
Hadoop3.X 完成分布式安装部署
需要三台虚拟机
所有相关安装包在Master节点的/opt/software目录下
解压到 /opt/module目录下
命令中要求使用绝对路径
一、 JDK安装
- 在master操作
1、解压jdk
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
2、修改配置文件
- 修改 etc下的profile文件:vi /etv/profile
添加配置文件(里面原本的内容不可以删除,在最后一行按 o 输入,修改完成先按 Esc 再输入 :wq ( :wq : 退出并保存)):
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
- 使文件生效:source /etc/profile ,使用 java -version命令验证

3、免密登录
- 修改/etc/hosts 文件(三台虚拟机都需要):vi /etc/hosts ,将slave1和slave2的ip添加到里面(查看IP的命令:ip addr):
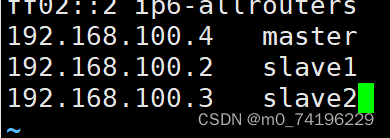
- 在master上输入:ssh-keygen -t rsa 然后连续按下三次回车然后输入命令(若遇到需要输入yes或者no 输入yes) ssh-copy-id master 按下回车后输入master所对应的虚拟机密码 ssh-copy-id slave1 按下回车后输入slave1所对应的虚拟机密码 ssh-copy-id slave2 按下回车后输入slave2所对应的虚拟机密码验证方式:输入 ssh slave1 不需要输入密码即可

二、hadoop集群环境搭建
- 将hadoop解压到/opt/module下
tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
- 修改配置文件
修改文件位于:/opt/module/hadoop-3.1.3/etc/hadoop
可以直接:cd /opt/module/hadoop-3.1.3/etc/hadoop
需要修改的配置文件有5个:
1,core-site.xml(核心配置文件)
2,hdfs-site.xml(HDFS配置文件)
3,mapred-site.xml(MapReduce配置文件)
4,yarn-site.xml(YARN配置文件)
5,hadoop-env.sh
6,yarn-env.sh
7,workers (该文件中添加的内容结尾不允许有空格,文件中不允许有空行)
1、配置文件
1,core-site.xml(核心配置文件)
vi core-site.xml
<property>
<!-- 指定NameNode的地址 -->
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<!-- 指定hadoop数据的存储目录 -->
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
2,hdfs-site.xml(HDFS配置文件)
vi hdfs-site.xml
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
3,mapred-site.xml
vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4,yarn-site.xml
vi yarn-site.xml(YARN配置文件)
<property>
<name>yarn.nodemanger.anx-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanger.vmen-check-enable</name>
<value>false</value>
</property>
5,hadoop-env.sh
vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
6,yarn-env.sh
vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
7,workers
vi workers
master
slave1
slave2
2、配置环境变量
vi /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3、给slave1和slave2分发配置文件
- 分发jdk
scp -r /opt/module/jdk1.8.0_212/ root@slave1:/opt/module/
scp -r /opt/module/jdk1.8.0_212/ root@slave2:/opt/module/
- 分发环境变量配置文件
scp -r /etc/profile root@slave1:/etc/profile
scp -r /etc/profile root@slave2:/etc/profile
- 分发hadoop
scp -r /opt/module/hadoop-3.1.3/ root@slave1:/opt/module/
scp -r /opt/module/hadoop-3.1.3/ root@slave2:/opt/module/
- 使slave1和slave2的配置文件生效
切换到slave1和slave2 输入命令 source /etc/profile
输入java -version 查看是否成功
4、启动Hadoop集群
- 初始化NameNode(在master)
hdfs namenode -format
- 启动hdfs和yarn
start-all.sh
master 节点下输入 jps 显示以下内容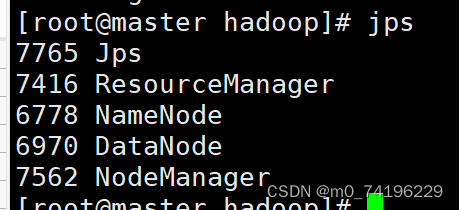
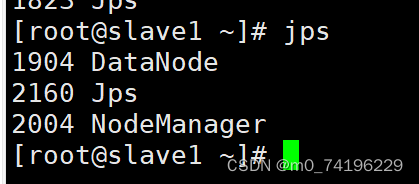
slave1节点下输入jps显示以下内容
配置完成!
本文转载自: https://blog.csdn.net/m0_74196229/article/details/135730778
版权归原作者 xiaodu最帅 所有, 如有侵权,请联系我们删除。
版权归原作者 xiaodu最帅 所有, 如有侵权,请联系我们删除。