
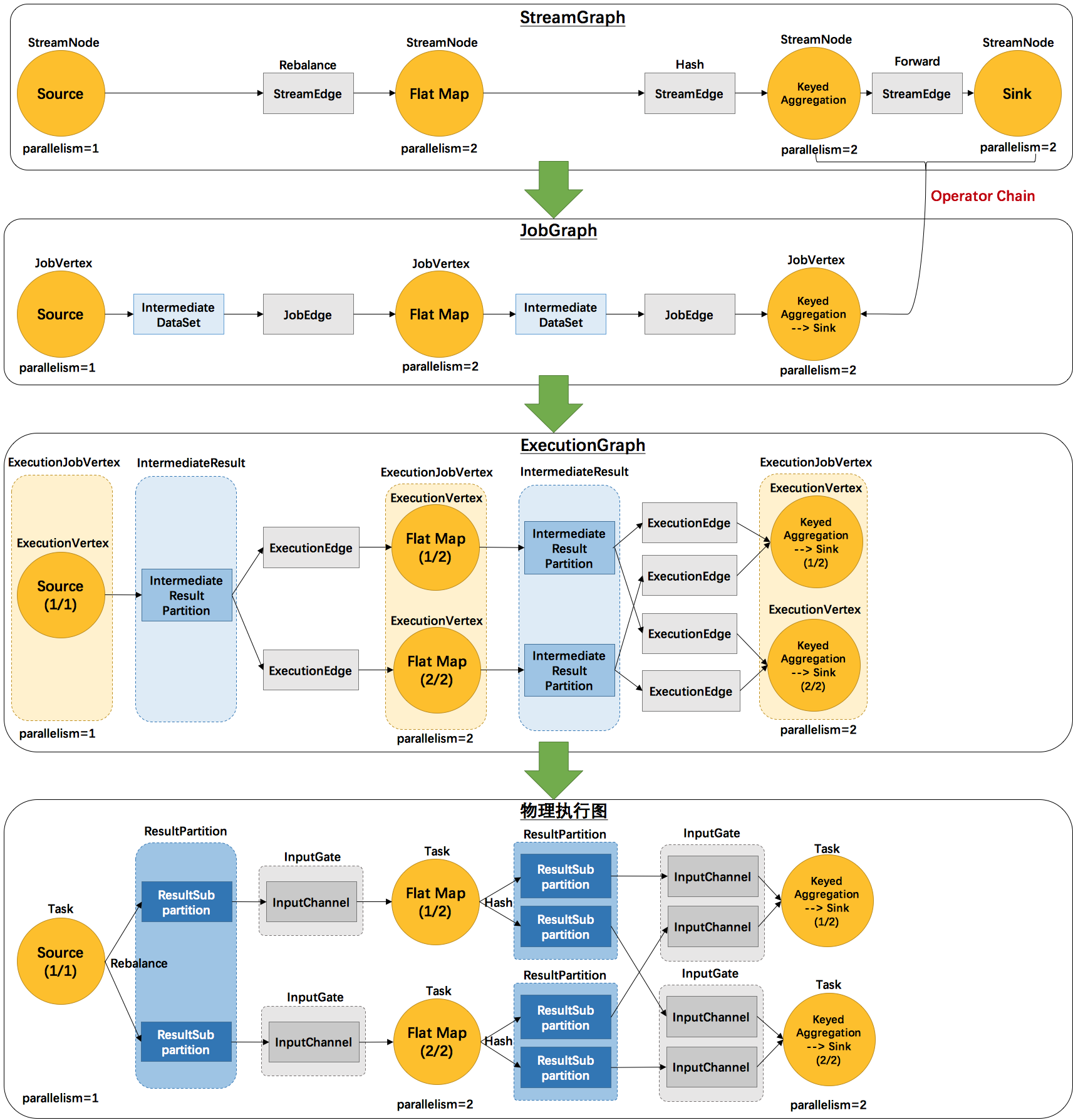
1. 核心概念
1.1. job执行流程
四层
说明
备注
SteamGraph
代码生成的最初的图
表示程序的拓扑结构
JobGraph
将多个符合条件的节点,链接为一个节点
可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗
ExecutionGraph
JobGraph的并行化版本
是调度层最核心的数据结构
PhysicalGraph
JobManager根据ExecutionGraph对Job进行调度后,在各个TaskManager上部署Task后形成的图
并不是一个具体的数据结构
- 首先,用户通过api开发的代码,会被flink任务提交客户端生成SteamGraph;
- 然后,客户端将SteamGraph加工成jobGraph****。对SteamGraph中将多个符合条件的节点,链接为一个节点;
- 然后,客户端将jobGraph提交到到集群JobManager,JobManager将其转化为ExecutionGraph(并行化后的执行图);
- 最后 ,ExecutionGraph中的各个task会以多并行示例(subTask)部署到taskManager上去执行(subTask运行的位置是taskManager提供的槽位(slot),槽位简单理解就是线程),实际运行的图就是PhysicalGraph。
1.2. task
通俗地理解,task就是一段代码逻辑。一个task中可以封装一个算子的计算逻辑,也可以封装多个算子的计算逻辑。
1.3. subTask
task的运行实例(线程),是任务调度的最小单位。
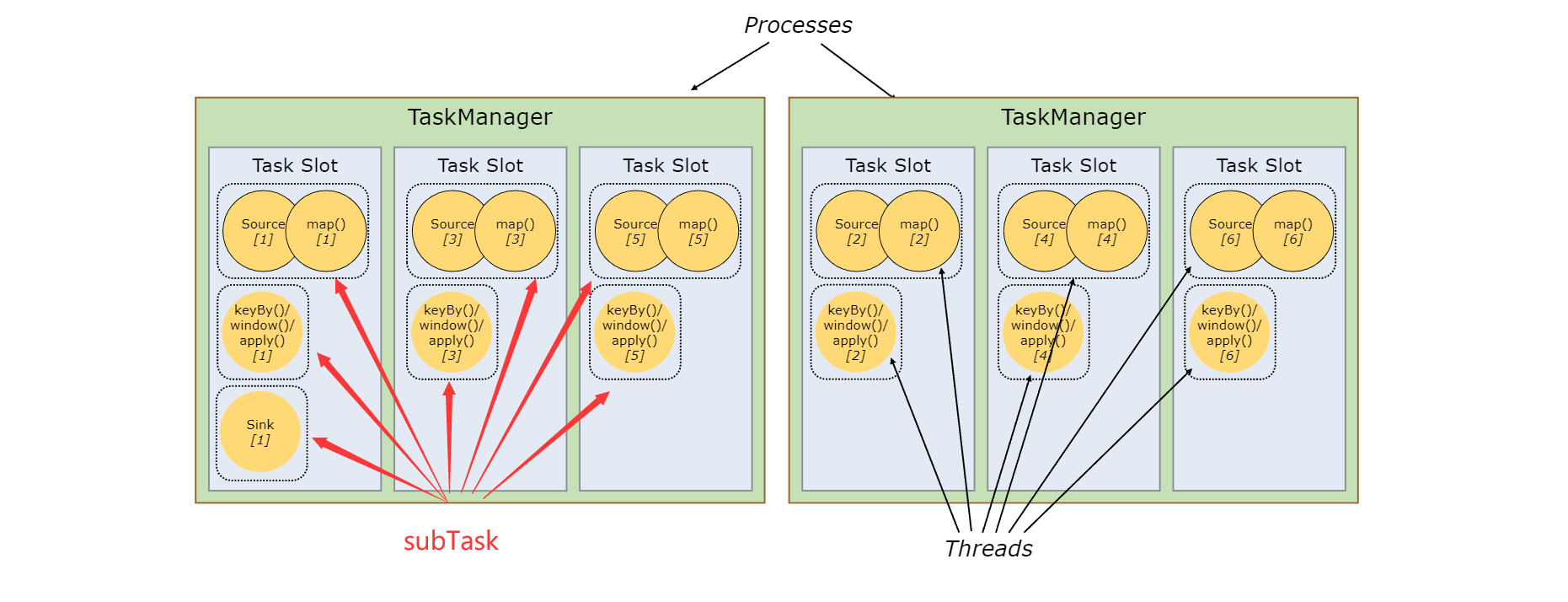
1.4. Task Slots
- 在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量;
- task slot只隔离内存,不隔离cpu。
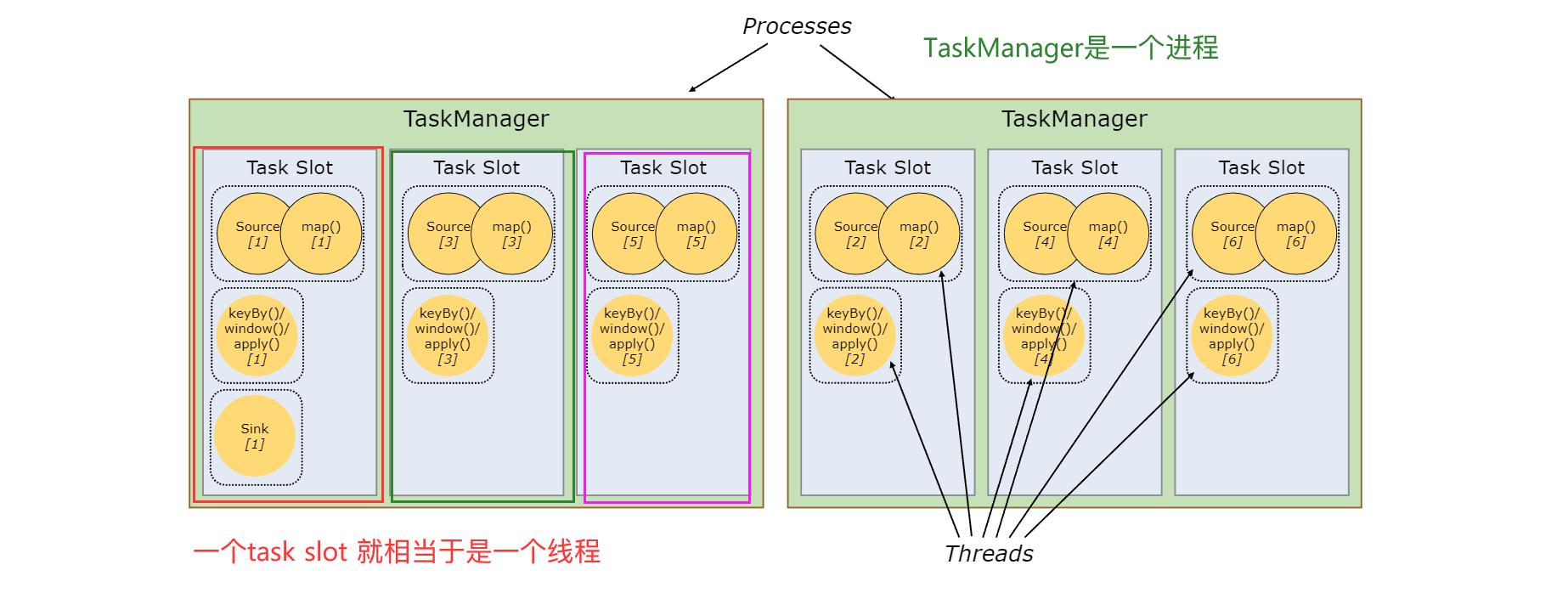
一个task slot 中可以执行多个算子,即多个算子可以被绑定到一个task中。这取决于于3个条件:
- 上下游算子是one to one 传输;- 上下游算子并行度相同;- 上下游算子属于相同的slotSharingGroup(槽位共享组)。
一个task slot 中可以运行多个不同task的各自的一个并行实例
同一个task的多个并行实例,不能放在同一个task slot中

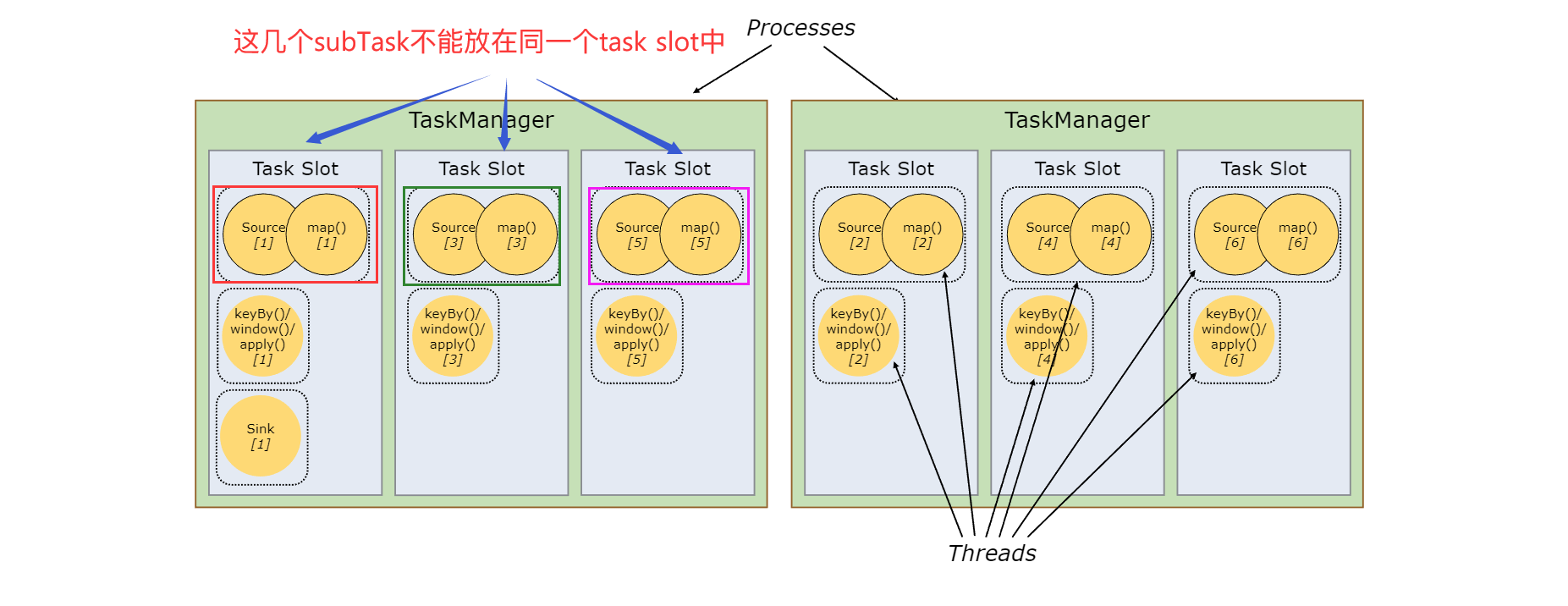
- 一个job中并行度最大的那个task的并行度 <= 可用槽位数
2. Stream API
2.1. sources
2.1.1. 自定义source
add_source()方法支持添加在java中定义的SourceFunction,实现方案如下:
- 使用java api 自定义 SourceFunction
可以定义单并行度、多并行度source
package com.siweicn.flink.test;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.types.Row;
import java.util.Random;
public class MyRichSourceFunction extends RichSourceFunction {
private static final String[] NAMES = {"Bob", "Marry", "Henry", "Mike", "Ted", "Jack"};
@Override
public void run(SourceContext sourceContext) throws Exception {
Random random = new Random();
for (int i = 0; i < NAMES.length; i++) {
Row row = Row.of(i, NAMES[i]);
sourceContext.collect(row);
}
}
@Override
public void cancel() {
}
}
- 打jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink_1.16</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.16.1</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
- 在PyFlink中引用jar包
# -*-coding:utf-8-*-
from pyflink.common import Types, Configuration
from pyflink.datastream import StreamExecutionEnvironment, SourceFunction, ProcessFunction
from pyflink.java_gateway import get_gateway
from pyflink.table import EnvironmentSettings, TableEnvironment
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
config = Configuration()
# ########################### 指定 jar 依赖 ###########################
config.set_string("pipeline.jars", "file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar;file:///F:/pycharm_projects/pyflink/jars/flink_1.16-1.0-SNAPSHOT-jar-with-dependencies.jar")
env.set_parallelism(1)
env.configure(config)
custom_source = SourceFunction("com.siweicn.flink.test.MyRichSourceFunction")
# add_source 就是来源于自定义的source from_source 就是来源于已有的source
ds = env.add_source(custom_source, type_info=Types.ROW([Types.INT(), Types.STRING()]))
ds.print()
env.execute()
2.1.2. kafka source
# -*-coding:utf-8-*-
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Row, Types
from pyflink.datastream import StreamExecutionEnvironment, TimeCharacteristic
from pyflink.datastream.connectors.jdbc import JdbcSink, JdbcConnectionOptions, JdbcExecutionOptions
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 使用kafka source需要加入kafka的jar包依赖,jdbc依赖
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///F:/pycharm_projects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///F:/pycharm_projects/pyflink/jars/mysql-connector-java-5.1.47.jar")
env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
env.set_parallelism(1)
# 构建kafka source
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.101.177:9092") \
.set_topics("pyflink-test") \
.set_group_id("pyflink") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
# 定义数据类型
type_info = Types.ROW([Types.INT(), Types.STRING()])
# 将源数据进行处理,并对数据类型做转换
map_stream = source_stream.map(lambda x: Row(int(x.split(",")[0]), x.split(",")[1]), type_info)
# 构建mysql sink
map_stream.add_sink(
JdbcSink.sink(
"insert into name_info (id, name) values (?, ?)",
type_info,
JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.with_url('jdbc:mysql://192.168.101.177:3306/pyflink?autoReconnect=true&useSSL=false')
.with_driver_name('com.mysql.jdbc.Driver')
.with_user_name('root')
.with_password('root')
.build(),
JdbcExecutionOptions.builder()
.with_batch_interval_ms(1000)
.with_batch_size(200)
.with_max_retries(5)
.build()
))
env.execute()
# -*-coding:utf-8-*-
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.formats.json import JsonRowDeserializationSchema
# 从 kafka读取数据,然后将其转成table
from pyflink.table import StreamTableEnvironment
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 使用kafka source需要加入kafka的jar包依赖
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar")
env.set_parallelism(1)
t_env = StreamTableEnvironment.create(env)
# kafka 中的数据是json格式
row_type_info = Types.ROW_NAMED(['name', 'age'], [Types.STRING(), Types.INT()])
json_format = JsonRowDeserializationSchema.builder().type_info(row_type_info).build()
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.101.177:9092") \
.set_topics("pyflink-test") \
.set_group_id("pyflink") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(json_format) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
table = t_env.from_data_stream(source_stream)
table.execute().print()
env.execute()
# -*-coding:utf-8-*-
from pyflink.common import WatermarkStrategy, Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.formats.csv import CsvRowDeserializationSchema
# 从 kafka读取数据,然后将其转成table
from pyflink.table import StreamTableEnvironment
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 使用kafka source需要加入kafka的jar包依赖
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar")
env.set_parallelism(1)
t_env = StreamTableEnvironment.create(env)
# kafka中的数据是csv的格式
row_type_info = Types.ROW_NAMED(['name', 'age'], [Types.STRING(), Types.INT()])
csv_format = CsvRowDeserializationSchema.Builder(row_type_info).build()
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.101.177:9092") \
.set_topics("pyflink-test") \
.set_group_id("pyflink") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(csv_format) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
table = t_env.from_data_stream(source_stream)
table.execute().print()
env.execute()
2.2. transformers
2.2.1. max(增量聚合算子)
测试数据
1,aa,male,4
2,bb,male,3
3,cc,male,6
4,dd,female,7
5,ff,female,4
6,gg,female,5
from pyflink.datastream import StreamExecutionEnvironment
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 设置算子并行度
env.set_parallelism(1)
file_source = env.read_text_file("../../data/transformation_max_test_data.txt")
file_source.map(lambda x: (x.split(",")[0], x.split(",")[1], x.split(",")[2], x.split(",")[3])).key_by(lambda x: x[2]).max(3).print()
env.execute()
输出结果
('1', 'aa', 'male', '4')
('1', 'aa', 'male', '4')
('1', 'aa', 'male', '6')
('4', 'dd', 'female', '7')
('4', 'dd', 'female', '7')
('4', 'dd', 'female', '7')
2.2.2. max_by(增量聚合算子)
测试数据
1,aa,male,4
2,bb,male,3
3,cc,male,6
4,dd,female,7
5,ff,female,4
6,gg,female,5
from pyflink.datastream import StreamExecutionEnvironment
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 设置算子并行度
env.set_parallelism(1)
file_source = env.read_text_file("../../data/transformation_max_test_data.txt")
file_source.map(lambda x: (x.split(",")[0], x.split(",")[1], x.split(",")[2], x.split(",")[3])).key_by(lambda x: x[2]).max_by(3).print()
env.execute()
输出结果
('1', 'aa', 'male', '4')
('1', 'aa', 'male', '4')
('3', 'cc', 'male', '6')
('4', 'dd', 'female', '7')
('4', 'dd', 'female', '7')
('4', 'dd', 'female', '7')
2.2.3. reduce(增量聚合算子)
测试数据
1,aa,male,4
2,bb,male,3
3,cc,male,6
4,dd,female,7
5,ff,female,4
6,gg,female,5
from pyflink.datastream import StreamExecutionEnvironment, ReduceFunction
class MyReduceFunction(ReduceFunction):
def reduce(self, value1, value2):
# 注意:其他字段也要输出,不然会报错
return value1[0], value1[1], value1[2], int(value1[3]) + int(value2[3])
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 设置算子并行度
env.set_parallelism(1)
file_source = env.read_text_file("../../data/transformation_max_test_data.txt")
file_source.map(lambda x: (x.split(",")[0], x.split(",")[1], x.split(",")[2], x.split(",")[3])).key_by(lambda x: x[2]).reduce(lambda a, b: (a[0], a[1], a[2], int(a[3]) + int(b[3]))).print()
# file_source.map(lambda x: (x.split(",")[0], x.split(",")[1], x.split(",")[2], x.split(",")[3])).key_by(lambda x: x[2]).reduce(MyReduceFunction()).print()
env.execute()
输出结果
('1', 'aa', 'male', '4')
('1', 'aa', 'male', 7)
('1', 'aa', 'male', 13)
('4', 'dd', 'female', '7')
('4', 'dd', 'female', 11)
('4', 'dd', 'female', 16)
2.2.4. process(底层算子)
可以用process算子实现更复杂的需求
2.3. sinks
2.3.1. FileSink
A unified sink that emits its input elements to FileSystem files within buckets.
该sink不但可以将数据写入到各种文件系统中,而且整合了checkpoint机制来保证Exactly Once语义,还可以对文件进行分桶存储(这里的分桶就是把不同时间段的数据写入不同的文件夹),还支持以列式存储的格式写入。
FileSink输出的文件,其生命周期会经历3种状态:
- in-progress Files:文件正在被写入的状态
- Pending Files:由于指定了回滚策略,in-progress Files会被关闭,等待被提交
- Finished Files:批模式下当文件已经写完,这时文件的状态就会被转换为“Finished”;流模式下成功进行了checkpoint,这时文件的状态就会被转换为“Finished”
2.3.1.1. CSV
从本地文件读取数据,然后以csv的格式将数据保存到本地文件系统。
from pyflink.common import Encoder
from pyflink.datastream import StreamExecutionEnvironment, ReduceFunction, CheckpointingMode
from pyflink.datastream.connectors.file_system import StreamingFileSink, FileSink, DefaultRollingPolicy, RollingPolicy, \
OutputFileConfig, BucketAssigner
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 设置算子并行度
env.set_parallelism(1)
file_source = env.read_text_file("../../data/transformation_max_test_data.txt")
# 设置写入文件的前缀和后缀
config = OutputFileConfig.builder().with_part_prefix("prefix").with_part_suffix(".txt").build()
# 输出为行格式
file_sink = FileSink\
.for_row_format("../../data/result", Encoder.simple_string_encoder("utf-8"))\
.with_rolling_policy(RollingPolicy.default_rolling_policy(
part_size=1024 * 1024 * 3, # 设置part文件大小,超过就回滚
rollover_interval= 6 * 1000, # 设置滚动时间间隔
inactivity_interval= 6 * 1000))\
.with_output_file_config(config)\
.build()
# 这里只能是sink_to,因为FileSink继承的是Sink,而sink_to传入的参数需要是一个Sink
file_source.sink_to(file_sink)
env.execute()
2.3.1.2. Avro
从本地文件读取数据,然后以avro的格式将数据保存到本地文件系统。
原始数据
1,e1
1,e2
1,e3
1,e4
2,e1
2,e3
3,e5
3,e2
示例代码
# -*-coding:utf-8-*-
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
from pyflink.datastream.connectors.file_system import FileSink
from pyflink.datastream.formats.avro import AvroBulkWriters, AvroSchema, GenericRecordAvroTypeInfo
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-parquet-1.16.2.jar",
"file:///F:/pycharm_projects/pyflink/jars/flink-sql-avro-1.16.2.jar")
env.set_parallelism(1)
env.set_runtime_mode(RuntimeExecutionMode.BATCH)
FILE_PATH = "../../data/test.txt"
# source_stream = env.from_collection([{'id': 1, 'event_id': 'e1'}, {'id': 1, 'event_id': 'e2'}])
source_stream = env.read_text_file(FILE_PATH).map(lambda x: {"id": int(x.split(",")[0]), "event_id": x.split(",")[1]})
# 定义数据的schema
schema = AvroSchema.parse_string("""
{ "namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "event_id", "type": "string"}
]
}
""")
avro_type_info = GenericRecordAvroTypeInfo(schema)
"""
GenericRecordAvroTypeInfo
A :class:`TypeInformation` of Avro's GenericRecord, including the schema. This is a wrapper of
Java org.apache.flink.formats.avro.typeutils.GenericRecordAvroTypeInfo.
Note that this type cannot be used as the type_info of data in
:meth:`StreamExecutionEnvironment.from_collection`.
.. versionadded::1.16.0
"""
sink = FileSink.for_bulk_format("../../data/avro", AvroBulkWriters.for_generic_record(schema=schema)).build()
source_stream.map(lambda e: e, output_type=avro_type_info).sink_to(sink)
env.execute()
GenericRecordAvroTypeInfo继承TypeInformation,是一种数据类型
原始数据
{'id': 1, 'event_id': 'e1'}
{'id': 1, 'event_id': 'e2'}
{'id': 1, 'event_id': 'e3'}
{'id': 1, 'event_id': 'e4'}
{'id': 2, 'event_id': 'e1'}
{'id': 2, 'event_id': 'e3'}
{'id': 3, 'event_id': 'e5'}
{'id': 3, 'event_id': 'e2'}
示例代码
# -*-coding:utf-8-*-
import ast
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
from pyflink.datastream.connectors.file_system import FileSink, OutputFileConfig, RollingPolicy, \
OnCheckpointRollingPolicy
from pyflink.datastream.formats.avro import AvroBulkWriters, AvroSchema, GenericRecordAvroTypeInfo
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-parquet-1.16.2.jar",
"file:///F:/pycharm_projects/pyflink/jars/flink-sql-avro-1.16.2.jar")
env.set_parallelism(1)
env.set_runtime_mode(RuntimeExecutionMode.BATCH)
FILE_PATH = "../../data/json.txt"
# 定义输出文件的前缀和后缀
config = OutputFileConfig.builder().with_part_prefix("prefix").with_part_suffix(".avro").build()
# 定义数据的schema,用于封装GenericRecordAvroTypeInfo
schema = AvroSchema.parse_string("""
{ "namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "event_id", "type": "string"}
]
}
""")
avro_type_info = GenericRecordAvroTypeInfo(schema)
"""
GenericRecordAvroTypeInfo
A :class:`TypeInformation` of Avro's GenericRecord, including the schema. This is a wrapper of
Java org.apache.flink.formats.avro.typeutils.GenericRecordAvroTypeInfo.
Note that this type cannot be used as the type_info of data in
:meth:`StreamExecutionEnvironment.from_collection`.
.. versionadded::1.16.0
"""
# source_stream = env.from_collection([{'id': 1, 'event_id': 'e1'}, {'id': 1, 'event_id': 'e2'}])
source_stream = env.read_text_file(FILE_PATH).map(lambda x: ast.literal_eval(x))
# 这里的文件滚动策略只能是OnCheckpointRollingPolicy.on_checkpoint_rolling_policy(),即在每个 Checkpoint 都会滚动。
# # 在pyflink中,AvroParquetWriters只有for_generic_record一种方法
sink = FileSink\
.for_bulk_format("../../data/avro", AvroBulkWriters.for_generic_record(schema=schema))\
.with_rolling_policy(OnCheckpointRollingPolicy.on_checkpoint_rolling_policy())\
.with_bucket_check_interval(5)\
.with_output_file_config(config)\
.build()
# 必须通过 map 操作将数据转换为GenericRecord,用于数据的序列化,才能sink
source_stream.map(lambda e: e, output_type=avro_type_info).sink_to(sink)
env.execute()
2.3.1.3. parquet
原始数据
hadoop
spark
hbase
spark
hive
hadoop
示例代码
# -*-coding:utf-8-*-
import os
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
from pyflink.datastream.connectors.file_system import FileSink, OutputFileConfig, RollingPolicy
from pyflink.datastream.formats.avro import AvroBulkWriters, AvroSchema, GenericRecordAvroTypeInfo
from pyflink.datastream.formats.parquet import ParquetBulkWriters, AvroParquetWriters
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 添加jar包,这里需要添加hadoop相关依赖
jar_directory = 'E:/PycharmProjects/pyflink/jars/lib/'
for filename in os.listdir(jar_directory):
if filename.endswith('.jar'):
env.add_jars("file:///" + jar_directory + filename)
env.set_parallelism(1)
env.set_runtime_mode(RuntimeExecutionMode.BATCH)
# 读取文件的路径
FILE_PATH = "../../data/test.csv"
# 设置输出文件的前缀和后缀
config = OutputFileConfig.builder().with_part_prefix("prefix").with_part_suffix(".parquet").build()
# 将数据处理成record的格式
source_stream = env.read_text_file(FILE_PATH).map(
lambda x: {"word": x})
# 定义数据的schema,用于封装GenericRecordAvroTypeInfo
schema = AvroSchema.parse_string("""
{ "namespace": "example.parquet",
"type": "record",
"name": "wordcount",
"fields": [
{"name": "word", "type": "string"}
]
}
""")
avro_type_info = GenericRecordAvroTypeInfo(schema)
# 这里文件的回滚策略只能是on_checkpoint_rolling_policy
# 在pyflink中,AvroParquetWriters只有for_generic_record一种方法
sink = FileSink\
.for_bulk_format("../../data/parquet", AvroParquetWriters.for_generic_record(schema=schema))\
.with_rolling_policy(RollingPolicy.on_checkpoint_rolling_policy())\
.with_output_file_config(config).build()
# 必须通过 map 操作将数据转换为GenericRecord,用于数据的序列化,才能sink
source_stream.map(lambda e: e, output_type=avro_type_info).sink_to(sink)
env.execute()
2.3.2. StreamingFileSink
Sink that emits its input elements to FileSystem files within buckets.
从本地文件读取数据,然后将数据原封不动地写回文件。
from pyflink.common import Encoder
from pyflink.datastream import StreamExecutionEnvironment, ReduceFunction, CheckpointingMode
from pyflink.datastream.connectors.file_system import StreamingFileSink, FileSink, DefaultRollingPolicy, RollingPolicy, \
OutputFileConfig, BucketAssigner
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 设置算子并行度
env.set_parallelism(1)
# 开启checkpoint
env.enable_checkpointing(5000, CheckpointingMode.EXACTLY_ONCE)
env.get_checkpoint_config().set_checkpoint_storage_dir("file:///e:/ckpt")
file_source = env.read_text_file("../../data/transformation_max_test_data.txt")
# 设置写入文件的前缀和后缀
config = OutputFileConfig.builder().with_part_prefix("prefix").with_part_suffix(".txt").build()
# *******************************方式二:流处理场景*******************************
# 输出为行格式
file_sink = StreamingFileSink.for_row_format("../../data/result", Encoder.simple_string_encoder("utf-8"))\
.with_rolling_policy(RollingPolicy.default_rolling_policy(
part_size=1024 * 1024 * 3,
rollover_interval=6 * 1000,
inactivity_interval=6 * 1000))\
.with_bucket_assigner(BucketAssigner.date_time_bucket_assigner())\
.with_bucket_check_interval(5)\
.with_output_file_config(config)\
.build()
# 这里只能是add_sink,因为file_sink继承的是SinkFunction,而add_sink传入的参数需要是一个SinkFunction
file_source.add_sink(file_sink)
env.execute()
2.3.3. KafkaSink
# -*-coding:utf-8-*-
from pyflink.common import SimpleStringSchema, RestartStrategies, Time, RestartStrategyConfiguration, TypeInformation, \
Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import DeliveryGuarantee
from pyflink.datastream.connectors.kafka import KafkaSink, KafkaRecordSerializationSchema
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar")
env.set_parallelism(1)
# 设置重启策略
env.set_restart_strategy(RestartStrategies.fixed_delay_restart(3, 10000))
# type_info=Types.STRING():python 是弱类型语言,需要指定数据的类型,这样可以提高代码运行速度
source_stream = env.from_collection(["11", "22", "33"], type_info=Types.STRING())
sink = KafkaSink.builder() \
.set_bootstrap_servers("192.168.101.222:9092") \
.set_record_serializer(
KafkaRecordSerializationSchema.builder()
.set_topic("pyflink-test")
.set_value_serialization_schema(SimpleStringSchema())
.build()
) \
.set_delivery_guarantee(DeliveryGuarantee.AT_LEAST_ONCE) \
.build()
source_stream.sink_to(sink)
env.execute()
2.3.4. JDBC Sink
2.3.4.1. at least once
from pyflink.common import Types, RestartStrategies
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode, HashMapStateBackend
from pyflink.datastream.connectors.jdbc import JdbcSink, JdbcConnectionOptions, JdbcExecutionOptions
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar", )
# 设置checkpoint的时间间隔,以及设置为对齐checkpoint
env.enable_checkpointing(1000, CheckpointingMode.EXACTLY_ONCE)
env.get_checkpoint_config().set_checkpoint_storage_dir("file:///E:/PycharmProjects/pyflink/eos_ckpt")
# 设置task级别的故障重启策略:固定重启次数为3次,每次重启的时间间隔为1000毫秒
env.set_restart_strategy(RestartStrategies.fixed_delay_restart(3, 1000))
# 设置状态后端,默认是HashMapStateBackend
env.set_state_backend(HashMapStateBackend())
# 设置算子并行度
env.set_parallelism(1)
type_info = Types.ROW([Types.INT(), Types.STRING(), Types.STRING(), Types.INT()])
# 指定数据源
data_stream = env.from_collection(
[(101, "Stream Processing with Apache Flink", "Fabian Hueske, Vasiliki Kalavri", 2019),
(102, "Streaming Systems", "Tyler Akidau, Slava Chernyak, Reuven Lax", 2018),
(103, "Designing Data-Intensive Applications", "Martin Kleppmann", 2017),
(104, "Kafka: The Definitive Guide", "Gwen Shapira, Neha Narkhede, Todd Palino", 2017)], type_info=type_info)
# 定义sink_function,不保证exactly once语义,能够保证at least once语义
jdbc_sink_function = JdbcSink.sink(
"insert into test_flink (id, title, authors, year) values (?, ?, ?, ?)",
type_info,
JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.with_url('jdbc:mysql://192.168.31.50:3306/test_flink?characterEncoding=utf8&useSSL=false')
.with_driver_name('com.mysql.jdbc.Driver')
.with_user_name('root')
.with_password('000000')
.build(),
JdbcExecutionOptions.builder()
.with_batch_interval_ms(1000)
.with_batch_size(200)
.with_max_retries(5)
.build())
# sink
data_stream.add_sink(jdbc_sink_function)
env.execute()
2.3.4.2. exactly once
更有效的精确执行一次可以通过 upsert 语句或幂等更新实现。
# -*-coding:utf-8-*-
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.jdbc import JdbcSink, JdbcConnectionOptions, JdbcExecutionOptions
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///F:/pycharm_projects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///F:/pycharm_projects/pyflink/jars/mysql-connector-java-5.1.47.jar", )
# 设置算子并行度
env.set_parallelism(1)
type_info = Types.ROW([Types.INT(), Types.STRING(), Types.STRING(), Types.INT()])
# 指定数据源
data_stream = env.from_collection(
[(101, "Stream Processing with Apache Flink", "Fabian Hueske, Vasiliki Kalavri", 2019),
(102, "Streaming Systems", "Tyler Akidau, Slava Chernyak, Reuven Lax", 2018),
(102, "Streaming Systems", "Tyler Akidau, Slava Chernyak, Reuven Lax", 2019),
(103, "Designing Data-Intensive Applications", "Martin Kleppmann", 2017),
(104, "Kafka: The Definitive Guide", "Gwen Shapira, Neha Narkhede, Todd Palino", 2017)], type_info=type_info)
# 定义sink_function,使用upsert语句来实现更有效的精确一致语义
jdbc_sink_function = JdbcSink.sink(
# "insert into books (id, title, authors, year) values (?, ?, ?, ?)",
"INSERT INTO books(id, title, authors, year) VALUES (?, ?, ?, ?) ON DUPLICATE KEY UPDATE id=VALUES(id), title=VALUES(title), authors=VALUES(authors), year=VALUES(year)",
type_info,
JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.with_url('jdbc:mysql://192.168.101.177:3306/pyflink?characterEncoding=utf8&useSSL=false')
.with_driver_name('com.mysql.jdbc.Driver')
.with_user_name('root')
.with_password('root')
.build(),
JdbcExecutionOptions.builder()
.with_batch_interval_ms(1000)
.with_batch_size(200)
.with_max_retries(5)
.build())
# sink
data_stream.add_sink(jdbc_sink_function)
env.execute()
2.4. flink多流操作
2.4.1. 广播流
2.4.1.1. 使用场景
主表关联维表数据,可以将维表数据放到广播流中。
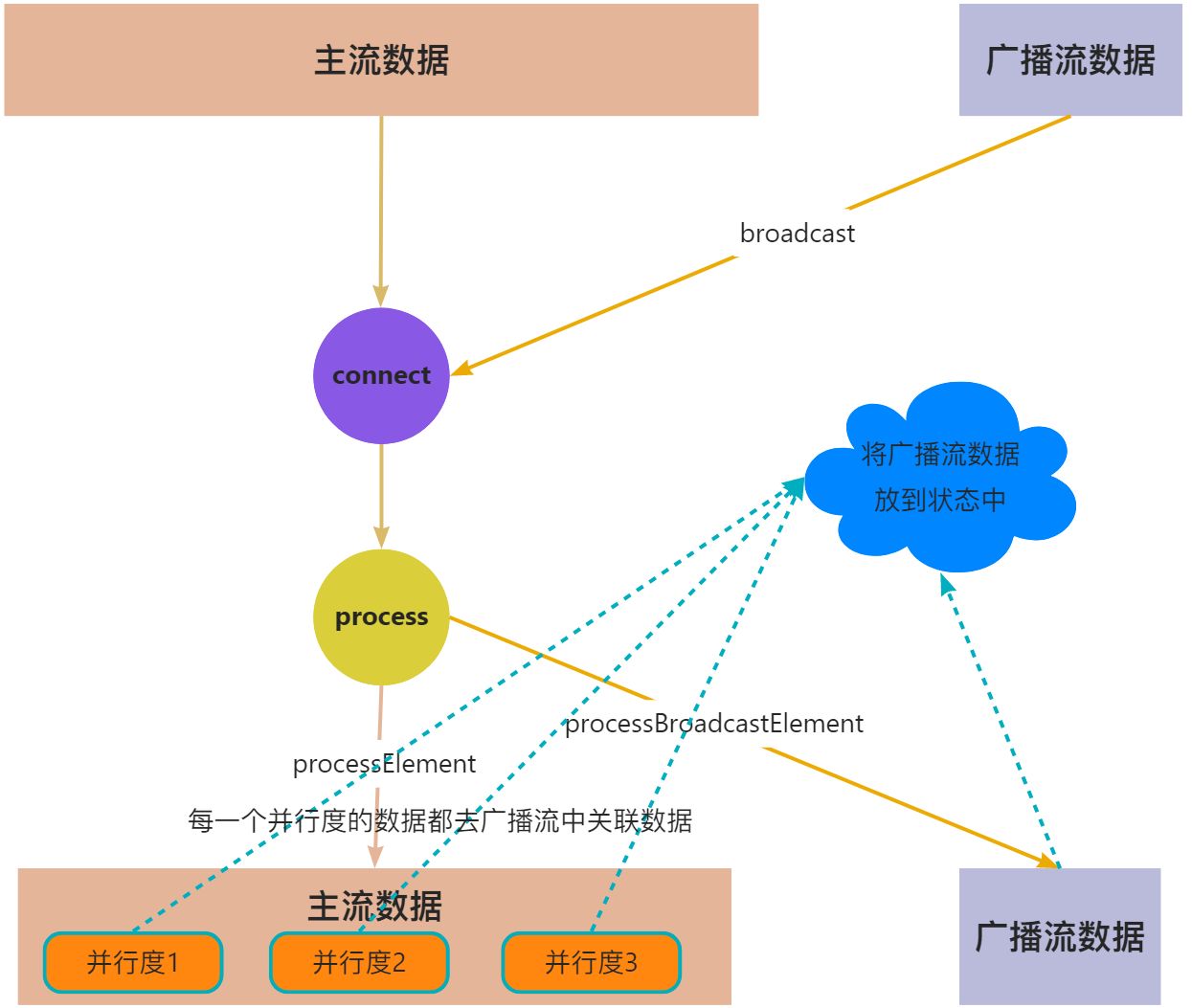
2.4.1.2. 底层原理
- 将需要广播出去的流,调用broadcast方法进行广播转换,得到广播流BroadcastStream
- 然后在主流上调用connect方法,来连接广播流(以实现广播状态的共享处理)
- 在连接流上调用process算子,就会在同一个ProcessFunction中提供两个方法分别对主流和广播流进行处理,并在这个ProcessFunction实现“广播状态”的共享
没有keyBy的情况
2.4.1.3. 示例代码
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Types
from pyflink.datastream import StreamExecutionEnvironment, TimeCharacteristic
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.functions import BroadcastProcessFunction
from pyflink.datastream.state import MapStateDescriptor
"""
broadcast算子的使用场景
用户信息表关联用户维度表,可以将维度表放到广播流中,实际上是将维度表数据放到状态中,用户信息表中的每一个分区都拥共享这份状态数据
"""
class MyBroadcastProcessFunction(BroadcastProcessFunction):
def process_element(self, value, ctx):
state = ctx.get_broadcast_state(descriptor)
if state is not None:
user_info = state.get(value[0])
yield value[0], value[1], user_info[0], user_info[1]
def process_broadcast_element(self, value, ctx):
state = ctx.get_broadcast_state(descriptor)
state.put(value[0], [value[1], value[2]])
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar")
# 主流数据来源
source1 = KafkaSource.builder() \
.set_bootstrap_servers("192.168.31.50:9092") \
.set_topics("main_stream") \
.set_group_id("my-group1") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.set_properties({"commit.offsets.on.checkpoint": "False"}) \
.set_properties({"enable.auto.commit": "False"}) \
.build()
# 广播流数据来源
source2 = KafkaSource.builder() \
.set_bootstrap_servers("192.168.31.50:9092") \
.set_topics("broadcast_stream") \
.set_group_id("my-group2") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.set_properties({"commit.offsets.on.checkpoint": "False"}) \
.set_properties({"enable.auto.commit": "False"}) \
.build()
# 主流数据
source_stream1 = env.from_source(source1, WatermarkStrategy.no_watermarks(), "Kafka Source1", type_info=Types.STRING())
# 广播流数据
source_stream2 = env.from_source(source2, WatermarkStrategy.no_watermarks(), "Kafka Source2", type_info=Types.STRING())
# 对主流数据做格式变换
map_stream1 = source_stream1.map(lambda x: (x.split(",")[0], x.split(",")[1]))
# 对广播流数据做格式变换
map_stream2 = source_stream2.map(lambda x: (x.split(",")[0], x.split(",")[1], x.split(",")[2]))
# 定义广播流状态
descriptor = MapStateDescriptor("userInfoStateDesc", Types.STRING(), Types.LIST(Types.PICKLED_BYTE_ARRAY()))
broadcast_stream = map_stream2.broadcast(descriptor)
# 连接主流数据和广播流数据,并对数据做处理
process = map_stream1.connect(broadcast_stream).process(MyBroadcastProcessFunction())
process.print()
env.execute()
2.5. watermark
2.5.1. 单并行度算子
示例代码
# -*-coding:utf-8-*-
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Row, Types
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, TimeCharacteristic, ProcessFunction
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
class MyTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, row, record_timestamp):
return row[1]
class MyProcessFunction(ProcessFunction):
def process_element(self, value, ctx: 'ProcessFunction.Context'):
wm = ctx.timer_service().current_watermark()
print("当前的数据:", value)
print("当前的watermark:", wm)
# 单并行度算子的watermark的传递机制
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 使用kafka source需要加入kafka的jar包依赖,jdbc依赖
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar")
env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
# 设置全局并行度为1
env.set_parallelism(1)
# 构建kafka source
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.31.50:9092") \
.set_topics("pyflink_test") \
.set_group_id("pyflink") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
# 定义数据类型
type_info = Types.ROW([Types.STRING(), Types.INT()])
# 将源数据进行处理,并对数据类型做转换
map_stream = source_stream.map(lambda x: Row(x.split(",")[0], int(x.split(",")[1])), type_info)
# 构建watermark生成策略
watermark_strategy = WatermarkStrategy.for_monotonous_timestamps().with_timestamp_assigner(MyTimestampAssigner())
# 将watermark应用到data stream
data_stream_wm = map_stream.assign_timestamps_and_watermarks(watermark_strategy)
# 调用process方法,拿到wm
data_stream_wm.process(MyProcessFunction()).print(
)
env.execute()
代码流程图

输出结果

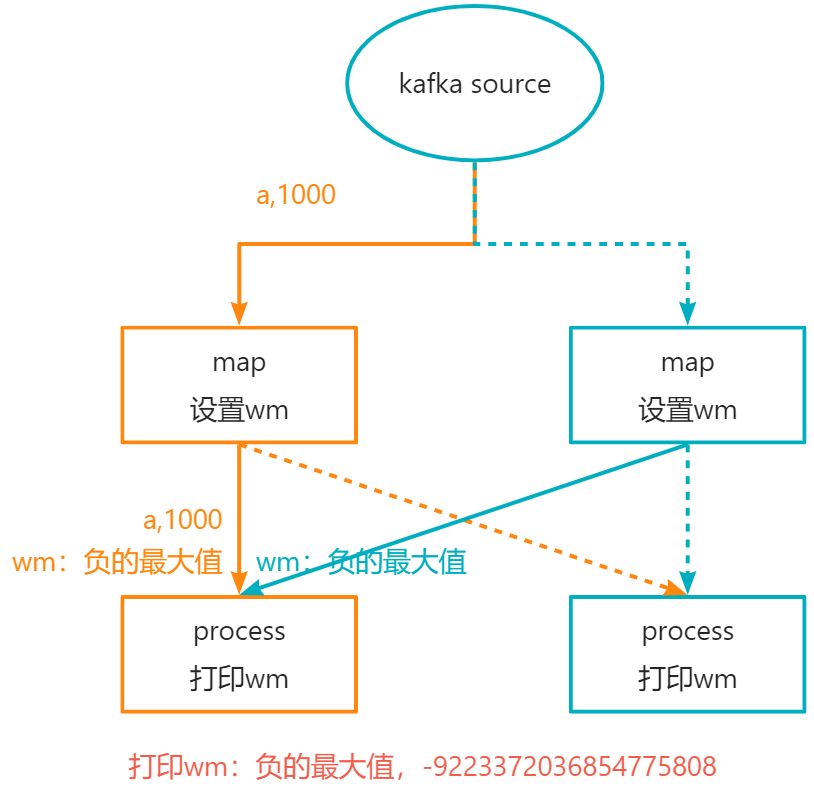
- watermark默认是每200ms更新一次
- watermark是在数据处理之后再更新,当输出第一条数据之后,此时打印的watermark是负的最大值,因为此时还没有更新watermark。
- watermark = maxTimestamp - outOfOrdernessMillis - 1。即当前的最大时间戳 - 乱序时间 - 1
2.5.2. 多并行度算子
示例代码
下面的代码是在linux系统上执行的,因为windows系统上多并行度有bug,运行不起来。
# -*-coding:utf-8-*-
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Row, Types, Configuration
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, TimeCharacteristic, ProcessFunction
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
class MyTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, row, record_timestamp):
return row[1]
class MyProcessFunction(ProcessFunction):
def process_element(self, value, ctx: 'ProcessFunction.Context'):
wm = ctx.timer_service().current_watermark()
print("当前的数据:", value)
print("当前的watermark:", wm)
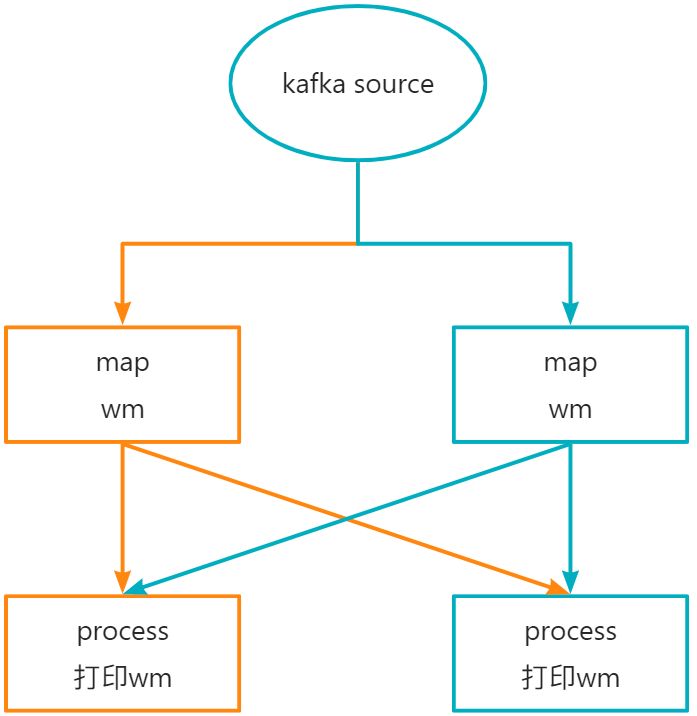
# 多并行度算子的watermark的传递机制
if __name__ == '__main__':
conf = Configuration()
conf.set_string("pipeline.jars", "file:///opt/project/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar;"
"file:///opt/project/pyflink/jars/flink-connector-jdbc-1.16.1.jar;"
"file:///opt/project/pyflink/jars/mysql-connector-java-5.1.47.jar")
env = StreamExecutionEnvironment.get_execution_environment(conf)
# 设置python解释器的路径
env.set_python_executable("/root/miniconda3/envs/pyflink_1.16/bin/python3.8")
# 为了好观测,先设置一个全局的并行度
env.set_parallelism(2)
# 构建kafka source
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.31.50:9092") \
.set_topics("pyflink_test") \
.set_group_id("pyflink") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
# 将kafka source的并行度设置为1
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source").set_parallelism(1)
# 定义数据类型
type_info = Types.ROW([Types.STRING(), Types.INT()])
# 将源数据进行处理,并对数据类型做转换,并将map算子的并行度设置为2
map_stream = source_stream.map(lambda x: Row(x.split(",")[0], int(x.split(",")[1])), type_info).set_parallelism(2)
# 构建watermark生成策略
watermark_strategy = WatermarkStrategy.for_monotonous_timestamps().with_timestamp_assigner(MyTimestampAssigner())
# 将watermark应用到data stream,将assign_timestamps_and_watermarks算子的并行度设置为2
data_stream_wm = map_stream.assign_timestamps_and_watermarks(watermark_strategy).set_parallelism(2)
# 调用process方法,拿到wm,并将process算子设置为一个新的chain,并行度设置为2
data_stream_wm.process(MyProcessFunction()).start_new_chain().set_parallelism(2)
# 打印执行计划
print(env.get_execution_plan())
env.execute()
"""
以上代码是在linux系统上运行,windows系统上以多并行度运行会报错
"""
代码流程图
测试数据
a,1000
b,2000
c,3000
d,4000
a,5000
b,6000
输出结果
当输入a,1000之后,数据的流转如下所示:
当输入b,2000之后,数据的流转如下所示:
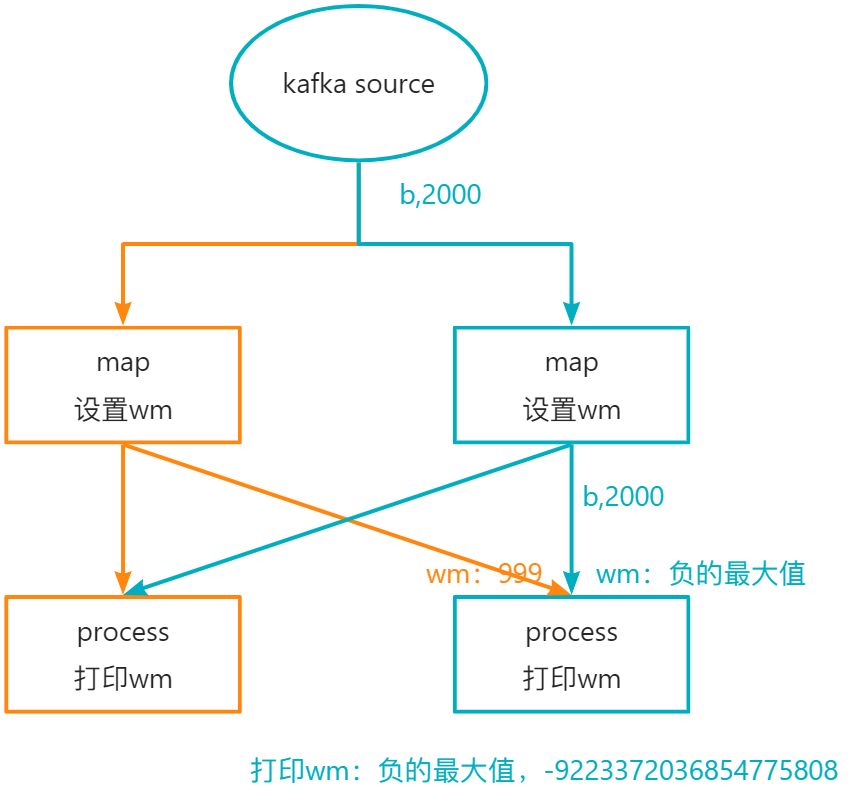
当输入c,3000之后,数据的流转如下所示:

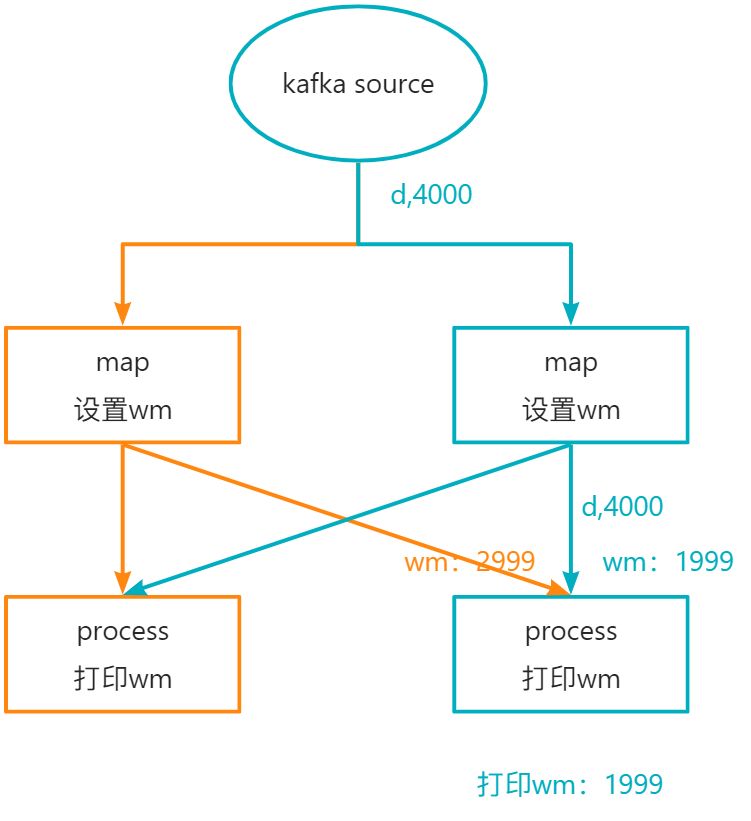
当输入d,4000之后,数据的流转如下所示:
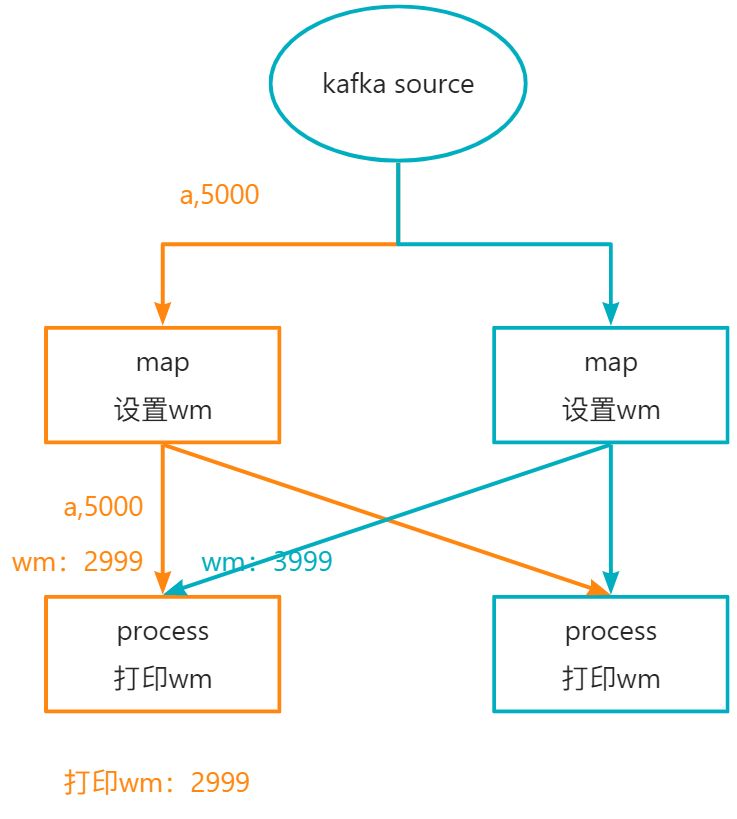
当输入a,5000之后,数据的流转如下所示:
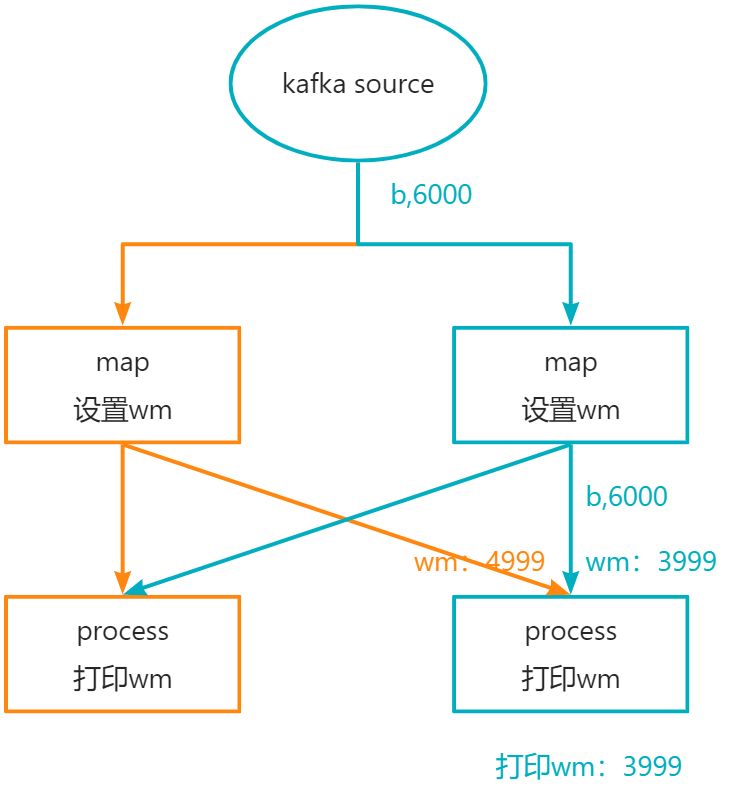
当输入b,6000之后,数据的流转如下所示:
2.5.3. watermark传递机制
以上面的多并行度算子为例,用画图的方式来解释watermark的传递机制
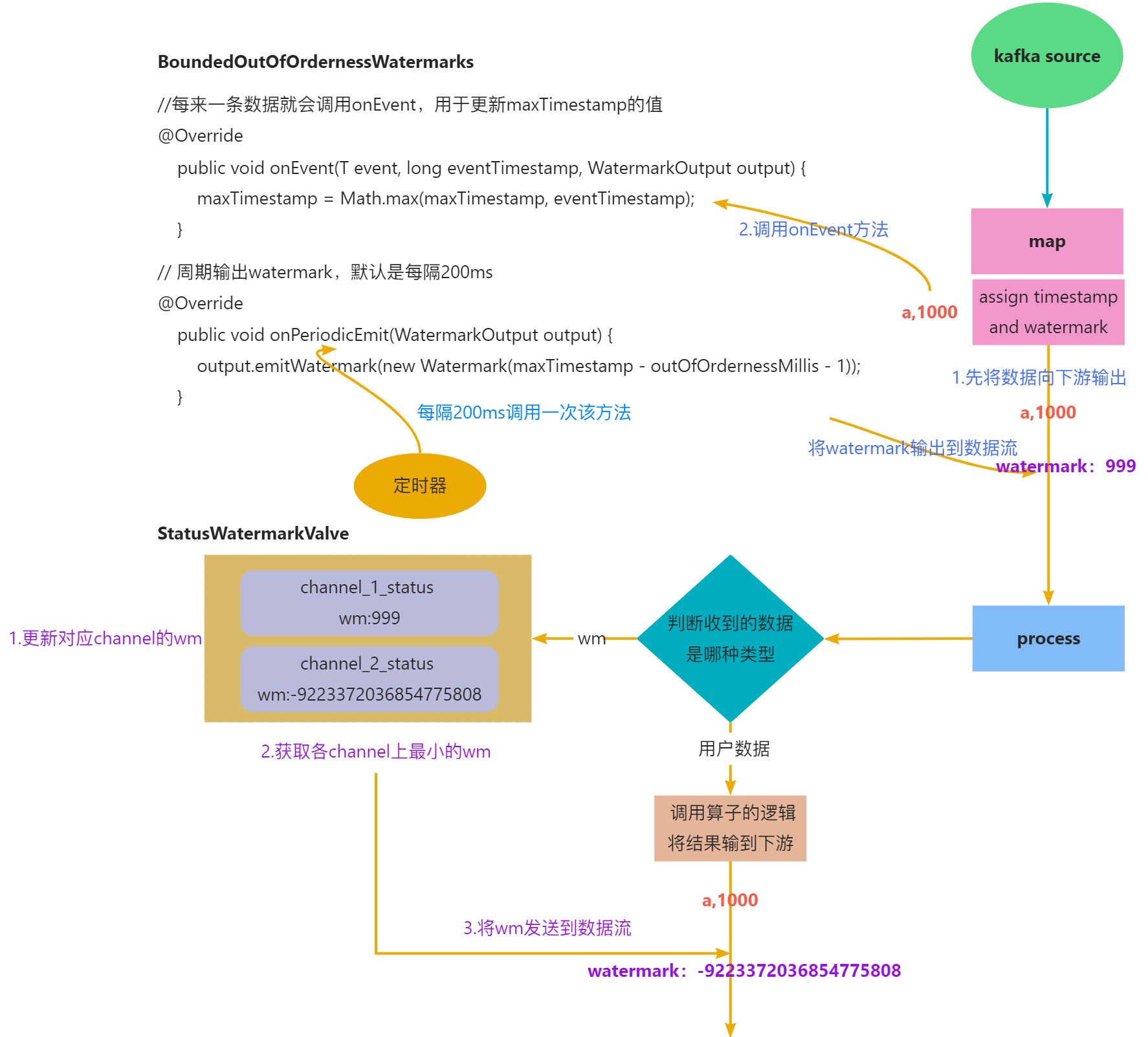
2.5.4. 事件时间语义中的watermark
- 作用:就是在事件时间语义中,用于单调递增地向前推进时间的一种标记;
- 原理:从wm源头开始,根据数据中的事件时间,在数据流中周期性地插入一种单调递增的时间戳(一种特殊数据),并向下游传递。
2.6. windows
2.6.1. sliding window
滑动窗口测试代码
# -*-coding:utf-8-*-
from typing import Iterable
import os
from pyflink.common import WatermarkStrategy, Duration, Types, Time, SimpleStringSchema, Row
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, TimeCharacteristic, AggregateFunction, ProcessWindowFunction
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.functions import KEY, IN, OUT
from pyflink.datastream.window import SlidingEventTimeWindows
# 测试滑动窗口的触发时机
"""
1,e1,1687745731000,20
1,e2,1687745733000,30
1,e3,1687745734001,40
1,e4,1687745737000,50
1,e5,1687745741000,20
1,e1,1687745742000,20
1,e2,1687745744000,30
1,e3,1687745751000,40
"""
class MyTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, row, record_timestamp):
return row[2]
class MyProcessWindowFunction(ProcessWindowFunction):
"""
在process方法中打印窗口的起始时间,窗口的结束时间,以及在该窗口内的数据
触发一个窗口就会调用一次process方法
"""
def process(self, key: KEY, context: 'ProcessWindowFunction.Context', elements: Iterable[IN]) -> Iterable[OUT]:
wm = context.current_watermark()
window_st = context.window().start
window_et = context.window().end
yield "窗口的起始时间:" + str(window_st) + ", 窗口的结束时间:" + str(window_et) + ", 数据:" + str(elements)
def main():
os.environ["JAVA_TOOL_OPTIONS"] = "-Dfile.encoding=utf-8"
env = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///F:/pycharm_projects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///F:/pycharm_projects/pyflink/jars/mysql-connector-java-5.1.47.jar")
env.set_parallelism(1)
watermark_strategy = WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_seconds(1)).with_timestamp_assigner(MyTimestampAssigner())
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.101.177:9092") \
.set_topics("pyflink-test") \
.set_group_id("pyflink") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
input_stream = env.from_source(source, watermark_strategy, "Kafka Source")
# 定义数据类型
type_info = Types.ROW([Types.INT(), Types.STRING(), Types.LONG(), Types.INT()])
# 将源数据进行处理,并对数据类型做转换
map_stream = input_stream.map(lambda x: Row(int(x.split(",")[0]), x.split(",")[1], int(x.split(",")[2]), int(x.split(",")[3])), type_info)
map_stream.print()
# 分配时间戳和wm
map_stream_with_wm = map_stream.assign_timestamps_and_watermarks(watermark_strategy)
# 处理数据
window_stream = map_stream_with_wm.key_by(lambda x: x[0])\
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(3)))\
.process(MyProcessWindowFunction())
# 输出数据
window_stream.print()
env.execute("SlidingEventTimeWindows")
if __name__ == '__main__':
main()
滑动窗口触发机制
当flink读取到一条数据之后,该条数据所属的所有的滑动窗口的开始时间和结束时间就确定好了。最后一个滑动窗口对应的开始时间和结束时间的计算公式如下:
/**
* Method to get the window start for a timestamp.
*
* @param timestamp epoch millisecond to get the window start.
* @param offset The offset which window start would be shifted by.
* @param windowSize The size of the generated windows.
* @return window start
*/
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
final long remainder = (timestamp - offset) % windowSize;
// handle both positive and negative cases
if (remainder < 0) {
return timestamp - (remainder + windowSize);
} else {
return timestamp - remainder;
}
}
对于正常情况来说,windowStartWithOffset = timestamp - (timestamp - offset) % windowSize ,其中:
- timestamp:当前数据的时间戳
- offset:窗口起始时间的偏移量
- windowSize:窗口的滑动步长
一条数据所属的滑动窗口的计算代码如下:
@Override
public Collection<TimeWindow> assignWindows(
Object element, long timestamp, WindowAssignerContext context) {
if (timestamp > Long.MIN_VALUE) {
List<TimeWindow> windows = new ArrayList<>((int) (size / slide));
long lastStart = TimeWindow.getWindowStartWithOffset(timestamp, offset, slide);
// 这里就是在计算这条数据所属的滑动窗口,有可能属于多个滑动窗口,从最后一个滑动窗口往前推
for (long start = lastStart; start > timestamp - size; start -= slide) {
windows.add(new TimeWindow(start, start + size));
}
return windows;
} else {
throw new RuntimeException(
"Record has Long.MIN_VALUE timestamp (= no timestamp marker). "
+ "Is the time characteristic set to 'ProcessingTime', or did you forget to call "
+ "'DataStream.assignTimestampsAndWatermarks(...)'?");
}
}
比如:1687745731000这个事件时间所属的滑动窗口有
- [1687745730000, 1687745733000)
- [1687745727000, 1687745737000)
- [1687745724000, 1687745734000)
滑动窗口开发案例
在pyflink中,开窗之后仅支持aggregate、reduce、process、apply(能用但已过时)四种算子
from typing import Iterable
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Types, Row, Time, Duration
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, AggregateFunction, KeyedProcessFunction, \
ProcessWindowFunction
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.functions import KEY, IN, OUT
from pyflink.datastream.window import SlidingEventTimeWindows
"""
1,e1,1687745731000,20
1,e2,1687745733000,30
1,e3,1687745734001,40
1,e4,1687745737000,50
1,e5,1687745741000,20
1,e1,1687745742000,20
1,e2,1687745744000,30
1,e3,1687745751000,40
"""
class MyTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, row, record_timestamp):
print(row)
return row[2]
class MyAggregateFunction(AggregateFunction):
def create_accumulator(self):
# 初始值设置为0
return 0
def add(self, value, accumulator):
# 滚动聚合规则
if (value[3]) > accumulator:
accumulator = value[3]
return accumulator
def get_result(self, accumulator):
# 获取最终的结果
return accumulator
def merge(self, acc_a, acc_b):
# 合并规则
if acc_a >= acc_b:
return acc_a
else:
return acc_b
class MyProcessWindowFunction(ProcessWindowFunction):
def process(self, key: KEY, context: 'ProcessWindowFunction.Context', elements: Iterable[IN]) -> Iterable[OUT]:
max_count = 0
for ele in elements:
curr_count = ele[3]
if curr_count > max_count:
max_count = curr_count
wm = context.current_watermark()
window_st = context.window().start
window_et = context.window().end
yield "窗口的起始时间:" + str(window_st) + ", 窗口的结束时间:" + str(window_et) + ", 最大行为时长:" + str(max_count)
class MyWindowFunction(WindowFunction):
def apply(self, key: KEY, window: W, inputs: Iterable[IN]) -> Iterable[OUT]:
max_count = 0
window_st = window.start
window_et = window.end
for input in inputs:
curr_count = input[3]
if curr_count > max_count:
max_count = curr_count
yield "窗口的起始时间:" + str(window_st) + ", 窗口的结束时间:" + str(window_et) + ", 最大行为时长:" + str(max_count)
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.add_jars("file:///opt/project/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///opt/project/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///opt/project/pyflink/jars/mysql-connector-java-5.1.47.jar")
env.set_python_executable("/root/miniconda3/envs/pyflink_1.16/bin/python3.8")
# 从kafka读取数据 用户id,事件id,事件时间,停留时间 1,w01,10000,10
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.31.50:9092") \
.set_topics("pyflink_test") \
.set_group_id("my-group1") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.set_properties({"commit.offsets.on.checkpoint": "False"}) \
.set_properties({"enable.auto.commit": "False"}) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
# 定义数据类型
type_info = Types.ROW([Types.INT(), Types.STRING(), Types.LONG(), Types.INT()])
# 将源数据进行处理,并对数据类型做转换
map_stream = source_stream.map(lambda x: Row(int(x.split(",")[0]), x.split(",")[1], int(x.split(",")[2]), int(x.split(",")[3])), type_info)
# 构建watermark生成策略
watermark_strategy = WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_seconds(1)).with_timestamp_assigner(MyTimestampAssigner())
# 将watermark应用到data stream
data_stream_wm = map_stream.assign_timestamps_and_watermarks(watermark_strategy)
# 需求1:每隔3秒统计最近10秒内每个用户的总访问时长
# data_stream_wm.key_by(lambda x: x[0]).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(3))).reduce(lambda a, b: Row(a[0], a[1], a[2], a[3] + b[3])).print()
# 需求2:每隔3秒统计最近10秒内每个用户的最大行为时长
# data_stream_wm.key_by(lambda x: x[0]).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(3))).process(MyProcessWindowFunction()).print()
# data_stream_wm.key_by(lambda x: x[0]).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(3))).apply(MyWindowFunction()).print()
data_stream_wm.key_by(lambda x: x[0]).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(3))).aggregate(MyAggregateFunction()).print()
env.execute()
from typing import Iterable
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Types, Row, Time, Duration
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, AggregateFunction, ProcessWindowFunction
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.functions import KEY, IN, OUT
from pyflink.datastream.window import SlidingEventTimeWindows
"""
1,e1,1687745731000,20
1,e2,1687745733000,30
1,e3,1687745734001,40
1,e4,1687745737000,50
1,e5,1687745741000,20
1,e1,1687745742000,20
1,e2,1687745744000,30
1,e3,1687745751000,40
aggregate与porcess算子相结合,使用aggregate进行增量聚合的同时,还能使用process算子获取到窗口的信息
"""
class MyTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, row, record_timestamp):
print(row)
return row[2]
class MyAggregateFunction(AggregateFunction):
def create_accumulator(self):
# 初始值设置为0
return 0
def add(self, value, accumulator):
# 滚动聚合规则
if (value[3]) > accumulator:
accumulator = value[3]
return accumulator
def get_result(self, accumulator):
# 获取最终的结果
return accumulator
def merge(self, acc_a, acc_b):
# 合并规则
if acc_a >= acc_b:
return acc_a
else:
return acc_b
class MyProcessWindowFunction(ProcessWindowFunction):
def process(self, key: KEY, context: 'ProcessWindowFunction.Context', elements: Iterable[IN]) -> Iterable[OUT]:
# 这里是已经计算好的最大值了,elements中起始只有一个元素,就是那个最大值
max = next(iter(elements))
window_st = context.window().start
window_et = context.window().end
yield "窗口的起始时间:" + str(window_st) + ", 窗口的结束时间:" + str(window_et) + ", 最大行为时长:" + str(max)
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.add_jars("file:///opt/project/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///opt/project/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///opt/project/pyflink/jars/mysql-connector-java-5.1.47.jar")
env.set_python_executable("/root/miniconda3/envs/pyflink_1.16/bin/python3.8")
# 从kafka读取数据 用户id,事件id,事件时间,停留时间 1,w01,10000,10
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.31.50:9092") \
.set_topics("pyflink_test") \
.set_group_id("my-group1") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.set_properties({"commit.offsets.on.checkpoint": "False"}) \
.set_properties({"enable.auto.commit": "False"}) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
# 定义数据类型
type_info = Types.ROW([Types.INT(), Types.STRING(), Types.LONG(), Types.INT()])
# 将源数据进行处理,并对数据类型做转换
map_stream = source_stream.map(lambda x: Row(int(x.split(",")[0]), x.split(",")[1], int(x.split(",")[2]), int(x.split(",")[3])), type_info)
# 构建watermark生成策略
watermark_strategy = WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_seconds(1)).with_timestamp_assigner(MyTimestampAssigner())
# 将watermark应用到data stream
data_stream_wm = map_stream.assign_timestamps_and_watermarks(watermark_strategy)
# 需求:每隔3秒统计最近10秒内每个用户的最大行为时长
data_stream_wm\
.key_by(lambda x: x[0])\
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(3)))\
.aggregate(MyAggregateFunction(), MyProcessWindowFunction())\
.print()
env.execute()
from typing import Iterable
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Types, Row, Time, Duration
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, AggregateFunction, ProcessWindowFunction
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.functions import KEY, IN, OUT
from pyflink.datastream.window import SlidingEventTimeWindows
"""
1,e1,1687745731000,20
1,e2,1687745733000,30
1,e3,1687745734001,40
1,e4,1687745737000,50
1,e5,1687745741000,20
1,e1,1687745742000,20
1,e2,1687745744000,30
1,e3,1687745751000,40
reduce与porcess算子相结合,使用reduce进行增量聚合的同时,还能使用process算子获取到窗口的信息
"""
class MyTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, row, record_timestamp):
return row[2]
class MyProcessWindowFunction(ProcessWindowFunction):
def process(self, key: KEY, context: 'ProcessWindowFunction.Context', elements: Iterable[IN]) -> Iterable[OUT]:
# 这里是已经计算好的最大值了,elements中起始只有一个元素,就是那个最大值
max = next(iter(elements))
window_st = context.window().start
window_et = context.window().end
yield "窗口的起始时间:" + str(window_st) + ", 窗口的结束时间:" + str(window_et) + ", 最大行为时长:" + str(max)
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.add_jars("file:///opt/project/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///opt/project/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///opt/project/pyflink/jars/mysql-connector-java-5.1.47.jar")
env.set_python_executable("/root/miniconda3/envs/pyflink_1.16/bin/python3.8")
# 从kafka读取数据 用户id,事件id,事件时间,停留时间 1,w01,10000,10
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.31.50:9092") \
.set_topics("pyflink_test") \
.set_group_id("my-group1") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.set_properties({"commit.offsets.on.checkpoint": "False"}) \
.set_properties({"enable.auto.commit": "False"}) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
# 定义数据类型
type_info = Types.ROW([Types.INT(), Types.STRING(), Types.LONG(), Types.INT()])
# 将源数据进行处理,并对数据类型做转换
map_stream = source_stream.map(lambda x: Row(int(x.split(",")[0]), x.split(",")[1], int(x.split(",")[2]), int(x.split(",")[3])), type_info)
map_stream.print()
# 构建watermark生成策略
watermark_strategy = WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_seconds(1)).with_timestamp_assigner(MyTimestampAssigner())
# 将watermark应用到data stream
data_stream_wm = map_stream.assign_timestamps_and_watermarks(watermark_strategy)
# 需求:每隔3秒统计最近10秒内每个用户的最大行为时长
data_stream_wm\
.key_by(lambda x: x[0])\
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(3)))\
.reduce(lambda a, b: b if b[3] > a[3] else a, window_function=MyProcessWindowFunction())\
.print()
env.execute()
2.6.2. tumbling window
# key_by前
stream.window_all(tumblingEventTimeWindows.of(Time.seconds(10))) # 10秒的滚动窗口
# key_by后
stream.window(tumblingEventTimeWindows.of(Time.seconds(10))
2.7. state
2.7.1. operator state
注意:****Python DataStream API 仍无法支持算子状态。
2.7.2. keyed state
key_by(...)之后可以使用keyed state
keyed state支持的状态类型
- ValueState<T>: 保存一个可以更新和检索的值,这个值可以通过 update(T) 进行更新,通过 T value() 进行检索。
- ListState<T>: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过 add(T) 或者 addAll(List<T>) 进行添加元素,通过 Iterable<T> get() 获得整个列表。还可以通过 update(List<T>) 覆盖当前的列表。ListState中的每一个元素都有一个TTL。
- ReducingState<T>: 保存一个单值,表示添加到状态的所有值的聚合。接口与 ListState 类似,但使用 add(T) 增加元素,会使用提供的 ReduceFunction 进行聚合。
- AggregatingState<IN, OUT>: 保留一个单值,表示添加到状态的所有值的聚合。和 ReducingState 相反的是, 聚合类型可能与 添加到状态的元素的类型不同。 接口与 ListState 类似,但使用 add(IN) 添加的元素会用指定的 AggregateFunction 进行聚合。
- MapState<UK, UV>: 维护了一个映射列表。 你可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用 put(UK,UV) 或者 putAll(Map<UK,UV>) 添加映射。 使用 get(UK) 检索特定 key。 使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图。你还可以通过 isEmpty() 来判断是否包含任何键值对。MapState中的每一个元素都有一个TTL。
TTL
TTL的使用说明
- 任何类型的** keyed state** 都可以有有效期 (TTL)。在使用状态 TTL 前,需要先构建一个StateTtlConfig 配置对象。 然后把配置传递到 state descriptor 中启用 TTL 功能。
- 暂时只支持基于 processing time 的 TTL。意思是说状态的过期时间是采用现实中的时间来算的,即如果定义了一个1小时的过期时间,那么就是从当前时间算起,一个小时之后状态会过期。而不是根据数据中的事件时间来往后推一个小时。
- 在窗口计算中,一般不需要显式指定状态数据的TTL,flink会在窗口触发后,自动清理相关的状态数据。
TTL的更新策略
- StateTtlConfig.UpdateType.OnCreateAndWrite - 仅在创建和写入时更新
- StateTtlConfig.UpdateType.OnReadAndWrite - 读取时也更新
注意: 如果在设置TTL的更新策略为StateTtlConfig.UpdateType.OnReadAndWrite 的同时将状态的可见性配置为 StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp, 那么在PyFlink作业中,状态的读缓存将会失效,这将导致一部分的性能损失)数据在过期但还未被清理时的可见性配置如下(默认为 NeverReturnExpired)。
过期数据的可见性
- StateTtlConfig.StateVisibility.NeverReturnExpired - 不返回过期数据
- StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp - 会返回过期但未清理的数据
过期数据的清理策略
cleanup_incrementally - 增量数据清理(默认的清理策略)
- 如果没有 state 访问,也没有处理数据,则不会清理过期数据。- 增量清理会增加数据处理的耗时。- 现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。- 如果 Heap state backend 使用同步快照方式,则会保存一份所有 key 的拷贝,从而防止并发修改问题,因此会增加内存的使用。但异步快照则没有这个问题。- 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后。
清理原理图如下:

- cleanup_full_snapshot - 全量快照清理,即在进行checkpoint的时候进行清理
- cleanup_in_rocksdb_compact_filter - 在RocksDB 压缩时清理
from pyflink.common import SimpleStringSchema, WatermarkStrategy, Types, Row, Time, Duration
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, KeyedProcessFunction, RuntimeContext, RuntimeExecutionMode, \
TimeCharacteristic
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.state import ListStateDescriptor, StateTtlConfig
"""
输入数据
1,e1,1687745731000,20
1,e2,1687745733000,30
1,e3,1687745734001,40
1,e4,1687745737000,50
2,e5,1687745741000,20
2,e1,1687745742000,20
2,e2,1687745744000,30
2,e3,1687745751000,40
输出结果
20
50
90
140
20
40
70
110
"""
class MyTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, row, record_timestamp):
return row[2]
class MyKeyedProcessFunction(KeyedProcessFunction):
def __init__(self):
self.state = None
def open(self, runtime_context: RuntimeContext):
# 通过open方法拿到状态
descriptor = ListStateDescriptor("mystate", Types.INT())
"""
ttl的相关配置
- Time.seconds(4):指定状态的过期时间
- set_update_type:如果两种过期时间的更新策略都配置了,后面设置的策略会覆盖掉前面设置的策略
- set_state_visibility:如果两种过期数据可见性策略都设置了,后面设置的策略会覆盖掉前面设置的策略
- cleanup_incrementally 是在访问状态数据的时候就去检查是否有状态数据过期
- cleanup_full_snapshot 是在进行checkpoint的时候,对过期的状态进行过滤,只存储未过期的状态数据
- cleanup_in_rocksdb_compact_filter 这种过期状态数据清除策略只适用于RocksDBStateBackend
上面三种策略如果都设置了,不是覆盖,而是添加,只是不同的策略会在不同的情况下才生效
如果都没指定,默认是cleanup_incrementally策略,且cleanup_size参数的值是5,表示每次随机检查5个key的状态数据;
run_cleanup_for_every_record参数的值是False,表示每次访问不都把状态数据全部检查一遍,然后对过期的数据进行清理
"""
ttl_config = StateTtlConfig \
.new_builder(Time.seconds(4)) \
.set_update_type(StateTtlConfig.UpdateType.OnCreateAndWrite)\
.set_update_type(StateTtlConfig.UpdateType.OnReadAndWrite)\
.set_state_visibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp) \
.set_state_visibility(StateTtlConfig.StateVisibility.NeverReturnExpired)\
.cleanup_in_rocksdb_compact_filter()\
.cleanup_incrementally() \
.cleanup_full_snapshot() \
.build()
descriptor.enable_time_to_live(ttl_config)
self.state = runtime_context.get_list_state(descriptor)
# get_list_state方法是根据name去获取状态的,即使是每次创建一个ListStateDescriptor对象,也不影响获取状态
# self.state = runtime_context.get_list_state(ListStateDescriptor("mystate", Types.INT()))
def process_element(self, value, ctx: 'KeyedProcessFunction.Context'):
self.state.add(value[3])
out = 0
list_state = self.state.get()
for s in list_state:
out += s
yield out
# keyed state的用法
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.add_jars("file:///opt/project/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///opt/project/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///opt/project/pyflink/jars/mysql-connector-java-5.1.47.jar")
env.set_python_executable("/root/miniconda3/envs/pyflink_1.16/bin/python3.8")
# 从kafka读取数据 用户id,事件id,事件时间,停留时间 1,w01,10000,10
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.31.50:9092") \
.set_topics("pyflink_test") \
.set_group_id("my-group1") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.set_properties({"commit.offsets.on.checkpoint": "False"}) \
.set_properties({"enable.auto.commit": "False"}) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
# 定义数据类型
type_info = Types.ROW([Types.INT(), Types.STRING(), Types.LONG(), Types.INT()])
# 将源数据进行处理,并对数据类型做转换
map_stream = source_stream.map(lambda x: Row(int(x.split(",")[0]), x.split(",")[1], int(x.split(",")[2]), int(x.split(",")[3])), type_info)
# 构建watermark生成策略
watermark_strategy = WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_seconds(0)).with_timestamp_assigner(MyTimestampAssigner())
# 将watermark应用到data stream
data_stream_wm = map_stream.assign_timestamps_and_watermarks(watermark_strategy)
# key by 之后使用状态
map_stream.key_by(lambda x: x[0]).process(MyKeyedProcessFunction()).print()
env.execute()
2.7.3. state backend
状态数据怎么存?存在哪?在进行checkpoint将状态数据保存到hdfs是以什么样的格式存储?都是状态后端来决定的。
HashMapStateBackend(默认的状态后端)
- 状态是存储在堆内存中,如果内存中放不下,再溢出到磁盘中
- 状态中的数据是以对象的形式存在
- 支持大规模的状态数据
RocksDBStateBackend
- 状态是存储在RocksDB(一种嵌入式数据库)中,本地磁盘(tmp dir)
- 状态中的数据是以序列化的kv字节形式存储
- RocksDB的磁盘文件数据读写速度相对还是较快的,所以在支持超大规模状态数据时,数据的读写效率不会有太大的降低
注意:上述两种状态后端在生成checkpoint快照文件时,生成的文件格式是完全一致的。所以,当用户的flink程序在更改状态后端后,重启时依然可以加载和恢复此前的状态。
2.8. checkpoint
概述
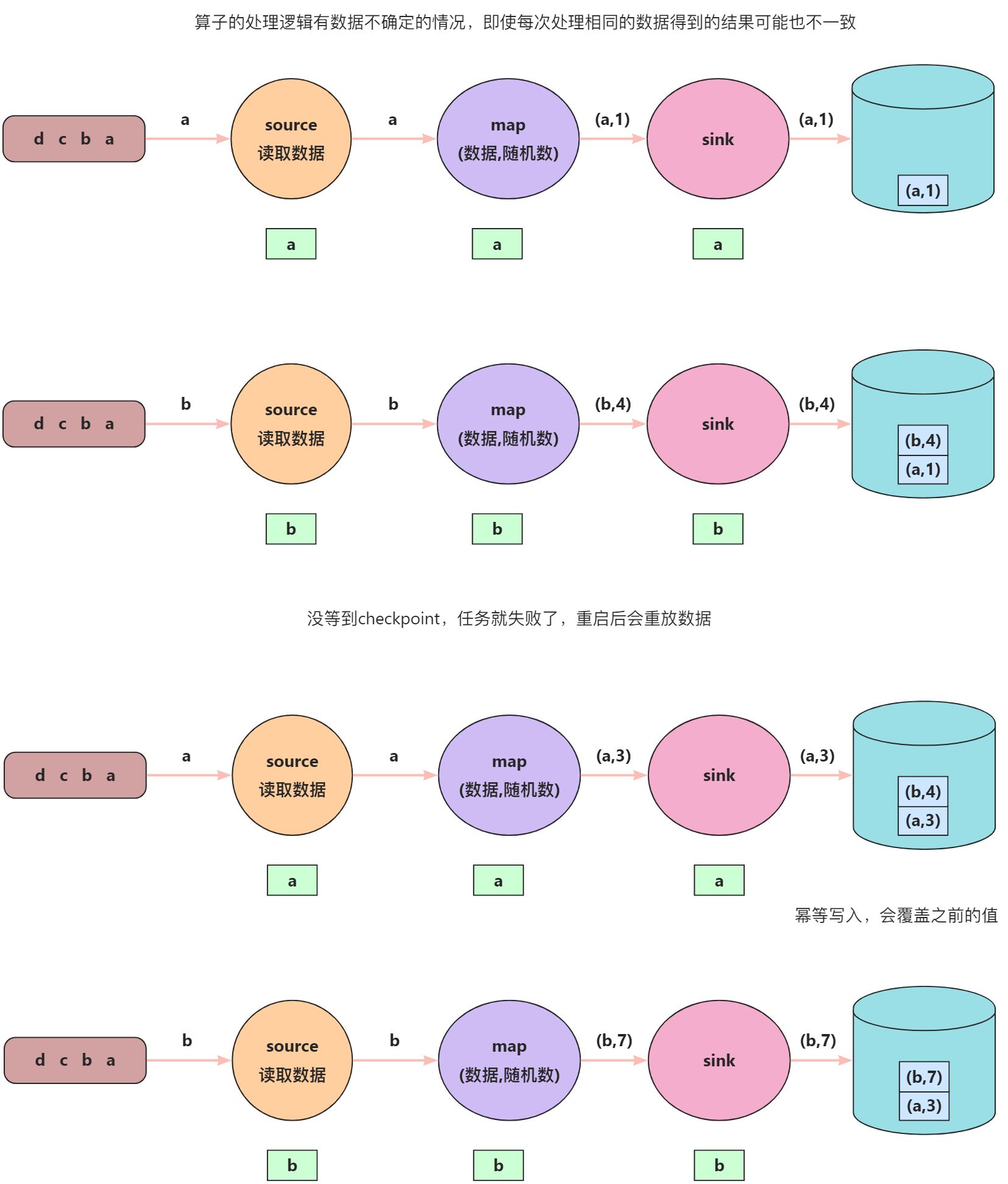
Checkpoint (状态快照)使 Flink 的状态具有良好的容错性,通过 checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。
正常数据处理过程
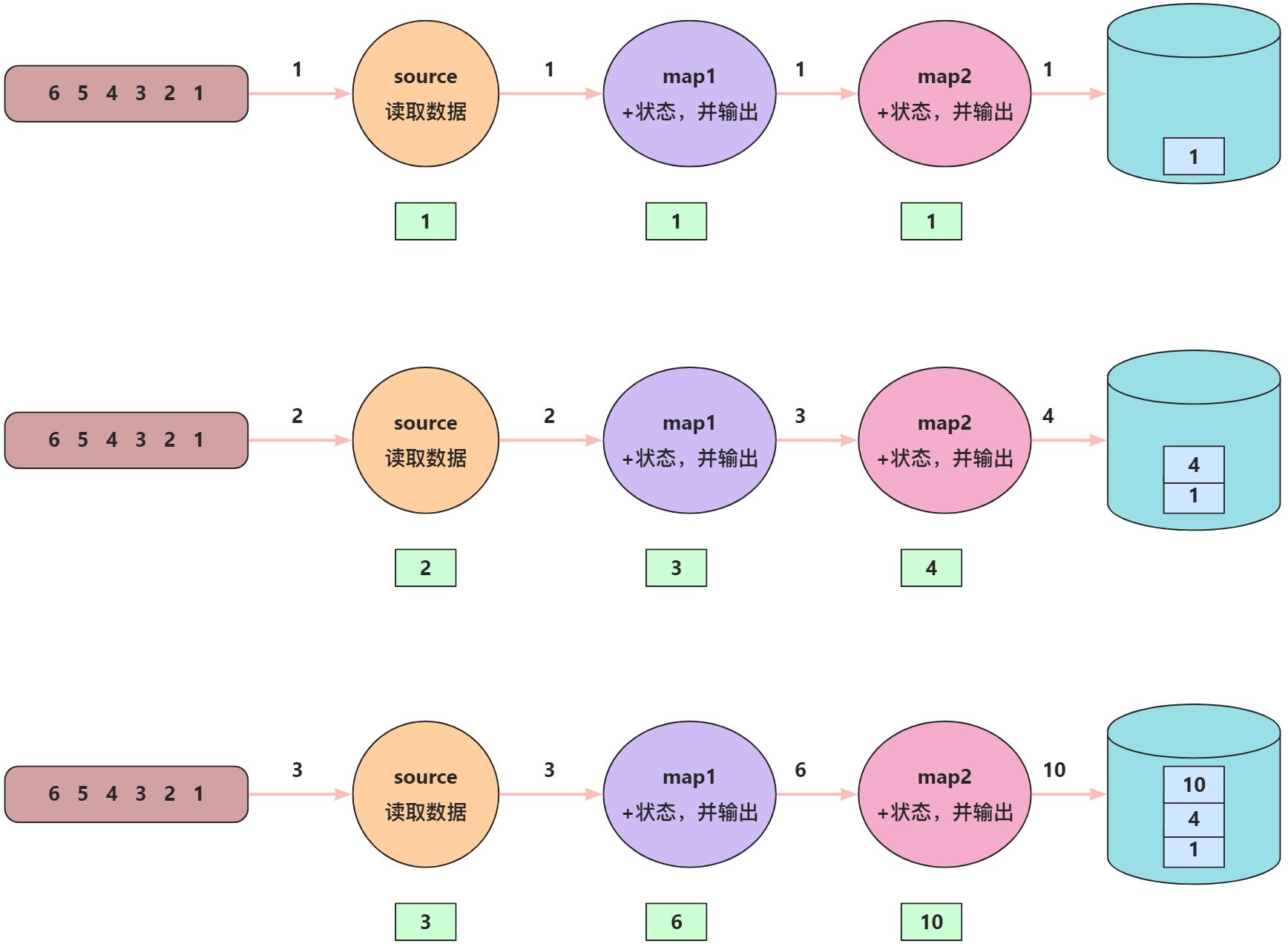
当source算子读取到“1”这条数据时,source算子会在状态中保存好该条数据的偏移量,然后向下传递数据,map1算子接收到“1”之后会执行map1算子中的逻辑,将计算好之后的结果保存在状态中,然后继续向下传递数据,map2接收到map1算子的输出之后会执行map2算子中的逻辑,将计算好之后的结果保存在状态中,最后将计算结果保存到数据库。后面数据的处理逻辑也是一样的。
上面是正常情况下数据的流转过程,如果中间某个过程发生故障了,等重启之后,继续处理数据,如何能保证数据能够被精确处理一次呢?
数据处理异常情况
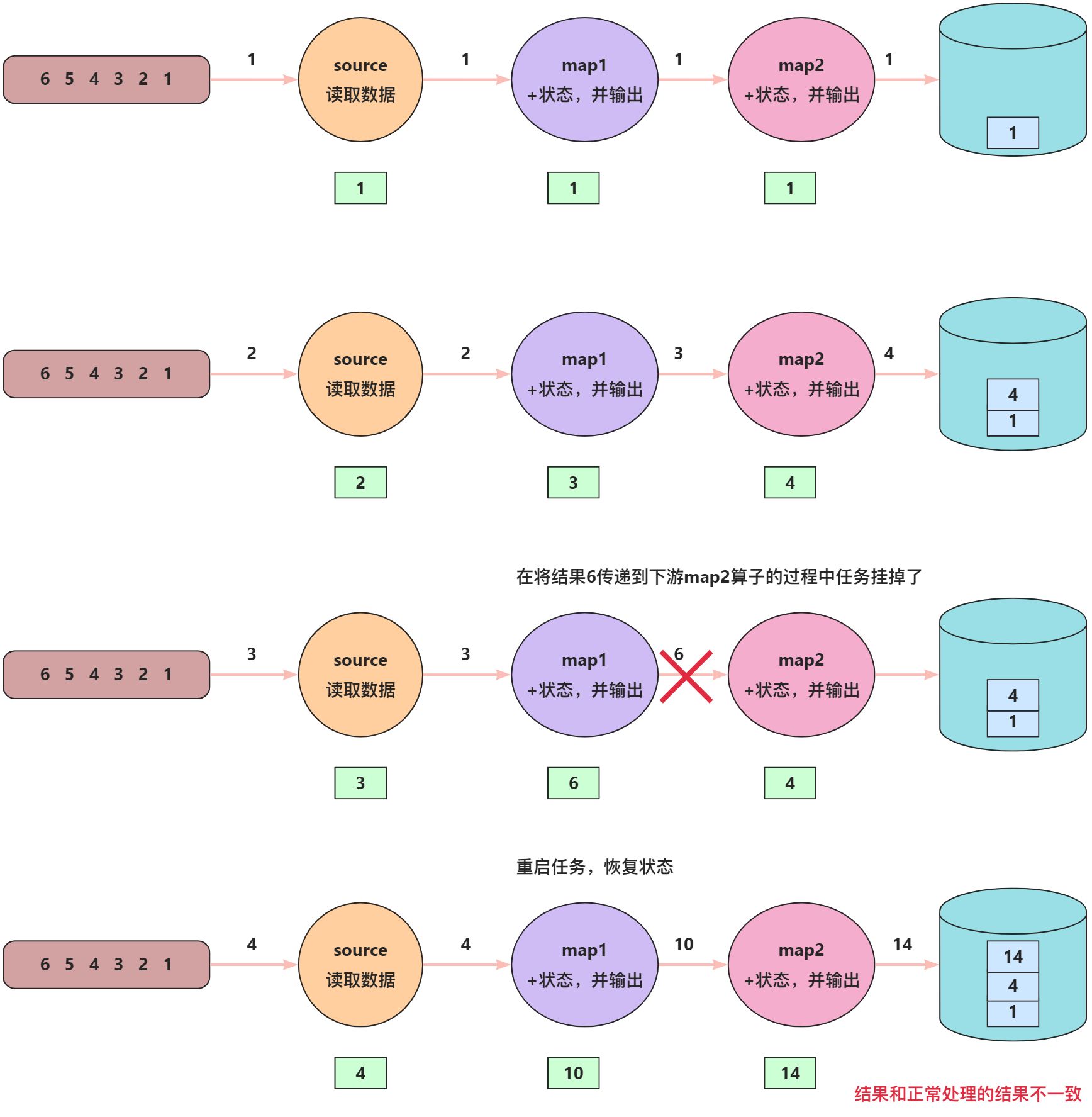
任务重启之后计算结果同正常情况不一致的原因在于:source算子保存的状态是3,表示“3”这条数据我已经处理过了,我应该从“4”开始读取,然后向下传递数据,map1算子中保存的状态值为6,经过map1的处理逻辑后,向下传递数据,map2中保存的状态值为4,经过map2的处理逻辑后,将结果保存为到数据库。
为了保证任务重启之后数据处理的正确性,需要引入checkpoint barrier。
底层逻辑
通过在数据流中插入序号单调递增的barrier,把无界流数据划分成逻辑上的数据段,当所有算子都处理完同一条数据段,并成功进行checkpoint,当前轮的checkpoint才算成功。
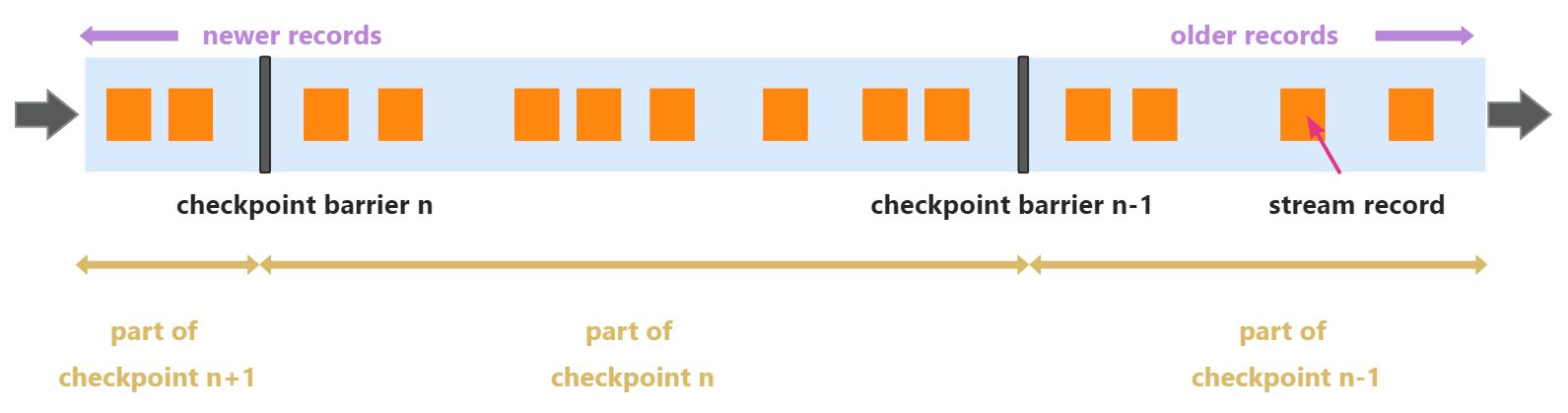
详细流程
- JobManager即CheckpointCoordinator会定期向source算子的每个subTask发送 start checkpoint的命令;
- 当source算的每个subTask收到trigger checkpoint指令后,产生barrier并通过广播的方式发送到下游。source算的每个subTask同时会执行本地checkpoint n,当checkpoint n完成后,向JobManager发送ack;
- 当所有的算子都完成checkpoint n,JobManager会收到所有节点的ack,那么就表示当前轮的checkpoint完成。
2.9. eos
端到端一致性
2.9.1. source端容错机制
source端必须可以重放数据
2.9.2. sink端容错机制
sink端必须是事务的(或者幂等的)
幂等写入
幂等写入的方式能实现最终一致,但有可能存在“过程中的不一致”。
kafka sink 是不支持幂等写入的;但是,在Kafka内部,producer和broker之间是支持幂等写入的。如何理解?
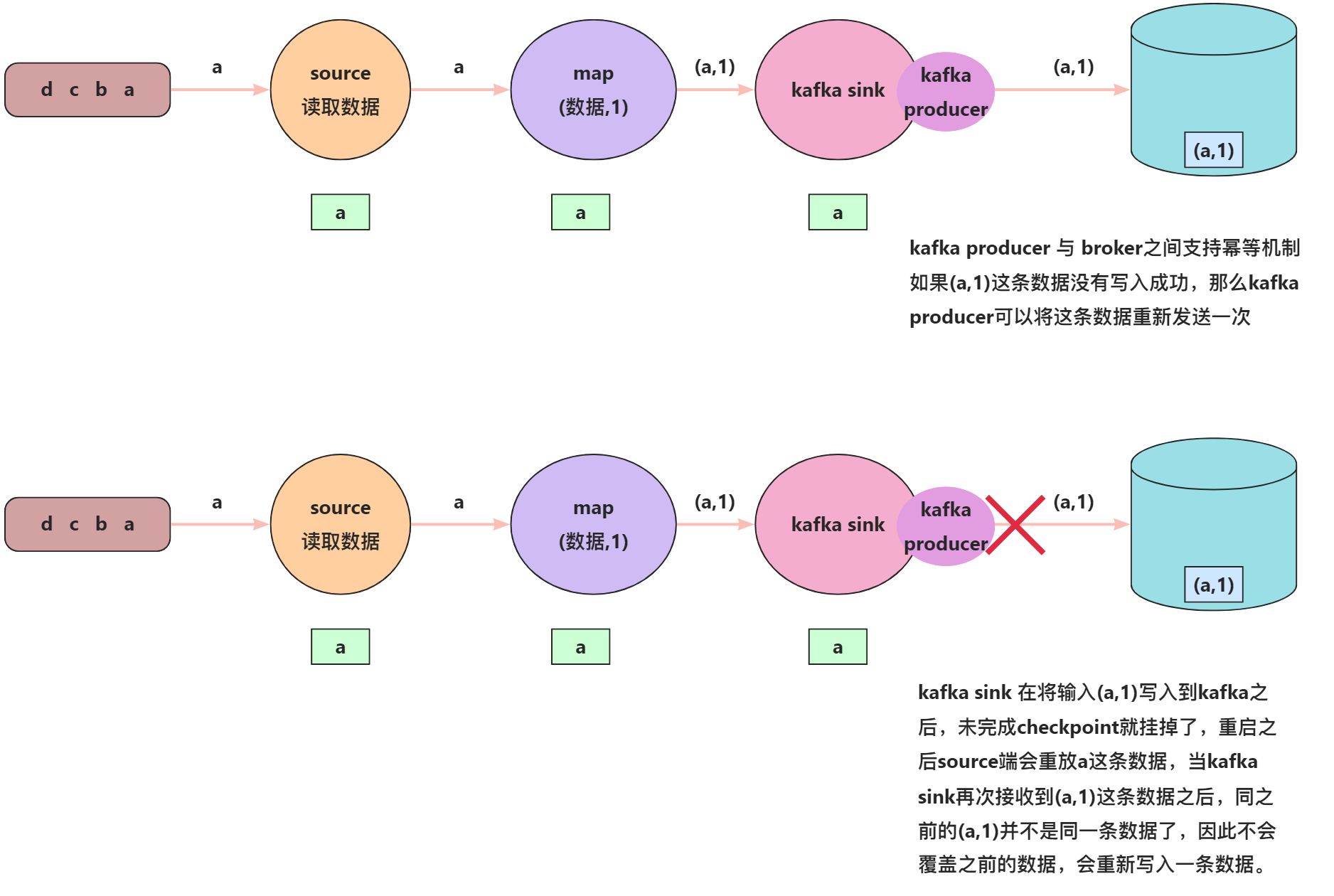
因此如果要将数据写入到kafka,应该使用事务提交的方式。
两阶段事务写入
以 mysql为例,画图详解两阶段事务提交的流程

两阶段预写日志写入
对应目标系统既不支持事务,也不支持幂等性的情况下,可以使用两阶段预写日志写入的方式将数据写入到外部存储系统。其实现原理同两阶段事务写入很像,只是当前checkpoint的数据是存储在sink的状态中,等notify之后,再将状态中的数据写入到外部存储系统。
3. Table API
3.1. 重要概念
- 动态表:数据是源源不断来的,不是由固定数据组成的表;
- ChangelogStream:下游的数据流中会为每条数据添加标记。例如:**+I、-D、-U、+U,分别表示新增数据、删除数据、更新前的数据、更新后的数据;**
- Row:表中的每条数据都是封装成Row对象
3.2. 数据类型映射
MySQL type
Oracle type
PostgreSQL type
SQL Server type
Flink SQL type
TINYINT
TINYINT
TINYINT
SMALLINT
TINYINT UNSIGNED
SMALLINT
INT2
SMALLSERIAL
SERIAL2
SMALLINT
SMALLINT
INT
MEDIUMINT
SMALLINT UNSIGNED
INTEGER
SERIAL
INT
INT
BIGINT
INT UNSIGNED
BIGINT
BIGSERIAL
BIGINT
BIGINT
BIGINT UNSIGNED
DECIMAL(20, 0)
BIGINT
BIGINT
BIGINT
FLOAT
BINARY_FLOAT
REAL
FLOAT4
REAL
FLOAT
DOUBLE
DOUBLE PRECISION
BINARY_DOUBLE
FLOAT8
DOUBLE PRECISION
FLOAT
DOUBLE
NUMERIC(p, s)
DECIMAL(p, s)
SMALLINT
FLOAT(s)
DOUBLE PRECISION
REAL
NUMBER(p, s)
NUMERIC(p, s)
DECIMAL(p, s)
DECIMAL(p, s)
DECIMAL(p, s)
BOOLEAN
TINYINT(1)
BOOLEAN
BIT
BOOLEAN
DATE
DATE
DATE
DATE
DATE
TIME [(p)]
DATE
TIME [(p)] [WITHOUT TIMEZONE]
TIME(0)
TIME [(p)] [WITHOUT TIMEZONE]
DATETIME [(p)]
TIMESTAMP [(p)] [WITHOUT TIMEZONE]
TIMESTAMP [(p)] [WITHOUT TIMEZONE]
DATETIME DATETIME2
TIMESTAMP [(p)] [WITHOUT TIMEZONE]
CHAR(n)
VARCHAR(n)
TEXT
CHAR(n)
VARCHAR(n)
CLOB
CHAR(n)
CHARACTER(n)
VARCHAR(n)
CHARACTER VARYING(n)
TEXT
CHAR(n)
NCHAR(n)
VARCHAR(n)
NVARCHAR(n)
TEXT
NTEXT
STRING
BINARY
VARBINARY
BLOB
RAW(s)
BLOB
BYTEA
BINARY(n)
VARBINARY(n)
BYTES
ARRAY
ARRAY
3.3. Table Environment
3.3.1. 方式一
# 初始化表环境
configuration = Configuration()
settings = EnvironmentSettings.new_instance() \
.in_streaming_mode() \
.with_configuration(configuration) \
.build()
t_env = TableEnvironment.create(settings)
# 将flink的相关参数设置到表环境中
table_config = t_env.get_config()
table_config.set("table.exec.mini-batch.enabled", "true")
table_config.set("table.exec.mini-batch.allow-latency", "5 s")
table_config.set("table.exec.mini-batch.size", "5000")
table_config.set("pipeline.jars", "file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar;"
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar;"
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar")
3.3.2. 方式二
env = StreamExecutionEnvironment.get_execution_environment()
# -------------------------设置各种参数------------------------------------------
# 添加jar包
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar", )
# 设置checkpoint的时间间隔,以及设置为对齐checkpoint
env.enable_checkpointing(1000, CheckpointingMode.EXACTLY_ONCE)
env.get_checkpoint_config().set_checkpoint_storage_dir("file:///E:/PycharmProjects/pyflink/eos_ckpt")
# 设置task级别的故障重启策略:固定重启次数为3次,每次重启的时间间隔为1000毫秒
env.set_restart_strategy(RestartStrategies.fixed_delay_restart(3, 1000))
# 设置状态后端,默认是HashMapStateBackend
env.set_state_backend(HashMapStateBackend())
# 设置算子并行度
env.set_parallelism(1)
t_env = StreamTableEnvironment.create(env)
3.4. formats
3.4.1. JSON
样本数据
{"id": 1, "friends": [{"name": "a", "info": {"addr": "bj", "gender": "male"}}, {"name": "b", "info": {"addr": "sh", "gender": "female"}}]}
示例代码
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
if __name__ == '__main__':
env: StreamExecutionEnvironment = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-json-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-table-common-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar", )
table_env: StreamTableEnvironment = StreamTableEnvironment.create(env)
table_env.execute_sql("CREATE TABLE users ("
"id INT,"
"friends ARRAY<ROW<name STRING, info ROW<addr STRING, gender STRING>>>" -- 复杂JSON的类型的定义
") "
"WITH ("
"'connector' = 'filesystem',"
"'path' = 'file:///E:/PycharmProjects/pyflink/data/users.json',"
"'format' = 'json')")
# 方式一,注意下标从1开始
table_env.execute_sql("""select id, friends[2].name as name, friends[2].info.gender as gender from users""").print()
# 方式二
table_env.execute_sql("""select id, friends[2]['name'] as name, friends[2]['info']['gender'] as gender from users""").print()
3.5. connectors
3.5.1. kafka
将kafka中的一个主题映射成flink中的一张表,示例代码如下:
from pyflink.common import Configuration
from pyflink.table import TableEnvironment, EnvironmentSettings
# 将kafka中的一个topic的数据映射成一张flinksql表
if __name__ == '__main__':
# 初始化表环境
configuration = Configuration()
settings = EnvironmentSettings.new_instance() \
.in_streaming_mode() \
.with_configuration(configuration) \
.build()
t_env = TableEnvironment.create(settings)
# 将flink的相关参数设置到表环境中
table_config = t_env.get_config()
table_config.set("table.exec.mini-batch.enabled", "true")
table_config.set("table.exec.mini-batch.allow-latency", "5s")
table_config.set("table.exec.mini-batch.size", "5000")
table_config.set("pipeline.jars", "file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar;"
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar;"
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar")
# 执行sql语句,创建kafka动态表
t_env.execute_sql(
"""
CREATE TABLE KafkaTable (
`user_id` BIGINT, -- 物理字段
`item_id` BIGINT, -- 物理字段
`behavior` STRING, -- 物理字段
`id` as user_id, -- 表达式字段
`offset` BIGINT METADATA VIRTUAL, -- 元数据字段,不需要重命名
`ts` TIMESTAMP(3) METADATA FROM 'timestamp' -- 元数据字段,kafka连接器暴露出来的元数据字段timestamp,如果需要对元数据进行重命名,则需要使用 METADATA FROM
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = '192.168.31.50:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
-- 下面是关于csv格式的一些参数
'csv.ignore-parse-errors' = 'true', -- csv解析失败是否需要忽略
'csv.allow-comments' = 'true' -- 是否允许注释,#开始的表示注释
)"""
)
# t_env.execute_sql("""select * from KafkaTable""").print()
t_env.execute_sql("select user_id, count(distinct (item_id)) from KafkaTable group by user_id").print()
- 上面代码中所使用到的参数可以参考官网:Kafka | Apache Flink
- 所有Kafka consumer和producer支持的配置项均可在配置前添加properties.前缀后在WITH参数中使用。例如需要配置Kafka consumer或producer的超时时间request.timeout.ms为60000毫秒,则可以在WITH参数中配置**'properties.request.timeout.ms'='60000'**。Kafka consumer和Kafka producer的配置项详情请参见Apache Kafka官方文档。
3.5.2. upsert-kafka
upsert-kafka sink:从kafka接收数据,对数据做处理之后,再写回kafka。
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
# 测试upsert kafka 连接器的用法
if __name__ == '__main__':
env: StreamExecutionEnvironment = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-json-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-table-common-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar", )
table_env: StreamTableEnvironment = StreamTableEnvironment.create(env)
table_env.execute_sql("""
CREATE TABLE user_info (
user_id BIGINT,
name STRING,
nick STRING,
age bigint,
gender STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_info',
'properties.group.id' = 'group1',
'properties.bootstrap.servers' = '192.168.31.50:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
)
""")
table_env.execute_sql("""
CREATE TABLE nick_count (
nick STRING,
user_count BIGINT,
PRIMARY KEY (nick) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'nick_count',
'properties.bootstrap.servers' = '192.168.31.50:9092',
'key.format' = 'json',
'value.format' = 'json'
)
""")
# insert into 语句 后面需要加上wait()
table_env.execute_sql("""insert into nick_count select nick,count(distinct (user_id)) as user_count from user_info group by nick""").wait()
# 打印到屏幕上可以看到-u +u的标记
table_env.execute_sql("sselect nick,count(distinct (user_id)) as user_count from user_info group by nick").print()
3.5.3. mysql-cdc
- 需要开启mysql的binlog服务
- 在flink中,需要开启checkpoint
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode
from pyflink.table import StreamTableEnvironment
if __name__ == '__main__':
env: StreamExecutionEnvironment = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-mysql-cdc-2.3.0.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar")
# 使用cdc连接器必须要开启checkpoint
env.enable_checkpointing(5000, CheckpointingMode.EXACTLY_ONCE)
env.get_checkpoint_config().set_checkpoint_storage_dir("file:///d:/checkpoint")
t_env = StreamTableEnvironment.create(env)
t_env.execute_sql("""create table flink_score(
id int,
name string,
gender string,
score double,
primary key(id) not enforced
)with(
'connector'='mysql-cdc',
'hostname'='192.168.31.50',
'port'='3306',
'username'='root',
'password'='000000',
'database-name'='test_flink',
'table-name'='score'
)
""")
t_env.execute_sql("select * from flink_score").print()
3.6. catelogs
元数据的保存位置,默认是保存在内存中,程序停止之后再启动就没有了。
3.6.1. GenericInMemoryCatalog
GenericInMemoryCatalog 是基于内存实现的 Catalog,所有元数据只在 session 的生命周期内可用。
3.6.2. JdbcCatalog
JdbcCatalog 允许用户通过 JDBC 协议将 Flink 连接到关系数据库。
3.6.2.1. JDBCCatalog 的使用
JDBC | Apache Flink
本小节主要描述如何创建并使用 Postgres Catalog 或 MySQL Catalog。
JDBC catalog 支持以下参数:
name:必填,catalog 的名称。
default-database:必填,默认要连接的数据库。
username:必填,Postgres/MySQL 账户的用户名。
password:必填,账户的密码。
base-url:必填,(不应该包含数据库名)
- 对于 Postgres Catalog base-url 应为 "jdbc:postgresql://<ip>:<port>" 的格式。- 对于 MySQL Catalog base-url 应为 "jdbc:mysql://<ip>:<port>" 的格式。
import os
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import EnvironmentSettings, TableEnvironment, StreamTableEnvironment
from pyflink.table.catalog import JdbcCatalog
if __name__ == '__main__':
env: StreamExecutionEnvironment = StreamExecutionEnvironment.get_execution_environment()
jar_directory = 'E:/PycharmProjects/pyflink/jars/lib/'
for filename in os.listdir(jar_directory):
if filename.endswith('.jar'):
env.add_jars("file:///" + jar_directory + filename)
t_env = StreamTableEnvironment.create(env)
name = "my_jdbc_catalog"
default_database = "mysql"
username = "root"
password = "000000"
base_url = "jdbc:mysql://192.168.31.50:3306"
catalog = JdbcCatalog(name, default_database, username, password, base_url)
t_env.register_catalog("my_jdbc_catalog", catalog)
# 设置 JdbcCatalog 为会话的当前 catalog
t_env.execute_sql("show catalogs").print()
t_env.execute_sql("use catalog my_jdbc_catalog").print()
t_env.execute_sql("show databases").print()
3.6.3. HiveCatalog
将flink表的元数据信息保存到hive,hive在去执行show tables命令时也是能看见flink的表的,但是hive不能查flink表的数据。
为什么能看见呢?hive的元数据表中装了包括表名、表字段、表参数等信息,而flink在创建表时也有表名(create table test)、表字段(user_id BIGINT,item_id BIGINT,*)和*表参数信息(with......),因此可以将其保存到元数据表中。
但是为什么又不能查flink中的表数据呢?因为hive表的定义和flink表的定义是完全不一样的。
3.6.3.1. HiveCatalog的使用
Overview | Apache Flink
import os
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import *
from pyflink.table.catalog import HiveCatalog
if __name__ == '__main__':
os.environ['HADOOP_USER_NAME'] = '能够创建hdfs目录的用户'
env: StreamExecutionEnvironment = StreamExecutionEnvironment.get_execution_environment()
jar_directory = 'E:/PycharmProjects/pyflink/jars/lib/'
for filename in os.listdir(jar_directory):
if filename.endswith('.jar'):
env.add_jars("file:///" + jar_directory + filename)
t_env = StreamTableEnvironment.create(env)
catalog_name = "hive1" # 自定义catalog名
default_database = "test" # 自定义hive中存储元数据的默认数据库
hive_conf_dir = "E:/PycharmProjects/pyflink/conf" # 自定义hive配置文件的路径
hive_catalog = HiveCatalog(catalog_name, default_database, hive_conf_dir)
# 将自定义的catalog注册到catalogManager中
t_env.register_catalog("myhive", hive_catalog)
# 创建hivecatalog表
t_env.execute_sql("CREATE TABLE `myhive`.`test`.`MyUserTable` (id INT,name STRING,age INT) "
"WITH ("
"'connector' = 'filesystem',"
"'path' = 'file:///E:/PycharmProjects/pyflink/data/person.txt',"
"'format' = 'json')")
# 打印所有的catalog
t_env.execute_sql("show catalogs").print()
# 切换到自定义的catalog
t_env.execute_sql("use catalog myhive")
# 打印当前catalog中的库
t_env.execute_sql("show databases").print()
3.7. Watermark
在Flink批处理中,默认使用的是处理时间(Processing Time)而不是事件时间(Event Time)。因此不需要指定Watermark字段。
3.7.1. 流转表
流转表,watermark不会自动传递,需要显式声明。
# -*-coding:utf-8-*-
import json
from pyflink.common import WatermarkStrategy, SimpleStringSchema, Types, Duration
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, MapFunction
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.table import StreamTableEnvironment, Schema
from pyflink.common.types import Row
class MyTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, row, record_timestamp):
return row[2]
class MyMapFunction(MapFunction):
# 输入的数据格式:1,e02,1683734401600,p001
def map(self, value):
fields = value.split(",")
return Row(int(fields[0]), str(fields[1]), int(fields[2]), str(fields[3]))
class MyMapFunction1(MapFunction):
# 输入的数据格式:{"guid": 1, "event_id": "e02", "event_time": 1683734400000, "page_id": "p001"}
def map(self, json_str):
return Row(**json.loads(json_str))
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 使用kafka source需要加入kafka的jar包依赖
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar")
env.set_parallelism(1)
t_env = StreamTableEnvironment.create(env)
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.101.177:9092") \
.set_topics("pyflink-test") \
.set_group_id("pyflink2") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
source_stream = env.from_source(source=source,
watermark_strategy=WatermarkStrategy.no_watermarks(),
source_name="Kafka Source")
watermark_strategy = WatermarkStrategy.for_bounded_out_of_orderness(Duration.of_millis(1)).with_timestamp_assigner(MyTimestampAssigner())
row_stream = source_stream\
.map(MyMapFunction1(), Types.ROW_NAMED(['guid', 'event_id', 'event_time', 'page_id'], [Types.INT(), Types.STRING(), Types.LONG(), Types.STRING()]))\
.assign_timestamps_and_watermarks(watermark_strategy)
# 重新定义watermark
table = t_env.from_data_stream(row_stream,
Schema
.new_builder()
.column("guid", "INT")
.column("event_id", "STRING")
.column("event_time", "BIGINT")
.column("page_id", "STRING")
.column_by_expression("rowtime", "TO_TIMESTAMP_LTZ(event_time, 3)")
.watermark("rowtime", "rowtime - INTERVAL '3' SECOND")
.build())
# 沿用流中的watermark
# table = t_env.from_data_stream(row_stream,
# Schema
# .new_builder()
# .column("guid", "INT")
# .column("event_id", "STRING")
# .column("event_time", "BIGINT")
# .column("page_id", "STRING")
# .column_by_metadata("rt", "TIMESTAMP_LTZ(3)", "rowtime")
# .watermark('rt', "source_watermark()")
# .build())
# 打印表的字段信息
table.print_schema()
# 将表对象转换成有名字的表
t_env.create_temporary_view("event", table)
# 查询数据
t_env.execute_sql("select guid, event_id, event_time, page_id, rowtime, CURRENT_WATERMARK(rowtime) from event").print()
# t_env.execute_sql("select guid, event_id, event_time, page_id, rt, CURRENT_WATERMARK(rt) from event").print()
env.execute()
3.7.2. 表转流
表转流,watermark会自动传递。
3.7.3. 直接使用sql创建表
3.7.3.1. 样本数据
{"guid": 1, "eventId": "e02", "eventTime": 1683734400000, "pageId": "p001"}
{"guid": 1, "eventId": "e02", "eventTime": 1683734401000, "pageId": "p001"}
{"guid": 1, "eventId": "e02", "eventTime": 1683734402000, "pageId": "p001"}
{"guid": 1, "eventId": "e02", "eventTime": 1683734403000, "pageId": "p001"}
3.7.3.2. 示例代码
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
from pyflink.table import StreamTableEnvironment
if __name__ == '__main__':
env: StreamExecutionEnvironment = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-json-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-table-common-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar", )
# 指定了批处理模式就不能在建表的时候指定Watermark。在Flink批处理中,默认使用的是处理时间(Processing Time)而不是事件时间(Event Time)。
# env.set_runtime_mode(RuntimeExecutionMode.BATCH)
table_env: StreamTableEnvironment = StreamTableEnvironment.create(env)
table_env.execute_sql("CREATE TABLE users ("
"guid INT,"
"eventId string, "
"eventTime bigint, "
"ts as TO_TIMESTAMP_LTZ(eventTime, 3)" -- watermark字段的数据类型必须是timestamp或者timestamp_ltz
"watermark for ts as ts - interval '1' second " -- 指定watermark,如果是批处理模式就不需要
") "
"WITH ("
"'connector' = 'filesystem',"
"'path' = 'file:///E:/PycharmProjects/pyflink/data/wm.txt',"
"'format' = 'json')")
table_env.execute_sql("select * from users").print()
3.8. 表创建
3.8.1. 使用from_xxx的方式得到一个表对象
从流转成表,得到一个表对象,且需要将流中的字段对应到表字段中。
Kafka 将消息键值以二进制进行存储,因此 Kafka 并不存在 schema 或数据类型。Kafka 消息使用格式配置进行序列化和反序列化,例如 csv,json,avro。 因此,如果要想解析kafka中的数据需要自定义反序列化器。
from pyflink.common import WatermarkStrategy, Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.formats.json import JsonRowDeserializationSchema
from pyflink.table import StreamTableEnvironment
# 从 kafka中读取数据(数据的格式是json字符串),然后将其转成table
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 使用kafka source需要加入kafka的jar包依赖
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar")
env.set_parallelism(1)
t_env = StreamTableEnvironment.create(env)
# kafka中的数据是json格式,需要指定json的反序列化器,其中Row的字段需要同json字段一一对应
row_type_info = Types.ROW_NAMED(['name', 'age'], [Types.STRING(), Types.INT()])
json_format = JsonRowDeserializationSchema.builder().type_info(row_type_info).build()
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.101.177:9092") \
.set_topics("pyflink-test") \
.set_group_id("pyflink") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(json_format) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
table = t_env.from_data_stream(source_stream)
table.execute().print()
env.execute()
from pyflink.common import WatermarkStrategy, Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer
from pyflink.datastream.formats.csv import CsvRowDeserializationSchema
from pyflink.table import StreamTableEnvironment
# 从 kafka中读取数据(数据的格式是csv),然后将其转成table
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
# 使用kafka source需要加入kafka的jar包依赖
env.add_jars("file:///F:/pycharm_projects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar")
env.set_parallelism(1)
t_env = StreamTableEnvironment.create(env)
# kafka中的数据是csv的格式,需要指定csv的反序列化器,其中Row的字段名同csv的字段值对应,Row的字段类型需要同csv的字段类型保持一致
row_type_info = Types.ROW_NAMED(['name', 'age'], [Types.STRING(), Types.INT()])
csv_format = CsvRowDeserializationSchema.Builder(row_type_info).build()
source = KafkaSource.builder() \
.set_bootstrap_servers("192.168.101.177:9092") \
.set_topics("pyflink-test") \
.set_group_id("pyflink") \
.set_starting_offsets(KafkaOffsetsInitializer.latest()) \
.set_value_only_deserializer(csv_format) \
.build()
source_stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
table = t_env.from_data_stream(source_stream)
table.execute().print()
env.execute()
3.8.2. 使用create_xxx的方式得到一个有名字的表
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment, TableDescriptor, Schema
from pyflink.table.types import DataTypes
if __name__ == '__main__':
env: StreamExecutionEnvironment = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///E:/PycharmProjects/pyflink/jars/flink-sql-connector-kafka-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-connector-jdbc-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-json-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/flink-table-common-1.16.1.jar",
"file:///E:/PycharmProjects/pyflink/jars/mysql-connector-java-5.1.47.jar", )
table_env = StreamTableEnvironment.create(env)
table_descriptor = TableDescriptor.for_connector("filesystem").schema(
Schema.new_builder()
.column("id", DataTypes.INT())
.column("name", DataTypes.STRING())
.column("age",DataTypes.INT()).build())\
.format("json")\
.option("path", "file:///E:/PycharmProjects/pyflink/data/person.txt")\
.build()
# 得到一个有名字的表
table_env.create_table("stu", table_descriptor)
# 根据表名进行查询
table_env.execute_sql("select * from stu").print()
3.9. 自定义函数
具体使用参考官网:普通自定义函数 | Apache Flink
3.9.1. 标量函数
- 输入:零个,一个或者多个列
- 输出:单个值
3.9.2. 表值函数
- 输入:零个,一个或者多个列
- 任意数量的行
**NOTE: **表值函数与标量函数唯一的区别是,Python 表值函数的返回类型必须是 iterable(可迭代子类), iterator(迭代器) or generator(生成器)。
3.9.3. 普通聚合函数
用户自定义聚合函数可以将多行中的标量值映射成一个标量值。
NOTE: 目前用户自定义聚合函数只支持在流处理模式中使用GroupBy aggregation和Group Window Aggregation****,如果是在批处理模式中,需要使用Vectorized Aggregate Functions。
3.9.4. 表聚合函数
用户自定义表聚合函数可以将多行中的标量值映射成零行,一行或者多行。
4. 生产环境的参数配置
env = StreamExecutionEnvironment.get_execution_environment()
# 如果是从Kafka读取数据,那么设置为kafka主题的分区数
env.set_parallelism(4)
# 设置checkpoint
env.enable_checkpointing(5 * 60000, CheckpointingMode.EXACTLY_ONCE) # 5分钟
# 设置checkpoint的保存路径,如果部署在YARN,那么最好是HDFS路径
env.get_checkpoint_config().set_checkpoint_storage_dir("hdfs://hadoop102:8020/pyflink/ck")
# 设置checkpoint的超时时间
env.get_checkpoint_config().set_checkpoint_timeout(10 * 60000) # 10分钟
# 设置两个 checkpoints 之间最少的间隔时间
env.get_checkpoint_config().set_min_pause_between_checkpoints(120000) # 2分钟
# 同时可以存在几个checkpoint
env.get_checkpoint_config().set_max_concurrent_checkpoints(1) # 1个
# 取消作业时保留 checkpoint,因为有时候任务 savepoint 可能不可用,这时我们就可以直接从 checkpoint 重启任务
env.get_checkpoint_config().enable_externalized_checkpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
# 是否允许checkpoint失败
env.get_checkpoint_config().set_fail_on_checkpointing_errors(False) # 允许,即checkpoint失败时,task不失败
# 设置重启策略
env.set_restart_strategy(RestartStrategies.fixed_delay_restart(3, 5000)) # 重启3次,每次重启的间隔时间为5s,如果3次都重启失败,那么这个任务也就失败了
# 设置状态后端
env.set_state_backend(RocksDBStateBackend()) # RocksDB状态后端
版权归原作者 凯尔哥 所有, 如有侵权,请联系我们删除。