
yolov5-7.0训练自己的VOC数据集
这个笔记可能只适用于7.0版本的,写这个笔记主要是给工作室伙伴参考的,大佬请绕行
有错误之处欢迎指出
一、下载
yolov5的GitHub仓库地址:Release v7.0 - YOLOv5 SOTA Realtime Instance Segmentation · ultralytics/yolov5 (github.com)
需要下载源码和预训练模型
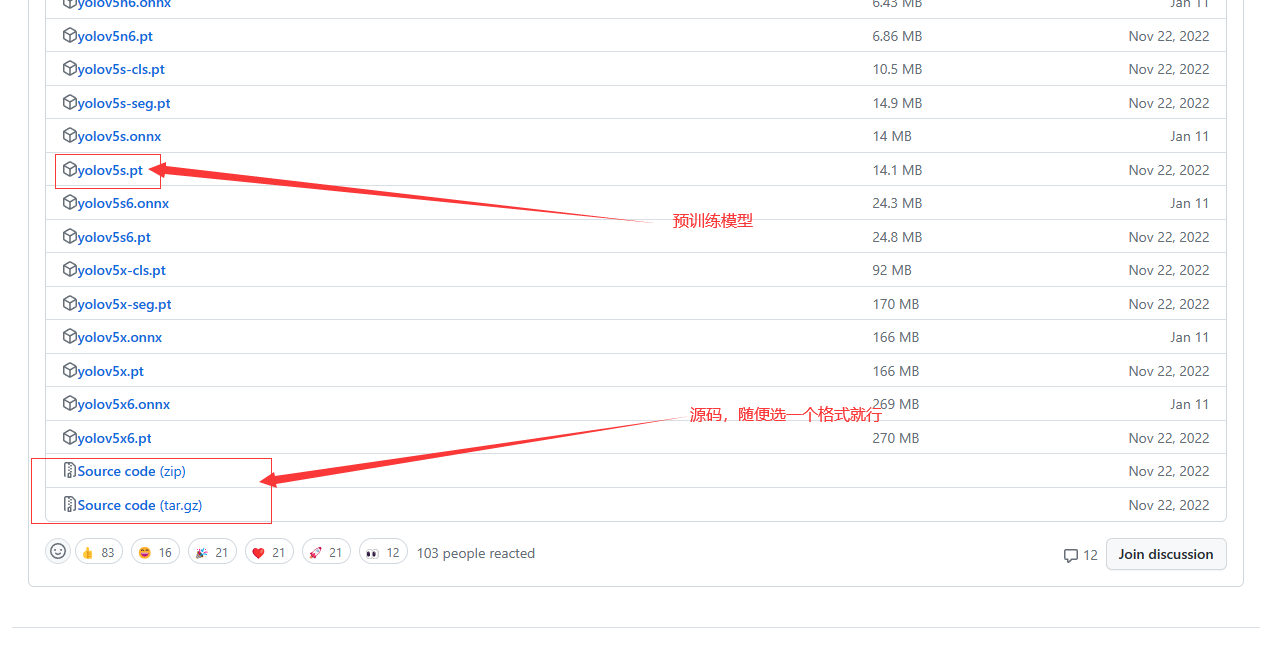
将源码解压,在其文件夹里面新建一个weights文件夹,把下载的预训练模型放入
二、配置yolov5训练环境
在yolov5的文件夹下进入终端环境,或者在终端下进入yolov5的目录

或者
1.使用anaconda创建虚拟环境
创建环境指令:
conda create -n yolov5 python=3.8

该指令在创建一个名为yolov5的虚拟环境的同时在该环境里面预装python3.8
创建完成会有如下输出
激活并进入创建的yolov5环境
指令:
conda activate yolov5
成功进入环境之后在路径前面会显示环境名称

2.在创建的环境里面安装cuda工具包(cudatoolkit)和cudnn
安装指令:
conda install cudatoolkit=11.3 cudnn
该指令在当前环境安装11.3版本的cuda工具包和最新版本的cudnn
也可以使用:
conda install cudatoolkit=10.2 cudnn=7.6.5
安装10.2的cuda工具包,和7.6.5的cudnn

安装完成之后会显示
3.在环境里面配置yolov5所需的python库
安装指令:
pip install -r requirements.txt
使用清华源镜像安装指令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
安装完成会有如下显示

4.测试环境
此测试主要为了测试环境里面安装的torch能否启动gpu进行训练
在终端里面进入python环境
测试指令:
import torch
torch.cuda.is_available()
依次输入,若返回结果为
True
则说明环境gpu可用,反之则不然
像下面这种则不行
重新安装pytorch
卸载指令:
pip uninstall torch
进入pytorch官网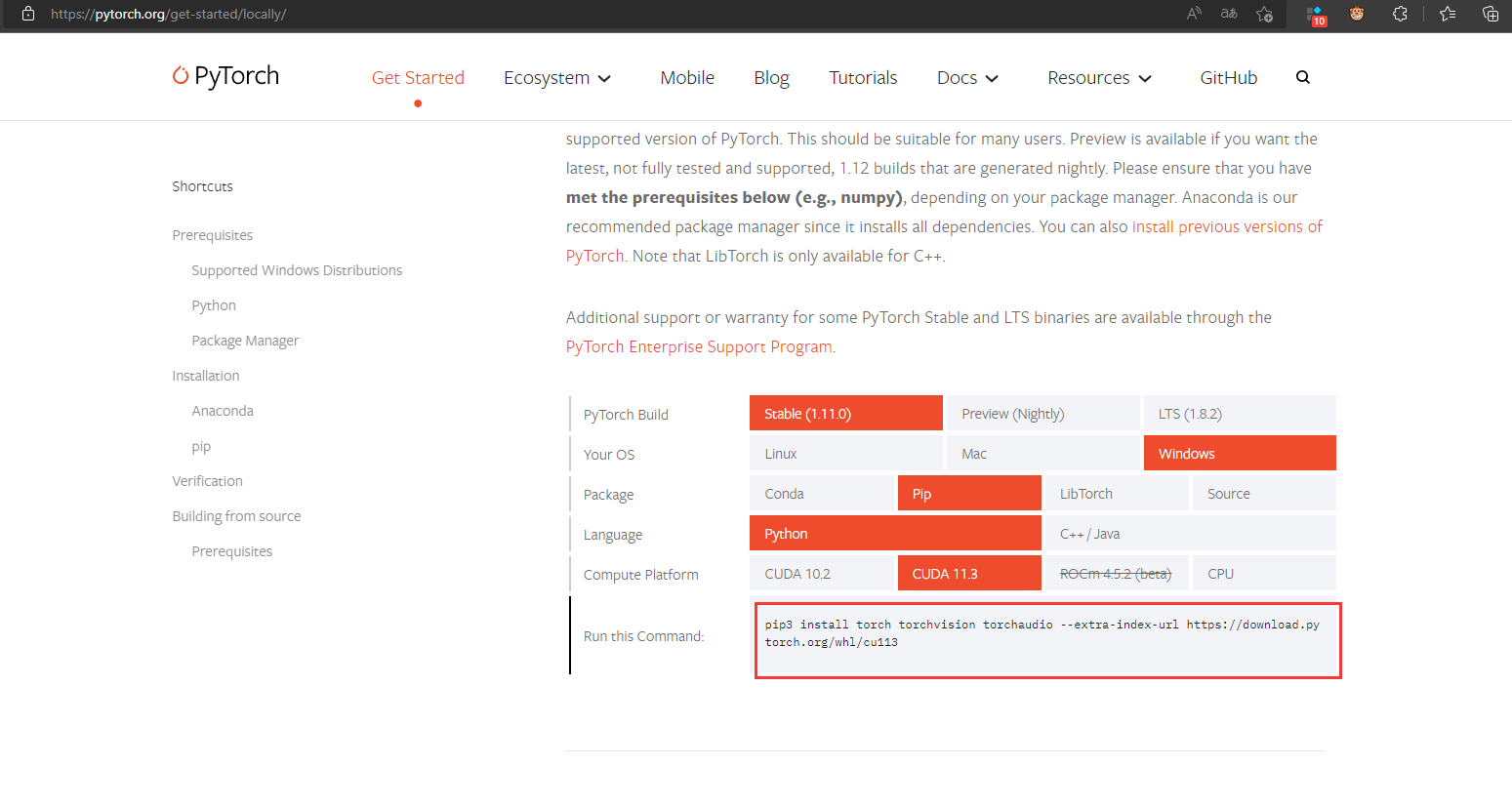
按照自己的环境配置选择,并复制下方指令,在其后面加入清华源链接安装
安装完成之后再次测试,结果如下即可

到此,环境配置完成
三、准备数据集
1.数据集格式
此教程使用voc数据集进行训练,下面以VOC2007为例
VOC2007
|—— Annotations #存放.xml标签文件,与图片一一对应
| |——000001.xml
| |——000002.xml
| |——……
|—— JPEGImages #存放.jpg图片文件
| |——000001.jpg
| |——000002.jpg
| |——……
|—— ImageSets #存放训练索引文件,txt文件里面每行对应一张图片名称
| |——Main
| | |——train.txt
| | |——val.txt
| | |——trainval.txt
| | |——test.txt
| | |——text.txt
图片标记建议使用labelimg(请自行百度搜索使用方法)
2.数据集划分
ImageSets/Main里面的数据集划分可以使用下面代码
创建一个python文件,将下面代码复制过去
# 划分VOC数据集import os
import random
datasets_path =r'D:\test_file\VOCdevkit\VOC2007/'# 数据集路径
trainval_percent =0.8
train_percent =0.7
xml_path = datasets_path +'Annotations'
txtsavepath = datasets_path +'ImageSets/Main'
total_xml = os.listdir(xml_path)
num =len(total_xml)
list1 =range(num)
tmtp =int(num * trainval_percent)
trp =int(tmtp * train_percent)
trainval = random.sample(list1, tmtp)
train = random.sample(trainval, trp)withopen(datasets_path +'ImageSets/Main/trainval.txt','w')as ftrainval, \
open(datasets_path +'ImageSets/Main/test.txt','w')as ftest, \
open(datasets_path +'ImageSets/Main/train.txt','w')as ftrain, \
open(datasets_path +'ImageSets/Main/val.txt','w')as fval:for i in list1:
name = total_xml[i][:-4]+'\n'if i in trainval:
ftrainval.write(name)if i in train:
ftrain.write(name)else:
fval.write(name)else:
ftest.write(name)
将准备好的数据集存放于yolov5目录下的data里面,如下
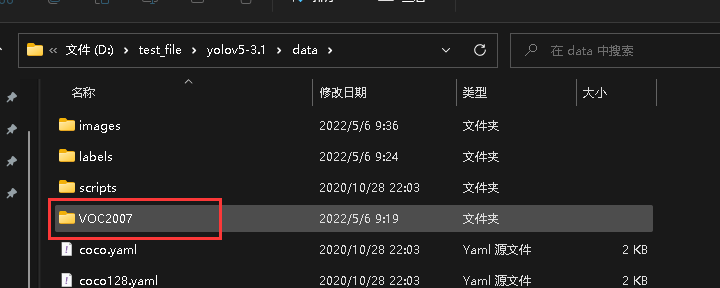
3.创建yolov5的训练数据
在yolov5/data下创建一个新文件,用于生成label以及复制文件
import xml.etree.ElementTree as ET
from tqdm import tqdm
from utils.general import Path
def convert_label(path, lb_path, year, image_id):
def convert_box(size, box):
dw, dh = 1. / size[0], 1. / size[1]
x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
return x * dw, y * dh, w * dw, h * dh
in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
out_file = open(lb_path, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
names = ['besom', 'heikuai', 'heiqiu', 'leaf', 'plastic', 'stone', 'branch', 'brokenshell', 'cereal', 'chip',
'guazi', 'heizhi', 'paper', 'seed', 'straw', 'bamboo', 'Besom', 'hagberry', 'hair',
'SayakaShell'] # 所有数据集类别
for obj in root.iter('object'):
cls = obj.find('name').text
if cls in names and int(obj.find('difficult').text) != 1:
xmlbox = obj.find('bndbox')
bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
cls_id = names.index(cls) # class id
out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
# Download
dir = Path('D:\\study_documents\\test_file\\test\\yolov5-master\\data') # 数据集路径,这里需要写到VOC数据集的上一级路径
# Convert
path = dir / ''
for year, image_set in ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
imgs_path = dir / 'images' / f'{image_set}{year}'
lbs_path = dir / 'labels' / f'{image_set}{year}'
imgs_path.mkdir(exist_ok=True, parents=True)
lbs_path.mkdir(exist_ok=True, parents=True)
with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
image_ids = f.read().strip().split()
for id in tqdm(image_ids, desc=f'{image_set}{year}'):
f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
f.rename(imgs_path / f.name) # move image
convert_label(path, lb_path, year, id) # convert labels to YOLO format
这个代码可以使用data/VOC.yaml里面的数据集划分代码
4.修改配置文件
1.修改data/voc.yaml
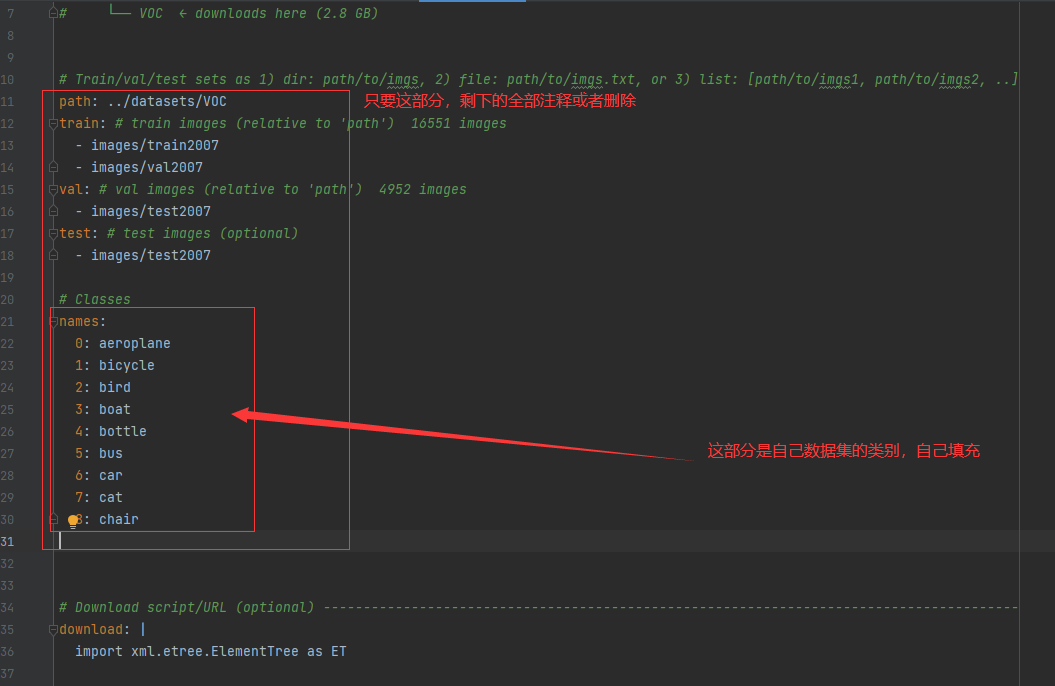
2.修改models/yolov5s.yaml
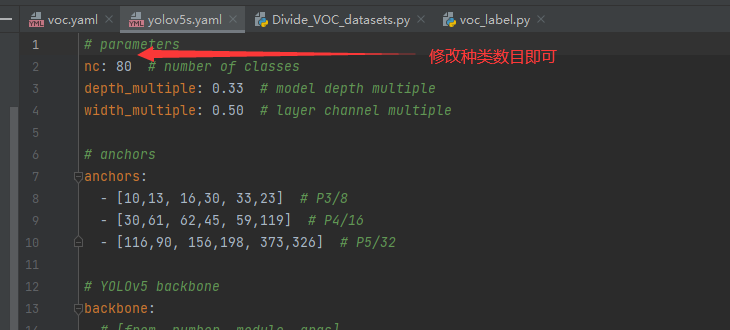
3.修改train.py
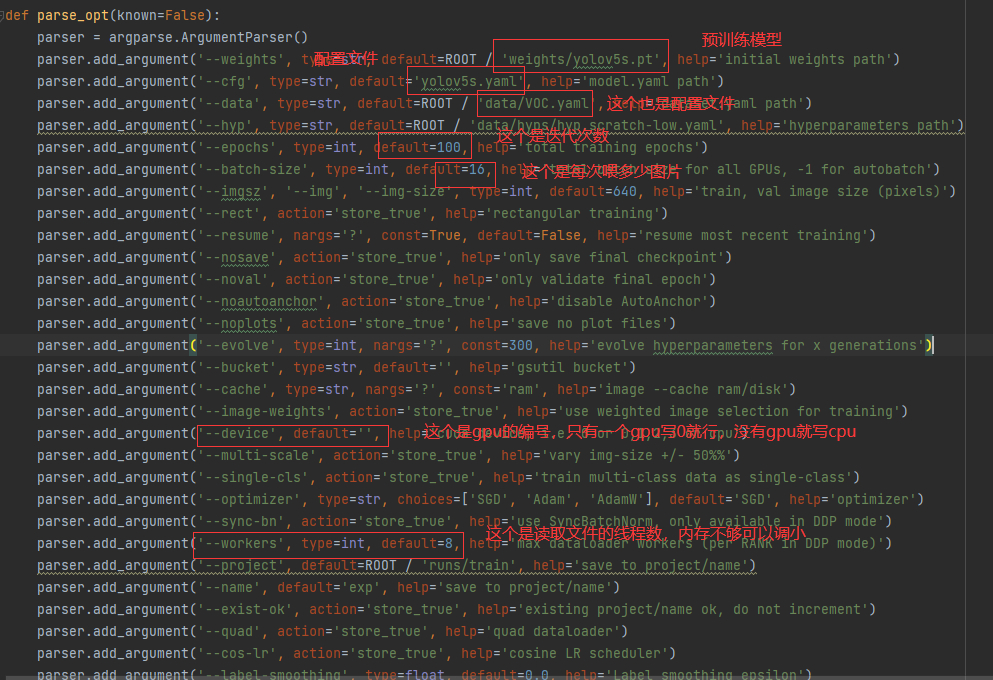
主要是上面标红的几个,按照自己修改的配置即可
四、训练与检测
1.开始训练
按照以上修改之后可以直接运行train.py
2.检测
修改detect.py
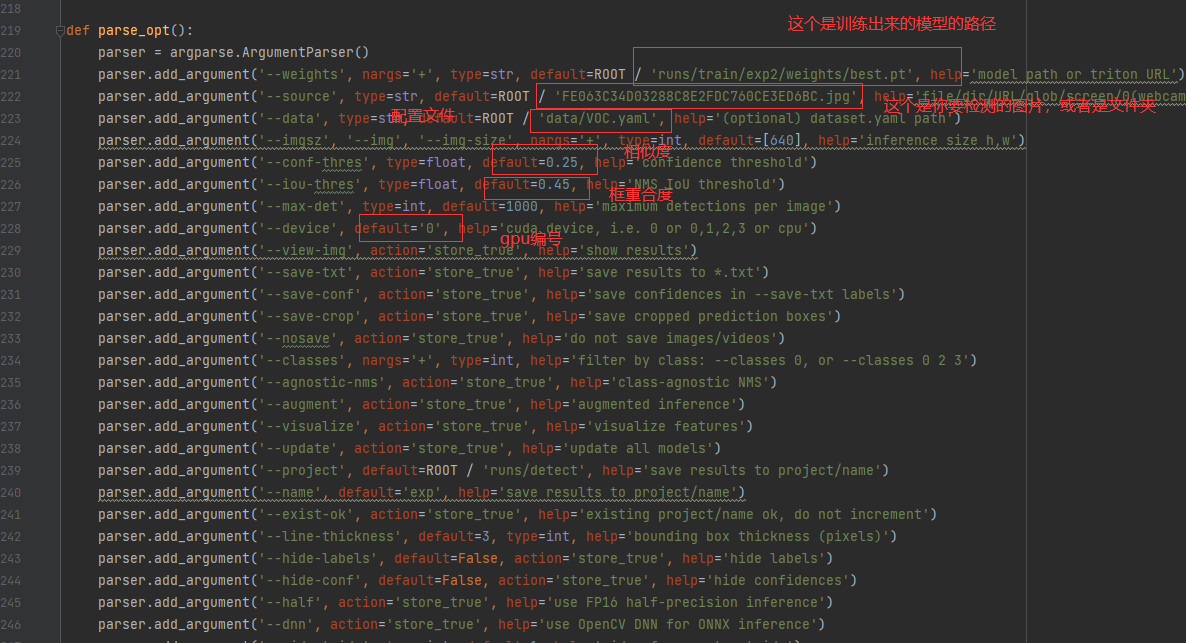
修改自己参数运行即可
版权归原作者 买醉的古岚 所有, 如有侵权,请联系我们删除。