
一、什么是Spark
Apache Spark™是一个多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习。

Spark最初由美国加州大学伯克利分校的AMP实验室于2009年开发,基于内存计算,适用于构建大型、低延迟的数据分析应用程序。Spark支持多种编程语言,如Java、Scala、Python和R,并提供了高级别的API,用于在分布式环境中进行大规模数据处理和分析。Spark的核心组件包括Spark Core、Spark SQL、Spark Streaming、MLlib等,它能够处理结构化数据、实时数据,并支持机器学习算法。Spark以其高性能、易用性和灵活性而闻名,能够在内存中保留数据,避免磁盘I/O的开销,从而提高计算速度和吞吐量。此外,Spark可以与Hadoop分布式文件系统(HDFS)等数据源集成,支持批处理、迭代算法、交互式查询和流处理等多种计算模式。
1.1 特点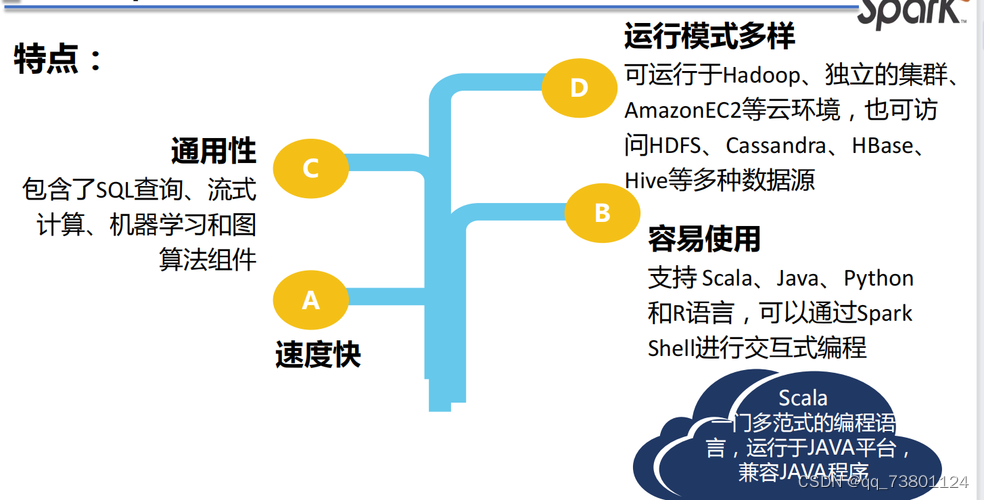
速度快:一般情况下,对于迭代次数较多的应用程序,Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。
易用性:Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高阶算子,使得编写并行应用程序变得容易,并且可以在Scala、Python或R的交互模式下使用Spark。
通用性:Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming(流计算),并且支持在一个应用中同时使用这些组件。
运行模式多样:用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。
1.2 spark的生态圈
Spark 生态圈是加州大学伯克利分校的 AMP 实验室打造的,是一个力图在算法(Algorithms)、机器(Machines)、人(People)之间通过大规模集成来展现大数据应用的平台。
AMP 实验室运用大数据、云计算、通信等各种资源及各种灵活的技术方案,对海量不透明的数据进行甄别并转化为有用的信息,以供人们更好地理解世界。该生态圈已经涉及机器学习、数据挖掘、数据库、信息检索、自然语言处理和语音识别等多个领域。

Spark Core:Spark核心,提供底层框架及核心支持。包含Spark的基本功能,包括任务调度、内存管理、容错机制等。
BlinkDB:一个用于在海量数据上运行交互式SQL查询的大规模并行查询引擎。
Spark SQL:可以执行SQL查询,包括基本的SQL语法和HiveQL语法。可读取的数据源包括Hive、HDFS、关系数据库(如MySQL)等。
Spark Streaming:可以进行实时数据流式计算。

MLBase:专注于机器学习,让机器学习的门槛更低,让一些可能并不了解机器学习的用户也能方便地使用MLBase。MLBase由4部分组成:MLlib、MLI、ML Optimizer和MLRuntime。
MLlib:MLBase的一部分,MLlib是Spark的数据挖掘算法库,实现了一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化。

GraphX:图计算的应用在很多情况下处理的数据量都是很庞大的。如果用户需要自行编写相关的图计算算法,并且在集群中应用,难度是非常大的。而使用GraphX即可解决这个问题,因为它内置了许多与图相关的算法,如在移动社交关系分析中可使用图计算相关算法进行处理和分析。

SparkR:SparkR是AMPLab发布的一个R开发包,使得R摆脱单机运行的命运,可以作为Spark的Job运行在集群上,极大地扩展了R的数据处理能力。
二、Spark与Hadoop的区别和联系
Spark 和 Hadoop 是两个不同的开源大数据处理框架,它们各有特色且可以相互补充。以下是它们之间的主要区别和联系:
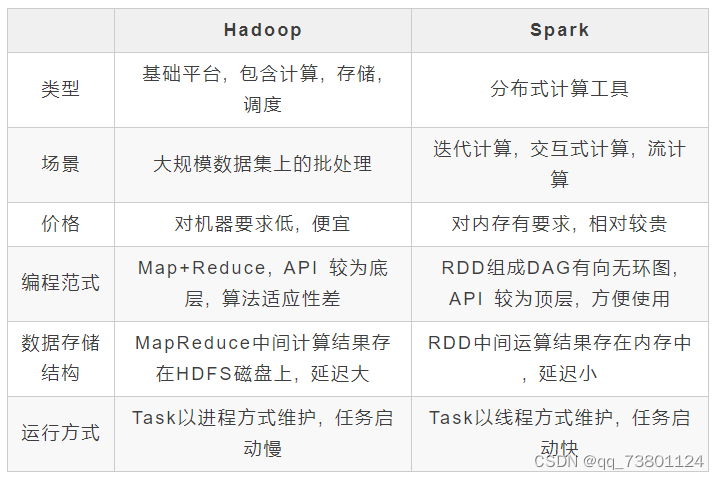
2.1 区别
处理方式:Spark是基于内存的计算框架,而Hadoop是基于磁盘的存储和计算框架。因此,Spark的数据处理速度比Hadoop更快。
计算模型:Spark采用的是基于内存的数据处理模型,可以在内存中缓存数据,从而加快数据处理速度。而Hadoop采用的是MapReduce模型,需要将数据写入磁盘,再进行计算。
执行引擎:Spark使用的是RDD(Resilient Distributed Datasets)执行引擎,可以在内存中缓存数据,支持多种数据处理操作。而Hadoop使用的是基于MapReduce的执行引擎,只能进行Map和Reduce操作。
应用场景:Spark适用于需要对数据进行实时处理和交互式查询的场景,如机器学习、图形处理等。而Hadoop适用于需要处理海量数据的批量处理场景,如数据清洗、日志分析等。
2.2 联系
处理大数据:Hadoop和Spark都是用于处理大数据的工具。
并行计算:两者都支持分布式并行计算。
生态系统:两者都有丰富的生态系统,包括各种工具、库和插件等。
总之,Hadoop和Spark都是大数据处理领域的重要工具,它们各有优缺点,在不同的场景中有不同的应用。
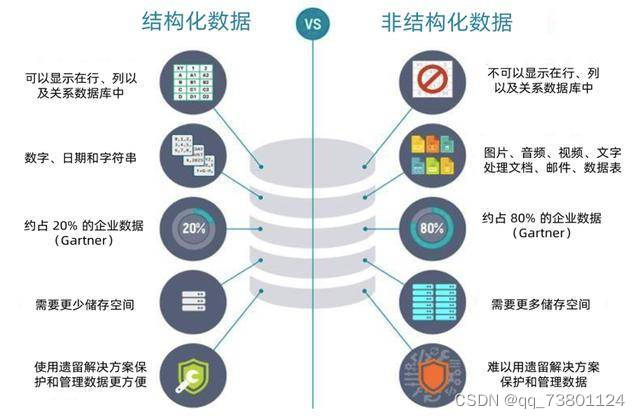
三、结构化数据与非结构化数据的区别
**结构化数据:**是指由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。也称作行数据,一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
**非结构化数据:**是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、HTML、各类报表、图像和音频/视频信息等等。而非结构化数据更难让计算机理解。
四、spark架构
spark是一个分布式的大数据处理引擎,它集成了多种计算功能,如SQL查询、图处理、机器学习、流处理等。Spark的核心架构包括以下几个部分:
- Cluster Manager:负责整个集群的资源管理和分配。Spark支持多种资源管理器,包括自带的Cluster Manager、Mesos Cluster Manager和Hadoop YARN Cluster Manager。
- Worker Node:执行任务的计算节点,负责分区任务的执行。
- Driver Task:应用程序的入口点,负责解析用户的应用程序代码,将任务划分成一系列的任务(stage),并在集群上为任务安排调度。
- Executor:在每个工作节点上运行的进程,负责实际执行任务。每个Executor都运行在自己的JVM进程中,并且为应用程序分配了一定数量的内存和CPU资源。
Spark的架构设计遵循Master/Slave模式,其中Driver节点作为Master,负责管理整个集群中的作业任务调度,而Executor节点作为Slave,负责执行任务。Spark应用程序通过Driver节点向Cluster Manager申请资源,然后在Worker节点上启动一批Executor。在执行阶段,Driver会将task和task所依赖的file和jar包序列化后传递给对应的Worker机器,同时Executor对相应数据分区的任务进行处理。

4.1 了解spark运行流程
local模式【本机模式】:单机运行,通常用于测试。
standalone模式:与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。
Spark on Mesos/yarn模式:Spark程序运行在资源管理器上,例如YARN/Mesos
Spark on Yarn存在两种模式
• yarn-client

• yarn-cluster

版权归原作者 qq_73801124 所有, 如有侵权,请联系我们删除。