
Kafka介绍
Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发并于2011年开源。它主要用于解决大规模数据的实时流式处理和数据管道问题。
Kafka是一个分布式的发布-订阅消息系统,可以快速地处理高吞吐量的数据流,并将数据实时地分发到多个消费者中。Kafka消息系统由多个broker(服务器)组成,这些broker可以在多个数据中心之间分布式部署,以提供高可用性和容错性。
Kafka的基本架构由生产者、消费者和主题(topic)组成。生产者可以将数据发布到指定的主题,而消费者可以订阅这些主题并消费其中的数据。同时,Kafka还支持数据流的处理和转换,可以在管道中通过Kafka Streams API进行流式计算,例如过滤、转换、聚合等。
Kafka使用高效的数据存储和管理技术,能够轻松地处理TB级别的数据量。其优点包括高吞吐量、低延迟、可扩展性、持久性和容错性等。
Kafka在企业级应用中被广泛应用,包括实时流处理、日志聚合、监控和数据分析等方面。同时,Kafka还可以与其他大数据工具集成,如Hadoop、Spark和Storm等,构建一个完整的数据处理生态系统。
消息队列的作用
队列是一种FIFO先进先出的数据结构。消息则是跨进程传递的数据。一个典型的MQ系统,会将消息消息由生产者发送到MQ进行排队,然后根据一定的顺序交由消息的消费者进行处理。
消息队列的优势
应用解耦
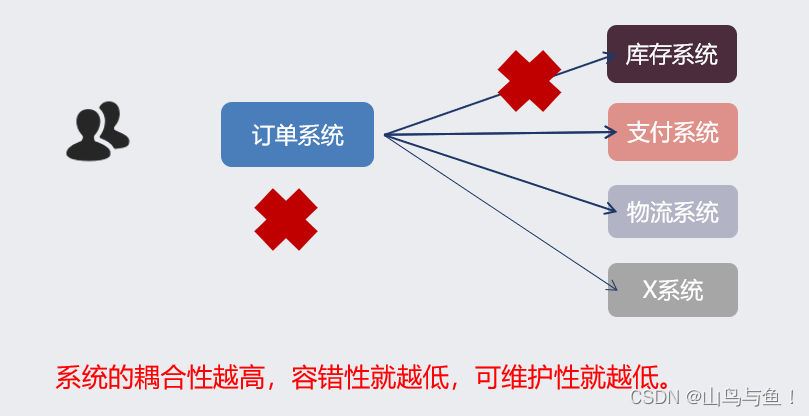
假如用户访问订单系统,而订单系统跟其他系统是强耦合的,如图如果库存系统挂了,那么整个订单系统也都不能用了。 如果这种情况还想要增加新的XX系统进来,那么就只能修改源代码来完成。系统的耦合性越高,容错性就越低,可维护性就越低。

通过引入MQ做到应用解耦,库存系统出现异常可以等库存系统恢复后去MQ中拿消息,此时不影响别的系统调用,如果还要加入新的系统比如XX系统,那么只需XX系统去MQ中拿取消息进行处理即可。使用MQ可以提升容错性和可维护性。
异步提速

原先用户请求订单系统,需要等到订单系顺序调用其他系统无误后返回,比较耗时。

现在通过引入MQ,订单系统只需要把信息发送到MQ中即可,相当于完成了之前顺序请求其他系统的步骤,时间成本大大减低。
削峰填谷

以上场景中激增请求会打垮系统,造成服务不可用。

通过将激增请求先放到MQ当前,然后系统再根据自身情况拉取请求来消费

为什么要用Kafka
Kafka产品的特点:
1、数据吞吐量很大: 需要能够快速收集各个渠道的海量数据(一般收集海量日志)。
2、集群容错性高:允许集群中少量节点崩溃。
3、功能不需要太复杂:Kafka的设计目标是高吞吐、低延迟和可扩展,主要关注消息传递而不是消息处理。所以,Kafka并没有支持死信队列、顺序消息等高级功能。
4、允许少量数据丢失:Kafka本身也在不断优化数据安全问题,目前基本上可以认为Kafka可以做到不会丢数据。
Kafka下载安装
下载地址:Apache Kafka

下载完成后解压,注意目录位置,先启动zookeeper

在启动kafka服务

一般都可以正常启动,使用默认的配置即可,如果执行命令发现报错“命令语法不正确。”请将下载的文件移到最外层目录,如上图位置。(本人遇到此问题,找寻了多种解决方案,发现这种方式才能解决我的问题。)
Kafka快速上手(单机体验)
1. 启动zookeeper服务

2. 启动kafka服务

3. 简单收发消息
Kafka的基础工作机制是消息发送者可以将消息发送到kafka上指定的topic,而消息消费者,可以从指定的topic上消费消息。

创建主题
bin\windows\kafka-topics.bat --create --topic test --bootstrap-server localhost:9092

查看主题
bin\windows\kafka-topics.bat --describe --topic test --bootstrap-server localhost:9092

**生产者往test的Topic发消息 **
bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test

消费者消费test的Topic消息
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning

这样就完成了一个基础的交互。这其中,生产者和消费者并不需要同时启动。他们之间可以进行数据交互,但是又并不依赖于对方。没有生产者,消费者依然可以正常工作,反过来,没有消费者,生产者也依然可以正常工作。这也体现出了生产者和消费者之间的解耦。
指定消费进度
如果需要精确的消费消息,可以指定从哪一条消息开始消费。
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --partition 0 --offset 2 --topic test

这表示从第0号Partition上的第二个消息开始读起。
Kakfa的消息传递机制
Kafka的消息发送者和消息消费者通过Topic这样一个逻辑概念来进行业务沟通。但是实际上,所有的消息是存在服务端的Partition这样一个数据结构当中的。
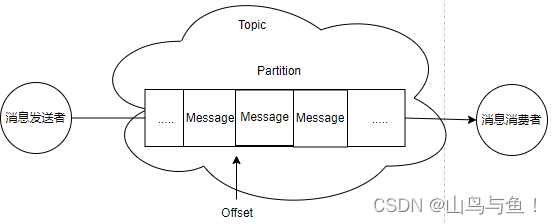
Kafka的基本概念:
客户端Client:
包括消息生产者 和 消息消费者。之前简单接触过。
消费者组:
每个消费者可以指定一个所属的消费者组,相同消费者组的消费者共同构成一个逻辑消费者组。每一个消息会被多个感兴趣的消费者组消费,但是在每一个消费者组内部,一个消息只会被消费一次。
服务端Broker:
一个Kafka服务器就是一个Broker。
话题Topic:
这是一个逻辑概念,一个Topic被认为是业务含义相同的一组消息。客户端都通过绑定Topic来生产或者消费自己感兴趣的话题。
分区Partition:
Topic只是一个逻辑概念,而Partition就是实际存储消息的组件。每个Partiton就是一个queue队列结构。所有消息以FIFO先进先出的顺序保存在这些Partition分区中。
版权归原作者 山鸟与鱼! 所有, 如有侵权,请联系我们删除。