
常用的hdfs操作
一、实验目的
- 理解HDFS在Hadoop体系结构中的角色
- 熟练使用HDFS操作常用的shell命令
- 熟悉HDFS操作常用的Java API
二、实验平台
- 操作系统:CentOS 8
- Hadoop版本:3.3.1
- jdk版本:1.8
- Java IDE:Eclipse
三、实验内容
1. 使用Hadoop命令操作分布式文件系统。
- 新建目录 在本地和hadoop中分别创建文件夹:在本地创建目录:
 Hadoop创建目录:
Hadoop创建目录: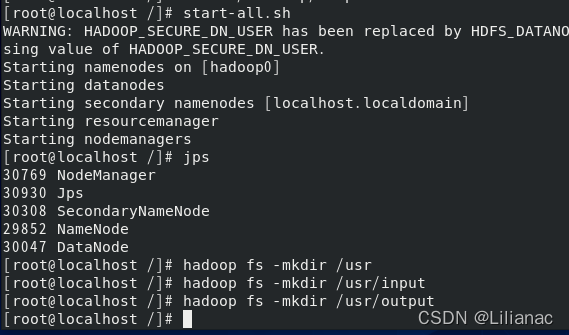
- 上传文件至dfs 切换到本地input目录下,创建文件并添加数据:
hello hadoop。
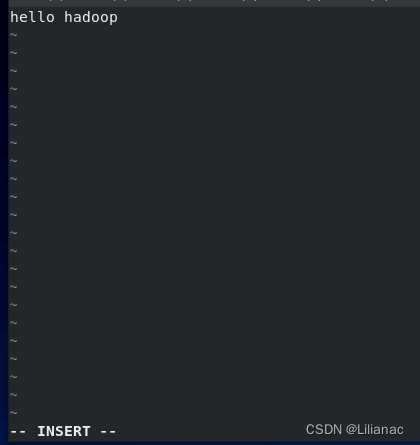 将该文件上传至hadoop:使用
将该文件上传至hadoop:使用hadoop fs -put <要上传的文件> <hdfs目录>命令。 查看上传到HDFS的文件:
查看上传到HDFS的文件:
- 移动与删除 列出HDFS中的目录和文件:
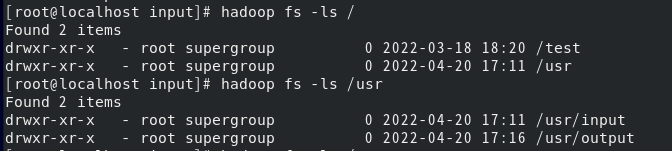
 将helloworld.txt移动到根目录:
将helloworld.txt移动到根目录: 删除helloworld.txt;
删除helloworld.txt;
下表列出了Hadoop常用的shell命令,在之后使用的时候可以作为参考。
名称选项使用格式含义-lsr-lsr <路径>递归查看指定路径的目录结构-du-du <路径>统计目录下个文件大小-dus-dus <路径>汇总统计目录下文件(夹)大小-count-count [-q] <路径>统计文件(夹)数量-mv-mv <源路径> <目的路径>移动-cp-cp <源路径> <目的路径>复制-rm-rm [-skipTrash] <路径>删除文件/空白文件夹-rmr-rmr [-skipTrash] <路径>递归删除-put-put <多个 linux 上的文件> <hdfs 路径>上传文件-copyFromLocal-copyFromLocal <多个 linux 上的文件><hdfs 路径>从本地复制-moveFromLocal-moveFromLocal <多个 linux 上的文件><hdfs 路径>从本地移动-getmerge-getmerge <源路径> <linux 路径>合并到本地-cat-cat <hdfs 路径>查看文件内容-text-text <hdfs 路径>查看文件内容-copyToLocal-copyToLocal [-ignoreCrc] [-crc] [hdfs 源路径] [linux 目的路径]从HDFS复制到本地-moveToLocal-moveToLocal [-crc] <hdfs 源路径> <linux目的路径>从HDFS移动到本地-mkdir-mkdir <hdfs 路径>创建空白文件夹-setrep-setrep [-R] [-w] <副本数> <路径>修改副本数量-touchz-touchz <文件路径>创建空白文件
2. HDFS-JAVA接口之读取文件
- 在eclipse中创建Hadoop项目 (1) 创建项目,新建lib目录
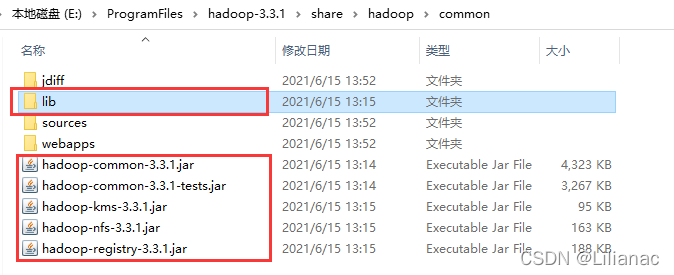
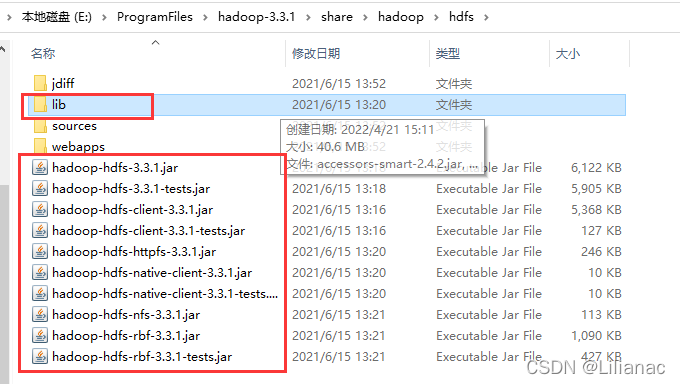
 (2)将Hadoop项目所需要的jar包copy到lib目录下。 将之前下载的hadoop压缩包解压到本地,打开share/hadoop的common目录和hdfs目录并将其中的jar包全部拷贝至项目的lib目录下。
(2)将Hadoop项目所需要的jar包copy到lib目录下。 将之前下载的hadoop压缩包解压到本地,打开share/hadoop的common目录和hdfs目录并将其中的jar包全部拷贝至项目的lib目录下。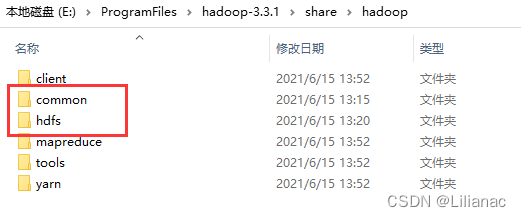
 选中所有jar包添加到项目依赖
选中所有jar包添加到项目依赖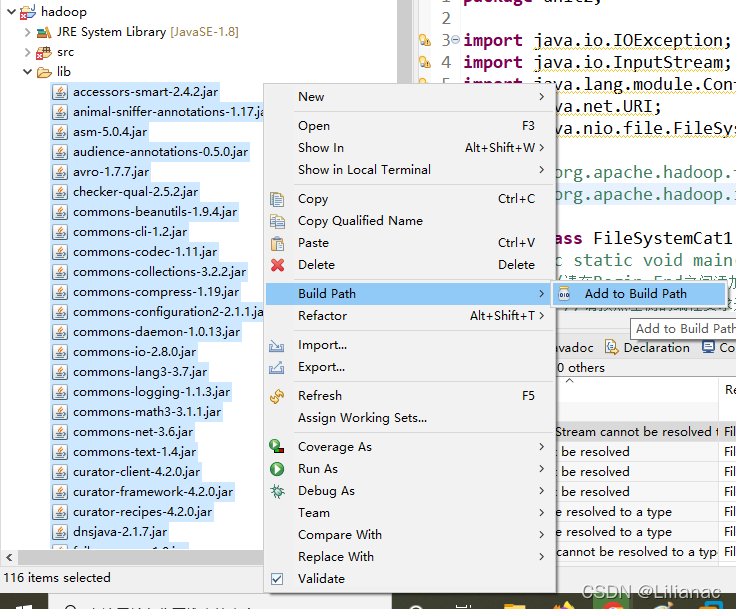 然后就可以开始进行编写hadoop项目了
然后就可以开始进行编写hadoop项目了 - FileSystem对象 要从Hadoop文件系统中读取文件,最简单的办法是使用
java.net.URL对象打开数据流,从中获取数据。不过这种方法一般要使用FsUrlStreamHandlerFactory实例调用setURLStreamHandlerFactory()方法。不过每个Java虚拟机只能调用一次这个方法,所以如果其他第三方程序声明了这个对象,那我们将无法使用了。 因为有时候我们不能在程序中设置URLStreamHandlerFactory实例,这个时候咱们就可以使用FileSystem API来打开一个输入流,进而对HDFS进行操作。 - FileSystem API示例 首先我们在本地创建一个文件,然后上传到HDFS以供测试。

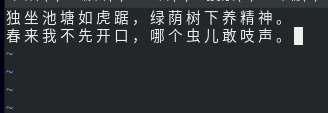
 接下来,在eclipse中编写代码,使用FileSystem,查看刚刚上传的文件。
接下来,在eclipse中编写代码,使用FileSystem,查看刚刚上传的文件。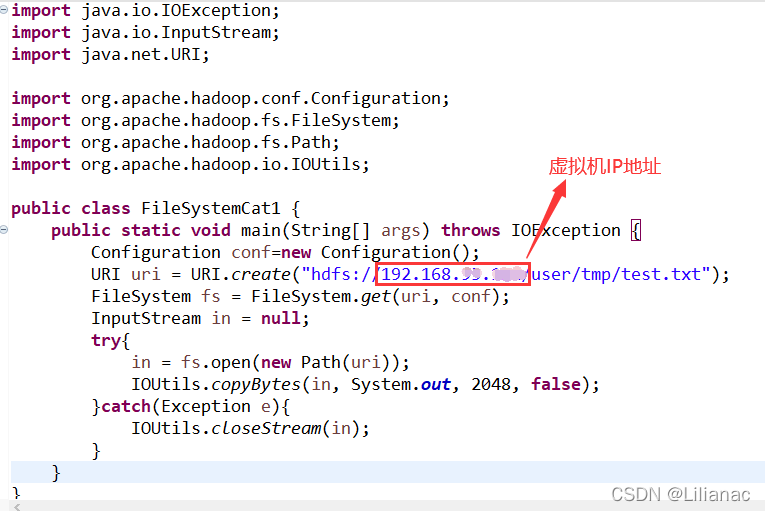 运行出现错误:
运行出现错误: 因为我们没有log4j.properties文件,我们在src目录下创建一个log4j.properties文件,写入以下内容:
因为我们没有log4j.properties文件,我们在src目录下创建一个log4j.properties文件,写入以下内容:#log4j.rootLogger=INFO, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n#--------console-----------log4j.rootLogger=info,myconsole,myfilelog4j.appender.myconsole=org.apache.log4j.ConsoleAppenderlog4j.appender.myconsole.layout=org.apache.log4j.SimpleLayout#log4j.appender.myconsole.layout.ConversionPattern =%d [%t] %-5p [%c] - %m%n#log4j.rootLogger=error,myfilelog4j.appender.myfile=org.apache.log4j.DailyRollingFileAppenderlog4j.appender.myfile.File=/tmp/flume.loglog4j.appender.myfile.layout=org.apache.log4j.PatternLayoutlog4j.appender.myfile.layout.ConversionPattern =%d [%t] %-5p [%c] - %m%n然后再次运行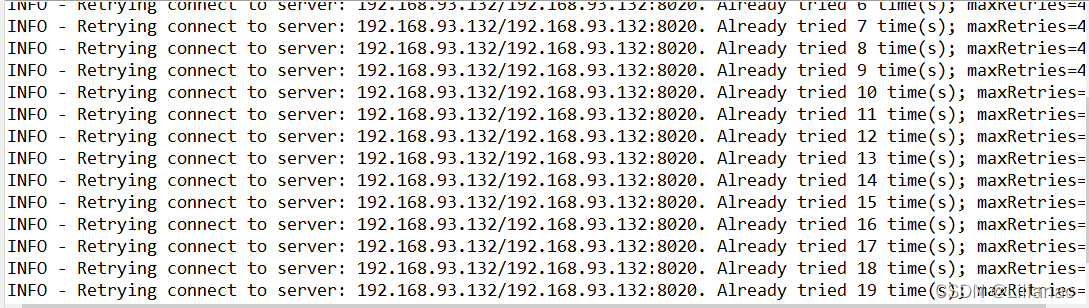 还是不行,如果我们写的直接是虚拟机的ip地址,那默认访问的应该是8020端口,我在Hadoop配置core-site.xml文件的时候设置的是8088端口,所以需要修改端口号。
还是不行,如果我们写的直接是虚拟机的ip地址,那默认访问的应该是8020端口,我在Hadoop配置core-site.xml文件的时候设置的是8088端口,所以需要修改端口号。 还是不行,
还是不行,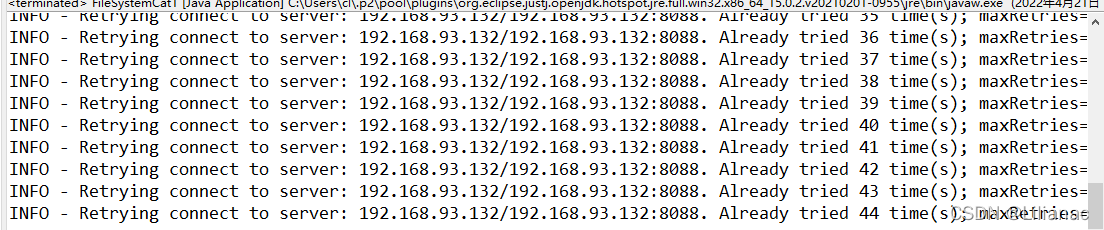 检查了一下我的hadoop启动情况,resourceManager没有启动,而ResourceManager的作用是:负责集群中所有资源的统一管理和分配,它接收来自各个NodeManager的资源汇报信息,并把这些信息按照一定的策略分配给各个ApplicationMaster。
检查了一下我的hadoop启动情况,resourceManager没有启动,而ResourceManager的作用是:负责集群中所有资源的统一管理和分配,它接收来自各个NodeManager的资源汇报信息,并把这些信息按照一定的策略分配给各个ApplicationMaster。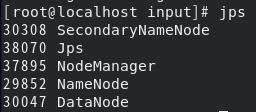 原来是我yarn-site.xml中resourcemanager的ip写错了,详细过程请看这篇文章resourcemanager启动失败 最后启动成功:
原来是我yarn-site.xml中resourcemanager的ip写错了,详细过程请看这篇文章resourcemanager启动失败 最后启动成功: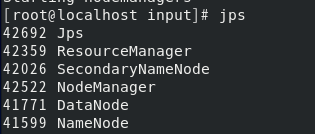 回到eclipse,重新运行代码,还是出现重连的情况,然后突然想起来是不是我的防火墙没有关,使用
回到eclipse,重新运行代码,还是出现重连的情况,然后突然想起来是不是我的防火墙没有关,使用systemctl status firewalld.service查看防火墙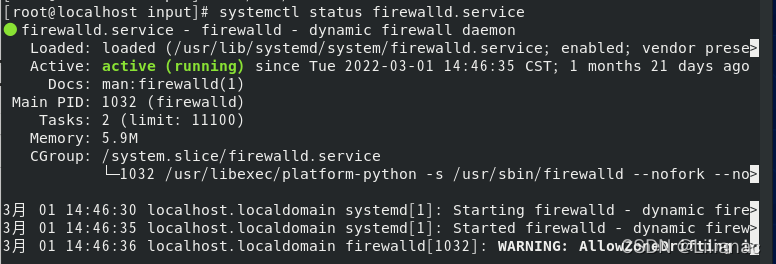 果然没有关防火墙,使用
果然没有关防火墙,使用systemctl stop firewalld.service关闭防火墙,再输入systemctl disable firewalld.service永久关闭防火墙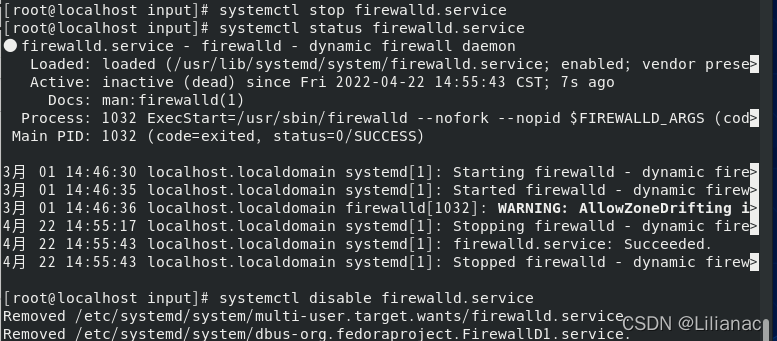 然后再回到eclipse运行代码,现在是出现乱码错误:
然后再回到eclipse运行代码,现在是出现乱码错误: 点击"Windows–>preferences"
点击"Windows–>preferences" 选择"general–>workspace–>text file encoding",选择other,然后选择utf-8
选择"general–>workspace–>text file encoding",选择other,然后选择utf-8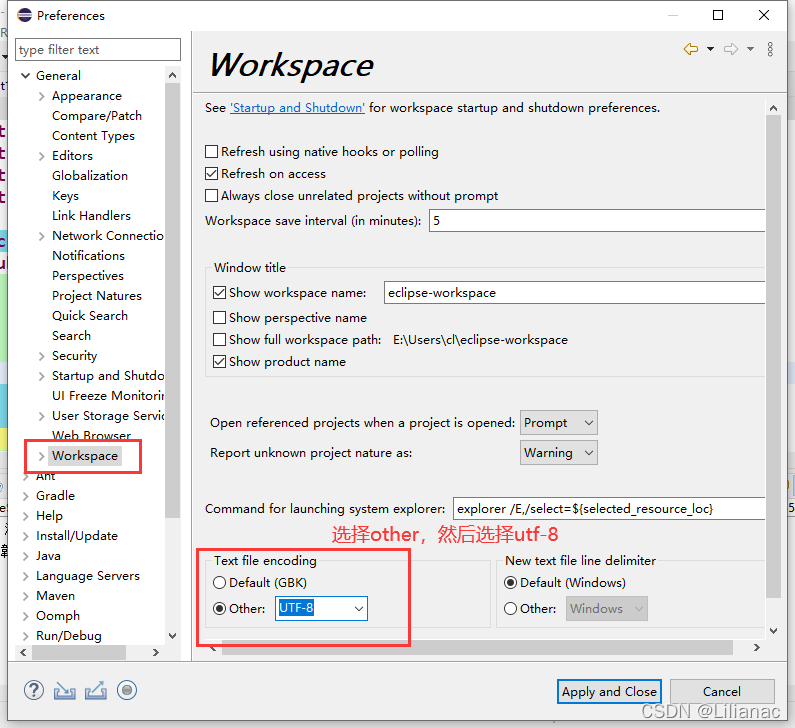 最后"apply and close",最后再重新运行,这下终于可以了:
最后"apply and close",最后再重新运行,这下终于可以了: FileSystem是一个通用的文件系统API,FileSystem实例有下列几个静态工厂方法用来构造对象。
FileSystem是一个通用的文件系统API,FileSystem实例有下列几个静态工厂方法用来构造对象。publicstaticFileSystemget(Configuration conf)throwsIOExceptionpublicstaticFileSystemget(URI uri,Configuration conf)throwsIOExceptionpublicstaticFileSystemget(URI uri,Configuration conf,String user)throwsIOExceptionConfiguration对象封装了客户端或服务器的配置,通过设置配置文件读取类路径来实现(如:/etc/hadoop/core-site.xml)。 (1) 第一个方法返回的默认文件系统是在core-site.xml中指定的,如果没有指定,就使用默认的文件系统。 (2) 第二个方法使用给定的URI方案和权限来确定要使用的文件系统,如果给定URI中没有指定方案,则返回默认文件系统, (3) 第三个方法作为给定用户来返回文件系统,这个在安全方面来说非常重要。 - FSDataInputStream对象 实际上,FileSystem对象中的open()方法返回的就是FSDataInputStream对象,而不是标准的java.io类对象。这个类是继承了java.io.DataInputStream的一个特殊类,并支持随机访问,由此可以从流的任意位置读取数据。在有了FileSystem实例之后,我们调用open()函数来获取文件的输入流。
publicFSDataInputStreamopen(Path p)throwsIOExceptionpublicabstractFSDataInputStreamopen(Path f,int bufferSize)throwsIOException使用FSDataInputStream获取HDFS的/user/tmp/目录下的task.txt的文件内容,并输出 首先我们在本地创建task.txt文件,写入"怕什么真理无穷,进一寸有一寸的欢喜。",然后上传到hdfs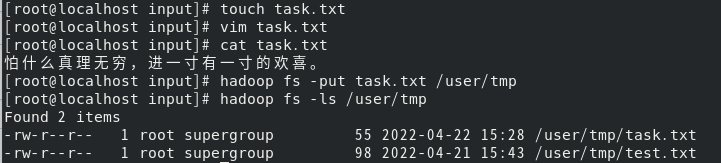 在eclipse中编写代码:
在eclipse中编写代码: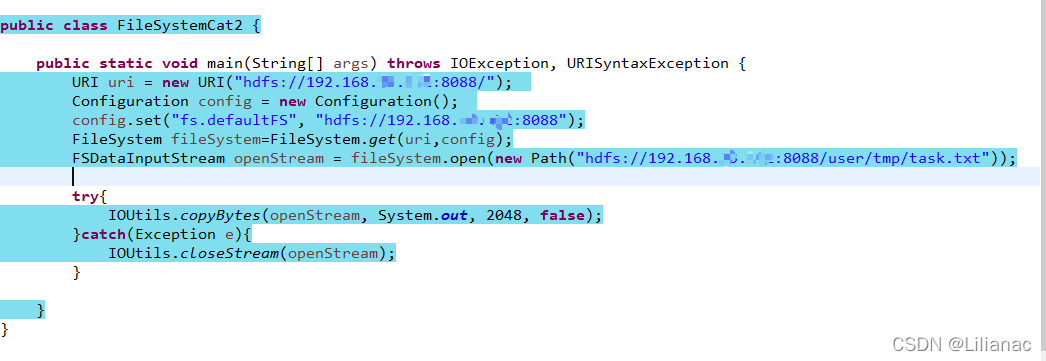 成功输出:
成功输出:
3. HDFS-JAVA接口之上传文件
FSDataOutputStream对象
FileSystem类有一系列新建文件的方法,最简单的方法是给准备新建的文件制定一个path对象,然后返回一个用于写入数据的输出流:
publicFSDataOutputStreamcreate(Path p)throwsIOException
该方法有很多重载方法,允许我们指定是否需要强制覆盖现有文件,文件备份数量,写入文件时所用缓冲区大小,文件块大小以及文件权限。
注意:create()方法能够为需要写入且当前不存在的目录创建父目录,即就算传入的路径是不存在的,该方法也会为你创建一个目录,而不会报错。如果有时候我们并不希望它这么做,可以先用exists()方法先判断目录是否存在。
我们在写入数据的时候经常想要知道当前的进度,API也提供了一个Progressable用于传递回调接口,这样我们就可以很方便的将写入datanode的进度通知给应用了。
packageorg.apache.hadoop.util;publicinterfaceProgressable{publicvoidprogress();}
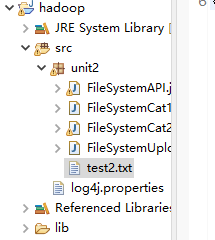
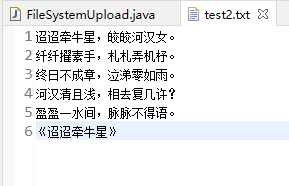
在本地目录下创建test2.txt文件,并输入如下数据,注意这里是在Windows的本地目录下创建文件:
迢迢牵牛星,皎皎河汉女。
纤纤擢素手,札札弄机杼。
终日不成章,泣涕零如雨。
河汉清且浅,相去复几许?
盈盈一水间,脉脉不得语。
《迢迢牵牛星》
使用FSDataOutputStream对象将文件上传至HDFS的/user/tmp/目录下,并打印进度。
编写代码如下:
importjava.io.BufferedInputStream;importjava.io.File;importjava.io.FileInputStream;importjava.io.IOException;importjava.io.InputStream;importjava.net.URI;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.FSDataOutputStream;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.IOUtils;importorg.apache.hadoop.util.Progressable;publicclassFileSystemUpload{publicstaticvoidmain(String[] args)throwsIOException{//路径最好写绝对路径,要不然容易报找不到文件的错误File localPath =newFile("E:\\Users\\cl\\eclipse-workspace\\hadoop\\src\\unit2\\test2.txt");//这里是hdfs的路径String hdfsPath ="hdfs://192.168.*.*:8088/user/tmp/test2.txt";//获取输入对象InputStream in =newBufferedInputStream(newFileInputStream(localPath));Configuration config=newConfiguration();FileSystem fs =null;try{//最后一个参数是指以什么身份上传文件,如果不写默认以你创建的用户的身份上传
fs =FileSystem.get(URI.create(hdfsPath), config,"root");}catch(IOException e){// TODO Auto-generated catch block
e.printStackTrace();}catch(InterruptedException e){// TODO Auto-generated catch block
e.printStackTrace();}//待上传文件大小long fileSize = localPath.length()>65536? localPath.length()/65536:1;FSDataOutputStream out = fs.create(newPath(hdfsPath),newProgressable(){//方法在每次上传了64KB字节大小的文件之后会自动调用一次long fileCount =0;publicvoidprogress(){System.out.println("总进度"+(fileCount / fileSize)*100+"%");
fileCount++;}});//最后一个参数的意思是使用完之后是否关闭流IOUtils.copyBytes(in, out,2048,true);}}
运行结果: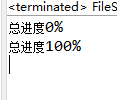
4. HDFS-JAVA接口之删除文件
- 列出文件 在HDFS的API中就提供了
listStatus()方法来实现该功能。publicFileStatus[]listStatus(Path f)throwsIOExceptionpublicFileStatus[]listStatus(Path f,PathFilter filter)throwsIOExceptionpublicFileStatuslistStatus(Path[] files)throwsIOExceptionpublicFileStatus()listStatus(Path[] files,PathFilter filter)throwsIOException当传入参数是一个文件时,他会简单的转变成以数组方式返回长度为1的FileStatus对象,当传入参数是一个目录时,则返回0或多个FileStatus对象,表示此目录中包含的文件和目录。现在我们使用listStatus()方法来列出hdfs根目录下的文件夹与user目录下的文件夹。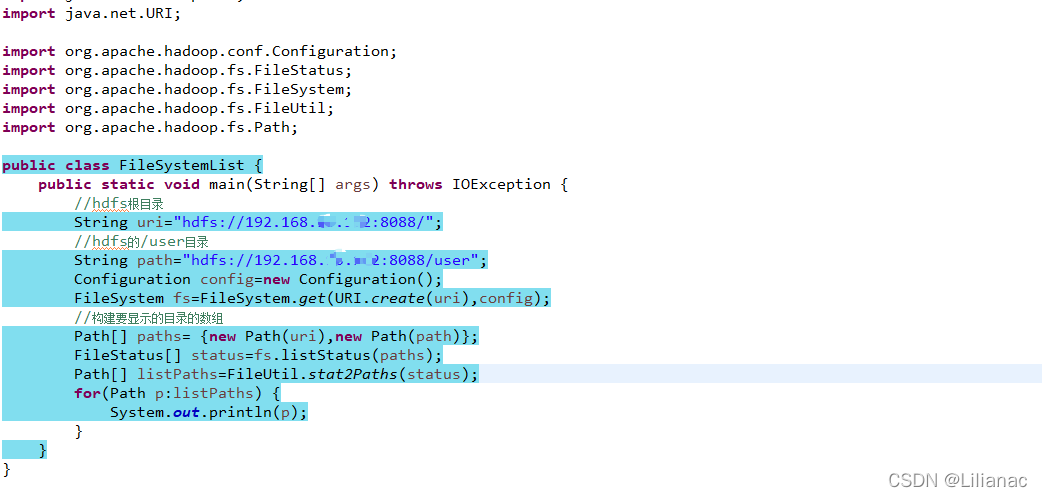 运行结果:
运行结果:
- 删除文件 使用FileSystem的delete()方法可以永久性删除文件或目录。
publicbooleandelete(Path f,boolean recursive)throwsIOException如果f是一个文件或者空目录,那么recursive的值可以忽略,当recursize的值为true,并且p是一个非空目录时,非空目录及其内容才会被删除(否则将会抛出IOException异常)。 我们来创建两个目录,一个是空目录,一个是非空目录
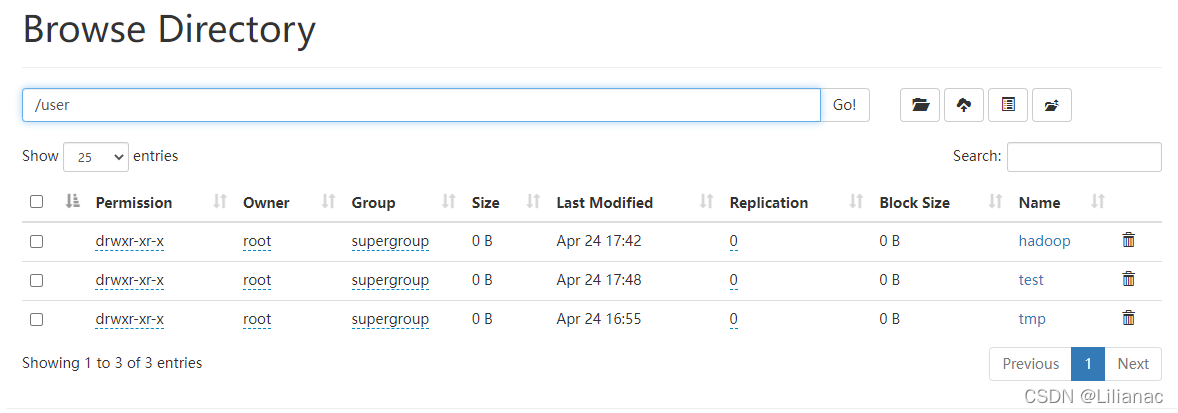 然后编写代码将这两个目录删除
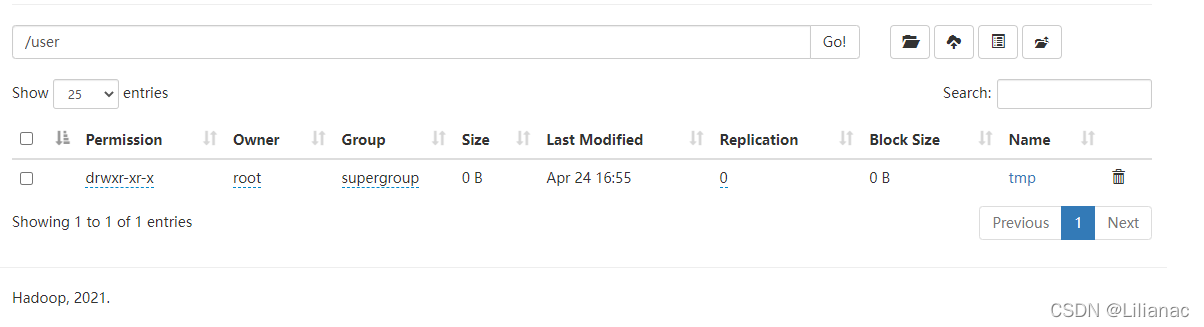
然后编写代码将这两个目录删除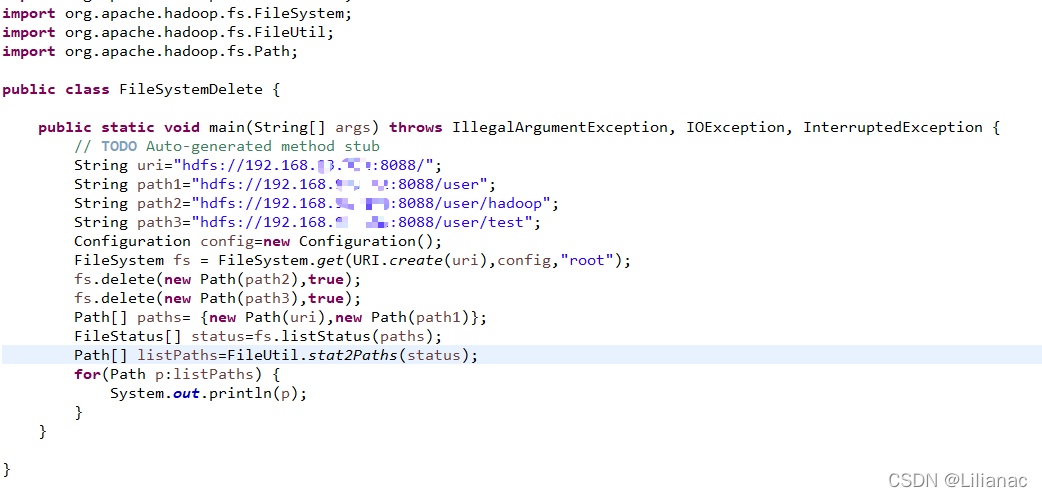 运行结果:
运行结果:
版权归原作者 Lilianac 所有, 如有侵权,请联系我们删除。