
参数意义
spark on yarn 的常用提交命令如下:
${SPARK_HOME}/bin/spark-submit --class org.apache.spark.examples.SparkPi \--masteryarn\
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 1g \
--executor-cores 4\
--num-executors 3\--queue default \${SPARK_HOME}/examples/jars/spark-examples*.jar \10
- num-executors 指要使用的 executor 的数量。
- executor-memory 指每个 executor 分配的内存大小。
- executor-cores 指每个 executor 的分配的 cpu core 数量。
- driver-memory 指 driver 分配的内存大小。
提交的应用程序在 AM 中运行起来就是一个 driver,它构建 sparkContext 对象、DAGScheduler 对象、TaskScheduler 对象、将 RDD 操作解析成有向无环图、依据宽窄依赖划分 stage、构建 task、封装 taskSet 等等,这些操作都需要占用内存空间,driver-memory 就是为其分配内存。
rdd 最终被解析成一个个 task 在 executor 中执行,每一个 cpu core 执行一个 task。集群上有
num-executors
个 executor,每个 executor 中有
executor-cores
个 cpu core,则**同一时刻最大能并行处理
num-executors * executor-cores
个 task,也就是说这两个参数调整 task 的最大并行处理能力,实际的并行度还跟数据分区数量有关**。
executor 的内存结构如下图所示,由 yarn overhead memory 和 JVM Heap memory 两部分构成,其中 JVM Heap memory 又可分为 RDD cache memory、shuffle memory、work heap 三部分,
executor-memory
表示 JVM Heap 的大小。spark 比 mapreduce 速度快的原因之一是它将计算的中间结果保存在内存中,而不是写回磁盘。所以当内存越大时,RDD 就可以缓存更很多的数据、shuffle 操作可以更多地使用内存,将尽量少的数据写入磁盘,从而减少磁盘IO;在task执行时,更大的内存空间意味着更少频率地垃圾回收,从这个点上又能提升性能。当然内存空间也不是越大越好,要大了集群分配不出来,yarn 直接将任务 kill 了,不过一定程度上提高资源的申请的确可以提高任务执行的效率。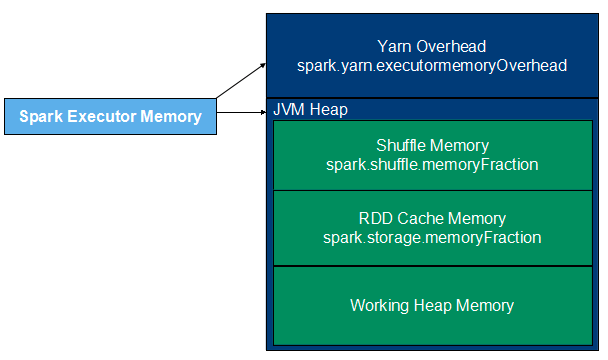
如何充分利用申请到的资源
充分地利用资源,才能让任务的执行效率更。这个其实也简单,一句话:task 任务的数量和 executor cores 的数量相匹配。假设 executor-cores=4、num-executors=3 则能实现 12 task 并行执行。但如果执行某个 stage 时 task 少于 12 个,这就导致了申请到的资源浪费了,而且执行效率相对低。
# 总数据量 12G 时:
分区 每个分区数据量 使用的 cores 效率
101.2G 10 低
12 10G 12 高
官方文档有这段描述
Clusters will not be fully utilized unless you set the level of parallelism for each operation high enough.
Spark automatically sets the number of “map” tasks to run on each file according to its size (though you can
control it through optional parameters to SparkContext.textFile, etc), and for distributed “reduce” operations,
such as groupByKey and reduceByKey, it uses the largest parent RDD’s number of partitions. You can pass the
level of parallelism as a second argument (see the spark.PairRDDFunctions documentation), or set the config
property spark.default.parallelism to change the default. In general, we recommend 2-3 tasks per CPU core in
your cluster.
细节自己看了,在 reduce 操作时,例如 reduceByKey 和 groupByKey,可以通过参数修改分区数,也可以在配置文件中使用 spark.default.parallelism 修改分区数。通常,建议每个 CPU core 分配 2-3 个 task,即 task 数量是全部 cores 的 2-3 倍。
版权归原作者 骑着蜗牛向前跑 所有, 如有侵权,请联系我们删除。