
文章目录
一. 中文文本分析相关库
1. 中文分词jieba库
(1). jieba库概述
jieba是优秀的中文分词第三方库
(2). jieba库安装
(3). jieba分词原理
jieba分词利用中文词库
(4). jieba库的使用说明
jieba分词的三种模式
1. 精确模式
把文本精确的切分开,不存在冗余单词
2. 全模式
把文本中所有可能词语都扫描出来,有冗余
3. 搜索引擎模式
在精确模式的基础上,对长词再次切分
(5). jieba库常用函数


2. 词云绘制worldcloud库
(1). worldcloud库概述

(2). worldcloud库安装

(3). worldcloud库使用说明
wordcloud库把词云当作一个WordCloud对象
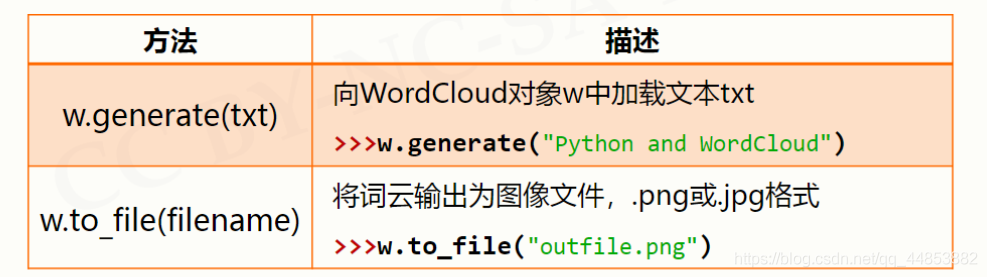
(4). wordcloud库常规方法

1. 举例:
import wordcloud
# 步骤一:配置对象参数
c = wordcloud.WordCloud()# 步骤二:加载词云文本
c.generate("wordcloud by Python")# 步骤三:输出词云文件
c.to_file("pywordcloud.png")

2. 分析:

(5). 配置对象参数




1. 举例1
import wordcloud
txt ="life is short,you need python"
w = wordcloud.WordCloud(background_color="white")
w.generate(txt)
w.to_file("pywordcloud1.png")

2. 实例2
import jieba
import wordcloud
txt = "程序设计语言是计算机能够理解和识别用户\
操作意图的一种交互体系,它按照特定规则组织计算机指令,\
使计算机能够自动进行各种运算处理"
w = wordcloud.WordCloud(width=1000,font_path="msyh.ttc",height=700)
w.generate(" ".join(jieba.lcut(txt)))
w.to_file("pywordcloud2.png")

(6). 政府工作报告词云

#GovRptWordCloudv1.pyimport jieba
import wordcloud
f =open("新时代中国特色社会主义.txt","r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt =" ".join(ls)
w = wordcloud.WordCloud( \
width =1000, height =700,\
background_color ="white",
font_path ="msyh.ttc")
w.generate(txt)
w.to_file("grwordcloud.png")

#GovRptWordCloudv2.pyimport jieba
import wordcloud
from imageio import imread
mask = imread("fivestar.png")#excludes = { }
f =open("新时代中国特色社会主义.txt","r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt =" ".join(ls)
w = wordcloud.WordCloud(\
width =1000, height =700,\
background_color ="white",
font_path ="msyh.ttc", mask = mask
)
w.generate(txt)
w.to_file("grwordcloudm.png")

3. 社交关系网络networkx库
二. 文本词频统计
1. 文本词频统计问题分析
需求:一篇文章,出现了哪些词?哪些词出现的最多?
做法:先判断文章是英文的还是中文的
2. 文本词频统计实例

3. hamlet英文词频统计实例
#CalHamletV1.pydefgetText():
txt =open("hamlet.txt","r").read()
txt = txt.lower()for ch in'!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch," ")#将文本中特殊字符替换为空格return txt
hamletTxt = getText()
words = hamletTxt.split()
counts ={}for word in words:
counts[word]= counts.get(word,0)+1#判断获取的词是否在字典中,默认为0
items =list(counts.items())#转换为列表类型
items.sort(key=lambda x:x[1], reverse=True)#进行按照键值对的2个元素的第二个元素进行排序for i inrange(10):
word, count = items[i]print("{0:<10}{1:>5}".format(word, count))
结果:
the 1138and965
to 754
of 669
you 550
i 542
a 542
my 514
hamlet 462in436
4. 三国演义人物出场统计实例
(1). 代码一
#CalThreeKingdomsV1.pyimport jieba
txt =open("threekingdoms.txt","r", encoding='utf-8').read()
words = jieba.lcut(txt)#分词处理,形参列表
counts ={}#构造字典for word in words:iflen(word)==1:continueelse:
counts[word]= counts.get(word,0)+1
items =list(counts.items())#转换为列表类型
items.sort(key=lambda x:x[1], reverse=True)for i inrange(15):
word, count = items[i]print("{0:<10}{1:>5}".format(word, count))
结果:
曹操 953
孔明 836
将军 772
却说 656
玄德 585
关公 510
丞相 491
二人 469
不可 440
荆州 425
玄德曰 390
孔明曰 390
不能 384
如此 378
张飞 358
(2). 代码二升级版
#CalThreeKingdomsV2.pyimport jieba
excludes ={"将军","却说","荆州","二人","不可","不能","如此"}#将确定不是人名的取出掉
txt =open("threekingdoms.txt","r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts ={}for word in words:iflen(word)==1:continueelif word =="诸葛亮"or word =="孔明曰":#进行人名关联
rword ="孔明"elif word =="关公"or word =="云长":
rword ="关羽"elif word =="玄德"or word =="玄德曰":
rword ="刘备"elif word =="孟德"or word =="丞相":
rword ="曹操"else:
rword = word
counts[rword]= counts.get(rword,0)+1for word in excludes:del counts[word]
items =list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)for i inrange(10):
word, count = items[i]print("{0:<10}{1:>5}".format(word, count))
结果:
曹操 1451
孔明 1383
刘备 1252
关羽 784
张飞 358
商议 344
如何 338
主公 331
军士 317
吕布 300
标签:
python
本文转载自: https://blog.csdn.net/qq_44853882/article/details/111086610
版权归原作者 巧克力code 所有, 如有侵权,请联系我们删除。
版权归原作者 巧克力code 所有, 如有侵权,请联系我们删除。