
一、生产者配置
1. 必须要配置的参数:
- kafaf集群地址列表:理论上写一个节点地址,就相当于绑定了整个kafka集群了,但是建议多写几个,如果只写一个,万一宕机就麻烦了
- kafka消息的key和value要指定序列化方法
- kafka对应的生产者id
使用java代码表示则为以下代码:
//BOOTSTRAP_SERVERS_CONFIG:连接kafka集群的服务列表,如果有多个,使用"逗号"进行分隔
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.101:9092");
// 使用字符串序列化类:org.apache.kafka.common.serialization.StringSerializer
// KEY: 是kafka用于做消息投递计算具体投递到对应的主题的哪一个partition而需要的
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// VALUE: 实际发送消息的内容
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//CLIENT_ID_CONFIG:这个属性的目的是标记kafkaclient的ID
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "producer-id");
2. 消息发送重试机制
可使用 retries 参数 进行设置,同时要注意记住两个概念:可重试异常(重试可能会成功)、不可重试异常(无论重试多少次都不会成功);
retries设置的代码:
properties.put(ProducerConfig.RETRIES_CONFIG, 3); # 默认是0
3. 一点说明
kafka的生产者是多线程安全的,表示多个线程可以同时共享同一个kafka生产者实例对象;但是kafka的消费者不是线程安全的。
kafka生产者提供的两个send()方法都是异步的,如下:
Future<RecordMetadata> send(ProducerRecord<K, V> record); # 这个send()虽然是异步的,但是可以通过 返回对象调用get()方法达到同步的效果
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
kafka在生产环境中,一定要在在代码中关闭自动创建 topic .可通过 kafka-manage 控制台创建好 topic,再进行消息的发送与接收。
测试代码:
public class NormalProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.101:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "normal-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// kafka 消息的重试机制: RETRIES_CONFIG该参数默认是0:
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
// 可重试异常, 意思是执行指定的重试次数 如果到达重试次数上限还没有发送成功, 也会抛出异常信息
// NetworkException
// LeaderNotAvailableException
// 不可重试异常
// RecordTooLargeException
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
User user = new User("100", "里德");
// kafka默认是可以在没有主题的情况下创建的
// 自动创建主题的特性,在生产环境中一定是禁用的
ProducerRecord<String, String> record =
new ProducerRecord<String, String>("normal-topic",
JSON.toJSONString(user));
/**
* //一条消息 必须通过key 去计算出来实际的partition, 按照partition去存储的
* ProducerRecord(
* topic=topic_normal,
* partition=null,
* headers=RecordHeaders(headers = [], isReadOnly = false),
* key=null,
* value={"id":"001","name":"xiao xiao"},
* timestamp=null)
*/
System.err.println("新创建的消息:"+record);
// 一个参数的send方法 本质上也是异步的 返回的是一个future对象; 可以实现同步阻塞方式
/*
Future<RecordMetadata> metadataFuture = producer.send(record);
RecordMetadata recordMetadata = metadataFuture.get();
System.err.println(String.format("发送结果:分区位置:%s, 偏移量:%s, 时间戳:%s",
recordMetadata.partition(),
recordMetadata.offset(),
recordMetadata.timestamp()));
*/
// 带有两个参数的send方法 是完全异步化的。在回调Callback方法中得到发送消息的结果
Future<RecordMetadata> metadataFuture = producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(null == exception) {
System.err.println(String.format("发送结果:分区位置:%s, 偏移量:%s, 时间戳:%s",
metadata.partition(),
metadata.offset(),
metadata.timestamp()));
}else {
exception.printStackTrace();
return;
}
}
});
producer.close();
}
}
4. 生产者端的重要参数
(1) acks: 表示发送消息后,broker端至少有多少副本接收到该消息:
- 默认acks=1, 表示只要 leader 副本接收到消息,就能收到来自服务端的成功响应
- acks=0: 生产者发送消息之后,不要等待任务服务端的响应。
- acks=-1 或 acks=all:生产者在消息发送之后,需要等待 ISR(In-sync Replication) 中的所有副本都成功写入消息之后,才能够收到来自服务端的成功响应。
- 并不是asks=-1 或 acks=all 就一定会被投递成功,因为可能只有leader副本在ISR中,follower副本都在 OSR(Out-sync Replication)中,而消息还没来得及传给 OSR 中的副本,leader副本就宕机了。
- 想要100%投递成立,还要配合参数 min.insync.replicas=2,表示至少两个副本接收到该消息,但是容易影响性能。
关于ISR与OSR:最开始所有的副本都在ISR中,在kafka工作的过程中,如果某个副本同步速度慢于replica.lag.time.max.ms指定的阈值,则被踢出ISR存入OSR,如果后续速度恢复可以回到ISR中。
(2)批量发送相关的参数
linger.ms:指定生产者发送ProducerBatch之前等待更多的消息加入producerBatch的时间,默认值为0,就像是等人上车的时间
batch.size:累计多少条消息,则一次进行批量发送,就是满多少人即发车的意思
buffer.memory:缓存大小,可以修改它提升缓存性能,默认32M
(3) 其他参数
max.request.size:该参数用来限制生产者客户端能发送的消息的最大值,默认值是 1M
retries和retry.backoff.msretries:重试次数和重试间隔时间,第一个默认0,第二个默认100ms
compression.type:指定对发送的消息的压缩方式,默认为“none”,可选gzip,snappy,lz4
connections.max.idle.ms:这个参数用来指定连接空闲多久之后关闭,默认540000ms,即9分钟
receive.buffer.bytes:设置socket接收消息缓冲区 默认32KB
send.buffer.bytes:设置socket发送消息缓冲区 默认128KB
request.timeout.ms:配置producer等待请求broker响应的最长时间,默认30000ms
二、消费者配置
1. 必要的参数
bootstrap.servers: 用来指定连接 Kafka集群所需的broker 地址清单
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.101:9092");
key.deserializer 和 value.deserializer: 反序列化参数
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
group.id:消费者所属消费组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "topic-module-consumer");
subscribe:消息主题订阅,支持集合/标准正则表达式;
# 订阅主题集合
consumer.subscribe(Collections.singletonList("topic-module"));
# 正则表达式
consumer.subscribe(Pattern.compile("topic-.*"));
assign:只订阅主题的某个分区
consumer.assign(Arrays.asList(new TopicPartition("topic-module", 0), new TopicPartition("topic-module", 4)));
2. 其他参数
fetch.min.bytes:一次拉取最小数据量,默认为1B
fetch.max.bytes: 一次拉取最大数据量,默认为50M
max.partition.fetch.bytes: 一次fetch请求,从一个partition中取得的records最大大小,默认1M
fetch.max.wait.ms: Fetch请求发给broker后,在broker中可能会被阻塞,默认等待的时长500毫秒
maxpoll.records: Consumer每次调用poll()时取到的records的最大数,默认为500条
3. 消费者提交commit操作
(1)自动提交
自动提交: enableauto.commit ,默认值为true,和参数:提交周期间隔 auto.commit.interval.ms 搭配使用,默设值为5秒
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
(2)手工提交
手工提交,需要将 enable.auto.commit配置为false;并使用 commitSync或者commitAsync进行提交,这两种方式一个是同步提交,一个是异步提交;无论是同步还是异步,都支持整体提交和按分区提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
示例代码
public class NormalConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.101:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "topic-module");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
// 改成手动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 消费者默认每次拉取的位置:从什么位置开始拉取消息
// AUTO_OFFSET_RESET_CONFIG 有三种方式: "latest", "earliest", "none" 默认值是latest
// none
// latest 从一个分区的最后提交的offset开始拉取消息
// earliest 从最开始的起始位置拉取消息 0
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
consumer.subscribe(Collections.singletonList("topic-module"));
System.err.println("quickstart consumer started...");
try {
while(true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for(TopicPartition topicPartition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(topicPartition);
String topic = topicPartition.topic();
int size = partitionRecords.size();
System.err.println(String.format("--- 获取topic: %s, 分区位置:%s, 消息总数: %s",
topic,
topicPartition.partition(),
size));
for(int i = 0; i < size; i++) {
ConsumerRecord<String, String> consumerRecord = partitionRecords.get(i);
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffser = offset + 1;
System.err.println(String.format("获取实际消息 value:%s, 消息offset: %s, 提交offset: %s",
value, offset, commitOffser));
// 在一个partition内部,每一条消息记录 进行一一提交方式
// 按分区提交:同步方式
consumer.commitSync(Collections.singletonMap(topicPartition, new OffsetAndMetadata(commitOffser)));
// 按分区提交:异步方式 (这种按照partition维度,并且是异步的提交方式使用最多)
consumer.commitAsync(Collections.singletonMap(topicPartition, new OffsetAndMetadata(commitOffser)), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if(null == exception) {
System.err.println("按分区进行提交成功,偏移量:" + offsets);
}else {
System.err.println("提交失败");
}
}
});
}
}
// 整体提交:同步方式
// consumer.commitSync();
// 整体提交:异步方式
/*consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if(exception == null){
System.err.println("整体提交成功,偏移量:"+offsets);
}else {
System.err.println("提交失败,"+exception);
}
}
});*/
}
} finally {
consumer.close();
}
}
}
三、自定义拦截器
1. 自定义生产者拦截器
自定义生产者拦截器类需要继承 org.apache.kafka.clients.producer.ProducerInterceptor,并实现其中的方法:
- onSend(ProducerRecord record)是发送消息之前的切面方法;
- onAcknowledgement(RecordMetadata metadata, Exception exception)是发送消息之后的切面方法;
- close()是生产者关闭前调用的方法;’
- configure(Map<String, ?> configs)是拦截器用于配置一些属性的方法;
拦截器代码示例CustomProducerInterceptor.java:
public class CustomProducerInterceptor implements org.apache.kafka.clients.producer.ProducerInterceptor<String, String> {
private volatile int success;
private volatile int failure;
// 发送消息之前的切面拦截
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
System.err.println("生产者发送前置方法!");
String value = "prefix:"+record.value();
return new ProducerRecord(record.topic(), record.partition(), record.timestamp(), record.key(), value, record.headers());
}
// 发送消息之后的切面拦截
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if(null == exception){
success++;
}else {
failure++;
}
System.err.println("生产者发送后置方法!");
}
@Override
public void close() {
System.err.println(String.format("发送成功率:%s %%", success*100/success+failure));
}
@Override
public void configure(Map<String, ?> configs) {
}
}
将拦截器类定义好之后,只需要在生产者创建时,作为一个属性配置传进去(CustomProducerInterceptor.class是自定义拦截器类):
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomProducerInterceptor.class.getName());
2. 自定义消费者拦截器
需要实现的接口为 org.apache.kafka.clients.consumer.ConsumerInterceptor ,并实现其中的方法:
- onConsume(ConsumerRecords records)是接到消息,但是处理之前的切面方法;
- onCommit(Map<TopicPartition, OffsetAndMetadata> offsets)是消息处理完成之后,提交处理结果之前的切面方法,(如果为自动提交,会按时间间隔不停进行提交操作,那么该切面方法也会被不断地执行)
- close()是消费者关闭前的切面方法;
- configure(Map<String, ?> configs)是拦截器配置一些属性的方法;
拦截器代码示例 CustomProducerInteceptor.java:
public class CustomConsumerInterceptor implements ConsumerInterceptor<String, String> {
// onConsume:消费者接到消息处理之前的拦截器
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
System.err.println("消费者消费前置方法!");
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
System.err.println("消费者消费后置方法!");
offsets.forEach((tp, om) -> {
System.err.println(String.format("分区位置:%s,提交偏移量:%s", tp, om));
});
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
四、序列化

1. 实现自定义对象的序列化
这里自定义对象为 User.java:
public class User {
private String id;
private String name;
public User() {
}
public User(String id, String name) {
this.id = id;
this.name = name;
}
// getter、setter省略
}
自定义序列化类需要实现 org.apache.kafka.common.serialization.Serializer接口:
SerializerProducer.java
public class SerializerProducer implements Serializer<User> {
@Override
public byte[] serialize(String topic, User user) {
try {
if (user == null) {
return null;
}
else {
String id = user.getId();
String name = user.getName();
byte[] idBytes, nameBytes;
if(null == id){
idBytes = new byte[0];
}else {
idBytes = id.getBytes("UTF-8");
}
if(null == name){
nameBytes = new byte[0];
}else {
nameBytes = name.getBytes("UTF-8");
}
ByteBuffer byteBuffer = ByteBuffer.allocate(4 + 4 + idBytes.length + nameBytes.length);
// 4个字节 也就是一个 int类型 : putInt 盛放 idBytes的实际真实长度
byteBuffer.putInt(idBytes.length);
// put bytes[] 实际盛放的是idBytes真实的字节数组,也就是内容
byteBuffer.put(idBytes);
byteBuffer.putInt(nameBytes.length);
byteBuffer.put(nameBytes);
return byteBuffer.array();
}
} catch (UnsupportedEncodingException e) {
throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding ", e);
}
}
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public void close() {
}
}
这里是对 消息的value,也就是 User 对象进行序列化,所以需要在生产者配置属性中加入自定义的序列化类:
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, SerializerProducer.class.getName());
2. 实现自定义对象的反序列化
反序列化类需要实现 org.apache.kafka.common.serialization.Deserializer类:
DeserializerConsumer.java
public class DeserializerConsumer implements Deserializer<User> {
@Override
public User deserialize(String topic, byte[] data) {
if(null == data){
return null;
}
if(data.length < 8){
throw new SerializationException("size is wrong, must be data.length >= 8");
}
ByteBuffer byteBuffer = ByteBuffer.wrap(data);
// idBytes 字节数组的真实长度
int idSize = byteBuffer.getInt();
byte[] idBytes = new byte[idSize];
byteBuffer.get(idBytes);
// nameBytes 字节数组的真实长度
int nameSize = byteBuffer.getInt();
byte[] nameBytes = new byte[nameSize];
byteBuffer.get(nameBytes);
String id, name;
try {
id = new String(idBytes, "UTF-8");
name = new String(nameBytes, "UTF-8");
} catch (UnsupportedEncodingException e) {
throw new SerializationException("deserializing error! ", e);
}
return new User(id, name);
}
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public void close() {
}
}
“将User对象直接转为json字符串,然后将字符串直接使用 getBytes("UTF-8") 方法转为字节数组”这种序列化方法也可以,不过这里是尝试另一种方法,即上面使用ByteBuffer拼接字节数组的方法
这里是对 消息的value,也就是 User 对象进行反序列化,所以需要在消费者配置属性中加入自定义的反序列化类:
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, DeserializerConsumer.class.getName());
五、分区器
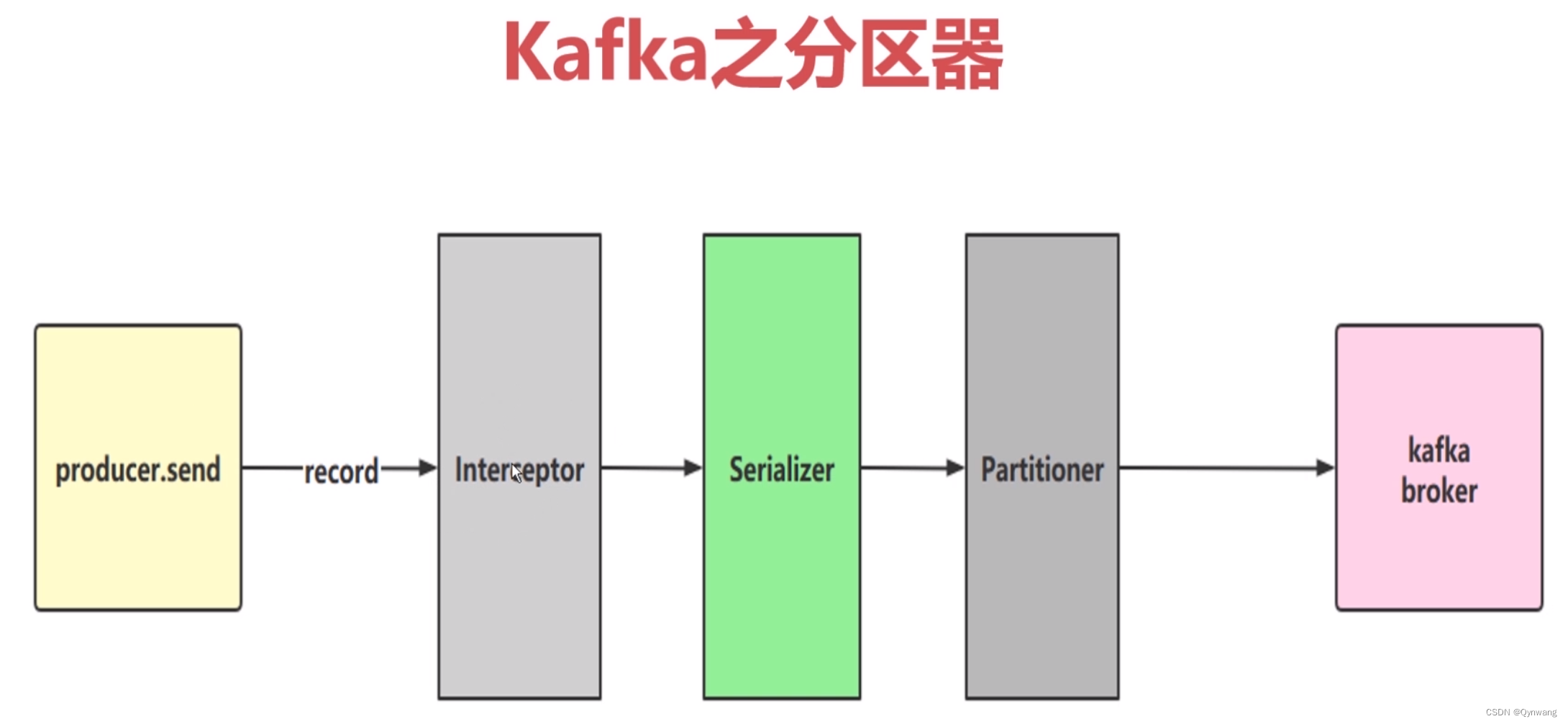
1. 分区器
默认分区器:是对kafka消息中的key进行一个hash计算,从而得到投递到具体哪个分区的区号;
另外可根据自己的实际业务场景自定义分区器,需要实现 org.apache.kafka.clients.producer.Partitioner 类:
public class CustomPartitioner implements Partitioner {
private AtomicInteger counter = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfoList = cluster.partitionsForTopic(topic);
int numPartitions = partitionInfoList.size();
System.err.println("---- 进入自定义分区器,当前分区个数:" + numPartitions);
if(keyBytes == null){
return counter.getAndIncrement() % numPartitions;
}else {
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
并在生产者的配置属性中增加该分区器类:
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class.getName());
2. 应用场景
什么情况下会需要自定义分区器?
比如有四种类型的订单:零食、衣服、灯泡、汽车,根据业务类型,让消息进入到各自的分区,也就是一个分区一种类型的数据,能够让各自类型的consumer快速获取属于自己的业务数据。
如果把所有数据随机的放到某个partation中,那么就会造成数据混乱,因为消息队列是顺序消费的(partition中的数据是先进先出),一些热门类型的业务占据大部分消息,比如零食的订单量远远高于汽车的订单量,零食的订单在消息partition中的前面,汽车的在后面,这就会一直堵塞汽车的消息迟迟到不了consumer端,导致汽车明明有订单,但是状态却是一直无法处理中。
所以最好的方法就是根据类型进行分区,不同的类型数据单独放到对应的partation中,一个类型的数据对应一个partation,可以通过类型自定义分区器。
版权归原作者 Java知者 所有, 如有侵权,请联系我们删除。