
MySQL数据库与Redis缓存双写一致性
文章目录
问题
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
分析
先做一个说明,从理论上来说,有两种处理思维,一种需保证数据强一致性,这样性能肯定大打折扣;另外我们可以采用最终一致性,保证性能的基础上,允许一定时间内的数据不一致,但最终数据是一致的。
一致性问题是如何产生的?
对于读取过程:
- 首先,读缓存;
- 如果缓存里没有值,那就读取数据库的值;
- 同时把这个值写进缓存中。
双更新模式:操作不合理,导致数据一致性问题
我们来看下常见的一个错误编码方式:
publicvoidputValue(key,value){// 保存到redisputToRedis(key,value);// 保存到MySQLputToDB(key,value);//操作失败了}
比如我要更新一个值,首先刷了缓存,然后把数据库也更新了。但过程中,更新数据库可能会失败,发生了回滚。所以,最后“缓存里的数据”和“数据库的数据”就不一样了,也就是出现了数据一致性问题。

你或许会说:我先更新数据库,再更新缓存不就行了?
publicvoidputValue(key,value){// 保存到MySQLputToDB(key,value);// 保存到redisputToRedis(key,value);}
这依然会有问题。
考虑到下面的场景:操作 A 更新 a 的值为 1,操作 B 更新 a 的值为 2。由于数据库和 Redis 的操作,并不是原子的,它们的执行时长也不是可控制的。当两个请求的时序发生了错乱,就会发生缓存不一致的情况。
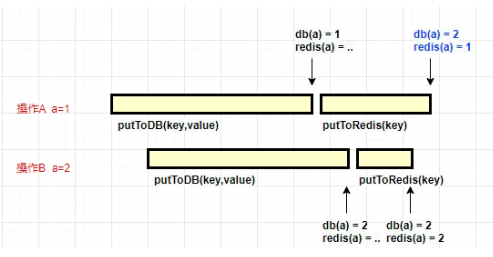
放到实操中,就如上图所示:A 操作在更新数据库成功后,再更新 Redis;但在更新 Redis 之前,另外一个更新操作 B 执行完毕。那么操作 A 的这个 Redis 更新动作,就和数据库里面的值不一样了。
那么怎么办呢?其实,我们把“缓存更新”改成“删除”就好了。
不再更新缓存,直接删除,为什么?
- 业务角度考虑
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
- 性价比角度考虑
更新缓存的代价有时候是很高的。如果频繁更新缓存,需要考虑这个缓存到底会不会被频繁访问?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
“后删缓存”能解决多数不一致
因为每次读取时,如果判断 Redis 里没有值,就会重新读取数据库,这个逻辑是没问题的。
唯一的问题是:我们是先删除缓存?还是后删除缓存?
答案是后删除缓存。
1.如果先删缓存
我们来看一下先删除缓存会有什么问题:
publicvoidputValue(key,value){// 删除redis数据deleteFromRedis(key);// 保存到数据库putToDB(key,value);}
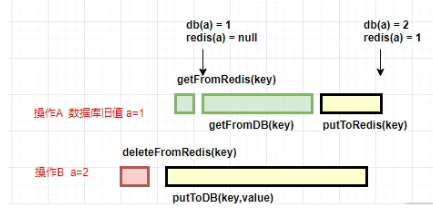
就和上面的图一样。操作 B 删除了某个 key 的值,这时候有另外一个请求 A 到来,那么它就会击穿到数据库,读取到旧的值, 然后写入redis,无论操作 B 更新数据库的操作持续多长时间,都会产生不一致的情况。
2.如果后删缓存
而把删除的动作放在后面,就能够保证每次读到的值都是最新的。
publicvoidputValue(key,value){// 保存到数据库putToDB(key,value);// 删除redis数据deleteFromRedis(key);}
这就是我们通常说的Cache-Aside Pattern,也是我们平常使用最多的模式。我们看一下它的具体方式。
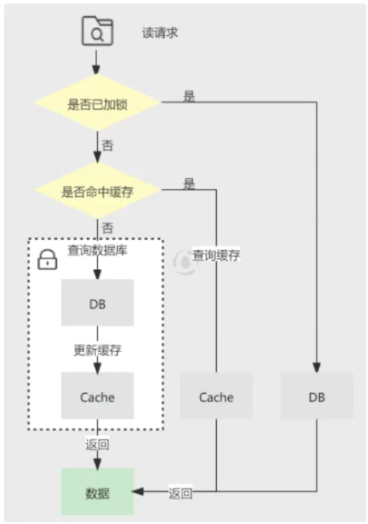
先看一下数据的读取过程,规则是“先读 cache,再读 db”,详细步骤如下:
- 每次读取数据,都从 cache 里读;
- 如果读到了,则直接返回,称作 cache hit;
- 如果读不到 cache 的数据,则从 db 里面捞一份,称作 cache miss;
- 将读取到的数据塞入到缓存中,下次读取时,就可以直接命中。
再来看一下写请求,规则是“先更新 db,再删除缓存”,详细步骤如下:
- 将变更写入到数据库中;
- 删除缓存里对应的数据。
大厂高并发,“后删缓存”依旧不一致
这种情况不存在并发问题么?不是的。假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
- 缓存刚好失效
- 请求A查询数据库,得一个旧值
- 请求B将新值写入数据库
- 请求B删除缓存
- 请求A将查到的旧值写入缓存
如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率又有多少呢?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的,因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
一般情况下,读取操作都是比写入操作快的,但我们要考虑两种极端情况:
一种是这个读取操作 A,发生在更新操作 B 的尾部。(比如写操作执行1s,读操作耗时100ms,读操作在写操作执行到800ms的时候开始执行,在写操作执行到900ms的时候结束,所以实际上读操作仅仅比写操作快了100ms而已)
一种是操作 A 的这个 Redis 的操作时长,耗费了非常多的时间。比如,这个节点正好发生了 STW。(Java中Stop-The-World机制简称STW,是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起(除了垃圾回收器之外)。Java中一种全局暂停现象,全局停顿,所有Java代码停止,native代码可以执行,但不能与JVM交互;这些现象多半是由于gc引起)
那么很容易地,读操作 A 的结束时间就超过了操作 B 删除的动作。
这种场景的出现,不仅需要缓存失效且读写并发执行,而且还需要读请求查询数据库的执行早于写请求更新数据库,同时读请求的执行完成晚于写请求。这种不一致场景产生的条件非常严格,一般业务是达不到这个量级的,所以一般公司不去处理这种情况,但高并发业务就非常常见了。
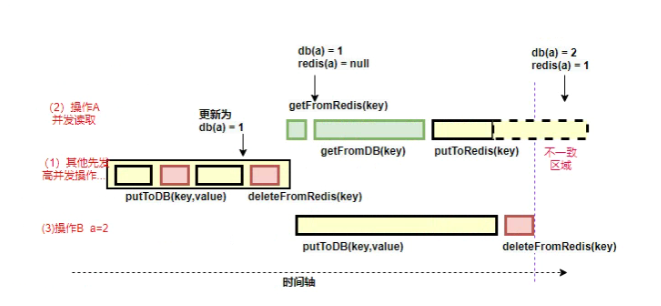
那如果是读写分离的场景下呢?如果按照如下所述的执行序列,一样会出问题:
- 请求A更新主库
- 请求A删除缓存
- 请求B查询缓存,没有命中,查询从库得到旧值
- 从库同步完毕
- 请求B将旧值写入缓存
如果数据库主从同步比较慢的话,同样会出现数据不一致的问题。事实上就是如此,毕竟我们操作的是两个系统,在高并发的场景下,我们很难去保证多个请求之间的执行顺序,或者就算做到了,也可能会在性能上付出极大的代价。
加锁?
可以采用加锁在写请求中保证“更新数据库&删除缓存”的串行执行为原子性操作(同理也可对读请求中缓存的更新加锁)。加锁势必会导致吞吐量的下降,故采取加锁的方案应该对性能的损耗有所预期。
如何解决高并发的不一致问题?
大家看上面这种不一致情况发生的场景,归根结底还是“删除操作”发生在“更新操作”之前了。
延时双删
假如我有一种机制,能够确保删除动作一定被执行,那就可以解决问题,起码能缩小数据不一致的时间窗口。
常用的方法就是延时双删,依然是先更新再删除,唯一不同的是:我们把这个删除动作,在不久之后再执行一次,比如 5 秒之后。
publicvoidputValue(key,value){putToDB(key,value);deleteFromRedis(key);// 数秒后重新执行删除操作deleteFromRedis(key,5);}
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
这种方案还算可以,只有休眠那一会,可能有脏数据,一般业务也会接受的。
其实在讨论最后一个方案时,我们没有考虑操作数据库或者操作缓存可能失败的情况,而这种情况也是客观存在的。
那么在这里我们简单讨论下,首先是如果更新数据库失败了,其实没有太大关系,因为此时数据库和缓存中都还是老数据,不存在不一致的问题。假设删除缓存失败了呢?此时确实会存在数据不一致的情况。除了设置缓存过期时间这种兜底方案之外,如果我们希望尽可能保证缓存可以被及时删除,那么我们必须要考虑对删除操作进行重试。
删除缓存重试机制
你当然可以直接在代码中对删除操作进行重试,但是要知道如果是网络原因导致的失败,立刻进行重试操作很可能也是失败的,因此在每次重试之间你可能需要等待一段时间,比如几百毫秒甚至是秒级等待。为了不影响主流程的正常运行,你可能会将这个事情交给一个异步线程来执行。
而删除动作也有多种选择:
- 如果开线程去执行,会有随着 JVM 进程的死亡,丢失更新的风险;
- 如果放在 MQ 中,会增加编码的复杂性。
所以到了这个时候,并没有一个能够行走天下的解决方案。我们得综合评价很多因素去做设计,比如团队的水平、工期、不一致的忍受程度等。
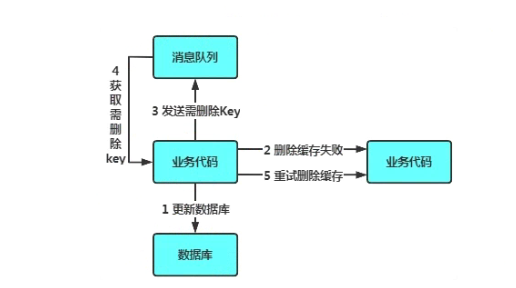
异步优化方式:消息队列
- 写请求更新数据库
- 缓存因为某些原因,删除失败
- 把删除失败的key放到消息队列
- 消费消息队列的消息,获取要删除的key
- 重试删除缓存操作
异步优化方式:基于订阅binlog的同步机制
那如果是读写分离场景呢?我们知道数据库(以Mysql为例)主从之间的数据同步是通过binlog同步来实现的,因此这里可以考虑订阅binlog(可以使用canal之类的中间件实现),提取出要删除的缓存项,然后作为消息写入消息队列,然后再由消费端进行慢慢的消费和重试。
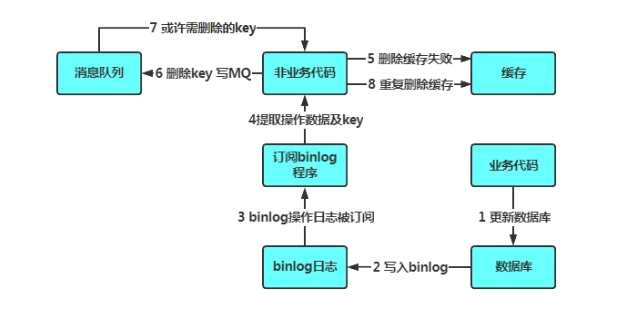
- 更新数据库数据
- 数据库会将操作信息写入binlog日志当中
- 订阅程序提取出所需要的数据以及key
- 另起一段非业务代码,获得该信息
- 尝试删除缓存操作,发现删除失败
- 将这些信息发送至消息队列
- 重新从消息队列中获得该数据,重试操作。
小结
针对 Redis 的缓存一致性问题,我们聊了很多。可以看到,无论你怎么做,一致性问题总是存在,只是几率慢慢变小了。
随着对不一致问题的忍受程度越来越低、并发量越来越高,我们所采用的方案也越来越极端。一般情况下,到了延时双删这一步,就证明你的并发量已经够大了;再往下走,无不是对高可用、成本、一致性的权衡,进入到了特事特办的场景,甚至要考虑基础设施,关于这些每个公司的策略都是不一样的。
除了 Cache-Aside Pattern,一致性常见的还有 Read-Through、Write-Through、Write-Behind 等模式,它们都有自己的应用场景,你可以再深入了解一下。
题的忍受程度越来越低、并发量越来越高,我们所采用的方案也越来越极端。一般情况下,到了延时双删这一步,就证明你的并发量已经够大了;再往下走,无不是对高可用、成本、一致性的权衡,进入到了特事特办的场景,甚至要考虑基础设施,关于这些每个公司的策略都是不一样的。
除了 Cache-Aside Pattern,一致性常见的还有 Read-Through、Write-Through、Write-Behind 等模式,它们都有自己的应用场景,你可以再深入了解一下。
如果觉得不错,记得收藏+点赞 哦~
版权归原作者 Resourceful! 所有, 如有侵权,请联系我们删除。