
本文收录于专栏:算法之翼
并行哈希表的设计与实现:性能优化与分布式扩展
哈希表是一种高效的键值对存储数据结构,广泛应用于各种计算任务中。随着现代计算系统的多核处理器和并行计算能力的普及,单线程哈希表已经无法充分利用这些硬件资源。本文将深入探讨并行哈希表的设计与实现,结合代码实例,探讨如何优化并行哈希表的性能。
1. 哈希表的基本概念
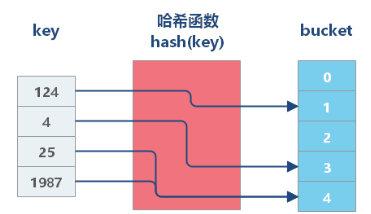
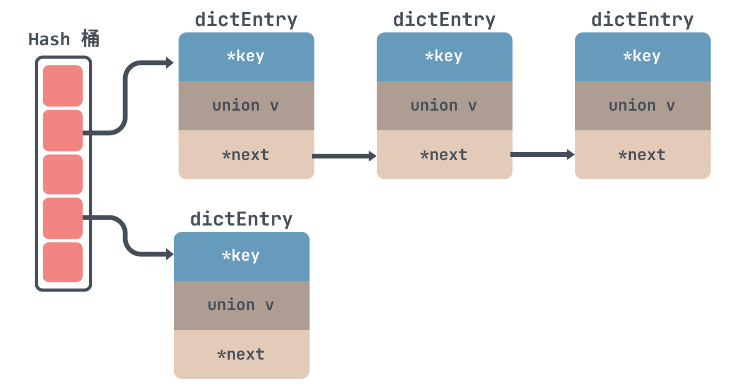
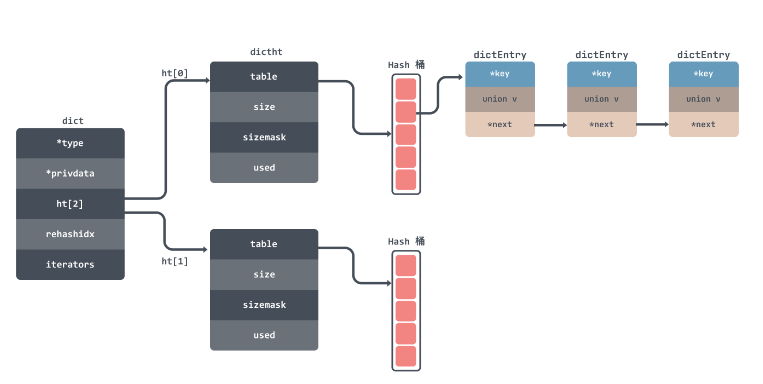
哈希表通过哈希函数将键映射到数组的索引位置,确保在常数时间复杂度下完成查找、插入和删除操作。然而,当多线程访问同一个哈希表时,可能会出现数据竞争和资源争用,导致性能瓶颈。
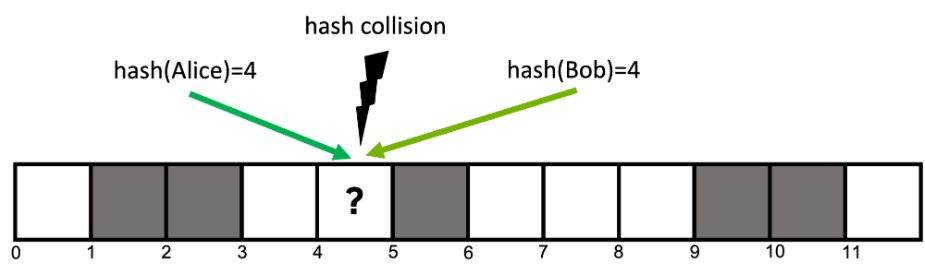
2. 并行哈希表的挑战
并行哈希表的主要挑战包括:
- 线程安全:多线程同时访问哈希表时,如何防止数据竞争。
- 负载平衡:确保各线程均衡地分担哈希表的访问任务,避免部分线程成为瓶颈。
- 缓存一致性:在多核处理器环境中,如何高效地管理缓存一致性,避免频繁的缓存失效。
3. 并行哈希表的设计策略
在设计并行哈希表时,常见的策略包括:
- **分片锁定 (Sharding)**:将哈希表分成多个独立的片,每个片由一个独立的锁保护。线程只需锁定对应片的锁,减少锁竞争。
- **无锁算法 (Lock-Free Algorithms)**:利用原子操作和CAS (Compare-And-Swap) 等技术设计无锁的数据结构,从根本上避免锁带来的开销。
- **读写锁 (Read-Write Locks)**:读操作频繁的情况下,使用读写锁可以允许多个线程同时读,提升并发性能。
4. 分片锁定的实现
以下是一个基于分片锁定的并行哈希表实现的Python示例:
import threading
classShardedHashTable:def__init__(self, num_shards=16):
self.num_shards = num_shards
self.shards =[{}for _ inrange(num_shards)]
self.locks =[threading.Lock()for _ inrange(num_shards)]def_get_shard(self, key):# 根据哈希值选择对应的片returnhash(key)% self.num_shards
definsert(self, key, value):
shard_index = self._get_shard(key)with self.locks[shard_index]:
self.shards[shard_index][key]= value
defget(self, key):
shard_index = self._get_shard(key)with self.locks[shard_index]:return self.shards[shard_index].get(key,None)defremove(self, key):
shard_index = self._get_shard(key)with self.locks[shard_index]:if key in self.shards[shard_index]:del self.shards[shard_index][key]
在这个实现中,哈希表被分成多个片 (
shards
),每个片都有一个独立的锁 (
locks
) 来保护。
_get_shard
方法根据键的哈希值选择相应的片,从而减少了锁竞争。
5. 无锁哈希表的实现
以下是一个简单的无锁并行哈希表实现示例,使用了Python的
multiprocessing
模块来演示CAS操作:
import multiprocessing
from multiprocessing import Value, Lock
classLockFreeHashTable:def__init__(self, size=1024):
self.size = size
self.table = multiprocessing.Array('l',[None]* size)def_hash(self, key):returnhash(key)% self.size
definsert(self, key, value):
index = self._hash(key)whileTrue:with self.table.get_lock():if self.table[index]isNone:
self.table[index]= value
returnelse:
index =(index +1)% self.size
defget(self, key):
index = self._hash(key)whileTrue:with self.table.get_lock():if self.table[index]== key:return self.table[index]elif self.table[index]isNone:returnNoneelse:
index =(index +1)% self.size
defremove(self, key):
index = self._hash(key)whileTrue:with self.table.get_lock():if self.table[index]== key:
self.table[index]=Nonereturnelif self.table[index]isNone:returnelse:
index =(index +1)% self.size
这个实现使用
multiprocessing.Array
来创建一个共享数组,支持多进程并发访问。
insert
方法使用线性探测来解决哈希冲突。
6. 性能分析与优化
在并行哈希表中,锁的使用会影响性能。因此,减少锁的粒度、使用无锁算法或读写锁等策略,可以有效提升性能。在实际应用中,还可以通过以下优化手段进一步提升性能:
- 减少缓存失效:使用局部性好的数据结构,避免频繁的缓存失效。
- 减少内存分配:预先分配足够的内存空间,减少内存分配的开销。
- 使用更高效的哈希函数:选择适合并行环境的哈希函数,减少冲突。
7. 并行哈希表的扩展与收缩
在实际应用中,哈希表的容量需求往往是动态变化的。当哈希表负载因子(即存储元素数量与哈希表容量的比值)过高时,哈希冲突的概率会显著增加,从而影响性能。因此,并行哈希表需要支持扩展(rehashing)和收缩(shrinking),以适应数据量的变化。
7.1. 并行扩展的挑战
哈希表扩展时,需要重新分配一个更大的底层数组,并将所有现有元素重新哈希到新数组中。这一过程需要确保线程安全性,并避免扩展过程中对外部的操作产生不一致性。
7.2. 分步扩展策略
为了避免扩展时阻塞其他操作,可以采用分步扩展(incremental rehashing)策略。在分步扩展中,扩展操作不会一次性完成,而是将重新哈希操作分解为多个小步骤,允许在扩展的同时继续处理插入和查询操作。
下面是分步扩展策略的伪代码实现:
classShardedHashTableWithResize:def__init__(self, initial_capacity=1024, num_shards=16):
self.num_shards = num_shards
self.shards =[{}for _ inrange(num_shards)]
self.locks =[threading.Lock()for _ inrange(num_shards)]
self.capacity = initial_capacity
self.resize_threshold =0.75
self.size =0def_get_shard(self, key, capacity):returnhash(key)% capacity
def_resize(self):
new_capacity = self.capacity *2
new_shards =[{}for _ inrange(self.num_shards)]with threading.Lock():# 防止多个线程同时触发_resizefor shard_index inrange(self.num_shards):
old_shard = self.shards[shard_index]for key, value in old_shard.items():
new_shard_index = self._get_shard(key, new_capacity)
new_shards[new_shard_index][key]= value
self.shards = new_shards
self.capacity = new_capacity
definsert(self, key, value):
shard_index = self._get_shard(key, self.capacity)with self.locks[shard_index]:if key notin self.shards[shard_index]:
self.size +=1
self.shards[shard_index][key]= value
if self.size / self.capacity > self.resize_threshold:
self._resize()defget(self, key):
shard_index = self._get_shard(key, self.capacity)with self.locks[shard_index]:return self.shards[shard_index].get(key,None)defremove(self, key):
shard_index = self._get_shard(key, self.capacity)with self.locks[shard_index]:if key in self.shards[shard_index]:del self.shards[shard_index][key]
self.size -=1
在这个实现中,当哈希表的负载因子超过设定的阈值时,
_resize
方法会被调用来扩展哈希表的容量。该方法在加锁的情况下对整个哈希表进行重新分片(rehash),并更新容量。
7.3. 并行收缩的实现
与扩展类似,当哈希表的负载因子过低时,可以进行收缩操作,以节省内存资源。然而,收缩操作同样需要考虑线程安全性和数据一致性。以下是并行哈希表收缩的伪代码示例:
def_shrink(self):
new_capacity = self.capacity //2
new_shards =[{}for _ inrange(self.num_shards)]with threading.Lock():# 防止多个线程同时触发_shrinkfor shard_index inrange(self.num_shards):
old_shard = self.shards[shard_index]for key, value in old_shard.items():
new_shard_index = self._get_shard(key, new_capacity)
new_shards[new_shard_index][key]= value
self.shards = new_shards
self.capacity = new_capacity
这个收缩操作与扩展类似,只是将容量减半,并重新映射现有数据。在某些高负载的应用场景中,动态收缩可以显著节省资源。
8. 并行哈希表在分布式系统中的应用
在分布式系统中,并行哈希表不仅需要应对单机环境下的并发访问,还需要处理网络延迟、数据分区、容错等问题。常见的分布式哈希表 (DHT, Distributed Hash Table) 是这种数据结构的典型应用。
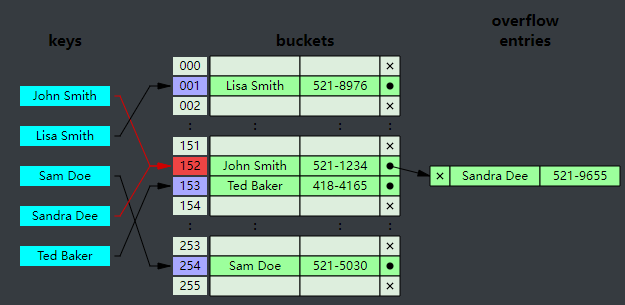
8.1. 分布式哈希表的基本原理
分布式哈希表通过将数据分布在多个节点上来实现扩展性和容错性。每个节点负责一部分哈希空间的存储和查询操作。当一个节点收到查询请求时,如果无法处理请求,它会将请求转发给负责相应哈希空间的节点。
8.2. 一致性哈希
一致性哈希 (Consistent Hashing) 是分布式哈希表中的核心技术,它解决了节点动态加入和退出时数据重新分布的问题。与传统的哈希方式不同,一致性哈希通过环形哈希空间和虚拟节点减少数据迁移量,提升系统的稳定性和可扩展性。
8.3. 分布式哈希表的实现
以下是一个简化的分布式哈希表的Python示例,展示如何在多个节点之间分布数据:
import hashlib
import bisect
from collections import defaultdict
classConsistentHashing:def__init__(self, nodes=None, replicas=3):
self.replicas = replicas
self.ring =[]
self.nodes = nodes or[]
self._ring_map ={}for node in self.nodes:
self._add_node(node)def_hash(self, key):returnint(hashlib.md5(key.encode('utf-8')).hexdigest(),16)def_add_node(self, node):for i inrange(self.replicas):
replica_key =f"{node}-{i}"
hash_key = self._hash(replica_key)
self.ring.append(hash_key)
self._ring_map[hash_key]= node
self.ring.sort()defadd_node(self, node):
self.nodes.append(node)
self._add_node(node)defremove_node(self, node):
self.nodes.remove(node)for i inrange(self.replicas):
replica_key =f"{node}-{i}"
hash_key = self._hash(replica_key)
self.ring.remove(hash_key)del self._ring_map[hash_key]defget_node(self, key):ifnot self.ring:returnNone
hash_key = self._hash(key)
index = bisect.bisect(self.ring, hash_key)%len(self.ring)return self._ring_map[self.ring[index]]# 使用示例
nodes =["NodeA","NodeB","NodeC"]
hashing = ConsistentHashing(nodes)print(hashing.get_node("my_key"))# 根据键获取负责的节点
在这个实现中,我们定义了一个一致性哈希环 (
ring
) 来存储虚拟节点的哈希值,并使用二分查找 (
bisect
) 来快速定位给定键对应的节点。这种方式使得分布式哈希表可以轻松应对节点的动态变化。
9. 并行哈希表性能测试与调优
实现并行哈希表后,下一步就是进行性能测试与调优。常见的性能指标包括吞吐量(每秒处理的请求数量)、延迟(处理单个请求的平均时间)以及扩展性(随着线程数或节点数增加,性能的变化)。
9.1. 性能测试工具
可以使用诸如
timeit
或
cProfile
等工具进行性能测试,或者使用更专业的工具如
Apache JMeter
、
locust
进行模拟负载测试。
import timeit
# 性能测试示例
hash_table = ShardedHashTableWithResize()# 插入性能测试
insert_time = timeit.timeit(lambda: hash_table.insert("key","value"), number=100000)print(f"Insert Time: {insert_time} seconds")# 查询性能测试
get_time = timeit.timeit(lambda: hash_table.get("key"), number=100000)print(f"Get Time: {get_time} seconds")
9.2. 性能调优策略
根据性能测试结果,调优策略可能包括:
- 锁的优化:尽量减少锁的粒度,或使用无锁算法。
- 内存分配优化:预分配内存减少动态扩展的次数。
- 负载均衡:调整哈
希函数或分片算法以实现更好的负载均衡。
- 数据结构选择:根据不同应用场景选择合适的数据结构,如跳表(Skip List)或树结构等。
10. 并行哈希表在大规模数据处理中的应用
在大规模数据处理和实时数据流应用中,并行哈希表发挥着至关重要的作用。其高效的数据存取和并发处理能力,使其成为诸如分布式缓存、流处理框架和实时分析系统中的核心组件。
10.1. 分布式缓存系统中的并行哈希表
在分布式缓存系统中,并行哈希表通常用于存储和管理缓存数据。由于缓存系统需要处理大量的并发请求,使用并行哈希表可以显著提升数据存取效率,同时保证数据的一致性和完整性。
例如,Memcached 和 Redis 这样的分布式缓存系统,内部使用了多线程或多进程的并行哈希表来管理内存中的键值对数据。这些系统通过分片或一致性哈希等技术,将数据分布在多个节点上,以实现水平扩展和高可用性。
10.2. 实时数据流处理中的并行哈希表
实时数据流处理系统,如 Apache Kafka 和 Apache Flink,通常需要处理来自多个数据源的高吞吐量数据流。这些系统使用并行哈希表来实时存储和更新状态信息,如计数器、窗口操作结果等。
例如,在 Apache Flink 中,状态后端(State Backend)使用了并行哈希表来管理任务状态。在分布式环境下,Flink 将任务状态分布在多个节点上,并通过快照和检查点机制来保证数据的一致性和容错性。
以下是一个基于 Apache Flink 的示例代码,展示了如何在流处理应用中使用并行哈希表来实现实时数据统计:
importorg.apache.flink.api.common.state.MapState;importorg.apache.flink.api.common.state.MapStateDescriptor;importorg.apache.flink.api.common.typeinfo.BasicTypeInfo;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.functions.KeyedProcessFunction;importorg.apache.flink.util.Collector;publicclassParallelHashTableFlinkExample{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> stream = env.socketTextStream("localhost",9999);
stream.keyBy(value -> value.split(",")[0]).process(newKeyedProcessFunction<String,String,String>(){privatetransientMapState<String,Long> countState;@Overridepublicvoidopen(Configuration parameters)throwsException{MapStateDescriptor<String,Long> descriptor =newMapStateDescriptor<>("countState",BasicTypeInfo.STRING_TYPE_INFO,BasicTypeInfo.LONG_TYPE_INFO);
countState =getRuntimeContext().getMapState(descriptor);}@OverridepublicvoidprocessElement(String value,Context ctx,Collector<String> out)throwsException{String key = value.split(",")[0];Long count = countState.get(key);if(count ==null){
count =0L;}
count +=1;
countState.put(key, count);
out.collect(key +": "+ count);}}).print();
env.execute("Parallel Hash Table in Flink");}}
在这个示例中,我们使用了 Flink 的
MapState
,它在后台通过并行哈希表来存储和管理状态。每个键值对都被分配到相应的处理线程,从而实现并行处理。
10.3. 并行哈希表在机器学习中的应用
在大规模机器学习任务中,并行哈希表被广泛应用于特征存储、参数服务器和模型分片等场景。例如,在训练大规模的深度学习模型时,需要管理和更新大量的模型参数,并行哈希表可以有效地组织这些参数,以支持分布式训练和并行计算。
以下是一个使用并行哈希表实现分布式参数服务器的简化示例:
import threading
classParameterServer:def__init__(self):
self.parameters ={}
self.lock = threading.Lock()defget(self, param_name):with self.lock:return self.parameters.get(param_name,None)defupdate(self, param_name, gradient, learning_rate):with self.lock:if param_name in self.parameters:
self.parameters[param_name]-= learning_rate * gradient
else:
self.parameters[param_name]=-learning_rate * gradient
# 使用示例
server = ParameterServer()defworker_thread(param_name, gradient):
server.update(param_name, gradient,0.01)
threads =[]for i inrange(10):
t = threading.Thread(target=worker_thread, args=("weight",0.1* i))
threads.append(t)
t.start()for t in threads:
t.join()print(server.get("weight"))
在这个示例中,
ParameterServer
使用并行哈希表来存储和更新模型参数。多个线程可以并发地更新参数,参数服务器通过加锁机制确保数据一致性。
11. 并行哈希表的未来发展方向
随着硬件技术的进步和数据规模的不断扩大,并行哈希表也在不断演进。未来的发展方向可能包括:
11.1. 硬件加速的并行哈希表
现代硬件,如多核处理器、GPU、FPGA 和专用加速器,提供了巨大的并行计算能力。未来的并行哈希表可能会更多地利用这些硬件资源,通过 SIMD 指令集、硬件事务内存和定制逻辑来加速哈希操作。
例如,使用 GPU 实现并行哈希表,可以显著提高高并发环境下的插入和查询性能。GPU 的并行计算模型非常适合处理大量独立的哈希操作。
11.2. 无锁并行哈希表
无锁数据结构(Lock-Free Data Structures)在高并发环境下表现优异,因为它们避免了线程阻塞和死锁问题。未来的并行哈希表可能会更多地采用无锁或乐观并发控制技术,如 Compare-And-Swap (CAS) 操作,以提高并发性能。
无锁并行哈希表的一个挑战是设计高效的内存管理和冲突检测机制。现有的一些研究成果,如无锁哈希表和无锁跳表,为未来的发展提供了理论基础和实践经验。
11.3. 分布式环境中的容错与一致性
在分布式环境中,并行哈希表需要处理节点故障、网络分区等问题。未来的研究可能会更深入地探讨如何在保证数据一致性的同时提高系统的可用性和容错性。
例如,基于 Paxos 或 Raft 协议的分布式哈希表可以在确保一致性的同时实现高可用性。通过使用副本和快照技术,系统可以快速恢复,并在网络分区或节点故障时保持一致性。
11.4. 自动调优的并行哈希表
随着并行哈希表应用场景的多样化,如何自动调优以适应不同的负载特征和硬件配置,成为一个重要的研究方向。未来的并行哈希表可能会集成机器学习模型,根据运行时数据动态调整参数,如哈希函数、负载因子和扩展策略。
这种自动调优机制可以显著提高哈希表在不同场景下的性能,同时简化开发和运维工作。
总结
本文深入探讨了并行哈希表的设计与实现,结合了多线程编程、锁机制、扩展性、动态调整等关键技术,展示了并行哈希表在大规模数据处理、分布式缓存系统、实时数据流处理、机器学习等领域的广泛应用。通过代码示例,详细说明了如何在实际项目中实现和优化并行哈希表,特别是在处理高并发、数据一致性和扩展性方面的挑战。
文章还展望了并行哈希表的未来发展方向,包括硬件加速、无锁数据结构、分布式环境中的容错与一致性,以及自动调优机制。随着硬件技术和编程技术的不断进步,并行哈希表将继续在高性能计算和大规模数据处理领域发挥重要作用。
版权归原作者 一键难忘 所有, 如有侵权,请联系我们删除。