
系列文章目录
手把手教你,本地RabbitMQ服务搭建(windows)
消息队列选型——为什么选择RabbitMQ
RabbitMQ灵活运用,怎么理解五种消息模型
推或拉? RabbitMQ 消费模式该如何选择
死信是什么,如何运用RabbitMQ的死信机制?
RabbitMQ 能保证消息可靠性吗
前言
前面我们在做MQ组件选型时,提到了rabbitMQ的消息可靠性,那么它到底可靠到什么程度?又是如何保证消息可靠性的呢?今天我们就一起来看一下
一、消息可靠性的定义
消息可靠性是指在消息传递过程中,确保消息能够被完整、准确、可靠地传递到目的地。更具体的说分为两个角度:
- 不会意外丢失
- 不会重复传递
因此,我们必须保证消息不会因为网络故障、系统故障或其他异常原因而丢失或重复传递,否则可能导致业务逻辑错误、数据损坏或系统崩溃等问题
二、几种不可靠的场景
- 消息漏发送:生产者在发送消息时,如果不观察RabbitMQ服务器的确认消息,可能导致有些消息在网络中丢失而不自知
- 消息重复发送:如果生产者在发送消息时,由于网络抖动或者其他原因,生产者无法从RabbitMQ收到消息确认,此时生产者会重发同样一条消息,从而导致消息重复
- 消息未储存:rabbitMQ服务器宕机,导致已经在rabbit服务器内的消息直接丢失
- 消费者重复消费:如果消费者和MQ都不记得曾经消费过的消息,主动拉取或推送了旧的消息,导致重复消费,
三、防意外丢失
在这里,必须提前声明一点:即消息意外丢失,因为rabbitMQ经由转换机,如果匹配不到任何队列,是会主动丢弃该消息的,这种丢失属于业务配置上的主动丢弃,不记在意外丢失中
1. 消息持久化
消息持久化需要在消息生产者修改代码
String MESSAGE ="Hello, RabbitMQ!";// 设置消息持久化
AMQP.BasicProperties properties =newAMQP.BasicProperties.Builder().contentType("text/plain").deliveryMode(2)// deliveryMode=1代表不持久化,deliveryMode=2代表持久化.build();
channel.basicPublish("", MESSAGE_QUEUE, properties, MESSAGE.getBytes("UTF-8"));
也可以直接使用内置的properties
channel.basicPublish("", MESSAGE_QUEUE, MessageProperties.PERSISTENT_TEXT_PLAIN, MESSAGE.getBytes("UTF-8"));
2. 队列持久化
尽管我们上面已经使用了消息持久化,但是这是不够的,消息本身不会作为一个实体存在硬盘上,真正落在硬盘上的是队列,及队列中的消息。所以,要想保存消息,还得把消息所在的队列持久化,因此需要在声明队列时,将其 durable 属性设置为true
// 设置队列持久化boolean durable =true;
channel.queueDeclare(QUEUE_NAME, durable,false,false, null);
注意,该属性不可修改,如果要把一个队列改成持久化,得先删除,再创建才行
3. 发布确认
我们上面已经成功把消息做了持久化,不过这并不能彻底避免消息丢失,比如在消息发布者发布消息的过程中,在消息成功持久化之前,rabbitMQ就崩溃了,此时消息仍然会丢失。因此,有必要执行发布确认的操作
即消息发送后,MQ要对生产者发送消息确认,确认已经持久化后,再进行发布确认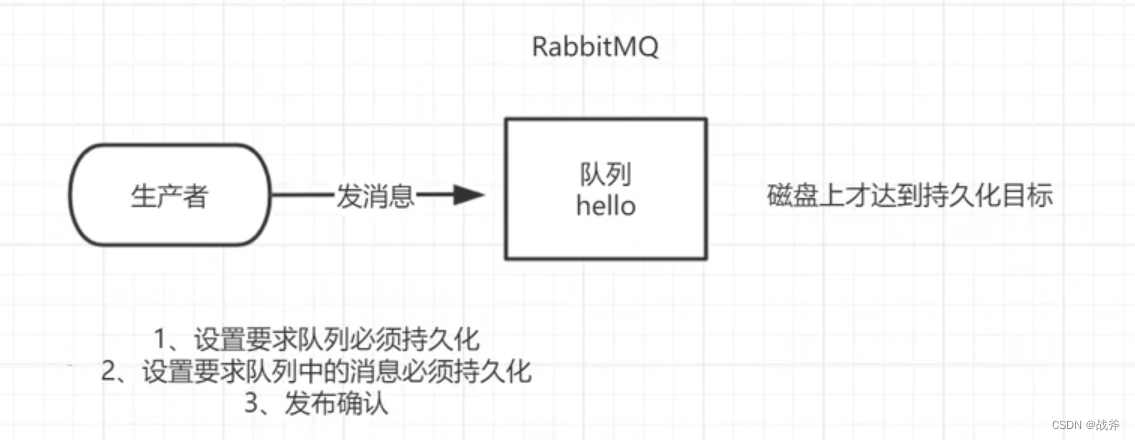
发布确认默认不开启,如果要开启,需要在channel上设置
Channel channel = connection.createChannel();// 将信道设置为发布确认
channel.confirmSelect();
进行完该项设置后,还需要针对确认消息的类型,适当的修改发送方代码。一般来说,发布确认有以下类型
3.1 简单发布确认
即发送后,单条单条的消息是否被rabbitMQ服务器接受
String message ="Hello, RabbitMQ!";
channel.queueDeclare(QUEUE_NAME,false,false,false, null);// 设置简单发布确认
channel.confirmSelect();
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());if(channel.waitForConfirms()){
System.out.println("Message published successfully.");}else{
System.err.println("Failed to publish message.");}
可以看到,这种方式其实采用的是发一条消息,确认一次,效率并不高。
3.2 批量发布确认
批量发布和简单发布,在调用方法上并没有区别,只是发送的消息,从发一条就等待确认一次,变成了发一批,才确认一次。
int MESSAGE_COUNT =100;
String message ="Hello, RabbitMQ!";
channel.queueDeclare(QUEUE_NAME,false,false,false, null);// 设置批量发布确认
channel.confirmSelect();for(int i =0; i < MESSAGE_COUNT; i++){
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());}int outstandingConfirms = MESSAGE_COUNT;while(outstandingConfirms >0){
outstandingConfirms -= channel.waitForConfirms();}
System.out.println("All messages published successfully.");
此种方式,虽然仍然会同步阻塞,但从每条确认一次进化到批量确认一次,大大节约了网络耗时。但是可能会出现一些消息发布成功,但是一些消息未成功的情况,不易进行排查和处理。
3.3 异步发布确认
异步确认则采用的另一种方案,通过给channel设置一个确认监听器,来异步的做确认,即将发布消息和确认处理放在不同的线程中处理
int MESSAGE_COUNT =100;
String message ="Hello, RabbitMQ!";
ConcurrentNavigableMap<Long, String> outstandingConfirms =newConcurrentSkipListMap<>();
Set<Long> failConfirmMessages =newHashSet<>();// 异步发布确认
channel.confirmSelect();// 需设置两个监听器,前者为肯定确认,后者为否定确认
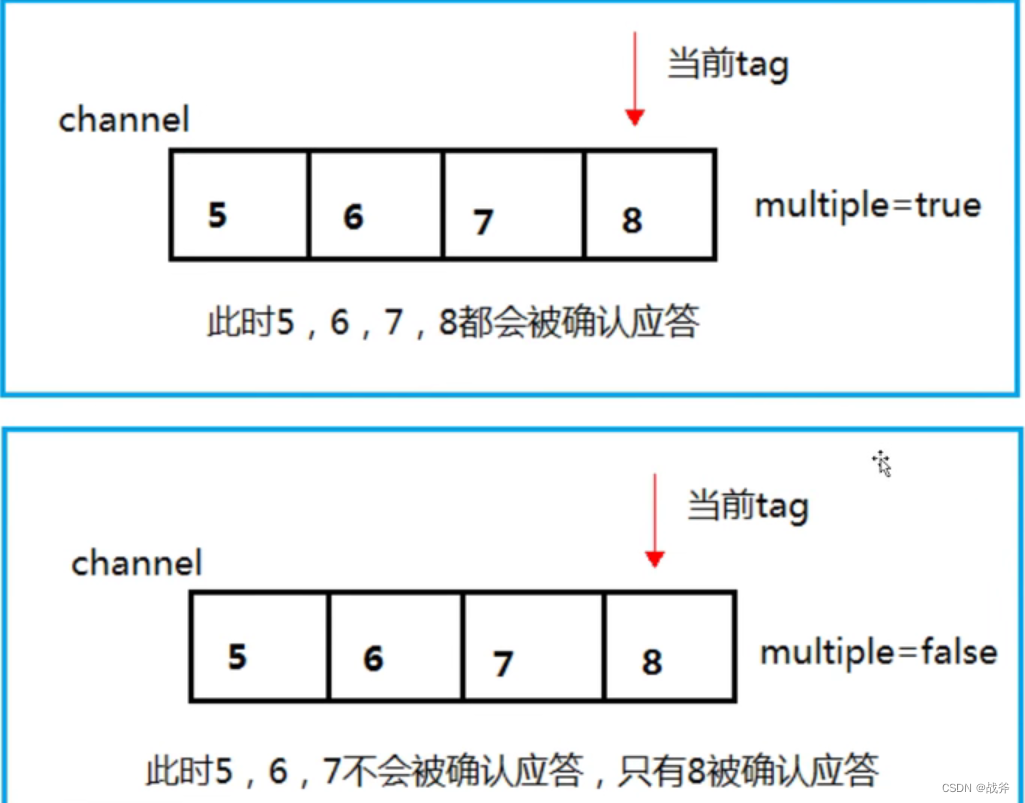
channel.addConfirmListener(newConfirmCallback(){@Override// deliveryTag 代表 投递消息的序号;multiple为true,则代表确认所有小于或等于当前消息deliveryTag的状态,为false,代表仅确认该条消息publicvoidhandle(long deliveryTag,boolean multiple)throws IOException {if(multiple){
ConcurrentNavigableMap<Long, String> confirmed = outstandingConfirms.headMap(deliveryTag,true);// 清除所有小于该序号的消息
confirmed.clear();}else{// 仅清除本条消息
outstandingConfirms.remove(deliveryTag);}}},newConfirmCallback(){@Overridepublicvoidhandle(long deliveryTag,boolean multiple)throws IOException {
System.err.println("Failed to publish message.");
failConfirmMessages.add(deliveryTag);}});for(int i =0; i < MESSAGE_COUNT; i++){long nextSeqNo = channel.getNextPublishSeqNo();
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
outstandingConfirms.put(nextSeqNo, message);}// 一段时间过后......// 看最后是否还有消息被确认丢失,此时可选择是否要重新发送if(failConfirmMessages .size()==0&& outstandingConfirms.size()==0){
System.out.println("All messages published successfully.");}else{
System.out.println("Some messages need republish.");}
通过异步方式做确认,能提升性能,缺点是需要一些多线程的知识,实现难度较高。
4. 手动接收确认
如果第三点,是保证消息发送者到MQ服务器之间,消息不会丢失。那么同理,还需要保证MQ服务器到消费者间,消息不会丢失。
这时候,就需要手动接收确认了,即消费者得到消息后,先进行业务处理(或消息存储),直到业务处理完成后。再告知rabbitMQ服务器,消息我收到了。从而避免了自动ack后,消费者宕机导致的消息未处理完就丢失的问题,其示例代码如下
// 创建消费者对象final Consumer consumer =newDefaultConsumer(channel){@OverridepublicvoidhandleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,byte[] body)throws IOException {
String message =newString(body,"UTF-8");try{// 处理消息
System.out.println("Received message: "+ message);// 显式 ack 消息
channel.basicAck(envelope.getDeliveryTag(),false);// 第二个参数表示是否批量处理}catch(Exception ex){// 处理消息时发生异常,拒绝消息并重新将其放回队列中
channel.basicNack(envelope.getDeliveryTag(),false,true);}}};// 开始消费消息,使用手动ackboolean autoAck =false;
channel.basicConsume(QUEUE_NAME, autoAck, consumer);
PS:需要注意的是,手动ack可能带来重复消费的问题,比如消息处理成功后,在执行channel.basicAck时宕机,导致RabbitMQ服务器没收到消息接收确认的信号,超时后会认为该消息未被接收
5. 死信队列
在某些情况下(如手动ACK),如消费者在暂时无法处理该消息,RabbitMQ 可能会将消息重新放回队列,但大量的重新放回会导致消息堆积,也是不可取的。
// 如下,消费者可以向rabbitMQ发送nack的消息,且设置requeue参数为falsevoidbasicNack(long deliveryTag,boolean multiple,boolean requeue)throws IOException;
为了避免这种情况,RabbitMQ 提供了死信队列的功能。当消息因为某些原因不能被消费时,RabbitMQ 将消息放入死信队列而不是重新放回队列,防止消息丢失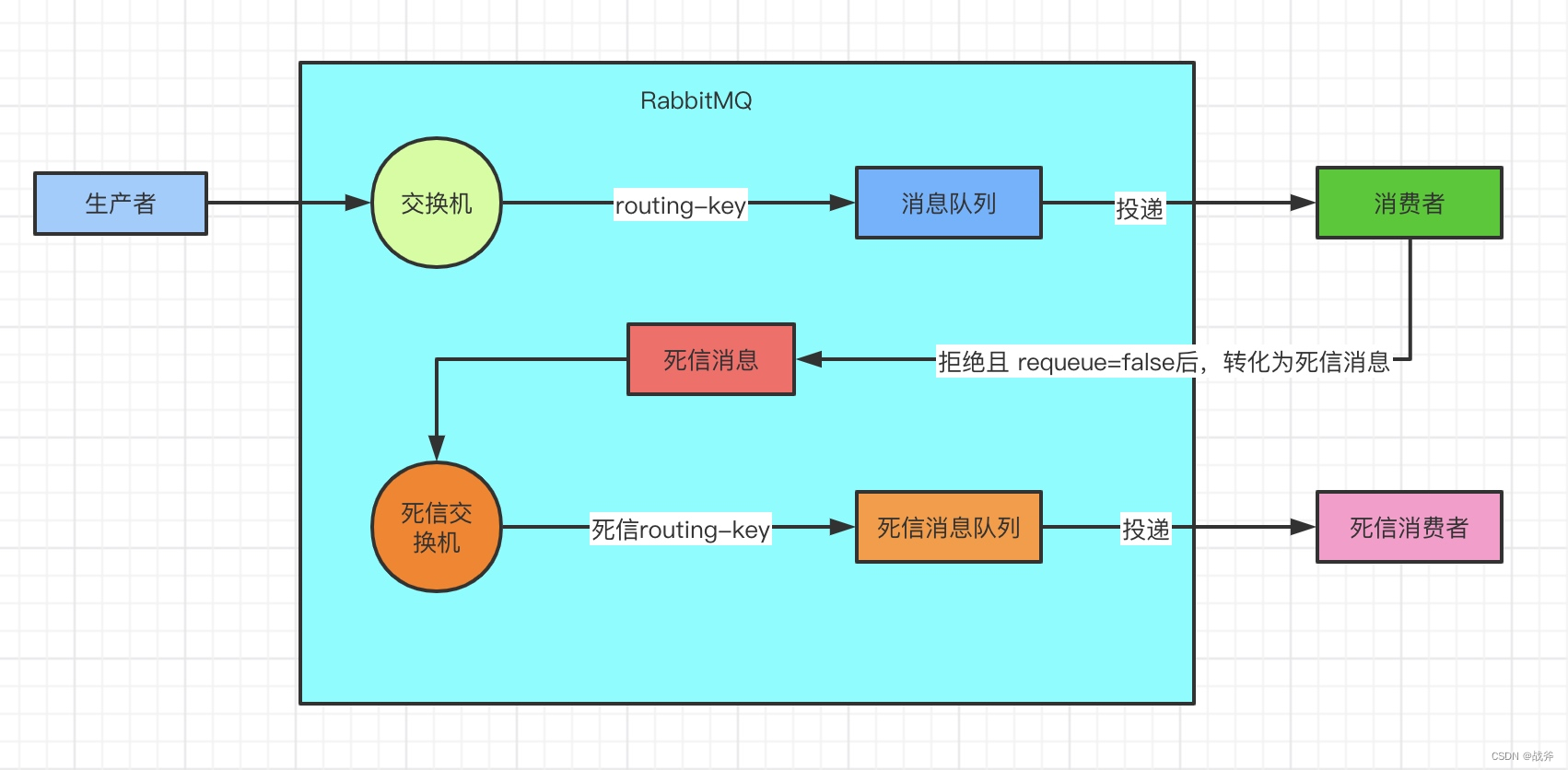
四、防重复传递
上面一节,我们为rabbitMQ在消息传递过程中,各个节点都有防消息丢失的配置。这一节,我们来说rabbitMQ为了防止一条消息重复传递而做的努力
1. 消息确认机制
上面,我们说了发布确认和接收确认。其实,不管是发布和接收,这都属于消息确认机制的一种,而消息确认机制是AMQP协议所规定的。发布确认是为了防止丢失消息,接收确认则是为了防止重复消费,当消费者成功接收到消息并完成处理后,发送确认通知给 RabbitMQ,RabbitMQ 才会将该消息标记为已消费,防止重复传递
2. 幂等性校验(需代码实现)
在消息生产者发送消息之前,消息可以被设置上全局唯一uuid,而消费者在消费前,则会判断该uuid是否已经消费过。
// 生产者发送消息之前,将消息标记为idempotent// 通过设置 messageId 属性为一个唯一值,即可标记该消息为幂等消息
String messageId = UUID.randomUUID().toString();
AMQP.BasicProperties properties =newAMQP.BasicProperties.Builder().messageId(messageId).build();
channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY, properties, message.getBytes());// 消费者在处理消息之前,检查该消息是否已经被消费过// 如果该消息已经被消费过,则直接确认消息
String messageId = properties.getMessageId();if(processedIds.contains(messageId)){
channel.basicAck(envelope.getDeliveryTag(),false);return;}// 处理消息,并将 messageId 加入已处理集合// ...
processedIds.add(messageId);
以上代码仅展示原理,实际上分布式高并发的情况下,uuid应该交由专门的服务器用雪花算法等方式去产生全局唯一的uuid。同样消费者处的processedIds也会进行远端存储
五、不可靠场景的对策
现在,让我们回头来看看不可靠场景下,rabbitMQ和我们开发者能用什么对策解决
- 消息漏发送:生产者在发送消息时,如果不观察RabbitMQ服务器的确认消息,可能导致有些消息在网络中丢失而不自知
- 消息重复发送:如果生产者在发送消息时,由于网络抖动或者其他原因,生产者无法从RabbitMQ收到消息确认,此时生产者会重发同样一条消息,从而导致消息重复
- 消息未储存:rabbitMQ服务器宕机,导致已经在rabbit服务器内的消息直接丢失
- 消费者重复消费:如果消费者不记得曾经消费过的消息,主动拉取或被推送了旧的消息,导致重复消费,
场景场景解释解决对策消息漏发送生产者在发送消息时,如果不观察RabbitMQ服务器的确认消息,可能导致有些消息在网络中丢失而不自知发布确认消息重复发送如果生产者在发送消息时,由于网络抖动或者其他原因,生产者无法从RabbitMQ收到消息确认,此时生产者会重发同样一条消息,从而导致消息重复无策略消息未储存rabbitMQ服务器宕机,导致已经在rabbit服务器内的消息直接丢失队列、消息持久化消费者重复消费如果消费者和MQ都不记得曾经消费过的消息,主动拉取或推送了旧的消息,导致重复消费接受确认、幂等性校验(代码实现)六、总结
RabbitMQ 能保证消息可靠性吗?答案是绝大部分情况可靠,但仅靠其自身机制无法做到100%。比如对于没有收到发布确认信息,导致消息生产者重复传递这种场景就并没有好的办法,只能通过开发者额外代码去解决,比如发消息带全局唯一id,然后由消费者去做幂等性校验。而针对更极端的场景,如RabbitMQ硬盘故障导致消息丢失,就得依托镜像部署等手段去处理了
版权归原作者 战斧 所有, 如有侵权,请联系我们删除。