
文章目录
一、什么是CDC
1.CDC介绍
CDC 是变更数据捕获(Change Data Capture)技术的缩写,它可以将源数据库(Source)的增量变动记录,同步到一个或多个数据目的(Sink)。在同步过程中,还可以对数据进行一定的处理,例如分组(GROUP BY)、多表的关联(JOIN)等。例如对于电商平台,用户的订单会实时写入到某个源数据库;A 部门需要将每分钟的实时数据简单聚合处理后保存到 Redis 中以供查询,B 部门需要将当天的数据暂存到 Elasticsearch 一份来做报表展示,C 部门也需要一份数据到 ClickHouse 做实时数仓。随着时间的推移,后续 D 部门、E 部门也会有数据分析的需求,这种场景下,传统的拷贝分发多个副本方法很不灵活,而 CDC 可以实现一份变动记录,实时处理并投递到多个目的地。
2.CDC原理
通常来讲,CDC 分为主动查询和事件接收两种技术实现模式。
主动查询模式(基于查询):用户通常会在数据源表的某个字段中,保存上次更新的时间戳或版本号等信息,然后下游通过不断的查询和与上次的记录做对比,来确定数据是否有变动,是否需要同步。这种方式优点是不涉及数据库底层特性,实现比较通用;缺点是要对业务表做改造,且实时性不高,不能确保跟踪到所有的变更记录,且持续的频繁查询对数据库的压力较大。
事件接收模式(基于Binlog):可以通过触发器(Trigger)或者日志(例如 Transaction log、Binary log、Write-ahead log 等)来实现。当数据源表发生变动时,会通过附加在表上的触发器或者 binlog 等途径,将操作记录下来。下游可以通过数据库底层的协议,订阅并消费这些事件,然后对数据库变动记录做重放,从而实现同步。这种方式的优点是实时性高,可以精确捕捉上游的各种变动;缺点是部署数据库的事件接收和解析器(例如 Debezium、Canal 等),有一定的学习和运维成本,对一些冷门的数据库支持不够。综合来看,事件接收模式整体在实时性、吞吐量方面占优,如果数据源是 MySQL、PostgreSQL、MongoDB 等常见的数据库实现,建议使用Debezium来实现变更数据的捕获。
两者之间的区别: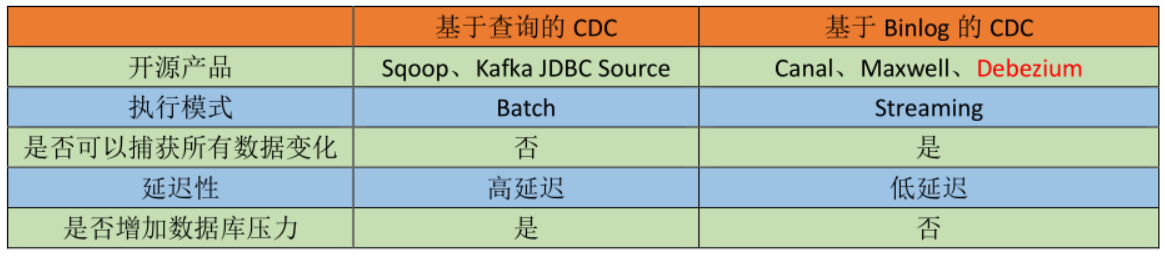
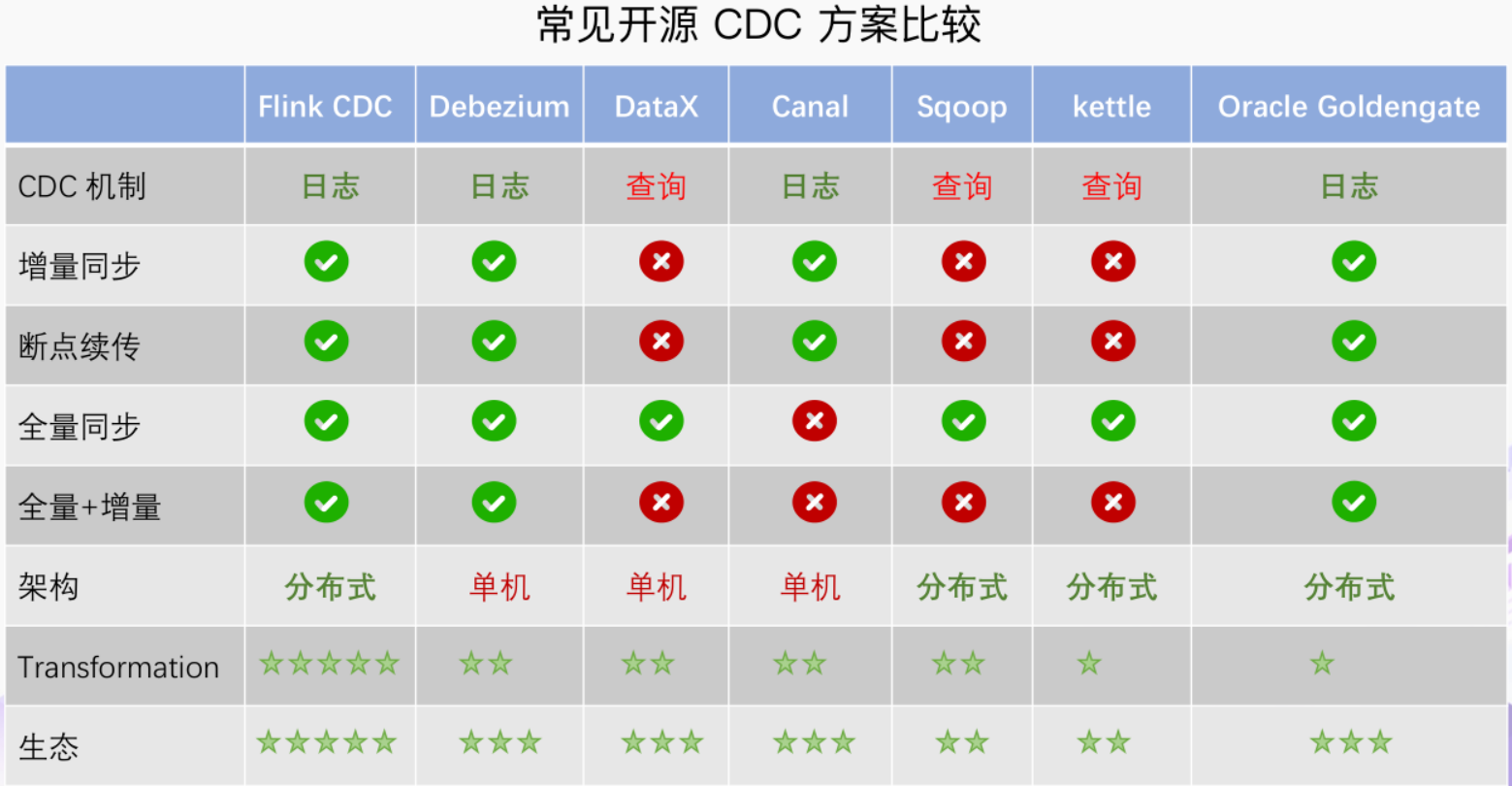
在最新 CDC 调研报告中,Debezium 和 Canal 是目前最流行使用的 CDC 工具,这些 CDC 工具的核心原理是抽取数据库日志获取变更。
在经过一系列调研后,目前 Debezium (支持全量、增量同步,同时支持 MySQL、PostgreSQL、Oracle 等数据库),使用较为广泛。
二、什么是FLink CDC
Flink社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址:https://github.com/ververica/flink-cdc-connectors
Flink CDC connector 可以捕获在一个或多个表中发生的所有变更。该模式通常有一个前记录和一个后记录。Flink CDC connector 可以直接在Flink中以非约束模式(流)使用,而不需要使用类似 kafka 之类的中间件中转数据。
Flink SQL CDC 内置了 Debezium 引擎,利用其抽取日志获取变更的能力,将
changelog 转换为 Flink SQL 认识的 RowData 数据。
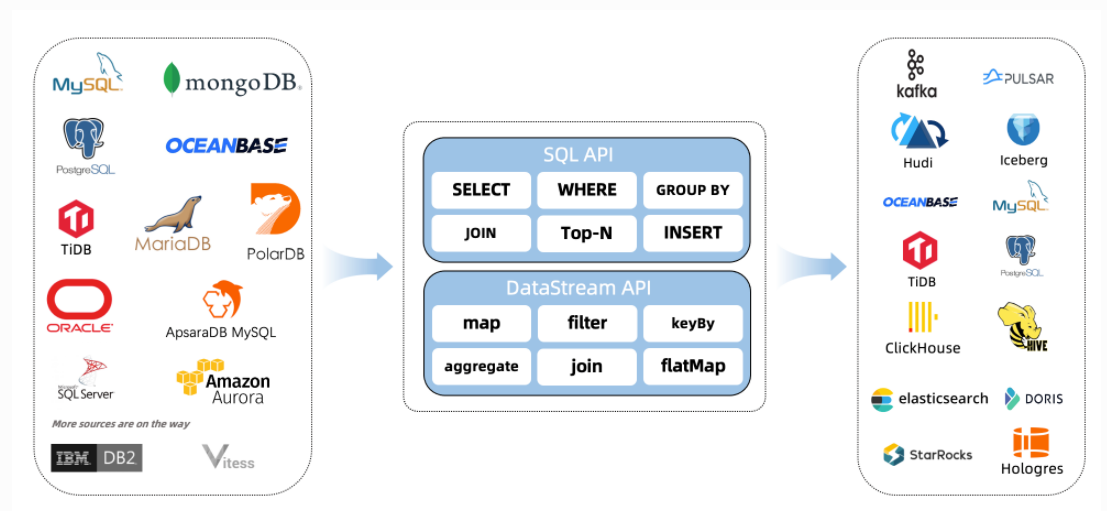


三、为什么要使用FLink CDC
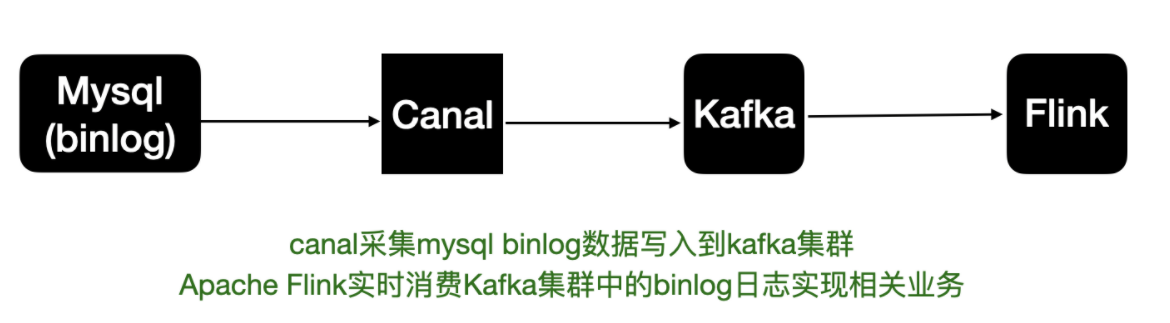
之前的mysql binlog日志处理流程,例如canal监听binlog把日志写入到kafka中。而Flink实时消费Kakfa的数据实现mysql数据的同步或其他内容等。
拆分来说整体上可以分为以下几个阶段:
- mysql开启binlog
- canal同步binlog数据写入到kafka
- flink读取kakfa中的binlog数据进行相关的业务处理。
整体的处理链路较长,需要用到的组件也比较多。Apache Flink CDC可以直接从数据库获取到binlog供下游进行业务计算分析。简单来说链路如下图:
四、FLink CDC代码样例
1.POM依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><scala.version>2.12</scala.version><flink.version>1.13.5</flink.version><java.version>1.8</java.version><maven.compiler.source>${java.version}</maven.compiler.source><maven.compiler.target>${java.version}</maven.compiler.target></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.12.15</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>2.12.15</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-state-processor-api_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-scala-bridge_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-cep-scala_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-oracle-cdc</artifactId><version>2.2.1</version></dependency></dependencies>
2.DataStream方式
importcom.ververica.cdc.connectors.oracle.OracleSource
importcom.ververica.cdc.connectors.oracle.table.StartupOptions
importcom.ververica.cdc.debezium.JsonDebeziumDeserializationSchema
importorg.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTypeInformation}importorg.apache.flink.streaming.api.functions.source.SourceFunction
object TestDateStreamCDC {def main(args: Array[String]):Unit={// flink cdc 监听数据变动val sourceFunction: SourceFunction[String]= OracleSource
.builder[String].hostname("IP").port(1521).database("phis").schemaList("XXX")//可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式.tableList("XXX.TEST").username("name").password("1234").deserializer(new JsonDebeziumDeserializationSchema).startupOptions(StartupOptions.latest()).build
//创建执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment
env.addSource(sourceFunction).print.setParallelism(1)// use parallelism 1 for sink to keep message ordering//执行任务
env.execute()}}
3.FlinkSQL方式
importorg.apache.flink.streaming.api.scala.StreamExecutionEnvironment
importorg.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object TestFlinkSQLCDC {def main(args: Array[String]):Unit={val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)// use parallelism 1 for sink to keep message orderingval tableEnv = StreamTableEnvironment.create(env)
tableEnv.executeSql("CREATE TABLE TEST ("+" id INT NOT NULL,"+" username STRING,"+" password STRING,"+" PRIMARY KEY(id) NOT ENFORCED "+" ) WITH ( "+" 'connector' = 'oracle-cdc',"+" 'hostname' = 'ip',"+" 'port' = '1521',"+" 'username' = 'name',"+" 'password' = '1234',"+" 'database-name' = 'phis',"+" 'schema-name' = 'XXX',"+" 'table-name' = 'TEST' )")
tableEnv.executeSql("select * from TEST").print
env.execute
}}
结尾
- 感谢大家的耐心阅读,如有建议请私信或评论留言。
- 如有收获,劳烦支持,关注、点赞、评论、收藏均可,博主会经常更新,与大家共同进步
版权归原作者 Xd聊架构 所有, 如有侵权,请联系我们删除。