
♥️作者:小刘在C站
♥️个人主页:**** 小刘主页 ********
♥️努力不一定有回报,但一定会有收获加油!一起努力,共赴美好人生!
♥️学习两年总结出的运维经验,以及思科模拟器全套网络实验教程。专栏:云计算技术
♥️小刘私信可以随便问,只要会绝不吝啬,感谢CSDN让你我相遇!
前言
本次MySQL—索引章节比较多,分为多篇进行发布,本章继续,链接—上一章
*6.5 SQL***提示 **
目前tb_user表的数据情况如下:
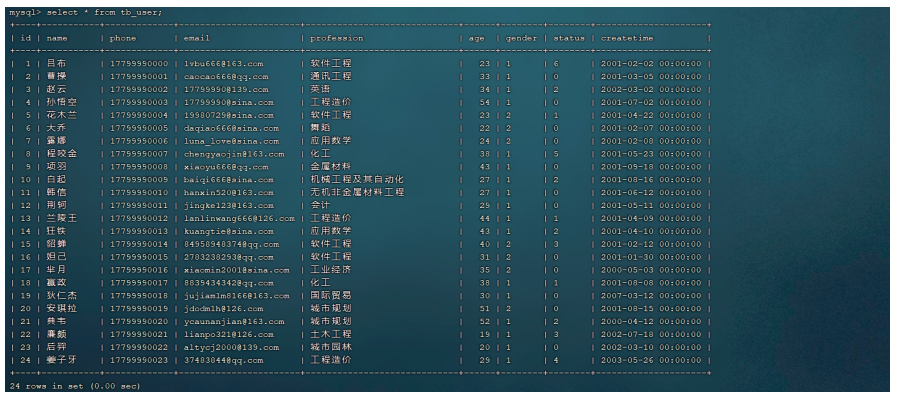
索引情况如下:

把上述的 idx_user_age, idx_email 这两个之前测试使用过的索引直接删除。
drop index idx_user_age on tb_user;
drop index idx_email on tb_user;
A. 执行SQL : explain select * from tb_user where profession = '软件工程';

查询走了联合索引。
B. 执行SQL,创建profession的单列索引:create index idx_user_pro on
tb_user(profession)

C. 创建单列索引后,再次执行A中的SQL语句,查看执行计划,看看到底走哪个索引。

测试结果,我们可以看到,possible_keys中 idx_user_pro_age_sta,idx_user_pro 这两个
索引都可能用到,最终MySQL选择了idx_user_pro_age_sta索引。这是MySQL自动选择的结果。
那么,我们能不能在查询的时候,自己来指定使用哪个索引呢? 答案是肯定的,此时就可以借助于 MySQL的SQL提示来完成。 接下来,介绍一下SQL提示。
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
1). use index : 建议MySQL使用哪一个索引完成此次查询(仅仅是建议,mysql内部还会再次进
行评估)。
explain select * from tb_user use index(idx_user_pro) where profession = '软件工
程';
2). ignore index : 忽略指定的索引。
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工
程';
3). force index : 强制使用索引。
explain select * from tb_user force index(idx_user_pro) where profession = '软件工
程';
示例演示:
A. use index
explain select * from tb_user use index(idx_user_pro) where profession = '软件工
程';

B. ignore index
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工
程';

C. force index
explain select * from tb_user force index(idx_user_pro_age_sta) where profession =
'软件工程';

**6.6 **覆盖索引
尽量使用覆盖索引,减少select *。 那么什么是覆盖索引呢? 覆盖索引是指 查询使用了索引,并
且需要返回的列,在该索引中已经全部能够找到 。
接下来,我们来看一组SQL的执行计划,看看执行计划的差别,然后再来具体做一个解析。
explain select id, profession from tb_user where profession = '软件工程' and age =
31 and status = '0' ;
explain select id,profession,age, status from tb_user where profession = '软件工程'
and age = 31 and status = '0' ;
explain select id,profession,age, status, name from tb_user where profession = '软
件工程' and age = 31 and status = '0' ;
explain select * from tb_user where profession = '软件工程' and age = 31 and status
= '0';
上述这几条SQL的执行结果为:
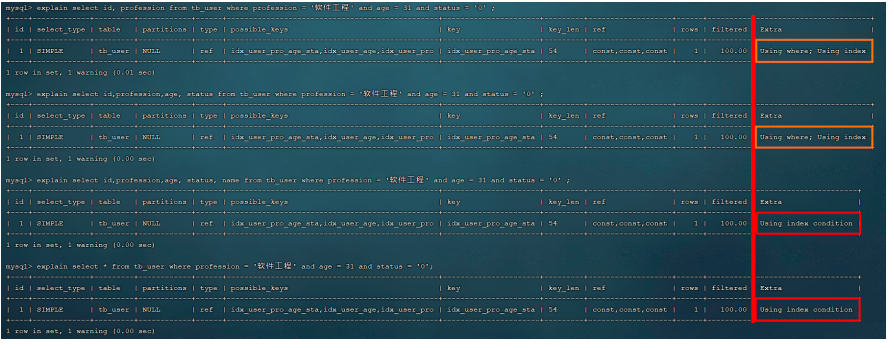
从上述的执行计划我们可以看到,这四条SQL语句的执行计划前面所有的指标都是一样的,看不出来差异。但是此时,我们主要关注的是后面的Extra,前面两天SQL的结果为 Using where; Using
Index ; 而后面两条SQL的结果为: Using index condition 。

因为,在tb_user表中有一个联合索引 idx_user_pro_age_sta,该索引关联了三个字段
profession、age、status,而这个索引也是一个二级索引,所以叶子节点下面挂的是这一行的主键id。 所以当我们查询返回的数据在 id、profession、age、status 之中,则直接走二级索引 直接返回数据了。 如果超出这个范围,就需要拿到主键id,再去扫描聚集索引,再获取额外的数据了,这个过程就是回表。 而我们如果一直使用select * 查询返回所有字段值,很容易就会造成回表 查询(除非是根据主键查询,此时只会扫描聚集索引)。
为了大家更清楚的理解,什么是覆盖索引,什么是回表查询,我们一起再来看下面的这组SQL的执行过程。
A. 表结构及索引示意图:

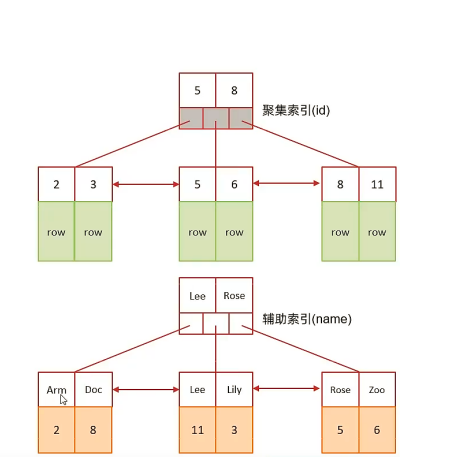
id是主键,是一个聚集索引。 name字段建立了普通索引,是一个二级索引(辅助索引)。
B. 执行SQL : select * from tb_user where id = 2;

根据id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
C. 执行SQL:selet id,name from tb_user where name = 'Arm';

虽然是根据name字段查询,查询二级索引,但是由于查询返回在字段为 id,name,在name的二级索引中,这两个值都是可以直接获取到的,因为覆盖索引,所以不需要回表查询,性能高。
D. 执行SQL:selet id,name,gender from tb_user where name = 'Arm';

由于在name的二级索引中,不包含gender,所以,需要两次索引扫描,也就是需要回表查询,性能相较差一点。
**6.7 **前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让
索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
1). 语法
create index idx_xxxx on table_name(column(n)) ;
示例:
为tb_user表的email字段,建立长度为5的前缀索引。
create index idx_email_5 on tb_user(email(5)); 1

2). 前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
select count(distinct email) / count(*) from tb_user ;
select count(distinct substring(email,1,5)) / count(*) from tb_user ;
3). 前缀索引的查询流程

**6.8 **单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
我们先来看看 tb_user 表中目前的索引情况:

在查询出来的索引中,既有单列索引,又有联合索引。
接下来,我们来执行一条SQL语句,看看其执行计划:

通过上述执行计划我们可以看出来,在and连接的两个字段 phone、name上都是有单列索引的,但是最终mysql只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的。
紧接着,我们再来创建一个phone和name字段的联合索引来查询一下执行计划。
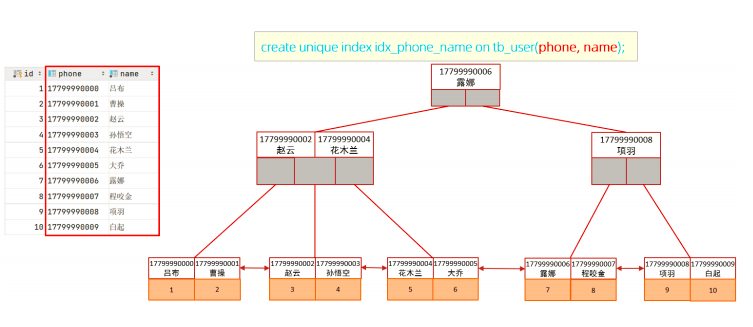
create unique index idx_user_phone_name on tb_user(phone,name);

此时,查询时,就走了联合索引,而在联合索引中包含 phone、name的信息,在叶子节点下挂的是对应的主键id,所以查询是无需回表查询的。
此时,查询时,就走了联合索引,而在联合索引中包含 phone、name的信息,在叶子节点下挂的是对应的主键id,所以查询是无需回表查询的。
如果查询使用的是联合索引,具体的结构示意图如下:
**7.****索引设计原则 **
1). 针对于数据量较大,且查询比较频繁的表建立索引。
2). 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3). 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4). 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5). 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间, 避免回表,提高查询效率。
6). 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增 删改的效率。
7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
好啦,MySQL索引就到此结束啦
投票
♥️关注,就是我创作的动力
♥️点赞,就是对我最大的认可
♥️这里是小刘,励志用心做好每一篇文章,谢谢大家
版权归原作者 小刘在C站 所有, 如有侵权,请联系我们删除。