
学习目标:
- Spark概述
- Spark运行模式
- Spark RDD创建
- RDD算子
Spark概述
大数据开发的总体架构
在数据计算层,作为Hadoop核心组成的MapReduce可以结合Hive通过类SQL的方式进行数据的离线计算(当然也可以编写独立的MapReduce应用程序进行计算);而Spark既可以做离线计算(Spark SQL),又可以做实时计算(Spark Streaming),它们底层都使用的是Spark的核心(Spark Core)。
Spark初识
Apache Spark是一个快速通用的集群计算系统,是一种与Hadoop相似的开源集群计算环境,但是Spark在一些工作负载方面表现得更加优越。它提供了Java、Scala、Python和R的高级API,以及一个支持通用的执行图计算的优化引擎。它还支持高级工具,包括使用SQL进行结构化数据处理的Spark SQL、用于机器学习的MLlib、用于图处理的GraphX,以及用于实时流处理的Spark Streaming。
Spark的主要特点
- 快速
MapReduce主要包括Map和Reduce两种操作,且将多个任务的中间结果存储于HDFS中。与MapReduce相比,Spark可以支持包括Map和Reduce在内的多种操作,这些操作相互连接形成一个有向无环图(Directed Acyclic Graph, DAG),各个操作的中间数据会被保存在内存中。因此,Spark处理速度比MapReduce更快。
- 易用
Spark可以使用Java、Scala、Python、R和SQL快速编写应用程序。此外,Spark还提供了超过80个高级算子,使用这些算子可以轻松构建应用程序。
- 通用
Spark拥有一系列库,包括SQL和DataFrame、用于机器学习的MLlib、用于图计算的GraphX、用于实时计算的Spark Streaming,可以在同一个应用程序中无缝地组合这些库。
- 到处运行
Spark可以使用独立集群模式运行(使用自带的独立资源调度器,称为Standalone模式),也可以运行在Hadoop YARN、Mesos(Apache下的一个开源分布式资源管理框架)等集群管理器之上,并且可以访问HDFS、HBase、Hive等数百个数据源中的数据。
Spark的主要组件
Spark是由多个组件构成的软件栈,Spark 的核心(Spark Core)是一个对由很多计算任务组成的、运行在多个工作机器或者一个计算集群上的应用进行调度、分发以及监控的计算引擎。
Spark安装
下载解压缩spark-3.3.3-bin-hadoop3.tgz,重命名Spark安装目录为spark,在配置文件/etc/profile中添加:
export SPARK_HOME=/export/servers/spark
export PATH=$PATH:$SPARK_HOME/bin
执行/etc/profile脚本,使配置生效
source /etc/profile
Spark运行模式
Spark主要有三种运行模式:
- 本地(单机)模式
本地模式通过多线程模拟分布式计算,通常用于对应用程序的简单测试。本地模式在提交应用程序后,将会在本地生成一个名为SparkSubmit的进程,该进程既负责程序的提交,又负责任务的分配、执行和监控等。
- Spark Standalone模式
使用Spark自带的资源调度系统,资源调度是Spark自己实现的。
- Spark On YARN模式
以YARN作为底层资源调度系统以分布式的方式在集群中运行。
Spark Standalone架构
Spark Standalone的两种提交方式
Spark Standalone模式为经典的Master/Slave架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:client和cluster,默认是client。可以在向Spark集群提交应用程序时使用–deploy-mode参数指定提交方式。
- client提交方式
当提交方式为client时,运行架构如下图所示:
Spark Standalone模式架构(client提交方式)
集群的主节点称为Master节点,在集群启动时会在主节点启动一个名为Master的守护进程;从节点称为Worker节点,在集群启动时会在各个从节点上启动一个名为Worker的守护进程。
Spark在执行应用程序的过程中会启动Driver和Executor两种JVM进程。
Driver为主控进程,负责执行应用程序的main()方法,创建SparkContext对象(负责与Spark集群进行交互),提交Spark作业,并将作业转化为Task(一个作业由多个Task任务组成),然后在各个Executor进程间对Task进行调度和监控。通常用SparkContext代表Driver。如图所示的架构中,Spark会在客户端启动一个名为SparkSubmit的进程,Driver程序则运行于该进程。
Executor为应用程序运行在Worker节点上的一个进程,由Worker进程启动,负责执行具体的Task,并存储数据在内存或磁盘上。每个应用程序都有各自独立的一个或多个Executor进程。
- cluster提交方式
当提交方式为cluster时,运行架构如下图所示:
Spark Standalone模式架构(cluster提交方式)
Standalone以cluster提交方式提交应用程序后,客户端仍然会产生一个名为SparkSubmit的进程,但是该进程会在应用程序提交给集群之后就立即退出。当应用程序运行时,Master会在集群中选择一个Worker启动一个名为DriverWrapper的子进程,该子进程即为Driver进程。
Spark Standalone模式的搭建
进入Spark安装根目录,进入conf目录,执行以下操作:
(1):复制spark-env.sh.template文件为spark-env.sh文件
cp spark-env.sh.template spark-env.sh
(2): 修改spark-env.sh文件,添加以下内容:
export JAVA_HOME=/export/servers/jdk1.8.0_161
export SPARK_MASTER_HOST=my2308-host
export SPARK_MASTER_PORT=7077
- JAVA_HOME:指定JAVA_HOME的路径。若节点在/etc/profile文件中配置了JAVA_HOME,则该选项可以省略,Spark启动时会自动读取。为了防止出错,建议此处将该选项配置上。
- SPARK_MASTER_HOST:指定集群主节点(Master)的主机名。
- SPARK_MASTER_PORT:指定Master节点的访问端口,默认为7077。
(3): 启动Spark集群
进入Spark安装目录,执行以下命令,启动Spark集群:
sbin/start-all.sh
启动完毕后,分别在各节点执行jps命令,查看启动的Java进程。若存在Master进程和Worker进程,则说明集群启动成功。
也可以在浏览器中访问网址http://虚拟机IP地址:8080,查看Spark的WebUI,查看Spark的WebUI,如图所示:
Spark On YARN架构
Spark On YARN的两种提交方式
Spark On YARN模式遵循YARN的官方规范,YARN只负责资源的管理和调度,运行哪种应用程序由用户自己决定,因此可能在YARN上同时运行MapReduce程序和Spark程序,YARN对每一个程序很好地实现了资源的隔离。这使得Spark与MapReduce可以运行于同一个集群中,共享集群存储资源与计算资源。
Spark On YARN模式与Standalone模式一样,也分为client和cluster两种提交方式。
- client提交方式
Spark On YARN模式架构(client提交方式)
客户端会产生一个名为SparkSubmit的进程,Driver程序则运行于该进程中。
- cluster提交方式
ResourceManager会在集群中选择一个NodeManager进程启动一个名为ApplicationMaster的子进程,该子进程即为Driver进程(Driver程序运行在其中)。
Spark On YARN模式的搭建
Spark On YARN模式的搭建比较简单,仅需要在YARN集群的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。Spark本身的Master节点和Worker节点不需要启动。
使用此模式需要修改Spark配置文件$SPARK_HOME/conf/spark-env.sh,添加Hadoop相关属性,指定Hadoop与配置文件所在目录,内容如下:
export HADOOP_HOME=/export/servers/hadoop-3.2.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
Spark应用程序的提交
Spark提供了一个客户端应用程序提交工具spark-submit,使用该工具可以将编写好的Spark应用程序提交到Spark集群。
spark-submit的使用格式:
bin/spark-submit [options] <app jar> [app options]
options:表示传递给spark-submit的控制参数;
app jar:表示提交的程序jar包(或Python脚本文件)所在位置;
app options:表示jar程序需要传递的参数,例如main()方法中需要传递的参数。
附表:
- spark-submit的常用参数介绍
- spark-submit的–master参数取值介绍
举个栗子:以Spark自带的求圆周率的程序提交为例:
- 在Standalone模式下,将Spark自带的求圆周率的程序提交到Spark自带的资源管理器:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://192.168.121.131:7077 \
/export/servers/spark/examples/jars/spark-examples_2.12-3.3.3.jar
注:上面命令中的\符号代表换行!
可通过:http://虚拟机IP:8080 查看提交的应用程序
- 在Sparn On YARN模式下,将Spark自带的求圆周率的程序提交到Hadoop YARN进行资源管理(注意提前将Hadoop HDFS和YARN启动),并且以Spark On YARN的cluster模式运行,命令如下:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/export/servers/spark/examples/jars/spark-examples_2.12-3.3.3.jar
可通过:http://虚拟机IP:8088/ 查看提交的应用程序
Spark Shell的使用
Spark带有交互式的Shell,可在Spark Shell中直接编写Spark任务,然后提交到集群与分布式数据进行交互,并且可以立即查看输出结果。Spark Shell提供了一种学习Spark API的简单方式,可以使用Scala或Python语言进行程序的编写。
执行以下命令,可以查看Spark Shell的相关使用参数:
spark-shell --help
Spark Shell在Spark Standalone模式和Spark On YARN模式下都可以执行,与使用spark-submit进行任务提交时可以指定的参数及取值相同。唯一不同的是,Spark Shell本身为集群的client提交方式运行,不支持cluster提交方式,即使用Spark Shell时,Driver运行于本地客户端,而不能运行于集群中。
- 本地(单机)模式启动Spark Shell终端
spark-shell --master local
- Spark Standalone模式启动Spark Shell终端
spark-shell --master spark://虚拟机IP:7077
从启动过程的输出信息可以看出,Spark Shell启动时创建了一个名为sc的变量,该变量为类SparkContext的实例,可以在Spark Shell中直接使用。SparkContext存储Spark上下文环境,是提交Spark应用程序的入口,负责与Spark集群进行交互。除了创建sc变量外,还创建了一个spark变量,该变量是类SparkSession的实例,也可以在Spark Shell中直接使用。
启动完成后,访问Spark WebUI http://虚拟机IP:8080查看运行的Spark应用程序,如图:
可以看到,Spark启动了一个名为Spark shell的应用程序(如果Spark Shell不退出,该应用程序就一直存在)。这说明,实际上Spark Shell底层调用了spark-submit进行应用程序的提交。与spark-submit不同的是,Spark Shell在运行时会先进行一些初始参数的设置,并且Spark Shell是交互式的。
- Spark On YARN模式启动Spark Shell终端(别忘了开启Hadoop YARN)
spark-shell --master yarn
注意:若启动过程中报错如图所示,则说明Spark任务的内存分配过小,YARN直接将相关进程杀掉了。
此时只需要在Hadoop的配置文件yarn-site.xml中加入以下内容即可:
<!--关闭物理内存检查-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
然后重启YARN即可。
Spark RDD概述
Spark RDD是什么
Spark提供了一种对数据的核心抽象,称为弹性分布式数据集(Resilient Distributed Dataset,简称RDD)。这个数据集的全部或部分可以缓存在内存中,并且可以在多次计算时重用。RDD其实就是一个分布在多个节点上的数据集合。
RDD的弹性主要是指:当内存不够时,数据可以持久化到磁盘,并且RDD具有高效的容错能力。
分布式数据集是指:一个数据集存储在不同的节点上,每个节点存储数据集的一部分。
例如,将数据集(hello,world,scala,spark,love,spark,happy)存储在三个节点上,节点一存储(hello,world),节点二存储(scala,spark,love),节点三存储(spark,happy),这样对三个节点的数据可以并行计算,并且三个节点的数据共同组成了一个RDD。
分布式数据集类似于HDFS中的文件分块,不同的块存储在不同的节点上;而并行计算类似于使用MapReduce读取HDFS中的数据并进行Map和Reduce操作。Spark则包含这两种功能,并且计算更加灵活。
在编程时,可以把RDD看作是一个数据操作的基本单位,而不必关心数据的分布式特性,Spark会自动将RDD的数据分发到集群的各个节点。Spark中对数据的操作主要是对RDD的操作(创建、转化、求值)。
RDD的主要特征(面试常问)
- RDD是不可变的,但可以将RDD转换成新的RDD进行操作,但是原来的RDD没有变化。
- RDD是可分区的。RDD由很多分区组成,每个分区对应一个Task任务来执行。
- 对RDD进行操作,相当于对RDD的每个分区进行操作。
- RDD拥有一系列对分区进行计算的函数,称为算子。
- RDD之间存在依赖关系,可以实现管道化,避免了中间数据的存储。
RDD的创建
RDD中的数据来源可以是程序中的对象集合,也可以是外部存储系统中的数据集,例如共享文件系统、HDFS、HBase或任何提供Hadoop InputFormat的数据源。
从对象集合创建RDD
Spark可以通过parallelize()或makeRDD()方法将一个对象集合转化为RDD。
例如,将一个List集合转化为RDD,代码如下:
val rdd=sc.parallelize(List(1,2,3,4,5,6))
或者
val rdd=sc.makeRDD(List(1,2,3,4,5,6))
从返回信息可以看出,上述创建的RDD中存储的是Int类型的数据。实际上,RDD也是一个集合,与常用的List集合不同的是,RDD集合的数据分布于多台机器上。
从外部存储创建RDD
Spark的textFile()方法可以读取本地文件系统或外部其他系统中的数据,并创建RDD。不同的是,数据的来源路径不同。
- 读取本地系统文件
# 将读取的本地文件内容转为一个RDD
val rdd = sc.textFile("file:///root/data/words.txt")
# 使用collect()方法查看RDD中的内容
rdd.collect() # 或者使用rdd.collect
注:collect()方法是RDD的一个行动算子
- 读取HDFS系统文件
# 将读取的HDFS系统文件内容转为一个RDD
val rdd = sc.textFile("hdfs://192.168.121.131:9000/words.txt")
# 使用collect()方法查看RDD中的内容
rdd.collect() # 或者使用rdd.collect
RDD算子
RDD被创建后是只读的,不允许修改。Spark提供了丰富的用于操作RDD的方法,这些方法被称为算子。一个创建完成的RDD只支持两种算子:转化(Transformation)算子和行动(Action)算子。
转化算子
转化算子负责对RDD中的数据进行计算并转化为新的RDD。Spark中的所有转化算子都是惰性的,因为它们不会立即计算结果,而只是记住对某个RDD的具体操作过程,直到遇到行动算子才会与其一起执行。
- map()算子
map()是一种转化算子,它接收一个函数作为参数,并把这个函数应用于RDD的每个元素,最后将函数的返回结果作为结果RDD中对应元素的值。
val rdd1=sc.parallelize(List(1,2,3,4,5,6))
val rdd2=rdd1.map(x => x+1)
在上述代码中,向算子map()传入了一个函数x=>x+1。其中,x为函数的参数名称。Spark会将RDD中的每个元素传入该函数的参数中。也可以将参数使用下划线“_”代替。例如以下代码:
val rdd1=sc.parallelize(List(1,2,3,4,5,6))
val rdd2=rdd1.map(_+1)
上述代码中的下划线"_"代表rdd1中的每个元素。实际上rdd1和rdd2中没有任何数据,因为parallelize()和map()都为转化算子,调用转化算子不会立即计算结果。若需要查看计算结果,则可使用行动算子collect()。
- filter()算子
filter()算子通过函数对源RDD的每个元素进行过滤,并返回一个新的RDD。
例如以下代码,过滤出rdd1中大于3的所有元素,并输出结果:
val rdd1=sc.parallelize(List(1,2,3,4,5,6))
#下面这行代码等同于:val rdd2=rdd1.filter(_>3)
val rdd2=rdd1.filter(x=>x>3)
rdd2.collect
# 也可以这样:
sc.parallelize(List(1,2,3,4,5,6)).filter(x=>x>3).collect()
- flatMap()算子
与map()算子类似,但是每个传入函数的RDD元素会返回0到多个元素,最终会将返回的所有元素合并到一个RDD。
例如以下代码,将集合List转为rdd1,然后调用rdd1的flatMap()算子将rdd1的每个元素按照空格分割成多个元素,最终合并所有元素到一个新的RDD。
val rdd1=
sc.parallelize(List("hadoop hello scala","spark hello"))
# 等同于 val rdd2 = rdd1.flatMap(x=>x.split(" "))
val rdd2=rdd1.flatMap(_.split(" "))
rdd2.collect
上述代码使用flatMap()算子的运行过程如下图所示:
- reduceByKey()算子
reduceByKey()算子的作用对象是元素为(key,value)形式(Scala元组)的RDD,使用该算子可以将key相同的元素聚集到一起,最终把所有key相同的元素合并成一个元素。该元素的key不变,value可以聚合成一个列表或者进行求和等操作。最终返回的RDD的元素类型和原有类型保持一致。
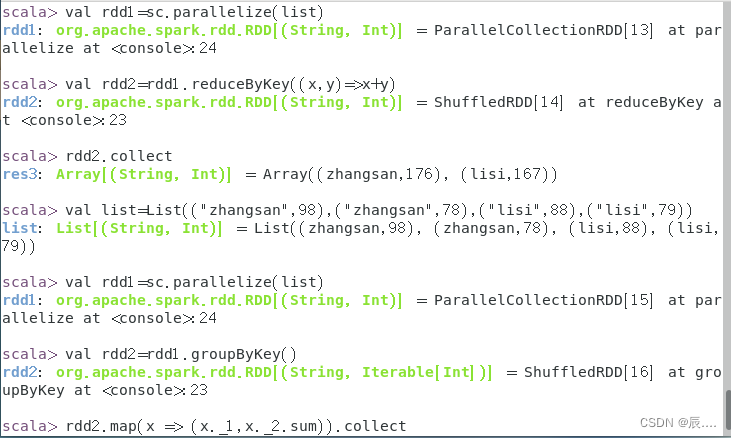
例如,有两个同学zhangsan和lisi,zhangsan的语文和数学成绩分别为98、78,lisi的语文和数学成绩分别为88、79,现需要分别求zhangsan和lisi的总成绩,代码如下:
val list=List(("zhangsan",98),("zhangsan",78),("lisi",88),("lisi",79))
val rdd1=sc.parallelize(list)
val rdd2=rdd1.reduceByKey((x,y)=>x+y)
rdd2.collect
上述代码使用了reduceByKey()算子,并传入了函数(x,y)=>x+y,其中x和y代表key相同的两个value值。该算子会寻找key相同的元素,当找到这样的元素时会对其value执行(x,y)=>x+y处理,即只保留求和后的数据作为value。
整个运行过程如图所示:
此外,上述代码中的rdd1.reduceByKey((x,y)=>x+y)可以简化为以下代码:
rdd1.reduceByKey(_+_)
- groupByKey()算子
groupByKey()算子的作用对象是元素为(key,value)形式(Scala元组)的RDD,使用该算子可以将key相同的元素聚集到一起,最终把所有key相同的元素合并成为一个元素。该元素的key不变,value则聚集到一个集合中。
仍然以上述求学生zhangsan和lisi的总成绩为例,使用groupByKey()算子的代码如下:
val list=List(("zhangsan",98),("zhangsan",78),("lisi",88),("lisi",79))
val rdd1=sc.parallelize(list)
val rdd2=rdd1.groupByKey()
rdd2.map(x => (x._1,x._2.sum)).collect
从上述代码可以看出,groupByKey()相当于reduceByKey()算子的一部分。首先使用groupByKey()算子对RDD数据进行分组后,返回了元素类型为(String, Iterable[Int])的RDD,然后对该RDD使用map()算子进行函数操作,对成绩集合进行求和。
整个运行过程如图所示:
- union()算子
union()算子将两个RDD合并为一个新的RDD,主要用于对不同的数据来源进行合并,两个RDD中的数据类型要保持一致。
例如以下代码,通过集合创建了两个RDD,然后将两个RDD合并成了一个RDD:
val rdd1=sc.parallelize(Array(1,2,3))
val rdd2=sc.parallelize(Array(4,5,6))
val rdd3=rdd1.union(rdd2)
rdd3.collect
- sortBy()算子
sortBy()算子将RDD中的元素按照某个规则进行排序。该算子的第一个参数为排序函数,第二个参数是一个布尔值,指定升序(默认)或降序。若需要降序排列,则需将第二个参数置为false。
例如,一个数组中存放了三个元组,将该数组转为RDD集合,然后对该RDD按照每个元素中的第二个值进行降序排列,代码如下:
val rdd1=sc.parallelize(Array(("hadoop",12),("java",32),("spark",22)))
val rdd2=rdd1.sortBy(x=>x._2,false)
rdd2.collect
上述代码sortBy(x=>x._2,false)中的x代表rdd1中的每个元素。由于rdd1的每个元素是一个元组,因此使用x._2取得每个元素的第二个值。当然,sortBy(x=>x.2,false)也可以直接简化为sortBy(._2,false)。
- sortByKey()算子
sortByKey()算子将(key,value)形式的RDD按照key进行排序。默认升序,若需降序排列,则可以传入参数false,代码如下:
val rdd1=sc.parallelize(Array(("hadoop",12),("java",32),("spark",22)))
val rdd2=rdd1.sortByKey(false)
rdd2.collect()
- join()算子
join()算子将两个(key,value)形式的RDD根据key进行连接操作,相当于数据库的内连接(Inner Join),只返回两个RDD都匹配的内容。例如,将rdd1和rdd2进行内连接,代码如下:
val arr1=
Array(("A","a1"),("B","b1"),("C","c1"),("D","d1"),("E","e1"))
val rdd1 = sc.parallelize(arr1)
val arr2=
Array(("A","A1"),("B","B1"),("C","C1"),("C","C2"),("C","C3"),("E","E1"))
val rdd2 = sc.parallelize(arr2)
rdd1.join(rdd2).collect
rdd2.join(rdd1).collect
上述代码使用join()算子的运行过程如图所示:
除了内连接join()算子外,RDD也支持左外连接leftOuterJoin()算子、右外连接rightOuterJoin()算子、全外连接fullOuterJoin()算子。
leftOuterJoin()算子与数据库的左外连接类似,以左边的RDD为基准(例如rdd1.leftOuterJoin(rdd2),以rdd1为基准),左边RDD的记录一定会存在。对上述rdd1和rdd2进行左外连接,代码如下:
rdd1.leftOuterJoin(rdd2).collect
rdd2.leftOuterJoin(rdd1).collect
上述代码使用leftOuterJoin()算子的运行过程如图所示:
rightOuterJoin()算子的使用方法与leftOuterJoin()算子相反,其与数据库的右外连接类似,以右边的RDD为基准(例如rdd1.rightOuterJoin(rdd2),以rdd2为基准),右边RDD的记录一定会存在。
fullOuterJoin()算子与数据库的全外连接类似,相当于对两个RDD取并集,两个RDD的记录都会存在。
对上述rdd1和rdd2进行全外连接,代码如下:
rdd1.fullOuterJoin(rdd2).collect
rdd2.fullOuterJoin(rdd1).collect
上述代码使用fullOuterJoin()算子的运行过程如图所示:
- intersection()算子
intersection()算子对两个RDD进行取交集操作,返回一个新的RDD,代码如下:
val rdd1 = sc.parallelize(1 to 5)
val rdd2 = sc.parallelize(3 to 7)
rdd1.intersection(rdd2).collect
- distinct()算子
distinct()算子对RDD中的数据进行去重操作,返回一个新的RDD,代码如下:
val rdd = sc.parallelize(List(1,2,3,3,4,2,1))
rdd.distinct.collect # 或 rdd.distinct().collect()
行动算子
Spark中的转化算子并不会马上进行运算,而是在遇到行动算子时才会执行相应的语句,触发Spark的任务调度。Spark常用的行动算子及其介绍如表所示。
- reduce()算子
将数字1~100所组成的集合转为RDD,然后对该RDD使用reduce()算子进行计算,统计RDD中所有元素值的总和,代码如下:
val rdd1 = sc.parallelize(1 to 100)
rdd1.reduce(_+_)
- count()算子
统计RDD集合中元素的数量,代码如下:
val rdd1 = sc.parallelize(1 to 100)
rdd1.count
- countByKey()算子
List集合中存储的是键值对形式的元组,使用该List集合创建一个RDD,然后对其使用countByKey()算子进行计算,代码如下:
val rdd1 = sc.parallelize(List(("zhang",87),("zhang",79),("li",90)))
rdd1.countByKey
- take(n)算子
返回集合中前5个元素组成的数组,代码如下:
val rdd1 = sc.parallelize(1 to 100)
rdd1.take(5)
各种RDD算子操作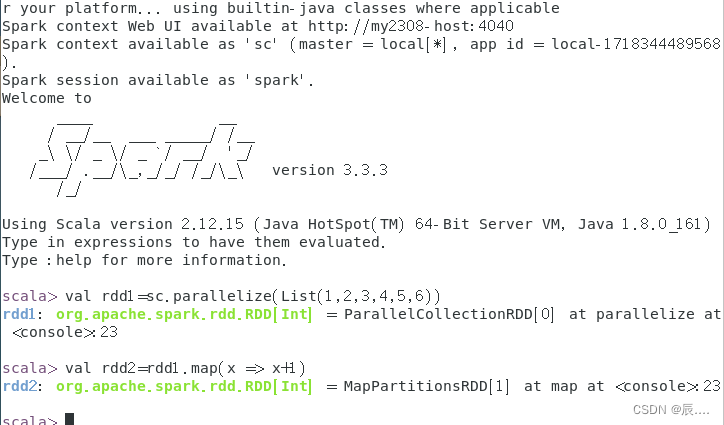








版权归原作者 辰.... 所有, 如有侵权,请联系我们删除。