
文章目录
关键词:selenium库,epub规范,ebooklib库,re正则表达式,浅浅的爬虫/前端知识
开始
处理过程
大致的处理过程为:
- 抓取web的目录页,获取每个章节的网址,存为txt文件。遍历上述txt文件,抓取web网页并提取正文内容部分存储为web文件夹下txt文件,避免每次调试程序都重新抓取一遍web网页,而且selenium蛮慢的。
- 遍历web文件夹,对这些原始数据进行整理和修改,将修改过后的文件存为modify文件夹下txt文件,这些文件就是即将被制作成epub的章节文件。
- 用ebooklib库,根据modify文件夹下的文件,制作epub
import os
import re
from ebooklib import epub
from selenium import webdriver
1. 抓取文章内容
1. 前置知识点
用selenium (Chrome)访问baidu.com并获取到右上角设置所在框里的文字
from selenium import webdriver
driver=webdriver.Chrome()# 访问网站
driver.get("https://www.baidu.com/")# css选择器定位,获取其内文字
word=driver.find_element_by_css_selector('#s-usersetting-top').get_attribute('innerText')print(word)
如何得出来用于定位的#s-usersetting-top:在网页按f12调出控制台后,点击控制台最左上角方框箭头,点击你想定位的元素,右键控制台内被高亮的标签——Copy Selector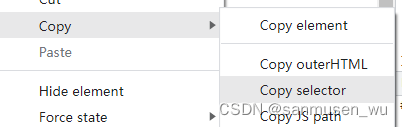
getHTML会获取该标签内html内容,和你在控制台看到的一样
getText只会获取标签内的文字
1.1. web目录→本地txt目录
selenium的安装请各位看其他帖子,大多有比较详细的安装说明,这里不再赘述,需要注意下载的驱动与你的浏览器版本能够对应上。
这里以我抓取的网站为例,可以看到目录网页的html里的script标签包含了每个章节的url信息(aid),其作用是对浏览器的window对象注入了一个闭包,调用它会返回一个json。所以我们直接使用selenium运行控制台指令,来访问这个挂到window上的闭包就能获取到目录的信息。(除了从selenium获取外,你也可以通过Request请求html文档,然后用Execjs库运行闭包里的函数,或者直接用NodeJS爬)
除了上面这种需要js运行时环境的方式之外,大多数平台对目录数据的存储方式是在html文件的body内的一个列表,遇到这种情况则可以使用
driver.find_elements_by_css_selector
方法找到ul内li元素组成的列表,然后for循环遍历列表内元素来得到每章的信息。
1.1 关键代码(目录信息在window内的情况)
driver.execute_script
能够在selenium的控制台运行js代码,js内return的东西会被这个方法返回,这里获取的是一个章节的json list。然后将每个章节的id拼接上网址保存在txt里
这里我把每个网址后面加上##和网址对应的章节数,方便下一步将下载的文件命名
zfill(3)可以在字符串左边补充若干的0来使得字符串长度等于3
driver.get("url")
article_list=driver.execute_script("return window.__NUXT__.data[0].series.articles")
article_website_list=[]for art in article_list:
article_website_list.append(r'https://www.lightnovel.us/cn/detail/'+str(art['aid'])+"##"+str(picknum_from_webtitle(art['title'])).zfill(3))# 把爬取的章节id拼接网址后保存为txtwithopen('{}/bookurls.txt'.format(storage_folders['root']),'w',encoding="utf8")as f:
f.write("\n".join(article_website_list))
1.2. web章节网页→本地章节txt
在这部分,访问bookurls.txt里记录的每个章节的网址。分割出网址和其对应的章节名字符串(同时以章节名字符串作为爬下来的txt的名称)。
定位到文章正文所在的html标签,保存其中的html格式的内容(由于Epub格式与html相同,这种方法能以网页观感保留信息)。
withopen('{}/bookurls.txt'.format(storage_folders['root']),'r',encoding="utf8")as f:
urls=f.readlines()for url in urls:# 分割url与章节字符串
weburl,num=url.strip().split("##")print("爬取 {}".format(num))# 如果文件已经在web文件夹里,则不再进行爬取if os.path.exists('{}/{}.txt'.format(storage_folders['web'],num.zfill(3))):print("网页 {} 已经存在".format(num))continue
driver.get(weburl)
art=driver.find_element_by_id("article-main-contents").get_attribute('innerHTML')withopen('{}/{}.txt'.format(storage_folders['web'],num.zfill(3)),'w',encoding="utf8")as f:
f.write(art)
2. 对数据进行处理
2. 前置知识点
re正则匹配
用re正则匹配章节名,提取章节数字那部分和章节名
import re
wordlist=['<p>第六章 七七四十九</p>','说时迟那时快','现在来到了第18章','第一名姓章','<p>第14章 四四十六</p>']for word in wordlist:if re.search(r'<p>第.*?章 .*?</p>',word):print(re.sub(r'<p>第(.*?)章 (.*?)</p>',r'\1-\2',word))# 输出:# 六-七七四十九# 14-四四十六
其中,re.search能够判断word里是否存在这个正则pattern,然后re.sub能够将正则pattern内的括号之外内容去除,保留括号内的内容。
?表示尽可能早的结束匹配,正则匹配默认会匹配到尽可能长的字符串。对于
'<p>第69章 签字 盖章 成交</p>'
这种包含章的标题内容,如果pattern内不加
?
,则结果会是
69章 签字 盖-成交
,加了
?
后:
69-签字 盖章 成交
建议自己检查下正则出来的内容,只要自己想制作的epub没有出现问题,任何不严谨的正则式子都是可以接受的。
2.1. 控制换行
第一步是替换网页换行符——br标签,我爬的网页中br标签是单标签但是缺少末尾的/,这在epub中是无法解析的,而且文章中出现太多的多行空白,因此需要处理换行。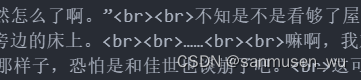
这里我直接按br标签把正文内容分割成列表,然后控制列表里连续的空白元素的数量不超过2,最后处理结束合并每行时给每行套
<p></p>
标签
#每个br作为分割点
contentlist=content.split("<br>")for con in contentlist:# 空行检测if blankflag andnot con:# 上行和这行空continueelifnot con:# 这行空
blankflag=Trueelse:# 这行非空
blankflag=False# 处理结束合并时给每行套<p></p>标签
con="<p>"+con.strip()+"</p>"# 后续处理...
2.2. 去除奇奇怪怪的标签
如果内容充满了奇奇怪怪的各种标签,如这一话,每行都被左对齐和大字体的span标签包裹。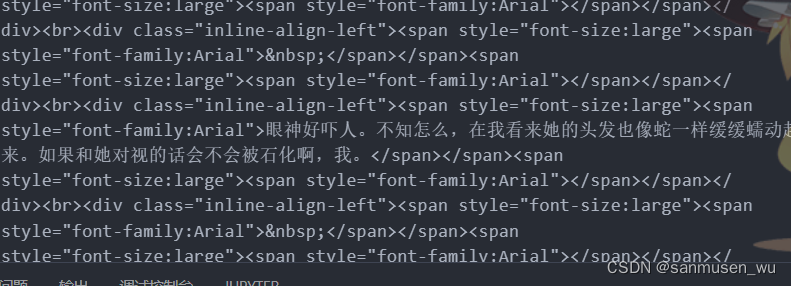
使用re.sub提取每行的中心文字,删除奇奇怪怪的那些标签
defeditif50(sencontent):# 如果是50话,这话版面抽风多出来很多标签,正则去除
choufeng=re.compile(r' style="font-size:large"| style="font-family:Arial"')
res=re.sub(choufeng,r'',sencontent)
spanspan=re.compile(r'<span><span>(.*?)</span></span>')
res=re.sub(spanspan,r'\1',res)
sbdiv=re.compile(r'<div class="inline-align-left">(.*?)</div>')
res=re.sub(sbdiv,r'\1',res)return res
2.3. 拆分一个文件内的多个章节
如果作者把几个章节写在同一个网页内(比如作品介绍和第一话一起更新,或者作者某次更新时在一个网页内连写了好几话内容),就会导致这几个章节之间无法像那些一个章节一个网页的情况各自成为txt文件。
处理过程为
- chap_infolist存储章节数字,章节名。chap_contentlist存储章节内容
- re.findall找到所有章节名(第X话 XXX),解析章节名,存入infolist
- 使用re.split切割章节名,如果开头有作品介绍,则n个章节应该切出来n+1个段,存入chap_contentlist,其中第一个元素pop出来作为intro,单独存储为一个章节。
- 最后,把原本的modify文件夹里的这一章文件删除,重新写入分割后的章节
defsplit_chapter(filepath):# 如果是网页上的第一话(实际是1-43话)分割一个网页中的不同章节withopen(filepath,"r",encoding="utf8")as f:
fcontent=f.read()# 所有章节名行内容
chaplines=chapter_pattern.findall(fcontent)
chap_infolist=[]for chapline in chaplines:
resnum=num_pattern.findall(chapline)[0]
chap_number=get_chap_num(resnum[0])
chap_name=resnum[1]
chap_infolist.append({'chap_number':chap_number,'chap_name':chap_name})
chap_contentlist=chapter_pattern.split(fcontent)# 在章节关键字出现前的文字作为intro保存为000.txtif(chap_contentlist):
pre_word=chap_contentlist.pop(0)withopen(os.path.join(storage_folders["modify"],"{}.txt".format("0".zfill(3))),'w',encoding="utf8")as f:
f.write('<h2>前言</h2>\n'+pre_word+"\n"+myword)if(len(chap_contentlist)!=len(chap_infolist)):print("章节分割出错,检测到{}个章节名,{}段".format(len(chap_infolist),len(chap_contentlist)))print([("匹配情况",chap_infolist[i],chap_contentlist[i])for i inrange(min(len(chap_infolist),len(chap_contentlist)))])raise IndexError("Length are Not Equal")# 删除原本文件,把每个章节单独保存到modify文件夹
os.remove(filepath)for i inrange(len(chap_contentlist)):withopen(os.path.join(storage_folders["modify"],"{}.txt".format(str(chap_infolist[i]['chap_number']).zfill(3))),'w',encoding="utf8")as f:# 此处为最终读者能在每话开头看到的标题文字
f.write('<b>第{}话 {}</b>\n'.format(chap_infolist[i]['chap_number'],chap_infolist[i]['chap_name'])+chap_contentlist[i])print("分割章节 {}".format(chap_infolist[i]['chap_number']))
3. 制作epub
最关键的一步(但是不怎么难 ),这是ebooklib的文档
经过前面的处理,我们已经在modify文件夹内有了每个章节的txt文件,其内是html形式的文本内容,接下来使用ebooklib库将其合成为epub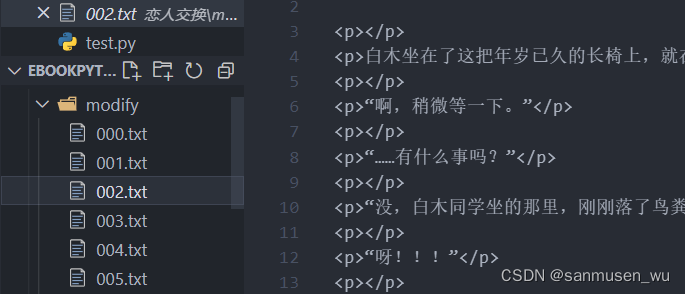
pip install ebooklib
安装库
3.1. 新建book,填入元信息
新建book对象,元信息就是书名,作者,这本书的唯一标识符(自己定义)等书本信息
这里还定义了一个chaplist列表,里面将会按顺序存储章节
book=epub.EpubBook()# 书籍元信息# chaplist为排序过的所有的章节文件EpubHtml,在最后会被统一for循环add进book和书脊和目录里,所以下文只用考虑chaplist
chaplist=[]
book.set_identifier("自己定义一串数字")
book.set_title("书名")
book.set_language("cn")
book.add_author("作者名")
book.add_metadata("DC","description","作品描述")
3.2. 添加css
css可以定义特殊的样式,由于我做的是个普通的epub所以没有用到css
style ='body { font-family: Times, Times New Roman, serif; }'
nav_css = epub.EpubItem(uid="style_nav",
file_name="style/nav.css",
media_type="text/css",
content=style)
book.add_item(nav_css)
3.3. 添加章节
遍历modify文件夹,将文件名排序后,按照顺序将其添加进chaplist列表,其中的每个元素是EpubHTML对象,也就是Epub格式的每个章节文件
# 添加章节for root, dirs, files in os.walk(storage_folders['modify']):
files.sort()# 分析所有章节是否连续,这边直接转int比较长度了iflen(files)>0:if files[0]=="000.txt":# 有introiflen(files)-1!=int(files[-1].split(".")[0]):print("章节出现缺失,请检查!")else:iflen(files)!=int(files[-1].split(".")[0]):print("章节出现缺失,请检查!")else:raise Exception("无章节txt")# 按文件添加 001.txtforfilein files:
fpath=os.path.join(root,file)withopen(fpath,'r',encoding="utf8")as f:
fcontent=f.read()
chaplist.append(epub.EpubHtml(
title="第{}话".format(file.split('.')[0]),
file_name='{}.xhtml'.format(file.split('.')[0]),
lang='cn',
content=fcontent
))break
3.4. 添加目录和书脊
前面说的chaplist里存储了每个章节对象,但这时它们只是一个python列表,还没有存储到book对象里,通过add_item就能把每个章节对象放入book这个压缩包里,在这之后每个章节才是可访问的
toc目录,可以理解为阅读软件里点击目录按钮之后会蹦出来的那个列表,这在epub里面是一个文件,定义了目录的顺序以及点击每个标题跳转到哪个文件。
spine书脊,可以理解为真实世界里的书本的装订顺序,如果不用目录跳转,单纯从第一页翻到最后一页,我们需要书脊来知道这一章的最后一页翻完之后是哪一章的第一页。
add_item,目录和书脊的不同:
add_item往book这个压缩包里放入了某个文件使其可被访问,目录toc提供了一种快速阅览书本章节和跳转的页面,书脊spine定义了一页一页翻阅epub的呈现顺序。
—如果某个HTML或CSS没有被add_item进book,则无论如何在epub文件里都看不到它们
—如果book.toc中删除其他只保留第一章,读者仍然可以一页一页翻到最后一章。
—如果book.spine删除其他只保留第一章,则读者只可阅览第一章内容,目录中的所有章节只有第一章可以正常跳转
#把所有chapters导入book里,并添加目录和书脊for chap in chaplist:
book.add_item(chap)
book.toc=chaplist
book.spine=chaplist
# 添加默认的 NCX and Nav file
book.add_item(epub.EpubNcx())
book.add_item(epub.EpubNav())
3.5. 导出
# 保存epub
epub.write_epub("./final.epub",book)print("书本 {} 已导出".format(bookname))
Bibi-快速阅览你的epub,不到1MB的本地静态文件,解压zip后打开index.html即可
碎碎念
正文结束,下面是一些碎碎念
为啥会做这个:最近在水群的时候刷到了一个漫画截图,谁不爱看薄纱牛头人呢 。
于是就迅速找到漫画然后找到小说翻译帖,看到小说翻译帖的epub楼层年久失修(某度云链接挂掉 )而且已经是三年前的东西了。看到翻译君趁着漫画出来继续三年前的翻译,于是想着拿python做一个不用怎么手动操作的程序,这样等翻译完了直接跑一遍程序就行 (如果不多出来什么新的奇奇怪怪的标签的话 )。
为啥用selenium而不是request库:selenium比较直观,并且正如1.1节里说的,爬目录需要js运行时环境,所以个人感觉使用selenium比request+解析script要方便的多。当然1.2节的工作使用request是比较快速的,不过考虑到爬取的内容被另存为txt,也不需要多次爬取,我就继续用selenium了,后续可以考虑这部分做成request然后多线程。
踩过的坑:
坑1
selenium使用execute_script在控制台运行脚本,需要在脚本里return,才能在python里获得返回值,
article_list=driver.execute_script("return window.__NUXT__.data[0].series.articles")
。否则返回值是Undefined
坑2
ebooklib创建的HTML对象,一定要记得挂到到book对象里,
book.add_item()
,然后书脊spine和目录toc才能找到正确的HTML对象,否则会报错
TypeError: Argument must be bytes or unicode, got 'NoneType'
坑3
re.sub中把某句子替换成r’\1’,则如果未匹配到pattern的话,sub的返回值会是原本的句子。所以在那之前要先search一下,如果存在,再sub。
禁止转载原文,如有需要可以链接本文地址
版权归原作者 sanmusen_wu 所有, 如有侵权,请联系我们删除。