
系列文章目录
Zookeeper安装教程
前言
这是我的学习笔记,以便后面翻阅。
一、Zookeeper简介
ZooKeeper是一个分布式的、开放源码的分布式应用程序协调服务,它是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
ZooKeeper的目标是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。它以Fast Paxos算法为基础,通过选举产生一个领导者(leader),只有领导者才能提交提议,从而解决了Paxos算法存在的问题。
ZooKeeper为分布式应用提供了一致性服务,其功能包括配置维护、域名服务、分布式同步、组服务等。它还提供了分布式独享锁、选举、队列的接口,其中分布锁和队列有Java和C两个版本,选举只有Java版本
二、Zookeeper的数据结构
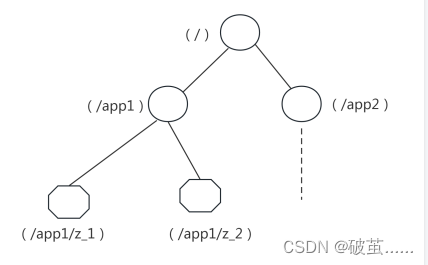
zookeeper 提供的名称空间类似于标准文件系统,key-value 的形式存储。名称 key 由斜线 / 分割的一系列路径元素,zookeeper 名称空间中的每个节点都是由一个路径标识。
三、CPA理论
CAP 理论指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency):在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性,等同于所有节点访问同一份最新的数据副本。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
- 可用性(Availability):每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。
- 分区容错性(Partition tolerance):分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
一个分布式系统最多只能同时满足一致性、可用性和分区容错性这三项中的两项。但是P 是必须的,因此只能在 CP 和 AP 中选择,zookeeper 保证的是 CP,对比 spring cloud 系统中的注册中心 eruka 实现的是 AP。
四、BASE 理论
BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- 基本可用(Basically Available):在分布式系统出现故障,允许损失部分可用性(服务降级、页面降级)。
- 软状态(Soft-state):允许分布式系统出现中间状态。而且中间状态不影响系统的可用性。这里的中间状态是指不同的 data replication(数据备份节点)之间的数据更新可以出现延时的最终一致性。
- 最终一致性(Eventually Consistent):它关注的是系统中所有的数据副本(data replications)在经过一段时间的同步后,最终能够达到一个一致的状态。这种策略强调的是系统的可用性和可靠性,即使在存在网络延迟或节点故障等异常情况下,也能保证系统的正常运行和数据的正确性。这种策略强调的是系统的可用性和可靠性,即使在存在网络延迟或节点故障等异常情况下,也能保证系统的正常运行和数据的正确性。最终一致性的实现通常采用一些延迟或异步的处理方式,例如使用消息队列、事件驱动架构等,将数据的变更异步地通知到其他副本,从而实现数据的最终一致性。这种策略的优点是能够提高系统的可用性和扩展性,但需要谨慎处理数据一致性和系统复杂性的平衡问题。在实际应用中,最终一致性常用于一些对实时性要求不高的场景,例如日志分析、缓存系统等。在这些场景中,最终一致性可以提供较好的性能和扩展性,同时保证数据的正确性和一致性。
五、ZooKeeper的特性
- 顺序一致性:从一个客户端发起的事务请求,最终都会严格按照其发起顺序被应用到ZooKeeper中。
- 原子性:所有事务请求的处理结果在整个集群中所有机器上都是一致的,不存在部分机器应用了该事务,而另一部分没有应用的情况。
- 单一视图:所有客户端看到的服务端数据模型都是一致的。
- 可靠性:一旦服务端成功应用了一个事务,则其引起的改变会一直保留,直到被另外一个事务所更改。
- 实时性:一旦一个事务被成功应用后,ZooKeeper可以保证客户端立即可以读取到这个事务变更后的最新状态的数据。
此外ZooKeeper还具有简单的数据模型、构建集群和顺序访问等功能和特性。
本文转载自: https://blog.csdn.net/qq_18402475/article/details/135675268
版权归原作者 破茧...... 所有, 如有侵权,请联系我们删除。
版权归原作者 破茧...... 所有, 如有侵权,请联系我们删除。