

👑作者主页:@安 度 因
🏠学习社区:StackFrame
📖专栏链接:Linux
文章目录
如果无聊的话,就来逛逛 我的博客栈 吧! 🌹
一、前言
小伙伴们,新年好!距离上次创作已经过去半个月了,
a
n
d
u
i
n
anduin
anduin 最近也去学习了一些新知识,但是目前还在整理笔记,所以估计得等到三月份才能逐渐写出博客来。
但是
a
n
d
u
i
n
anduin
anduin 也不能闲着,于是今天我就为大家带来一篇干货文章。本篇文章对于冯诺依曼体系结构作出了详细讲解,特别是对于内存、数据流动;另一部分则是
a
n
d
u
i
n
anduin
anduin 对于操作系统的一些理解,对于其中的管理我也做出了剖析,相信看完一定会有所收获。
话不多说,让我们赶快开始学习吧!
二、冯诺依曼体系结构
1、体系简述
学习过计算机组成原理的小伙伴们应该对冯诺依曼体系结构并不陌生。冯诺依曼体系结构是一种将程序指令存储器和数据存储器合并在一起的存储器结构。
我们常见的计算机,如笔记本,或是不常见的服务器,基本都遵守冯诺依曼体系。
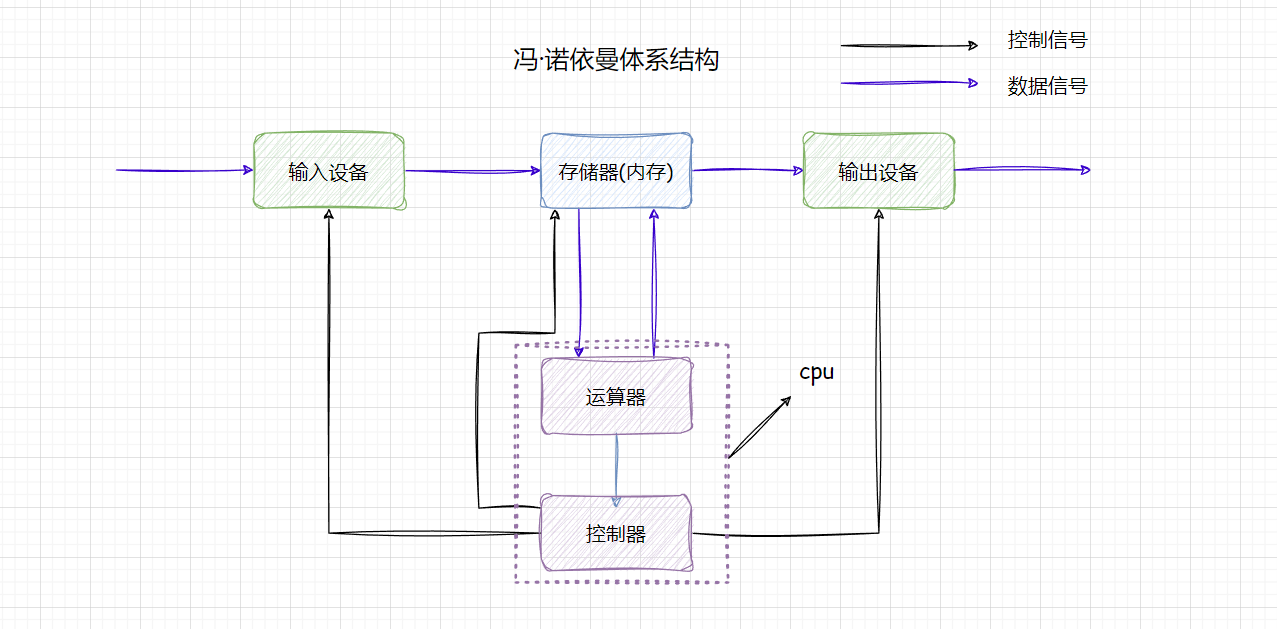
目前的计算机,单靠计算机本身是无法完成交互工作的,所以需要 人将数据“喂”计算机 ,说白了就是 输入设备 ;同样的 计算机也需要把处理数据的结果呈现给用户 ,说白了就是 输出设备 。
而这一过程中依赖的两个设备就是体系结构中的输入输出设备,两种常见的设备如下:
- 输入设备:键盘、话筒、摄像头、网卡、磁盘、鼠标…
- 输出设备:显示器、磁盘、网卡、声卡、音箱…
对于同一个设备而言,可以同时充当输入设备和输出设备,例如 磁盘 :
磁盘上的文件就是用户保存的文件。用户保存就说明 采集了用户的数据 ,再将文件进行运行,如:计算机计算、加密等… ,这一过程就是 输入 。
同样的,用户在磁盘上下载了一个文件,例如一部电影,那么磁盘上的文件需要被用户观看,这就相当于把 结果呈现给用户 ,这一过程为 输出 。
而对于结构中的 存储器、运算器、控制器 我们也需要拎一下概念:
- 存储器不是磁盘,而是 内存
- 计算机的本质工作是计算,所以一定需要运算器和控制器,它们被合称为
cpu
输入、输出设备被称为外围设备,即外设 :
外设包含输入输出,所以外设一般都会比较慢,比如磁盘。而内存则在磁盘的基准上高了许多量级。
但是外设比较便宜,比如买电脑时,电脑磁盘动不动
512g, 1t,但是内存只有
8, 16g。
对于它们两个都可以存储数据,但是对于内存存储数据是有时效性的。内存属于掉电易失介质 ,若突然关机,内存数据就会丢失;但是对于磁盘则不会。
但是内存储存数据的时效性短,为什么价格还是比外设贵?因为一个字,快 。
2、内存的重要性
可能大家会有疑惑,计算机中内存并不是最快的,**
cpu
速度是最快的** ,那么既然这样,为什么要有内存呢?**直接舍弃内存,让输入设备直接连到
cpu
不行吗?比如这样**:
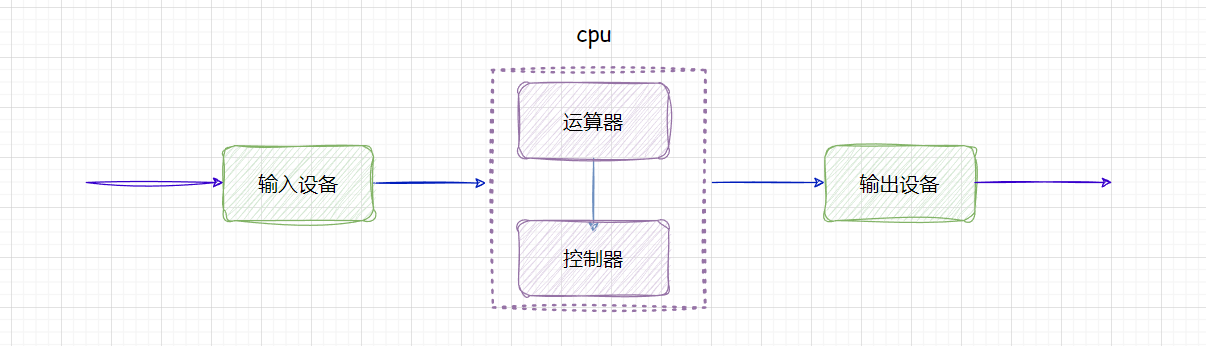
我让输入设备通过
cpu
计算后,直接输出,这样岂不是更快?
方案确实可以,但是会有代价。 因为外设是极其慢的,而
cpu
太快了。
这就涉及到一个理论 —— 木桶原理 :

木桶原理:一只木桶盛水的多少,并不取决于木桶壁上最高的那块木板,而是取决于最短的那块。
对于体系结构来说也是这样。**如果对应的输入很慢,但是
cpu
很快,整体表现出来的整体效率就以外设为主。**
所以这时,冯诺依曼大神就引入了 内存 。内存比外设快的多,但是比
cpu
慢。
举个例子,外设可以理解为毫秒级,内存是微秒级,cpu 是纳秒级。这中间的差距都很大,但是可以互补。
内存可以临时存储数据,并且不慢。而在
cpu
计算数据的同时,DMA又可以把外设的数据搬到内存,等
cpu
把数据执行完毕后,再直接执行刚刚搬进来的数据。
因为内存的存在,就可以大大缓解木桶原理带来的效率下降。
**所以这里得出一个结论:在数据层面,一般
cpu
不和外设直接沟通,而是直接和内存打交道,由此看出内存的重要性。**
那么有没有可以代替内存的存储设备?
通过上面的了解,我们发现内存是没有制造数据的能力的,它就像一个驿站,用来中转数据。但是既然是一个中转站的功能,如果谈到速度和功能,cpu 中还有个 寄存器 ,它的速度是极快的,那么 为什么不拿寄存器作为存储单元来缓解木桶效应?
一个字:贵 ,寄存器在 cpu 中只有极小部分。我们当前的计算机实际上是通过技术手段打造的一个性价比产品,因为一些存储设备太贵了。所以就用内存来平衡内设和 cpu 之间的速度不均衡。从而达到既能完成工作,并且效率均衡且便宜的特点。
3、硬件方案解释软件行为
说到这儿,我们其实可以理解之前一些难以解答的问题:
为什么一个程序必须要选加载到内存才能执行?
我们自己写的 c 代码,生成的可执行程序就是一个文件,是文件就在磁盘中保存,而磁盘属于外设。
而当可执行程序运行时,需要 cpu 帮忙执行,而现在的计算机符合冯诺依曼体系结构,所以 cpu 访问你的代码和数据时就必须问内存要,所以数据需要被加载到内存,以便让 cpu 读取数据!
而程序加载到内存在 windows 上是双击,在 linux 上则是 ./ 运行。
而这一切的一切就是因为体系结构,这就是用 硬件方案解释软件行为 。
4、体系结构中的数据流动
学习了冯诺依曼体系结构,我们再来谈谈数据之间的流向。
假设你和你的朋友在聊天,当你向你朋友发送 “吃了吗” 信息时,数据时在体系结构中如何流动的?
假设你和你的朋友的点电脑都符合冯诺依曼体系结构,且不考虑中间网络层的传输,假定发送出去就能被接收:
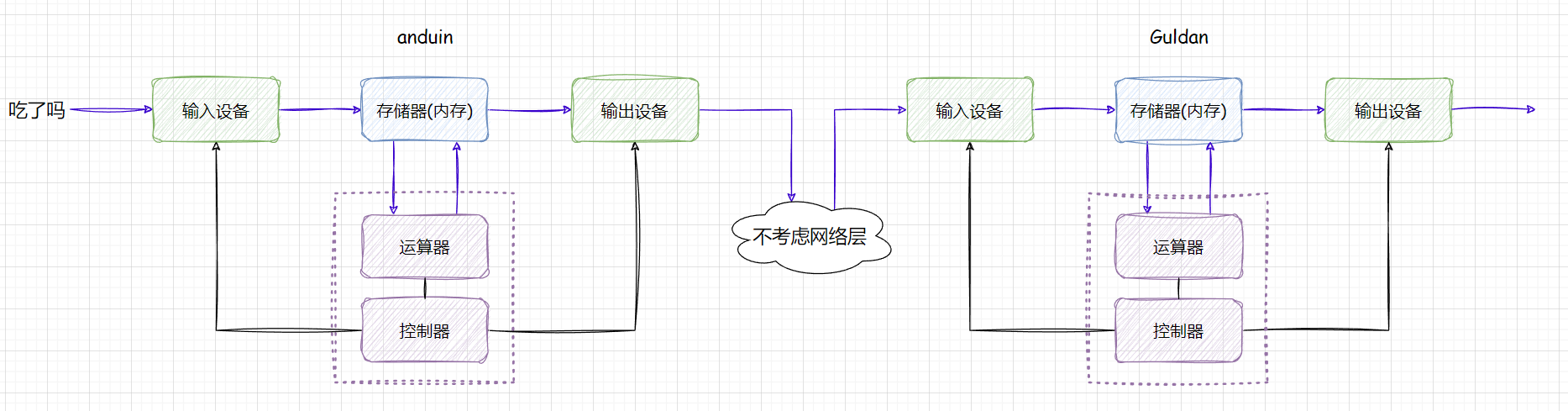
对于
a
n
d
u
i
n
anduin
anduin 也就是我,我通过输入设备(键盘)输入“吃了吗”,从硬件层面上数据被输入到内存,软件层面上数据被输入到 qq 。
这里我们 只考虑硬件层面 ,当数据输入后,数据被加载到内存这时数据就要进行计算(例如加密),这时 cpu 就需要从内存中拿数据,再计算完毕之后,将数据返回内存,数据再被显示到输出设备。
而这里有 两个刷新动作 ,一个是数据当被发送时,显示在自己电脑的显示框,这种很简单。
而 **第二个刷新动作就是把数据刷新到
G
u
l
d
a
n
Guldan
Guldan 的电脑上** ,这其中的流动规则如下:
当
a
n
d
u
i
n
anduin
anduin 的数据输出后,输出到输出设备(网卡)上,网卡再刷新到网络。
G
u
l
d
a
n
Guldan
Guldan 通过输入设备(网卡),将数据加载到内存中,cpu计算(解密操作),再写回内存,再次刷新数据到输出设备(对方显示屏)上。
**而这过程实际上是符合体系结构的,并不是说,当信息发送出去后,就直接一步到位到
G
u
l
d
a
n
Guldan
Guldan 的显示屏。**
而对于一些加密,解密,以及将数据从外设读到内存这些都是软件提供的,这些我们暂时不要考虑。
讲到这里再提一嘴:其实从外设获取数据,我们也天天在用,比如 c 语言的 scanf ,就是从外设读数据的。所以这里就不难理解为啥软件可以获得外设的输入。
至此我们就得出结论:数据在流动的时候必须从外设到达内存,并不能直接到达目标地点,完全遵守冯诺依曼体系结构。说白了就是 外设只和内存打交道。
5、拓展
实际上对于外设只和内存打交道在之前是有歧义的:
因为早期芯片集成数据的能力较差。会把输入设备的数据直接打给 cpu ,读取的时候再通过 cpu 把数据放到内存里。再把数据缓存起来,需要使用的时候再把数据拿出来。
而现在 cpu 里面通常还带了 dma 芯片,就是专门把外设数据搬到内存的,这样外设和 cpu 和外设之间就无需直接沟通了,所以咱们当前认为 cpu 不直接和外设沟通。
还有一点需要补充的是:
外设和cpu虽然数据层面不直接交互,但是对于一些控制信号,它们之间是要交涉的,比如外设要给cpu发控制信号,需要让cpu帮外设做事情。但是当前我们还不考虑这点,还是考虑数据层面上,cpu和外设不直接沟通。
而冯诺依曼我们就聊到这儿。
三、操作系统简述
我们知道 Linux 是一个操作系统,但是什么是操作系统?对于这个概念我们了解起来也许模棱两可,所以今天的另一个话题就是谈谈操作系统。
首先看一下计算机体系图,接下来的内容会涉及到体系中的内容:
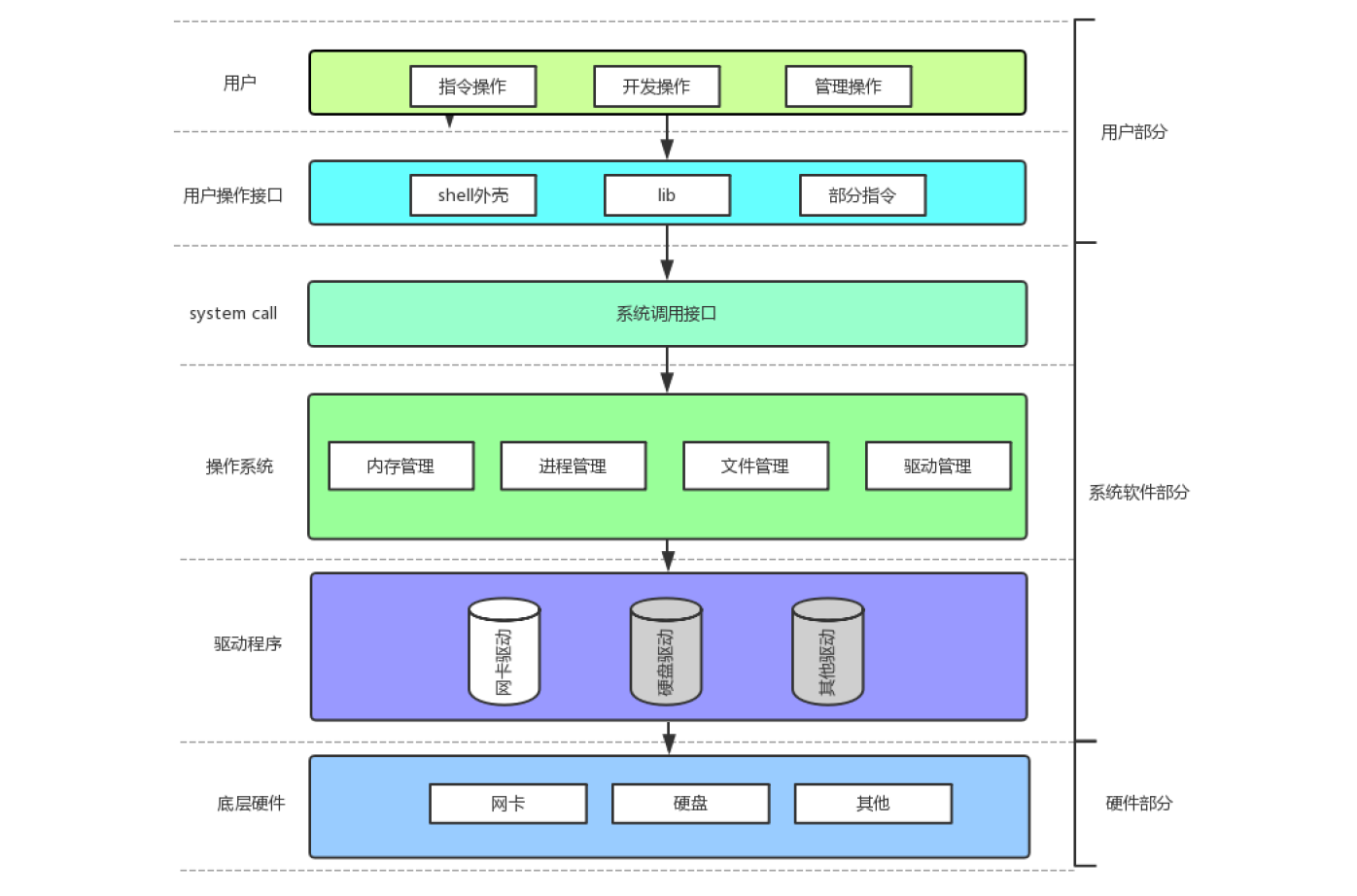
1、概念
任何计算机系统都包含一个基本的程序集合,称为操作系统,也就是 OS 。如果笼统的理解操作系统,它就包含两部分:
- 内核(进程管理,内存管理,文件管理,驱动管理)
- 其他程序(例如函数库,shell 程序等)
2、重要性
当讲冯诺依曼的时候,我们说过,数据是被加载到内存中,再供 cpu 进行内存读取的。
但是中间涉及了一大堆工作,例如,预加载的数据是哪一部分数据,内存如果不够了这时候怎么办?
随便抛出一个数据可能我们都说不出来,而这些工作其实都是软件做的,这个软件就是操作系统。
打个比方,硬件就好比是医院里的检测仪器,输出仪器。但是只有机器能看病吗?肯定不行,还得需要医生,而这其中面临很多问题,比如症状的分流,人员的分配,病人找到医生的方式,这么些抽象的问题仅仅依靠仪器是不能处理的。
这就说明软件是必须的,而这些繁杂的工作都由操作系统来处理。
3、定位
接下来我们看看 OS 的定位。其实 OS 定位很简单,它就是一款软件。
所有程序想要运行,都必须加载到内存中,而在开机加载的时候操作系统就被加载到了内存中,这样软件就可以被 cpu 跑了。
操作系统本身是一款对软硬件资源进行管理的软件。
4、如何管理
对于管理,一共有 三个结论 ,我们通过例子中间穿插着概念来感性理解它们:
首先明确一下管理者和被管理者 :
日常生活中,我们需要进行各种决策(想干什么)和执行(做什么)。
而在一个组织结构中,真正的管理者做的就是决策。其实这么说还不够详细,应该说管理者不是完全不做执行,但是管理者大部分时间都在决策。
若当前背景是一个学校,我们就将学校抽象成三部分:校长、辅导员、学生,如下:

而辅导员和校长都可以进行管理,但是他们谁是真正的管理者?校长 ,因为校长本身的工作大部分都在决策。
举个例子:
比如学校举办一个运动会。对于运动会场地,经费都是校长来决策,而剩下的就是学生执行。
那么辅导员再干什么?辅导员就是把校长的决策落地,部分决策让学生去干什么,部分执行去执行校长的决策。
也就是校长把决策给辅导员,辅导员执行嚣张的决策。相当于辅导员做的就是 伪决策 。
所以辅导员不是一个真正的管理者,辅导员只是对校长的决策做落地的角色,而学生就是纯粹的执行者。
所以校长才是真正的执行者 。
通过这一过程,角色就划分成了三块:

而这一过程校长(管理者)和被管理者(学生)见过面了吗?很明显没有。可能在大学中,学生见到校长也就是开学典礼的时候,只是一面之缘。
到这里,我们得出第一个结论:管理者和被管理者是不需要直接沟通的。
问题来了,既然管理者和被管理者没有直接沟通,它是如何管理我的?
再来举个例子:
比如说你的父母,在高中可能可以天天看着你,属于直接管理。但是上了大学父母不能进行直接管理,但是可以通过别人,例如你的室友,你的辅导员,获得你最近的行动,这样也可以进行管理。
而这一行为不就是管理者(父母)和被管理者(我)没有直接沟通,但是依然管理了。而管理方式就是通过数据。
至此,我们得出了第二个结论:管理的本质是对被管理对象的数据做管理。
通过这个结论,又衍生出了两个问题:
1)管理者是如何拿到被管理者的数据的 ?
这就好比校长从没见过我,但是它是如何管理到我的,怎么拿到我的数据?
这个过程就需要辅导员来进行,辅导员拿到数据,然后把数据给校长。
2)如果被管理者基数庞大,管理者是如何处理海量数据,筛选出特定数据?
虽然学生的数据不一样,但是学生的属性信息类型是一样的,比如:姓名、年级、电话、成绩、紧急联系人 …
而如果,我是说如果,校长一看这个,就想起了结构体,那么完全可以 **把信息抽象成一个结构体
s t r u c t s t u struct\ stu struct stu** 。而对于信息管理,可以将其抽象成一个链表,这时每个学生的信息就是一个节点:
这时如果要筛选出数据,就只需要根据关键值筛选就可以,从而将管理行为转换成对链表的管理。
而如果需要对学生进行信息删除,就只需要找到节点,然后释放,之后这个节点就被移除了,这个节点也消失,不需要再管理了。
这时决策就转换成对链表的增删查改。

而一个决策被转换为对数据结构的管理,这就相当于完成了一个建模的过程,把具体场景转换为计算机语言,就是建模的过程。
所以这里体现出语法和数据结构的重要性 :
这里就是先用结构体进行描述,再采集信息,构建对象,再形成某种结构,再把节点组织起来,并根据某种特性进行特殊化构建。
这其中就涉及到了面向对象和数据结构。
好了,现在也就引出了第三个结论:管理的方法是先描述,再组织。 而这句话也会被贯穿到之后 Linux 的学习中,一定要记好了。
管理的方法我们说完了,那么校长,辅导员和学生都代表着计算机里的什么角色?
- 学生:硬件(软件),这里的软件包括应用层和操作系统内的软件
- 辅导员:硬件驱动
- 校长:操作系统
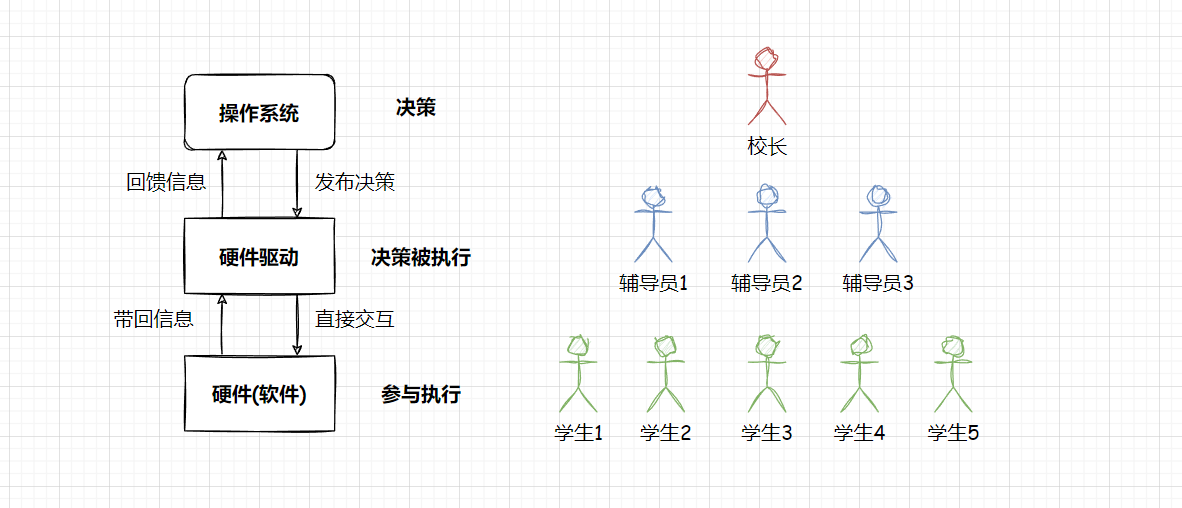
而硬件驱动,实际上就是驱动程序,它和硬件交互,拿到硬件传输的数据。操作系统发布决策给驱动,而操作系统是真正的管理者。
管理到这就讲完了,总结一下管理的特性和本质 :
- 管理者和被管理者是不需要直接沟通的
- 管理的本质是对被管理对象的数据做管理
- 管理的方法是先描述,再组织
5、管理目的
上面说了这么多管理的方法,但是操作系统为什么要对软硬件资源进行管理呢?它图啥呢?
为了更好地给用户提供服务,不让软件老是出 bug 。
要知道,一款操作系统能否生存,就是依赖于生态链和用户人数。不妨设想一下,如果操作系统动不动就蓝屏,打着打着游戏就关机了,还有人用吗?
肯定没有,这样子用户人数急剧减少,操作系统的生存问题就会出现了。而人们挑选操作系统的依据就是 是否好用 ,所以操作系统必须优化体验。
所以操作系统通过对下管理好软硬件资源,对上(用户层)给用户提供 安全、稳定、高效、功能丰富 的执行环境,让用户有一个最佳体验,这就是目的!
四、系统调用
刚说完管理目的,操作系统也为我们提供者服务,但是有一个问题,操作系统相信我吗?
这个问题可能很无厘头,是什么意思?提供服务不就完了,什么是相信?
同样的,我们举一个例子:
好比现在我们把银行当做一个操作系统,当我们去银行存钱的时候。银行人员看到你会说:“先生,往直走转弯就是金库,你把钱放在那边,不要拿走里面的钱,你就自己去存钱吧!”
这显然是不可能的,这也就反映了,虽然操作系统给我们提供了很好的服务,但是OS不相信我们,不相信任何人。
相反,操作系统会进行一些措施进行自我保护,比如银行配备了保安,操作系统也有对应的封装。
而生活中,银行是通过柜台来通过工作人员的操作,帮助我们存钱,就比如:

通过柜台窗口,把需求给员工,让员工完成操作,对于银行为了提供服务和保证自身安全,提供的是窗口式服务。
而对于操作系统,这个窗口式服务就是系统调用,而说到这边,我们就可以画出计算机软硬件体系结构图:
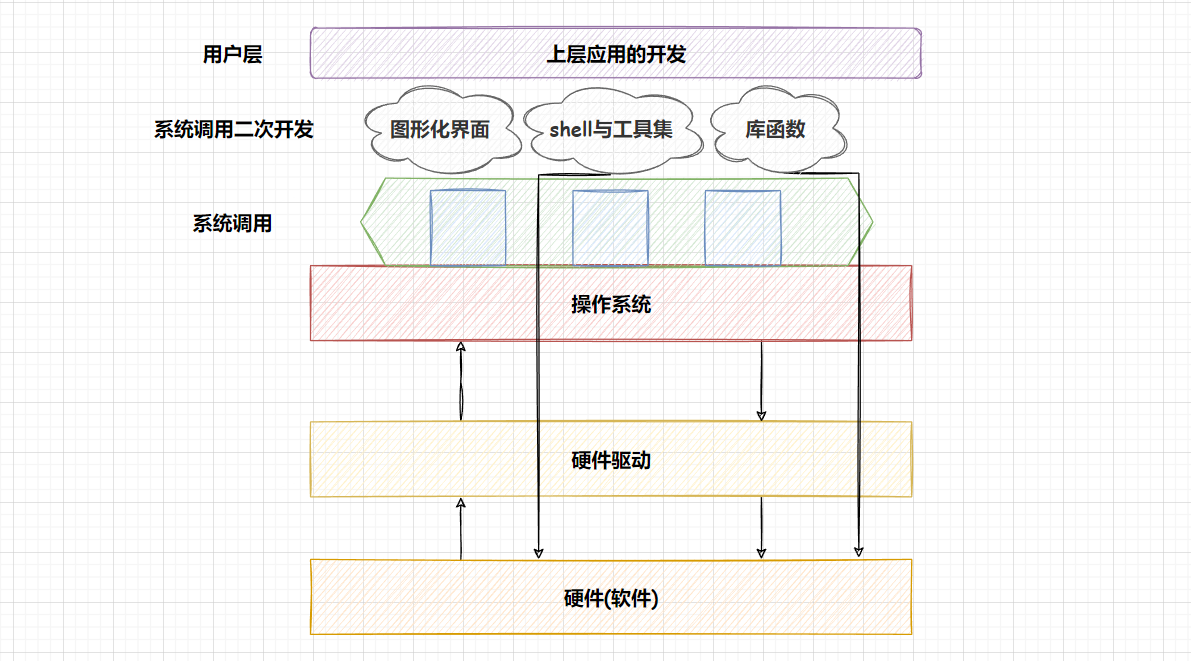
操作系统选择将对应的功能以接口的形式让别人访问,这一批接口,就被称为操作系统的系统调用。
而这一操作既帮助我们完成了功能,又保护了操作系统本身。
其实我们也都用过系统调用接口,但是它是以一种更简单的方式提供给我们使用了。
**因为系统调用接口的使用成本很高,于是就有相关人员对系统接口进行二次的软件开发,例如:图形化界面,
s
h
e
l
l
shell
shell 和工具集**。
而通过 shell 工具,我们就可以通过操作系统,对硬件或软件进行交互,例如
touch
这就是通过指令,依靠封装后的系统调用,从而贯穿体系结构,往磁盘(硬件)写入,从而生成文件。
同理对于语言,也就是库函数,也调用了系统调用 :
例如
printf
显示的设备是硬件,而向硬件写入的就是通过操作系统进行软硬件资源管理。
printf
就是 C 语言通过包含头文件,而它的底层就调用了系统调用接口。
而我们当前的开发,还在系统调用二次开发的上层,也就是用户层 。
五、结语
到这里,本篇博客就到此结束了。
相信看完文章,大家应该都对冯诺依曼体系结构和操作系统以及系统调用有了一定的了解。尤其是在管理部分一定要记住:先描述、再组织 ,这句话可以说是本篇文章的核心之一。
由于本篇是纯概念,所以建议看完可以好好消化一下,毕竟没有代码那么好记。
如果觉得
a
n
d
u
i
n
anduin
anduin 写的不错的话,可以 **点赞 + 收藏 + 评论** 支持一下哦!我们下期见~

版权归原作者 安 度 因 所有, 如有侵权,请联系我们删除。