
Kafka 集群部署
概述
本篇讲解以下kafka集群的搭建,这里搭建了两种Kafka集群,一种是使用ZK的传统集群,一种是不需要ZK的实验版集群,后期Kafka将会废弃ZK,但是现阶段还是推荐使用带有ZK的,因为不需要ZK的还处于实验性质
环境准备
JDK安装
kafka3.0 不再支持 JDK8,建议安装 JDK11 或 JDK17,事先安装好
Docker环境安装
我们后面有Docker安装的方式,推荐预先安装docker和docker-compose
Kafka集群搭建(ZK模式)
zookeeper集群搭建
这里使用的zk是
apache-zookeeper-3.8.0-bin.tar.gz,其他版本可以至官方网站 zookeeper官网下载
zookeeper部署情况
准备三台 Linux 服务器,IP 地址如下所示
节点IPnode1192.168.245.129node2192.168.245.130node3192.168.245.131
准备工作
分别在三台服务器上执行如下操作,搭建并配置 zookeeper 集群
下载安装包
在三台机器都需要下载安装包
mkdir /usr/local/zookeeper &&cd /usr/local/zookeeper
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
解压安装包
tar-zxvf apache-zookeeper-3.8.0-bin.tar.gz
cd apache-zookeeper-3.8.0-bin/
创建数据存放目录
mkdir-p /usr/local/zookeeper/apache-zookeeper-3.8.0-bin/zkdatas
创建配置文件
复制并创建新的配置文件
cd /usr/local/zookeeper/apache-zookeeper-3.8.0-bin/conf
cp zoo_sample.cfg zoo.cfg
编辑配置文件
cd /usr/local/zookeeper/apache-zookeeper-3.8.0-bin/conf
vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# Zookeeper的数据存放目录,修改数据目录
dataDir=/usr/local/zookeeper/apache-zookeeper-3.8.0-bin/zkdatas
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
# 保留多少个快照,本来就有这个配置, 只不过注释了, 取消注释即可
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
# 日志多少小时清理一次,本来就有这个配置, 只不过注释了, 取消注释即可
autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
# 集群中服务器地址,集群间通讯的端口号,文件末尾直接增加
server.1=192.168.245.129:2888:3888
server.2=192.168.245.130:2888:3888
server.3=192.168.245.131:2888:3888
配置
myid
文件
该
myid文件中的值用于和
zoo.cfg配置文件中的配置项
server.x=nodex:2888:3888进行对应,用于标识当前节点的
zookeeper,在
zookeeper集群启动的时候,完成
leader的选举
node1执行
echo1> /usr/local/zookeeper/apache-zookeeper-3.8.0-bin/zkdatas/myid
node2执行
echo2> /usr/local/zookeeper/apache-zookeeper-3.8.0-bin/zkdatas/myid
node3执行
echo3> /usr/local/zookeeper/apache-zookeeper-3.8.0-bin/zkdatas/myid
启动服务
从第 1 台服务器开始,依次执行如下命令
cd /usr/local/zookeeper/apache-zookeeper-3.8.0-bin
#启动服务sh bin/zkServer.sh start
# 查看进程
jps
查看集群状态
sh bin/zkServer.sh status

kafka集群部署
部署规划
首先目前官方页面上并没有集群搭建文档,我们下载安装包,可以查看config/kraft下的README.md文件,根据说明,这里我搭建Kraft模式的kafka集群,这里我用的是3.3.1版本
HOSTNAMEIPOSkafka01192.168.245.129centos7.9kafka02192.168.245.130centos7.9kafka03192.168.245.131centos7.9
准备工作
下载kafka
三台机器都需要下载Kafka
mkdir /usr/local/kafka/ &&cd /usr/local/kafka/
wget https://downloads.apache.org/kafka/3.3.1/kafka_2.12-3.3.1.tgz
解压安装
kafka安装包下载完成后就需要解压以及创建日志目录了
tar-zxvf kafka_2.12-3.3.1.tgz
cd kafka_2.12-3.3.1 &&mkdir logs
配置server.properties
我们需要配置kafka的配置文件,该文件在kafka的
config/server.properties目录下
kafka01配置
vi config/server.properties
#节点ID
broker.id=1
# 本机节点
listeners=PLAINTEXT://192.168.245.129:9092
# 本机节点
advertised.listeners=PLAINTEXT://192.168.245.129:9092
# 这里我修改了日志文件的路径
log.dirs=/usr/local/kafka/kafka_2.12-3.3.1/logs
# zookeeper连接地址
zookeeper.connect=192.168.245.129:2181,192.168.245.130:2181,192.168.245.131:2181
kafka02配置
vi config/kraft/server.properties
#节点ID
broker.id=2
# 本机节点
listeners=PLAINTEXT://192.168.245.130:9092
# 本机节点
advertised.listeners=PLAINTEXT://192.168.245.130:9092
# 这里我修改了日志文件的路径
log.dirs=/usr/local/kafka/kafka_2.12-3.3.1/logs
# zookeeper连接地址
zookeeper.connect=192.168.245.129:2181,192.168.245.130:2181,192.168.245.131:2181
kafka03配置
vi config/kraft/server.properties
#节点ID
broker.id=3
# 本机节点
listeners=PLAINTEXT://192.168.245.131:9092
# 本机节点
advertised.listeners=PLAINTEXT://192.168.245.131:9092
# 这里我修改了日志文件的路径
log.dirs=/usr/local/kafka/kafka_2.12-3.3.1/logs
# zookeeper连接地址
zookeeper.connect=192.168.245.129:2181,192.168.245.130:2181,192.168.245.131:2181
启动集群
可以使用下面的命令来启动集群
nohupsh bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1&
创建主题
sh bin/kafka-topics.sh --create--topictest--partitions1 --replication-factor 1 --bootstrap-server 192.168.245.129:9092

查看主题列表
sh bin/kafka-topics.sh --list --bootstrap-server 192.168.245.129:9092

查看主题信息
sh bin/kafka-topics.sh --bootstrap-server 192.168.245.129:9092 --describe--topictest

Docker方式部署
创建数据目录
mkdir-p /tmp/kafka/broker{1..3}/{data,logs}mkdir-p /tmp/zookeeper/zookeeper/{data,datalog,logs,conf}
Zookeeper配置
创建Zookeeper配置文件
vi /tmp/zookeeper/zookeeper/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data
dataLogDir=/datalog
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
创建Zookeeper日志配置
vi /tmp/zookeeper/zookeeper/conf/log4j.properties
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO, CONSOLE
zookeeper.console.threshold=INFO
zookeeper.log.dir=/logs
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=.
zookeeper.tracelog.file=zookeeper_trace.log
#
# ZooKeeper Logging Configuration
#
# Format is "<default threshold> (, <appender>)+
# DEFAULT: console appender only
log4j.rootLogger=${zookeeper.root.logger}
# Example with rolling log file
#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE
# Example with rolling log file and tracing
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
#
# Log INFO level and above messages to the console
#
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
# Max log file size of 10MB
log4j.appender.ROLLINGFILE.MaxFileSize=10MB
# uncomment the next line to limit number of backup files
log4j.appender.ROLLINGFILE.MaxBackupIndex=10
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add TRACEFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
log4j.appender.TRACEFILE.Threshold=TRACE
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
### Notice we are including log4j's NDC here (%x)
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
创建Docker编排文件
vi docker-compose.yaml
version:'2'services:zookeeper:container_name: zookeeper
image: wurstmeister/zookeeper
restart: unless-stopped
hostname: zoo1
##volumes:##- "/tmp/zookeeper/zookeeper/data:/data"##- "/tmp/zookeeper/zookeeper/datalog:/datalog"##- "/tmp/zookeeper/zookeeper/logs:/logs"##- "/tmp/zookeeper/zookeeper/conf:/opt/zookeeper-3.4.13/conf"ports:-"2181:2181"networks:- kafka
kafka1:container_name: kafka1
image: wurstmeister/kafka
ports:-"9091:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.56.101 ## 修改:宿主机IPKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.56.101:909## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT:"zoo1:2181"KAFKA_ADVERTISED_PORT:9091KAFKA_BROKER_ID:1KAFKA_LOG_DIRS: /kafka/data
volumes:- /tmp/kafka/broker1/logs:/opt/kafka/logs
- /tmp/kafka/broker1/data:/kafka/data
depends_on:- zookeeper
networks:- kafka
kafka2:container_name: kafka2
image: wurstmeister/kafka
ports:-"9092:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.56.101 ## 修改:宿主机IPKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.56.101:9092## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT:"zoo1:2181"KAFKA_ADVERTISED_PORT:9092KAFKA_BROKER_ID:2KAFKA_LOG_DIRS: /kafka/data
volumes:- /tmp/kafka/broker2/logs:/opt/kafka/logs
- /tmp/kafka/broker2/data:/kafka/data
depends_on:- zookeeper
networks:- kafka
kafka3:container_name: kafka3
image: wurstmeister/kafka
ports:-"9093:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.56.101 ## 修改:宿主机IPKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.56.101:9093## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT:"zoo1:2181"KAFKA_ADVERTISED_PORT:9093KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR:3KAFKA_MIN_INSYNC_REPLICAS:2KAFKA_BROKER_ID:3KAFKA_LOG_DIRS: /kafka/data
volumes:- /tmp/kafka/broker3/logs:/opt/kafka/logs
- /tmp/kafka/broker3/data:/kafka/data
depends_on:- zookeeper
networks:- kafka
kafka-manager:image: sheepkiller/kafka-manager ## 镜像:开源的web管理kafka集群的界面environment:ZK_HOSTS: 192.168.56.101 ## 修改:宿主机IPports:-"9090:9090"## 暴露端口networks:- kafka
networks:kafka:driver: bridge
启动服务
docker-compose up -d
Kafka集群搭建(kraft模式)
为什么kafka依赖zookeeper?
zookeeper是一个开源的分布式应用协调系统,用于管理分布式应用程序,kafka使用zookeeper存储kafka集群元数据信息,包括主题配置、主题分区位置等,可以说,kafka没有zookeeper就无法工作。
如何让kafka摆脱zookeeper依赖?
使用zookeeper充当kafka的外部元数据管理系统存在一些问题,例如数据重复、增加部署复杂度,需要额外的java进程等。
Apache Kafka3.0.0的发布为kafka彻底去掉Zookeeper铺平了道路,Kafka Raft 支持元数据主题的快照以及自我管理,而3.1.0版本在2022.1.24发布,对3.0.0版本又修改了
为了在没有zookeeper的情况下运行kafka,可以使用kafka Raft元数据模式(KRaft)运行它,当 Kafka 集群处于 KRaft 模式时,它将元数据存储在控制器节点的 KRaft 仲裁中,元数据将存储在内部kafka topic
@metadata
中。
注意,KRaft目前还处于早期实验阶段,不应在生产中使用,但可在 kafka 2.8 版本中进行测试。
KRaft简介
Kafka的共识机制KRaft,仍然处于预览机制。未来KRaft将作为Apache Kafka的内置共识机制将取代Zookeeper,该模式在2.8版本当中就已经发布了体验版本,在3.X系列中KRaft是一个稳定release版本。
KRaft运行模式的kafka集群,不会将元数据存储在zookeeper中,即部署新集群的时候,无需部署zk集群,因为Kafka将元数据存储在Controller节点的KRaft Quorum中。KRAFT可以带来很多好处,比如可以支持更多的分区,更快速的切换Controller,也可以避免Controller缓存的元数据和zk存储的数据不一致带来的一系列问题。
KRaft架构
首先来看一下KRaft在系统架构层面和之前的版本有什么区别,KRaft模式提出来去zookeeper后的kafka整体架构入下图是前后架构图对比:
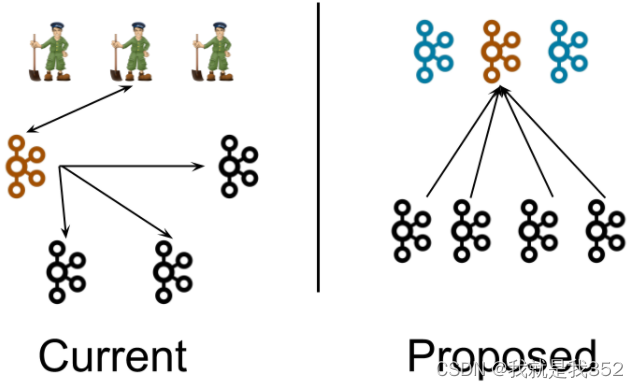
上图中黑色代表 Broker(消息代理服务),褐色/蓝色代表 Controller(集群控制器)
左图(kafka2.0)
一个集群所有节点都是 Broker 角色,利用 zookeeper 的选举能力从三个 Broker 中选举出来一个 Controller 控制器,同时控制器将集群元数据信息(比如主题分类、消费进度等)保存到 zookeeper,用于集群各节点之间分布式交互。
右图(kafka3.0)
假设一个集群有四个 Broker,配置指定其中三个作为 Conreoller 角色(蓝色)。使用 kraft 机制实现 controller 主控制器的选举,从三个 Controller 中选举出来一个 Controller 作为主控制器(褐色),其他的 2 个备用。zookeeper 不再被需要。相关的集群元数据信息以 kafka 日志的形式存在(即:以消息队列消息的形式存在)。
服务部署
部署规划
首先目前官方页面上并没有集群搭建文档,我们下载安装包,可以查看config/kraft下的README.md文件,根据说明,这里我搭建Kraft模式的kafka集群,这里我用的是3.3.1版本
HOSTNAMEIPOSkafka01192.168.245.129centos7.9kafka02192.168.245.130centos7.9kafka03192.168.245.131centos7.9
准备工作
安装JDK11
kafka3.0 不再支持 JDK8,建议安装 JDK11 或 JDK17,事先安装好
下载kafka
三台机器都需要下载Kafka
mkdir /usr/local/kafka/ &&cd /usr/local/kafka/
wget https://downloads.apache.org/kafka/3.3.1/kafka_2.12-3.3.1.tgz
解压安装
kafka安装包下载完成后就需要解压以及创建日志目录了
tar-zxvf kafka_2.12-3.3.1.tgz
cd kafka_2.12-3.3.1 &&mkdir logs
配置server.properties
我们需要配置
kraft的配置文件,该文件在kafka的
config/kraft/server.properties目录下
kafka01配置
vi config/kraft/server.properties
#节点角色
process.roles=broker,controller
#节点ID,和节点所承担的角色想关联
node.id=1
# 集群地址
[email protected]:9093,[email protected]:9093,[email protected]:9093
#本机节点
listeners=PLAINTEXT://192.168.245.129:9092,CONTROLLER://192.168.245.129:9093
#本机节点
advertised.listeners=PLAINTEXT://192.168.245.129:9092
# 这里我修改了日志文件的路径
log.dirs=/usr/local/kafka/kafka_2.12-3.3.1/logs
kafka02配置
vi config/kraft/server.properties
#节点角色
process.roles=broker,controller
#节点ID,和节点所承担的角色想关联
node.id=1
# 集群地址
[email protected]:9093,[email protected]:9093,[email protected]:9093
#本机节点
listeners=PLAINTEXT://192.168.245.129:9030,CONTROLLER://192.168.245.130:9093
#本机节点
advertised.listeners=PLAINTEXT://192.168.245.130:9092
# 这里我修改了日志文件的路径
log.dirs=/usr/local/kafka/kafka_2.12-3.3.1/logs
kafka03配置
vi config/kraft/server.properties
#节点角色
process.roles=broker,controller
#节点ID,和节点所承担的角色想关联
node.id=1
# 集群地址
[email protected]:9093,[email protected]:9093,[email protected]:9093
#本机节点
listeners=PLAINTEXT://192.168.245.131:9092,CONTROLLER://192.168.245.131:9093
#本机节点
advertised.listeners=PLAINTEXT://192.168.245.131:9092
# 这里我修改了日志文件的路径
log.dirs=/usr/local/kafka/kafka_2.12-3.3.1/logs
配置参数解释
Process.Roles
每个Kafka服务器现在都有一个新的配置项,叫做Process.Roles, 这个参数可以有以下值:
- 如果Process.Roles = Broker, 服务器在KRaft模式中充当 Broker。
- 如果Process.Roles = Controller, 服务器在KRaft模式下充当 Controller。
- 如果Process.Roles = Broker,Controller,服务器在KRaft模式中同时充当 Broker 和Controller。
- 如果process.roles 没有设置。那么集群就假定是运行在ZooKeeper模式下。
如前所述,目前不能在不重新格式化目录的情况下在ZooKeeper模式和KRaft模式之间来回转换。同时充当Broker和Controller的节点称为“组合”节点。
对于简单的场景,组合节点更容易运行和部署,可以避免多进程运行时,JVM带来的相关的固定内存开销。关键的缺点是,控制器将较少地与系统的其余部分隔离,例如,如果代理上的活动导致内存不足,则服务器的控制器部分不会与该OOM条件隔离。
node.id
这将作为集群中的节点 ID,唯一标识,按照我们事先规划好的(上文),在不同的服务器上这个值不同。
其实就是 kafka2.0 中的
broker.id
,只是在 3.0 版本中 kafka 实例不再只担任 broker 角色,也有可能是 controller 角色,所以改名叫做 node 节点。
Quorum Voters
系统中的所有节点都必须设置
controller.quorum.voters配置,这个配置标识有哪些节点是 Quorum 的投票者节点
所有想成为控制器的节点都需要包含在这个配置里面。这类似于在使用ZooKeeper时,使用ZooKeeper.connect配置时必须包含所有的ZooKeeper服务器,然而,与ZooKeeper配置不同的是,
controller.quorum.voters
配置需要包含每个节点的id。格式为: id1@host1:port1,id2@host2:port2。
搭建KRaft集群
生成集群ID
生成一个唯一的集群 ID(在一台 kafka 服务器上执行一次即可),这一个步骤是在安装 kafka2.0 版本的时候不存在的
sh bin/kafka-storage.sh random-uuid
k4CR-54TQZajZSvxWkADtQ
格式化数据目录
使用生成的集群 ID+配置文件格式化存储目录
log.dirs,所以这一步确认配置及路径确实存在,并且 kafka 用户有访问权限(检查准备工作是否做对),每一台主机服务器都要执行这个命令
sh bin/kafka-storage.sh format-t k4CR-54TQZajZSvxWkADtQ -c config/kraft/server.properties
查看meta.properties
格式化操作完成之后,你会发现在我们定义的
log.dirs目录下多出一个
meta.properties文件
meta.properties
文件中存储了当前的 kafka 节点的 id(
node.id
),当前节点属于哪个集群(
cluster.id
)
cat logs/meta.properties

启动集群
可以使用下面的命令来启动集群
nohupsh bin/kafka-server-start.sh config/kraft/server.properties 1>/dev/null 2>&1&
创建主题
sh bin/kafka-topics.sh --create--topictest--partitions1 --replication-factor 1 --bootstrap-server 192.168.245.129:9092

查看主题列表
sh bin/kafka-topics.sh --list --bootstrap-server 192.168.245.129:9092

查看主题信息
sh bin/kafka-topics.sh --bootstrap-server 192.168.245.129:9092 --describe--topictest

Docker方式部署
创建数据目录
mkdir-p /tmp/kafka/broker{1..3}/{data,logs}
创建Docker编排文件
vi docker-compose.yaml
version:"3"services:kafka01:container_name: kafka01
image: bitnami/kafka:3.3.1
user: root
ports:-'9092:9092'environment:- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.245.129:9092- KAFKA_BROKER_ID=1
- KAFKA_KRAFT_CLUSTER_ID=LelM2dIFQkiUFvXCEcqRWA
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01:9093,2@kafka02:9093,3@kafka03:9093- ALLOW_PLAINTEXT_LISTENER=yes
volumes:- /tmp/kafka/broker1/data:/bitnami/kafka
networks:- kafka
kafka02:container_name: kafka02
image: bitnami/kafka:3.3.1
user: root
ports:-'9192:9092'environment:- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.245.129:9192- KAFKA_BROKER_ID=2
- KAFKA_KRAFT_CLUSTER_ID=LelM2dIFQkiUFvXCEcqRWA
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01:9093,2@kafka02:9093,3@kafka03:9093- ALLOW_PLAINTEXT_LISTENER=yes
volumes:- /tmp/kafka/broker2/data:/bitnami/kafka
networks:- kafka
kafka03:container_name: kafka03
image: bitnami/kafka:3.3.1
user: root
ports:-'9292:9092'environment:- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.245.129:9292- KAFKA_BROKER_ID=3
- KAFKA_KRAFT_CLUSTER_ID=LelM2dIFQkiUFvXCEcqRWA
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01:9093,2@kafka02:9093,3@kafka03:9093- ALLOW_PLAINTEXT_LISTENER=yes
volumes:- /tmp/kafka/broker3/data:/bitnami/kafka
networks:- kafka
networks:kafka:driver: bridge
启动服务
docker-compose up -d
版权归原作者 我就是我352 所有, 如有侵权,请联系我们删除。