
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
也许过去十年在计算机视觉和机器学习方面的突破是GANs(生成式对抗网络)的发明——这种方法引入了超越数据中已经存在的内容的可能性,是一个全新领域的敲门砖,现在称为生成式建模。然而,在经历了一个蓬勃发展的阶段后,GANs开始面临平台期,其中大多数方法都在努力解决对抗性方法面临的一些瓶颈。这不是单个方法的问题,而是问题本身的对抗性。GANs的一些主要瓶颈是:
- 图像生成缺乏多样性
- 模式崩溃
- 多模态分布问题学习
- 训练时间过长
- 由于问题表述的对抗性,不容易训练
还有另一系列基于似然的方法(例如,马尔可夫随机场),它已经存在了相当长的一段时间,但由于对每个问题的实现和制定都很复杂,因此未能获得重大影响。其中一种方法是“扩散模型”——一种从气体扩散的物理过程中获得灵感的方法,并试图在多个科学领域对同一现象进行建模。然而,在图像生成领域,它们的应用最近变得越来越明显。主要是因为我们现在有更多的计算能力来测试复杂的算法,这些算法在过去是不可实现的。
一个标准扩散模型有两个主要的过程域:正向扩散和反向扩散。在前向扩散阶段,图像被逐渐引入的噪声污染,直到图像成为完全随机噪声。在反向过程中,利用一系列马尔可夫链在每个时间步逐步去除预测噪声,从而从高斯噪声中恢复数据。

扩散模型最近在图像生成任务中表现出了显著的性能,并在图像合成等任务上取代了GANs的性能。这些模型还能够产生更多样化的图像,并被证明不会受到模式崩溃的影响。这是由于扩散模型保留数据语义结构的能力。然而,这些模型的计算要求很高,训练需要非常大的内存,这使得大多数研究人员甚至无法尝试这种方法。这是因为所有的马尔可夫状态都需要一直在内存中进行预测,这意味着大型深度网络的多个实例一直在内存中。此外,这些方法的训练时间也变得太高(例如,几天到几个月),因为这些模型往往陷入图像数据中细粒度的、难以察觉的复杂性。然而,需要注意的是,这种细粒度图像生成也是扩散模型的主要优势之一,因此,使用它们是一种矛盾。
另一个来自NLP领域的非常著名的方法系列是transformer。他们在语言建模和构建对话AI工具方面非常成功。在视觉应用中,transformer表现出泛化和自适应的优势,使其适合通用学习。它们比其他技术更好地捕捉文本甚至图像中的语义结构。然而,与其他方法相比,transformer需要大量的数据,并且在许多视觉领域也面临着性能方面的平台。
潜在扩散模型
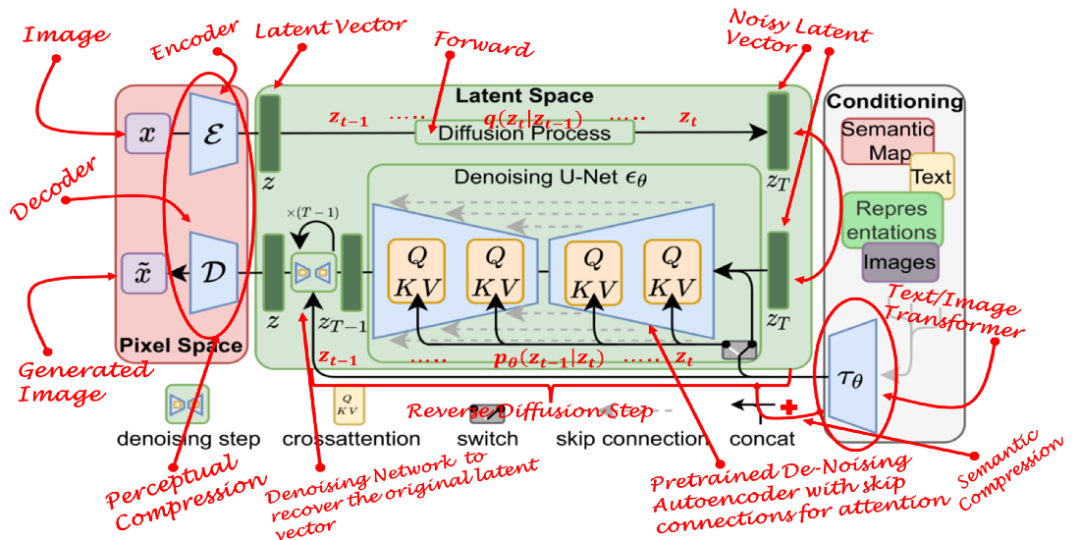
一种最近提出的方法,利用GANs的感知能力、扩散模型的细节保持能力和transformer的语义能力,将三者合并在一起。该技术被作者称为“潜在扩散模型”(LDM)。LDM已经证明自己比前面提到的所有模型都更健壮和高效。与其他方法相比,它们不仅节省了内存,还产生了多样化的、高度详细的图像,保留了数据的语义结构。简而言之,LDM是潜空间而不是像素空间中扩散过程的应用,同时结合了来自transformer的语义反馈。
任何生成式学习方法都有两个主要阶段:感知压缩和语义压缩。
**压缩感知 **
在感知压缩学习阶段,学习方法必须通过去除高频细节将数据封装为抽象表示。这一步对于构建环境的不变和鲁棒表示是必要的。GANs擅长提供这种感知压缩。他们通过将高维冗余数据从像素空间投影到称为潜空间的超空间来实现这一点。隐空间中的隐向量是原始像素图像的压缩形式,可以有效地代替原始图像。
更具体地说,自动编码器(AE)结构是捕获感知压缩的结构。AE中的编码器将高维数据投影到潜空间,解码器从潜空间恢复图像。
**语义压缩 **
在学习的第二个阶段,图像生成方法必须能够捕捉数据中存在的语义结构。这种概念和语义结构保存了图像中各种物体的上下文和相互关系。transformer擅长捕捉文本和图像中的语义结构。transformer的泛化能力和扩散模型的细节保持能力的结合提供了两个世界的优点,并提供了一种生成细粒度的高度详细图像的能力,同时保留图像中的语义结构。
**感知损失 **
LDM中的自动编码器通过将数据投影到潜空间来捕捉数据的感知结构。作者使用一种特殊的损失函数来训练这种自编码器,称为“感知损失”。该损失函数确保重建被限制在图像流形内,并减少使用像素空间损失(例如L1/L2损失)时可能出现的模糊。
**扩散损失 **
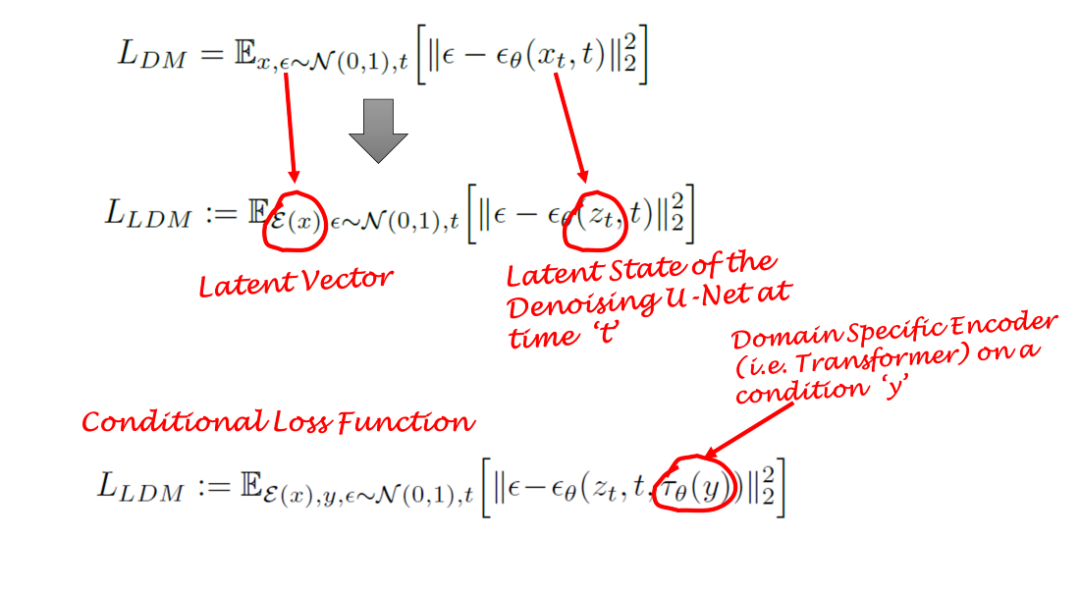
扩散模型通过逐步去除正态分布变量中的噪声来学习数据分布。换句话说,DMs采用长度为T的反向马尔可夫链。这也意味着DMs可以建模为时间步长T =1,…,T的一系列T去噪自编码器。这由下式中的εθ表示。请注意,损失函数依赖于隐向量而不是像素空间。
**条件扩散 **
扩散模型是一种依赖先验的条件模型。在图像生成任务中,先验通常是文本、图像或语义图。为了获得这种情况的潜在表示,使用了一个transformer(例如CLIP),它将文本/图像嵌入到潜在向量τ中。因此,最终的损失函数不仅取决于原始图像的潜空间,而且还取决于条件的潜嵌入。
**注意机制 **
LDM的骨干是U-Net自编码器,具有稀疏连接,提供交叉注意力机制[6]。Transformer网络将条件文本/图像编码为潜在嵌入,然后通过交叉注意力层映射到U-Net的中间层。这个交叉注意力层实现了注意力(Q,K,V) = softmax(QKT/✔)V,而Q,K和V是可学习的投影矩阵。
**文本到图像合成 **
我们使用python中LDM v4的最新官方实现来生成图像。在文本到图像合成中,LDM使用预训练的CLIP模型[7],该模型为文本和图像等多种模态提供了基于transformer的通用嵌入。然后,transformer模型的输出被输入到LDM的python API diffusers。有一些参数也是可以调整的(例如,没有。扩散步骤、种子、图像大小等)。扩散损失

图像到图像合成
同样的设置也适用于图像到图像的合成但是,需要输入样本图像作为参考图像。生成的图像在语义和视觉上与作为参考的图像相似。这个过程在概念上类似于基于风格的GAN模型,然而,它在保留图像的语义结构方面做得更好。

结论
我们已经介绍了图像生成领域的最新发展,称为潜扩散模型。ldm在以精细细节生成不同背景的高分辨率图像方面是鲁棒的,同时还保留了图像的语义结构。因此,LDM是图像生成特别是深度学习方面的一个进步。如果您仍然想知道“稳定扩散模型”,那么这只是应用于高分辨率图像的LDM的重新命名,同时使用CLIP作为文本编码器。
GitHub链接:https://github.com/azad-academy/stable-diffusion-model-tutorial
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
版权归原作者 小白学视觉 所有, 如有侵权,请联系我们删除。