
作者:石臻臻, CSDN博客之星Top5、Kafka Contributor 、nacos Contributor、华为云 MVP ,腾讯云TVP, 滴滴Kafka技术专家 、 KnowStreaming PMC, 《Kafka运维与实战宝典》电子书作者。
领取《Kafka运维与实战宝典》PDF请联系石臻臻
KnowStreaming 是滴滴开源的Kafka运维管控平台, 有兴趣一起参与参与开发的同学,可以联系我呀 。
文章目录
1. 分配策略的作用
我们在分析生产者的时候有专门写过文章分析生产者的分区分配策略
Kafka中生产消息时的三种分区分配策略
生成者的分配策略是把我们产生的消息选择一个合适的分区去发送,
那么今天我们要讲解一下 消费者的分区分配策略 他要做的事情是
同一个消费组中 给不同消费者分配能够消费的分区数;
同一个消费组中,一个分区只会被一个消费者消费。
2. 分配策略的选择
2.1 分配策略配置
每个消费组客户端都可以配置一个
partition.assignment.strategy
属性
并且可以配置多个自己支持的分配策略,例如:
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor,org.apache.kafka.clients.consumer.RoundRobinAssignor
默认策略是
org.apache.kafka.clients.consumer.RoundRobinAssignor
2.2 选择合适的策略
既然每个客户端成员都可以配置多个自己支持的分配策略, 那么GroupCoordinator(消费组协调器)使用哪个分配策略去分配这些资源呢?
肯定是需要消费组下面的所有成员都使用同一种分配策略来进行分配。 所以GroupCoordinator就面临着选择哪个分配策略。
选择的逻辑如下
- 选择所有Member都支持的分配策略
- 在1的基础上,优先选择每个
partition.assignment.strategy配置靠前的策略。
请看下面的2个例子
caseconsumer-0consumer-1consumer-2选中策略case-1roundrobin,rangrang,roundrobin,strickroundrobin,rangroundrobincase-2strick,roundrobin,rangrang,roundrobinstrick ,rangrang
Case-1
- 所有支持的分配策略为:roundrobin,rang
- 每个consumer都在1的基础上,给自己排最前面的投票, consumer-0投roundrobin, consumer-1投rang, consumer-3投roundrobin; 这样算下来 roundrobin是有2票的, 那么久选择roundrobin为分配策略;
Case-2
- 所有支持的分配策略为:rang
- 都不用投票, 直接选择rang当选
如果新Member加入Group的时候, 带上的分配策略跟现有Group中所有Member(Group有Member的情况下)都支持的协议都不交叉
那么就会抛出异常:INCONSISTENT_GROUP_PROTOCOL
[2022-09-08 14:34:12,508] INFO [Consumer clientId=client2, groupId=consumer0] Rebalance failed. (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
org.apache.kafka.common.errors.InconsistentGroupProtocolException: The group member's supported protocols are incompatible with those of existing members or first group member tried to join with empty protocol type or empty protocol list.
[2022-09-08 14:34:12,511] ERROR Error processing message, terminating consumer process: (kafka.tools.ConsoleConsumer$)
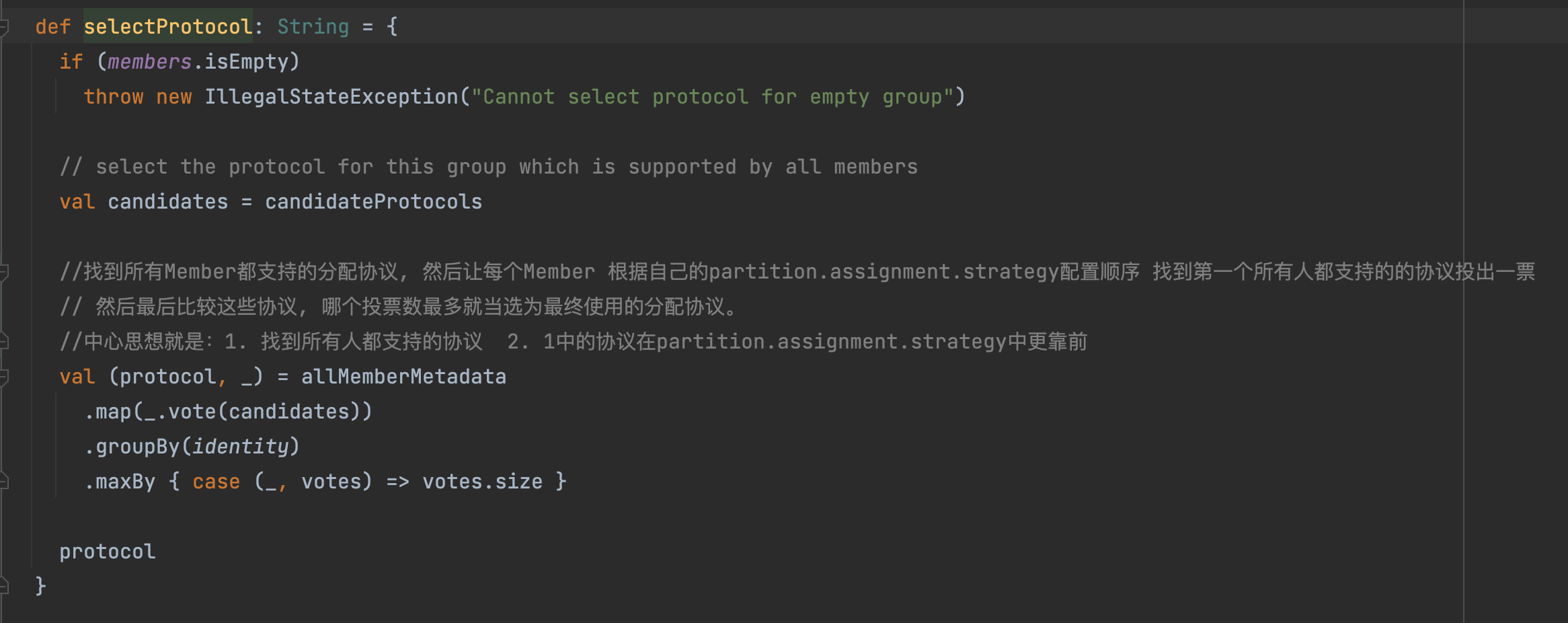
这个协议的选择的代码逻辑在 GroupMetadata#selectProtocol
调用的时机是当前发起JoinGroup的Member都完成JoinGroup,并调用onCompleteJoin
具体详情可以看 : Kafka消费者JoinGroupRequest流程解析
3. 分配策略计算和传播
3.1 分配策略计算时机
既然我们已经知道了分区分配策略的选择, 那么什么时候会触发这个策略的逻辑计算呢?
如果你有看过之前的文章: Kafka消费者JoinGroupRequest流程解析 那么对此就肯定会有一定的了解
当所有的Member(成员)发起JoinGroup请求, 并且组协调器(GroupCoordinator)也都处理正常,就会回调当前发起JoinGroup请求的Member(成员)
其中有个最特别的就是, 组协调器(GroupCoordinator)会把所有的Member(成员)的元信息打包一并返回给那个Leader Member, 而Follow Member是不会返回的。
Leader Member 接受到回调并拿到这个元信息之后, 就开始去计算每个成员应该被分配到的分区。
代码定位
ConsumerCoordinator#performAssignment
@OverrideprotectedMap<String,ByteBuffer>performAssignment(String leaderId,String assignmentStrategy,List<JoinGroupResponseData.JoinGroupResponseMember> allSubscriptions){ConsumerPartitionAssignor assignor =lookupAssignor(assignmentStrategy);if(assignor ==null)thrownewIllegalStateException("Coordinator selected invalid assignment protocol: "+ assignmentStrategy);//省略部分代码...// 更新一下所有订阅的Topic的元信息// 如果有变更的元信息则更新一下updateGroupSubscription(allSubscribedTopics);//省略部分代码...Map<String,Assignment> assignments = assignor.assign(metadata.fetch(),newGroupSubscription(subscriptions)).groupAssignment();if(protocol ==RebalanceProtocol.COOPERATIVE){validateCooperativeAssignment(ownedPartitions, assignments);}//省略部分代码...}
上面的代码主要是 根据分配策略,获取分配策略实例, 然后调用
assign
方法进行计算,得到分配方式。
但是最终调用的计算逻辑是每个AbstractPartitionAssignor实现类的
assign
方法。
并且也可以实现自定义的分配策略.只需要实现接口AbstractPartitionAssignor就行。
3.2 分配策略传播
在 3.1 分配策略计算时机 中我们知道分配策略的计算时机, 那么计算好了之后如何告知其他的Member, 他们对应的分配状态呢?
当每个Member收到JoinGroup的回调之后, 他们会发起一个SyncGroupRequest, 其中Leader Member就会把刚刚计算好的分配策略, 一起当做入参发起请求。请看下图

上面发起的请求也只是告知了组协调器(GroupCoordinator)分配的情况, 最终还是需要组协调器(GroupCoordinator)来告知每个Member的。
那么这个告知的过程就是所有Member都同步完成后的回调 ;
具体请看:KafkaConsumer SyncGroupRequest详解
4. 图解所有分配策略
上面所有的铺垫都讲解清楚了,那么目前Kafka支持哪些分配策略呢?
我们来一一分析一下
4.1 RangeAssignor 范围分区分配策略
partition.assignment.strategy=]org.apache.kafka.clients.consumer.RangeAssignor
这也是默认的分配策略
它是以单个Topic为一个维度来计算分配的, 他只负责将每一个Topic的分区尽可能均衡的分配给消费者
- 消费组里面所有消费者(Member)按照字母排序, 给Topic的分区按照分区号排序。
- 先计算每个分区最少平均分配多少个分区数, 然后余下的逐个分 举个例子:Topic为Topic1 有11个分区;有3个消费者订阅 那么平均每个 11/3=3余2, 那么前面两个可以分到4个分区,最后一个分到3个;[ 4, 4, 3 ]他们最终分配方式如下消费者Member:client1-ba0ebe99-cd09-42e9-87b9-11b6f828bfcaTopic1-0, Topic1-1, Topic1-2, Topic1-3Member:client2-cbfb4cf2-c878-41d2-852c-86d56dbb99c2Topic1-4, Topic1-5, Topic1-6, Topic1-7Member:client3-ad60e7a5-204f-4741-b66f-3da3acb0a2f9Topic1-8, Topic1-9, Topic1-10分配是先分完一个消费者再分配下一个的,跟遍历是有区别。 clientId-1 先分到 [ 0 , 1 , 2 , 3 ] 号分区, 后面的接着分。

图里面的Member就是消费者, 对消费组来说他内部的对象是Member
Range弊端
Range针对单个Topic的情况下显得比较均衡, 但是假如Topic很多的话, Member排序靠前的可能会比Member排序靠后的负载多很多。

看,像这种情况, 3个Member都订阅了这4个Topic, 可是Member这么多分区愣是没有分配到1个
4.2 RoundRobinAssignor 轮询分区策略
把所有Member排序, 所有TopicPartition排序。轮训遍历分配

Member-3下线
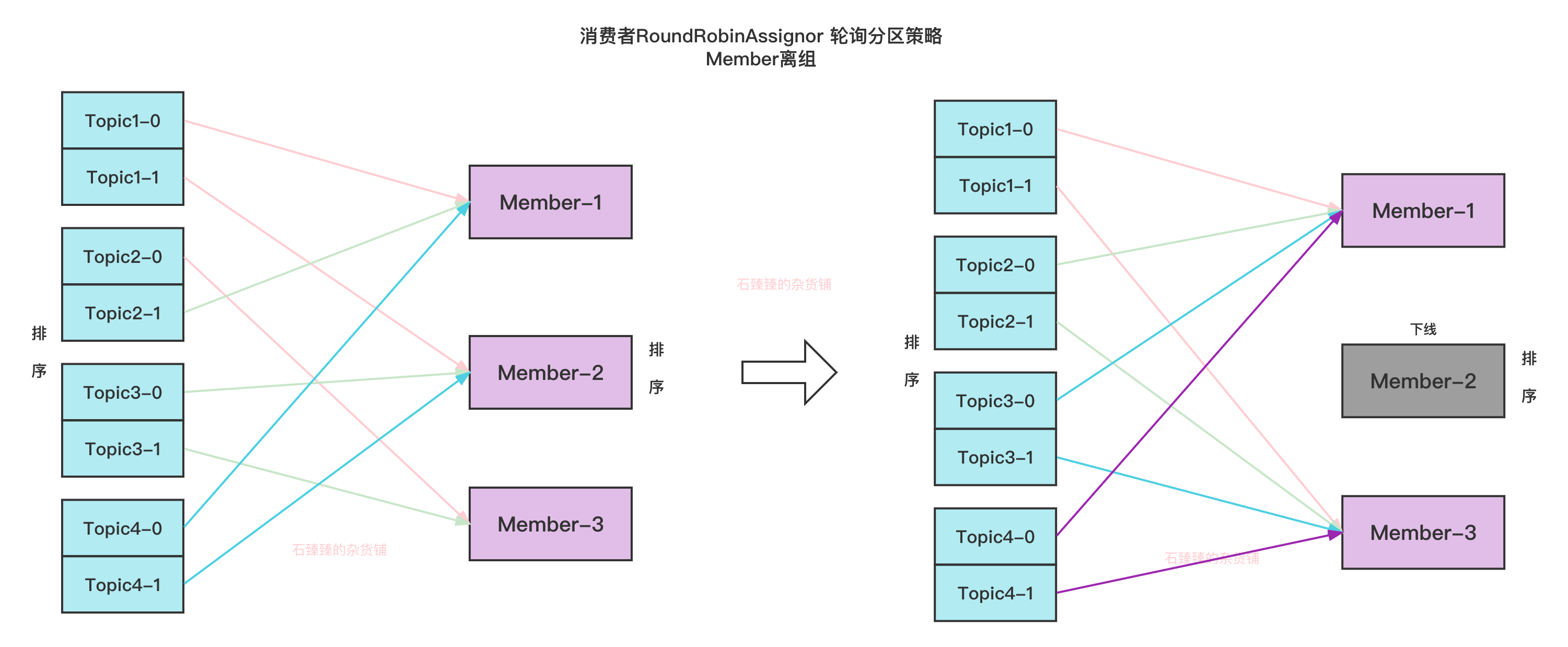
RoundRobin的一些弊端
如果成员订阅的Topic不尽相同的时候, 最终结果也不可能会完全均衡的。

如果图中的Memner-3比另外两个多订阅了Topic-4,那他总共就消费了6个分区了, 但是另外两个分别只消费了2个分区。
如果这里的Member-3把分区 Topic2-0、Topic3-1 分给另外两个那才是最均衡的情况。
那么有什么策略能解决这个问题吗?接下来我们另外一个分区策略 – 粘性分区
4.3 StickyAssignor 粘性分区策略
上面介绍的两种分区分配方式,多多少少都会有一些分配上的偏差, 而且每次重新分配的时候都是把所有的都重新来计算并分配一遍, 那么每次分配的结果都会偏差很多, 如果我们在计算的时候能够考虑上一次的分配情况,来尽量的减少分配的变动,这样我们将尽可能地撤销更少的分区,因为撤销过程是昂贵的
我们之前在讲生产者的时候也讲过粘性分区: Kafka中生产消息时的三种分区分配策略
那么消费者的粘性分区策略是什么样子的呢?
目标:
- 分区的分配尽量的均衡
- 每一次重分配的结果尽量与上一次分配结果保持一致
当这两个目标发生冲突时,优先保证第一个目标。第一个目标是每个分配算法都尽量尝试去完成的,而第二个目标才真正体现出StickyAssignor特性的。
首先, StickyAssignor粘性分区在进行分配的时候,是以RoundRobinAssignor的分配逻辑来计算的,但是它又弥补了RoundRobinAssignor的一些可能造成不均衡的弊端。
比如在讲RoundRobinAssignor弊端的那种case, 但是在StickyAssignor中就是下图的分配情况
把RoundRobinAssignor的弊端给优化了

体现粘性分区地方就在于重新分配的时候了, 还是上面的case(上图右边的StickAssignor), 假如 Member-2 离线了
粘性分区的计算方式把把离线的那个Member所属的分区分配给其他的Member, 在其他的Member已拥有的分区不变的前提下,尽量的均衡。
Member-2 有3个分区, 可以分两个分区给Member-1,分1个分区给Member-3 最终分配图如下:

4.4 CooperativeStickyAssignor策略
上面分析的StickyAssignor粘性分区策略,主要作用是保证消费者客户端在重平衡之后能够维持原本的分配方案。
但是StickyAssignor还是属于 RebalanceProtocol.EAGER 协议, 重平衡的时候需要每个客户端都要先放弃当前持有的资源。
为了解决这个问题, 所以就有了 CooperativeStickyAssignor分配策略
你可以理解为 CooperativeStickyAssignor 的分配策略跟StickyAssignor的策略差不多。
但是它在此基础上是用的RebalanceProtocol.COOPERATIVE协议。渐进式的重平衡。
后续专门写一篇文章来讲解一下这一块内容,挖个坑0.0
4.5 自定义分配策略
我们先看一下分区策略的类图

我们想要自定义分配策略,只需要实现接口:
publicinterfaceConsumerPartitionAssignor{/**
* 返回序列化后的自定义数据
*/defaultByteBuffersubscriptionUserData(Set<String> topics){returnnull;}/**
* 分区分配的计算逻辑
*/GroupAssignmentassign(Cluster metadata,GroupSubscription groupSubscription);/**
* 当组成员从领导者那里收到其分配时调用的回调
*/defaultvoidonAssignment(Assignment assignment,ConsumerGroupMetadata metadata){}/**
* 指明使用的再平衡协议
* 默认使用RebalanceProtocol.EAGER协议, 另外一个可选项为 RebalanceProtocol.COOPERATIVE
*/defaultList<RebalanceProtocol>supportedProtocols(){returnCollections.singletonList(RebalanceProtocol.EAGER);}/**
* Return the version of the assignor which indicates how the user metadata encodings
* and the assignment algorithm gets evolved.
*/defaultshortversion(){return(short)0;}/**
* 分配器的名字
* 例如 RangeAssignor、RoundRobinAssignor、StickyAssignor、CooperativeStickyAssignor
* 对应的名字为
* range、roundrobin、sticky、cooperative-sticky
*/Stringname();
当然我们也可以根据自己的需求来实现其他的抽象类
比如:AbstractStickyAssignor抽象类就是专门给粘性分区使用的抽象类
5. 重平衡协议
上面我们讲的是分区策略, 但是分区策略本质上又分为两大类
- RebalanceProtocol.EAGER
- RebalanceProtocol.COOPERATIVE 协作重平衡,kafak2.4出的功能。
这两个区别是
EAGER 重新平衡协议要求消费者在参与重新平衡事件之前始终撤销其拥有的所有分区。因此,它允许完全改组分配
COOPERATIVE协议允许消费者在参与再平衡事件之前保留其当前拥有的分区。分配者不应该立即重新分配任何拥有的分区,而是可以指示消费者需要撤销分区,以便可以在下一次重新平衡事件中将被撤销的分区重新分配给其他消费者
COOPERATIVE协议将一次全局重平衡,改成每次小规模重平衡,直至最终收敛平衡的过程。
COOPERATIVE有效的改进来在此之前EAGER协议重平衡而触发的stop-the-world(STW)
我们上面讲的分配策略3种策略都是 RebalanceProtocol.EAGER 协议
- RangeAssignor 范围分区分配策略
- RoundRobinAssignor 轮询分区策略
- StickyAssignor 粘性分区策略
而CooperativeStickyAssignor分配策略是使用的 RebalanceProtocol.COOPERATIVE协议
关于更多的关于重平衡协议的讲解,请看: Kafka 重平衡的两种协议讲解
版权归原作者 石臻臻的杂货铺 所有, 如有侵权,请联系我们删除。