:[4026531992]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 pid_for_children -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 time -> time:[4026531834]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 time_for_children -> time:[4026531834]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 Dec 1214:10 uts -> uts:[4026531838]
ll /proc/14976/ns
#nginx master进程
lrwxrwxrwx. 1 root root 0 Dec 1214:12 cgroup -> cgroup:[4026531835]
lrwxrwxrwx. 1 root root 0 Dec 1214:12 ipc -> ipc:[4026532397]
lrwxrwxrwx. 1 root root 0 Dec 1213:59 mnt -> mnt:[4026532395]
lrwxrwxrwx. 1 root root 0 Dec 1213:59 net -> net:[4026532400]
lrwxrwxrwx. 1 root root 0 Dec 1214:12 pid -> pid:[4026532398]
lrwxrwxrwx. 1 root root 0 Dec 1214:12 pid_for_children -> pid:[4026532398]
lrwxrwxrwx. 1 root root 0 Dec 1214:12 time -> time:[4026531834]
lrwxrwxrwx. 1 root root 0 Dec 1214:12 time_for_children -> time:[4026531834]
lrwxrwxrwx. 1 root root 0 Dec 1214:12 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 Dec 1214:12 uts -> uts:[4026532396]#nginx worker进程
ll /proc/15010/ns
lrwxrwxrwx. 11011010 Dec 1214:12 cgroup -> cgroup:[4026531835]
lrwxrwxrwx. 11011010 Dec 1214:12 ipc -> ipc:[4026532397]
lrwxrwxrwx. 11011010 Dec 1214:12 mnt -> mnt:[4026532395]
lrwxrwxrwx. 11011010 Dec 1214:12 net -> net:[4026532400]
lrwxrwxrwx. 11011010 Dec 1214:12 pid -> pid:[4026532398]
lrwxrwxrwx. 11011010 Dec 1214:12 pid_for_children -> pid:[4026532398]
lrwxrwxrwx. 11011010 Dec 1214:12 time -> time:[4026531834]
lrwxrwxrwx. 11011010 Dec 1214:12 time_for_children -> time:[4026531834]
lrwxrwxrwx. 11011010 Dec 1214:12 user -> user:[4026531837]
lrwxrwxrwx. 11011010 Dec 1214:12 uts -> uts:[4026532396]
不难发现,worker和master的ns是一样的,而与docker containerd shim 进程 ns是不一样的。虽然都在宿主机中运行,但是由于ns不同,他们两个是隔离的。
同时可以在子系统下,根据对应pid查看其资源分配情况。不过docker需要手动限制,或者docker run启动的时候限制
docker run --memory 64m -p80:80 -d nginx
# 查看对应资源分配sudocat /sys/fs/cgroup/memory/docker/<container_id or container_name>/memory.limit_in_bytes
不过笔者的cgroup下却没有docker目录,这个暂时还不知道为啥。查了一下可能是Docker 配置使用了不同的 cgroup 驱动程序。所以路径也有所不同。
查看容器详细信息,在里面也没发现cgroup路径,无奈只能进容器里看了。
docker inspect b5ce5ac1e4ae
#dockerexec-it b5ce5ac1e4ae bashcat /proc/self/cgroup
13:hugetlb:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
12:cpuset:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
11:memory:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
10:freezer:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
9:blkio:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
8:devices:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
7:rdma:/
6:cpu,cpuacct:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
5:pids:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
4:misc:/
3:net_cls,net_prio:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
2:perf_event:/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
# 这里就可以看到挂载了哪些进来。 这些地方是读写层,那么可以在对应宿主机(只读层)去查看即可,或者直接在docker里查看# 退出来cd /sys/fs/cgroup/memory/system.slice/docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope
[root@localhost docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope]# ls
cgroup.clone_children memory.kmem.failcnt memory.kmem.tcp.limit_in_bytes memory.max_usage_in_bytes memory.move_charge_at_immigrate memory.stat tasks
cgroup.event_control memory.kmem.limit_in_bytes memory.kmem.tcp.max_usage_in_bytes memory.memsw.failcnt memory.numa_stat memory.swappiness
cgroup.procs memory.kmem.max_usage_in_bytes memory.kmem.tcp.usage_in_bytes memory.memsw.limit_in_bytes memory.oom_control memory.usage_in_bytes
memory.failcnt memory.kmem.slabinfo memory.kmem.usage_in_bytes memory.memsw.max_usage_in_bytes memory.pressure_level memory.use_hierarchy
memory.force_empty memory.kmem.tcp.failcnt memory.limit_in_bytes memory.memsw.usage_in_bytes memory.soft_limit_in_bytes notify_on_release
[root@localhost docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope]# cat memory.max_usage_in_bytes14090240[root@localhost docker-b5ce5ac1e4ae9b644fc8950eb8293077878a47b198c3a468738062d425fee312.scope]# cat memory.limit_in_bytes67108864
正好是64m
版权归原作者 咚伢 所有, 如有侵权,请联系我们删除。