
📖 前言: Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook开发团队想设计一种使用SQL语言对日志数据查询分析的工具,而Hive就诞生于此,只要懂SQL语言,就能够胜任大数据分析方面的工作,还节省了开发人员的学习成本。

目录
🕒 1. 数据仓库简介
🕘 1.1 什么是数据仓库
数据仓库是一个面向主题的、集成的、随时间变化的,但信息本身相对稳定的数据集合,它用于支持企业或组织的决策分析处理。
🕘 1.2 数据仓库的结构
数据仓库的结构是由数据源、数据存储及管理、OLAP服务器和前端工具四个部分组成。
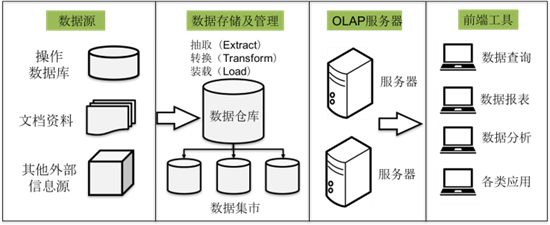
- 数据源:数据源是数据仓库的基础,即系统的数据来源,通常包含企业的各种内部信息和外部信息。
- 数据存储及管理:数据存储及管理是整个数据仓库的核心,数据仓库的组织管理方式决定了对外部数据的表现形式,针对系统现有的数据,进行抽取、转换和装载,按照主题进行组织数据。
- OLAP服务器:OLAP服务器对需要分析的数据按照多维数据模型进行重组,以支持用户随时进行多角度、多层次的分析,并发现数据规律和趋势。
- 前端工具:前端工具主要包含各种数据分析工具、报表工具、查询工具、数据挖掘工具以及各种基于数据仓库或数据集市开发的应用。
🕘 1.3 数据仓库的数据模型
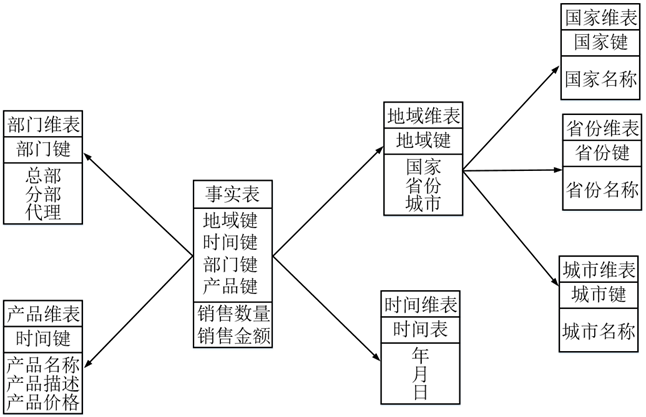
数据模型(Data Model)是数据特征的抽象,在数据仓库建设中,一般围绕星型模型和雪花模型来设计数据模型。
星型模型是以一个事实表和一组维度表组合而成,并以事实表为中心,所有维度表直接与事实表相连。
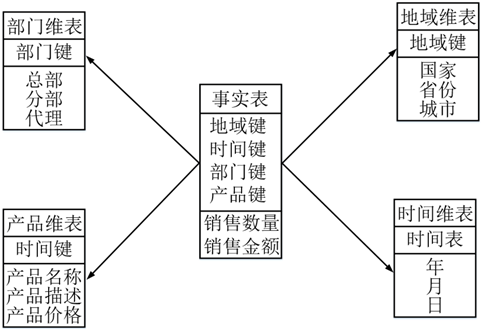
雪花模型是当有一个或多个维表没有直接连到事实表上,而是通过其他维表连到事实表上,其图解像多个雪花连在一起,故称雪花模型。雪花模型是对星型模型的扩展,原有的各维表可被扩展为小的事实表,形成一些局部的 "层次 " 区域,被分解的表都连主维度表而不是事实表。
🕒 2. Hive简介
🕘 2.1 什么是Hive
Hive是建立在Hadoop文件系统上的数据仓库,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的工具。Hive定义简单的类SQL查询语言(即HQL),可以将结构化的数据文件映射为一张数据表,允许熟悉SQL的用户查询数据,允许熟悉MapReduce的开发者开发mapper和reducer来处理复杂的分析工作,与MapReduce相比较,Hive更具有优势。
Hive采用了SQL的查询语言
HQL
,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处,MySQL与Hive对比如下所示。
对比项HiveMySQL查询语言Hive QLSQL数据存储位置HDFS块设备、本地文件系统数据格式用户定义系统决定数据更新不支持支持事务不支持支持执行延迟高低可扩展性高低数据规模大小
🕘 2.2 Hive系统架构
Hive是底层封装了Hadoop的数据仓库处理工具,运行在Hadoop基础上,其系统架构组成主要包含4部分,分别是用户接口、跨语言服务、底层驱动引擎及元数据存储系统。
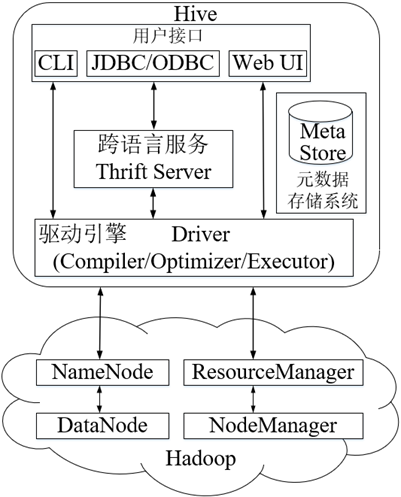
🕘 2.3 Hive工作原理
Hive建立在Hadoop系统之上,因此Hive底层工作依赖于Hadoop服务,Hive底层工作原理如下所示。
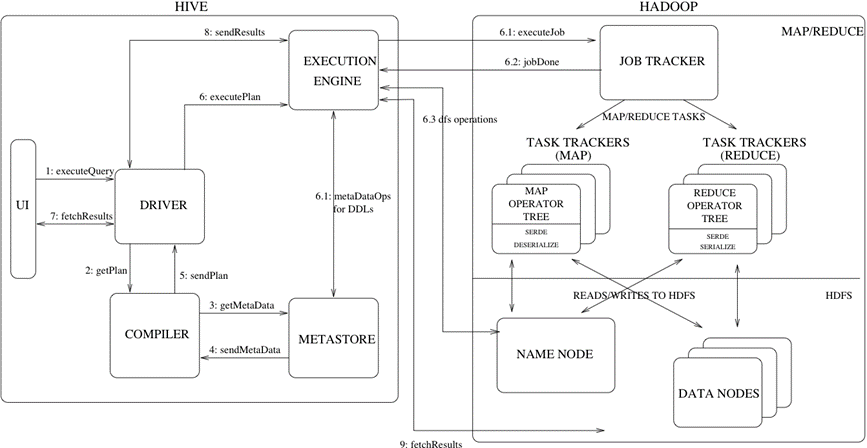
(1) CLI将用户提交的HiveQL语句发送给DRIVER。
(2) DRIVER将HiveQL语句发送给COMPILER获取执行计划。
(3) COMPILER从METASTORE获取HiveQL语句所需的元数据。
(4) METASTORE将查询到的元数据信息发送给COMPILER。
(5) COMPILER得到元数据后,首先将HiveQL语句转换为抽象语法树,然后将抽象语法树转换为查询块,接着将查询块转换为逻辑执行计划,最后将逻辑执行计划转换为物理执行计划,并将物理执行计划解析为MapReduce任务发送给DRIVER。
(6) DRIVER将MapReduce任务发送给EXECUTION ENGINE(执行引擎)执行。
(7) CLI向DRIVER发送获取HiveQL语句执行结果的请求。
(8) DRIVER与EXECUTION ENGINE进行通信,请求获取HiveQL语句执行结果的请求。
(9) EXECUTION ENGINE向NameNode发送请求获取HiveQL语句执行结果的请求。
🕘 2.4 Hive数据模型
Hive中所有的数据都存储在HDFS中,它包含数据库(Database)、表(Table)、分区表(Partition)和桶表(Bucket)四种数据类型。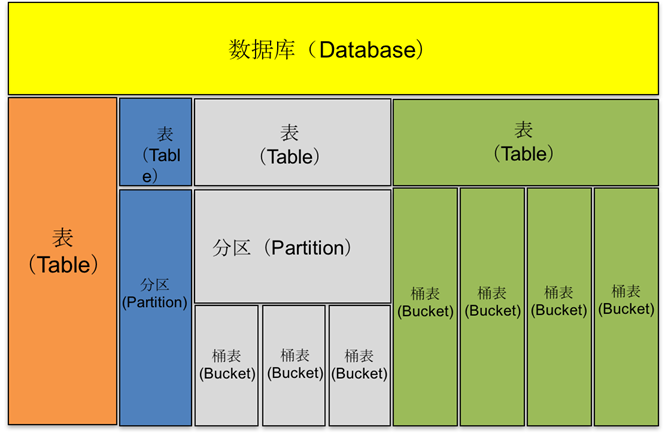
- 数据库:数据库用于存储与同一业务相关的一组表,可以有效隔离不同业务的表。
- 表:表是数据库中用来存储数据的对象,对象以二维表格的形式组织数据。Hive中的表分为内部表和外部表这两种类型。
- 分区:根据分区规则将表的整体数据划分为多个独立的数据进行存储,每个独立的数据看做是一个分区,每个分区存储在HDFS文件系统的不同目录中。
- 桶:根据指定分桶规则将表的数据随机、均匀的划分到不同的桶进行存储,每个桶存储在HDFS文件系统的不同文件中。
🕒 3. Hive环境搭建
🕘 3.1 Hive的安装
Hive的安装模式分为三种,分别是嵌入模式、本地模式和远程模式。
- 嵌入模式 使用内嵌Derby数据库存储元数据,这是Hive的默认安装方式,配置简单,但是一次只能连接一个客户端,适合用来测试,不适合生产环境。
- 本地模式 采用外部数据库存储元数据,该模式不需要单独开启Metastore服务,因为本地模式使用的是和Hive在同一个进程中的Metastore服务。
- 远程模式 与本地模式一样,远程模式也是采用外部数据库存储元数据。不同的是,远程模式需要单独开启Metastore服务,然后每个客户端都在配置文件中配置连接该Metastore服务。远程模式中,Metastore服务和Hive运行在不同的进程中。
本文采用本地模式配置:
1、下载并解压Hive安装包
🔎 Hive下载官网
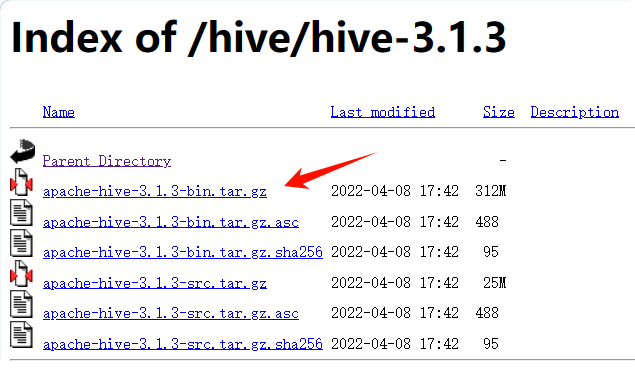
sudotar-zxvf ./apache-hive-3.1.3-bin.tar.gz -C /usr/local # 解压到/usr/local中cd /usr/local/
sudomv apache-hive-3.1.3-bin hive # 将文件夹名改为hivesudochown-R hadoop:hadoop hive # 修改文件权限
2、配置环境变量
vim ~/.bashrc
在该文件最前面一行添加如下内容:
exportHIVE_HOME=/usr/local/hive
exportPATH=$PATH:$HIVE_HOME/bin
exportHADOOP_HOME=/usr/local/hadoop
HADOOP_HOME需要被配置成你机器上Hadoop的安装路径,比如这里是安装在/usr/local/hadoop目录。
保存退出后,运行如下命令使配置立即生效:
source ~/.bashrc
3、修改/usr/local/hive/conf下的hive-site.xml
执行如下命令:
cd /usr/local/hive/conf
mv hive-default.xml.template hive-default.xml
然后,使用vim编辑器新建一个配置文件hive-site.xml,命令如下:
cd /usr/local/hive/conf
vim hive-site.xml
在hive-site.xml中添加如下配置信息:
<?xml version="1.0"encoding="UTF-8"standalone="no"?><?xml-stylesheet type="text/xsl"href="configuration.xsl"?><configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true</value><description>JDBC connect string for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>hive</value><description>username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>hive</value><description>password to use against metastore database</description></property></configuration>
🕘 3.2 安装并配置mysql
这里我们采用MySQL数据库保存Hive的元数据,而不是采用Hive自带的derby来存储元数据。
使用以下命令即可进行mysql安装,注意安装前先更新一下软件源以获得最新版本:
sudoapt-get update #更新软件源sudoapt-getinstall mysql-server #安装mysql
上述命令会安装以下包:
libaio1 libcgi-fast-perl libcgi-pm-perl libevent-core-2.1-7
libevent-pthreads-2.1-7 libfcgi-bin libfcgi-perl libfcgi0ldbl
libhtml-template-perl libmecab2 libprotobuf-lite23 mecab-ipadic
mecab-ipadic-utf8 mecab-utils mysql-client-8.0
mysql-client-core-8.0 mysql-common mysql-server mysql-server-8.0
mysql-server-core-8.0
因此无需再安装mysql-client等。安装过程会提示设置mysql root用户的密码,设置完成后等待自动安装即可。默认安装完成就启动了mysql。
启动服务器:
service mysql start
确认是否启动成功,mysql节点处于LISTEN状态表示启动成功:
sudonetstat-tap|grep mysql

进入mysql shell界面:
mysql -u root -p
注:在新版Ubuntu下安装 MySQL8.0 之后没有提示输入初始密码从而导致无法进入mysql root账户,解决方案如下:
执行下面命令,查看user和password
sudocat /etc/mysql/debian.cnf
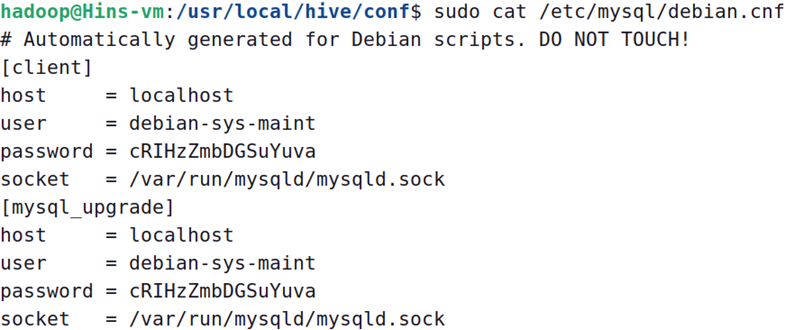
执行下面命令,登录MySQL
mysql -u debian-sys-maint -p
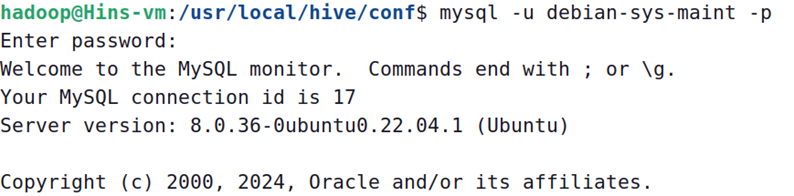
执行下面SQL命令
use mysql;ALTERUSER'root'@'localhost' IDENTIFIED WITH mysql_native_password BY'1111';
quit;
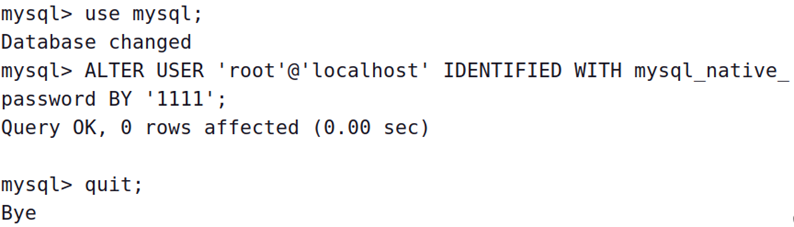
之后重启MySQL,以root登录,密码就是我们之前设的,这里是1111
sudoservice mysql restart
mysql -u root -p
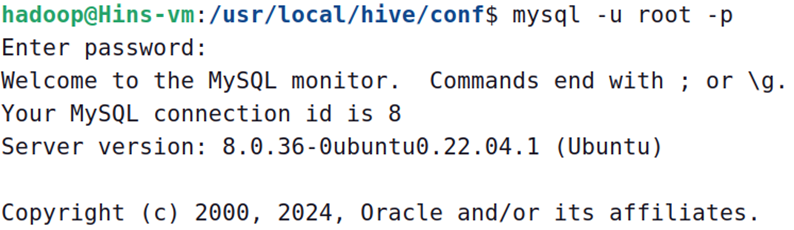
成功以root身份进入mysql shell界面。
检查一个MySQL的编码设置(一般没问题, 是utf8就正常,utf8mb4是utf8的超集)
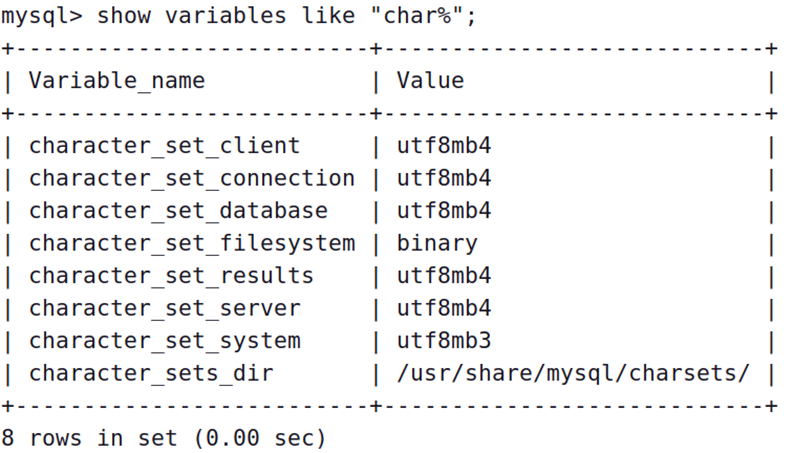
退出和关闭mysql服务器:
mysql> quit;
service mysql stop
🕘 3.3 配置MySQL JDBC
下载MySQL JDBC连接驱动JAR包
🔎 JDBC官网
sudotar-zxvf mysql-connector-j-8.3.0.tar.gz #解压cp mysql-connector-j-8.3.0/mysql-connector-j-8.3.0.jar /usr/local/hive/lib
# 将mysql-connector-j-8.3.0.jar拷贝到/usr/local/hive/lib目录下
启动并登陆MySQL Shell:
service mysql start
mysql -u root -p
🕘 3.4 配置Hive
新建hive数据库:
mysql>createdatabase hive;# 这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,两者名称必须一致,用来保存hive元数据
配置MySQL允许Hive接入:
# 创建hive用户
mysql>createuser'hive'@'localhost' identified by'hive';# 将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
mysql>grantallprivilegeson*.*to'hive'@'localhost';
mysql> flush privileges;# 刷新mysql系统权限关系表
升级元数据:
使用Hive自带的schematool工具升级元数据,也就是把最新的元数据重新写入MySQL数据库中。
可以在终端中执行如下命令
cd /usr/local/hive
./bin/schematool -initSchema-dbType mysql

🕘 3.5 启动Hive
启动hive之前,请先启动hadoop集群
start-dfs.sh # 启动Hadoop的HDFS
hive # 启动Hive
注意,如果没有配置PATH,需加上路径才能运行命令,比如,本文Hadoop安装目录是“/usr/local/hadoop”,Hive的安装目录是“/usr/local/hive”,因此,启动hadoop和hive,要使用下面带路径的方式:
cd /usr/local/hadoop #进入Hadoop安装目录
./sbin/start-dfs.sh
cd /usr/local/hive
./bin/hive
启动进入Hive的交互式执行环境以后,会出现如下命令提示符:
hive>
此时如遇到下图提示: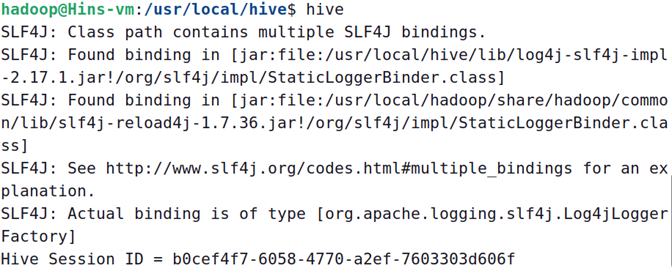
是报jar包冲突,进入hive的lib包下,删除log4j-slf4j-impl-2.17.1.jar即可。
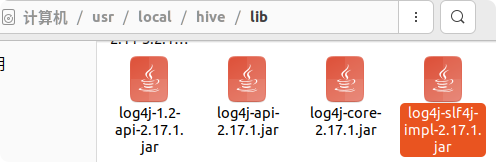
可以在里面输入SQL语句,如果要退出Hive交互式执行环境,可以输入如下命令:
hive>exit;
🕒 4. Hive的常用HiveQL操作
🕘 4.1 Hive基本数据类型
Hive支持基本数据类型和复杂类型,基本数据类型主要有数值类型(INT、FLOAT、DOUBLE) 、布尔型和字符串,复杂类型有三种:ARRAY、MAP 和 STRUCT。
🕘 4.2 常用的HiveQL操作命令
Hive常用的HiveQL操作命令主要包括:数据定义、数据操作。
更多关于HiveQL的使用指南可查看林子雨老师的博客
🔎 Hive3.1.3安装和使用指南
🕒 5. 课后习题
一、填空题
1、Hive建表时设置分割字符命令__________
2、Hive查询语句select ceil(2.34)输出内容是______。
3、Hive创建桶表关键字_____,且Hive默认分桶数量是_______。
二、判断题
1、Hive使用length()函数可以求出输出的数量。
2、再创建外部表的同时要加载数据文件,数据文件会移动到数据仓库指定的目录下。
3、Hive是一款独立的数据仓库工具,因此在启动前无需启动任何服务。
4、Hive默认不支持动态分区功能,需要手动设置动态分区参数开启功能。
5、Hive分区字段不能与已存在字段重复,且分区字段是一个虚拟的字段,它不存放任何数据,该数据来源于装载分区表时所指定的数据文。
三、选择题
1、Hive是建立在()之上的一个数据仓库
A、HDFS
B、MapReduce
C、Hadoop
D、HBase
2、Hive查询语言和SQL的一个不同之处在于()操作
A、Group by
B、Join
C、Partition
D、Union
3、Hive最重视的性能是可测量性、延展性、()和对于输入格式的宽松匹配性
A、较低恢复性
B、容错性
C、快速查询
D、可处理大量数据
4、以下选项中,哪种类型间的转换是被Hive查询语言所支持的()
A、Double—Number
B、BigInt—Double
C、Int—BigInt
D、String–Double
5、按粒度大小的顺序,Hive数据被分为:数据库、数据表、()、桶?
A、元祖
B、栏
C、分区
D、行
四、简答题
1、简述Hive的特点是什么。
2、简述Hive中内部表与外部表区别。
五、编程题
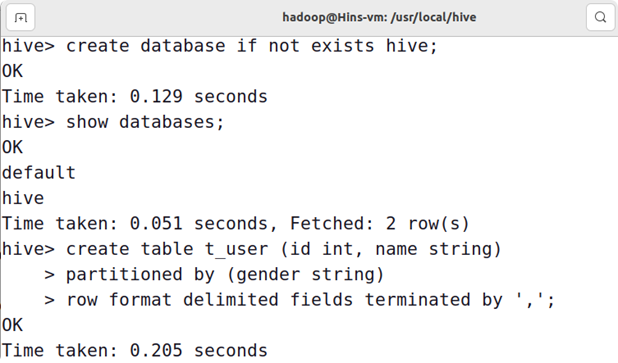
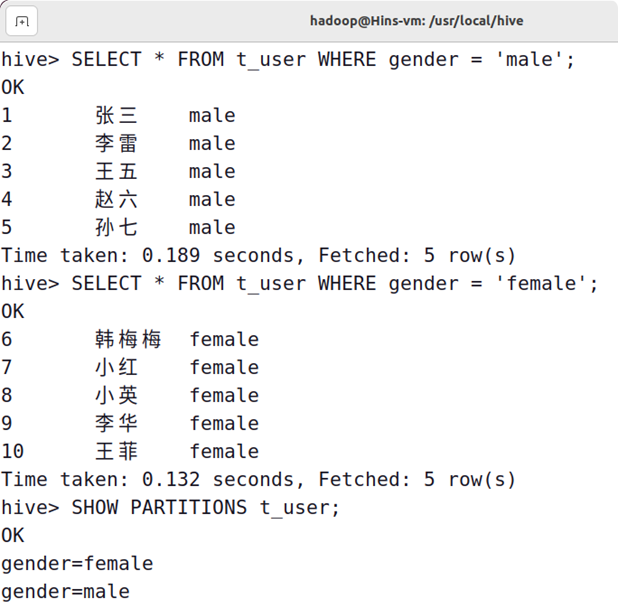
1、创建字段为id、name的用户表,并且以性别gender为分区字段的分区表。
解答:
一、填空题
1、row format delimited fields terminated by char
2、3
3、clustered by、-1
二、判断题(AI解析)
- 错误。Hive中的
length()函数用于计算字符串的长度,而不是输出的数量。 - 错误。在创建外部表时加载数据文件,数据文件不会移动到数据仓库指定的目录下,而是保留在原来的位置。
- 错误。虽然Hive是一款数据仓库工具,但在启动Hive之前需要启动Hadoop服务,因为Hive运行在Hadoop之上。
- 正确。Hive默认不支持动态分区,需要通过设置参数
hive.exec.dynamic.partition和hive.exec.dynamic.partition.mode来开启动态分区功能。 - 正确。Hive分区字段不能与已存在的字段重复,且分区字段是一个虚拟的字段,它不存放任何数据,该数据来源于装载分区表时所指定的数据值。
三、选择题
1、C 2、C 3、B 4、D 5、C
四、简答题
1、Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
2、创建表阶段:
外部表创建表的时候,不会移动数到数据仓库目录中(/user/hive/warehouse),只会记录表数据存放的路径,内部表会把数据复制或剪切到表的目录下。
删除表阶段:
外部表在删除表的时候只会删除表的元数据信息不会删除表数据,内部表删除时会将元数据信息和表数据同时删除。
五、编程题
createtable t_user (id int, name string)
partitioned by(gender string)row format delimited fieldsterminatedby',';
OK,以上就是本期知识点“Hive数据仓库”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟📌~
💫如果有错误❌,欢迎批评指正呀👀让我们一起相互进步🚀
🎉如果觉得收获满满,可以点点赞👍支持一下哟
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页
版权归原作者 HinsCoder 所有, 如有侵权,请联系我们删除。