
Spark

1. Spark基础概念
1.1 Spark是什么
Spark 基于内存式计算的分布式的统一化的数据分析引擎。
1.2 Spark 模块
Spark 框架模块包含:Spark Core、Spark SQL、Spark Streaming、Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上。
1.3 Spark 四大特点
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合一样轻松的操作分布式数据集。Spark具有运行速度快、易用性好、通用性强和随处运行等特点。
运行速度快:Spark支持内存计算
Spark处理数据与MapReduce处理数据相比,有如下3个不同点:
MapReduceSpark计算流程结构Map和Reduce的结果都必须进入磁盘支持DAG,一个程序中可以有多个Map、Reduce过程,多个Map之间的操作可以直接在内存中完成中间结果存储磁盘不经过Shuffle的中间处理结果数据直接存储在内存中Task运行方式进程(Process):MapTask、ReduceTask线程(Thread):所有Task都以线程方式存在,不需要频繁启动、申请资源
1.4 Spark 运行模式
Spark 框架编写的应用程序可以运行在本地模式(Local Mode)、集群模式(Cluster Mode)和云服务(Cloud),方便开发测试和生产部署。
集群模式:
- Hadoop YARN集群模式(生产环境使用):运行在 yarn 集群之上,由yarn负责资源管理,Spark负责任务调度和计算,好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
- Spark Standalone集群模式(开发测试及生成环境使用):类似Hadoop YARN架构,典型 的Mater/Slaves模式,使用Zookeeper搭建高可用,避免Master是有单点故障的。
- Apache Mesos集群模式(国内使用较少):运行在mesos资源管理器框架之上,由mesos 负责资源管理,Spark 负责任务调度和计算。
1.5 spark 三大核心
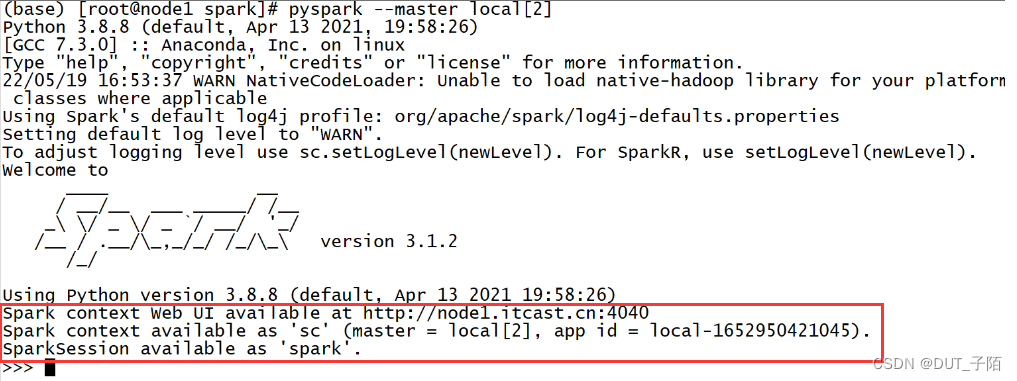
1.5.1 web 监控界面
Spark context Web UI available at http://node1.itcast.cn:4040
Spark为每个程序都提供了一个Web监控界面,端口从4040开始,如果被占用就不断+1,方便我们对每个程序的运行状况做监控。
1.5.2 SparkContext
Spark context available as ‘sc’ (master = local[2], app id = local-1652950421045)
SparkContext是Spark程序中的一个类,任何一个Spark的程序都必须包含一个SparkContext类的对象
功能:1. 负责启动、监听整个程序组件2. 负责管理当前程序的所有配置信息3. 负责读取外部数据,将数据构建为RDD4. 负责解析同步提交job等
1.5.2 SparkSession
SparkSession available as ‘spark’
SparkSession也是Spark程序中的一个类,功能类似于SparkContext,Spark2.0以后推出的,主要用于SparkSQL
1.6 spark-submit
# 脚本:spark-submit
spark-submit \
--master spark://node1.itcast.cn:7077 \
--name test_app \
--deploy-mode client \
--driver-memory 512M \
--driver-cores 1 \
--supervise \
--executor-memory 1G \
--executor-cores 1 \
--total-executor-cores 2 \
执行的程序的路径 \
参数1 \
参数2 \
…
- –master: 用于指定程序的运行的模式:Local、Standalone、YARN、Mesos、K8s参数注释local[N]:使用本地模式,给N核CPUspark://主机名:7077:使用Standalone模式,提交给Masteryarn:使用YARN集群模式,提交给ResourceManager
- –name: 指定程序的名字,等同于代码中setAppName
- –deploy-mode: 部署模式,决定Driver程序运行在哪里。- client模式:学习测试时使用(Driver运行在提交代码的机器上)- cluster模式:生产环境中使用该模式(Driver运行在集群中的一台机器的节点上)
- –deploy-mode: 决定了Driver进程运行的位置,两种模式:client【默认】、cluster
- –jars: 指定额外的第三方依赖包,例如读写MySQL,需要MySQL的驱动包
- –conf: 指定一些其他配置–conf key=value, 等同于代码中set方法
- –driver-memory: 用于指定Driver进程运行时能够使用的内存大小
- –driver-cores: 用于指定Driver进程运行时能够使用CPU的核数
- –supervise: 用于保证Driver进程安全,故障以后会自动重启
- –executor-memory: 用于指定每个Executor能使用的内存数
- –executor-cores: 用于指定每个Executor能使用的CPU核心数
- –total-executor-cores: 用于指定 Standalone 情况下,所有Executor使用的总CPU核数
- —num-executors: 用于指定 YARN 情况下,指定启动的Executor的个数
- –queue: 用于指定将程序提交到哪个队列中运行
2. Spark核心概念
2.1 集群架构层面概念(ClusterManager、Worker)
- Cluster Manager:分布式资源管理的主节点- YARN:ResourceManager- Standalone:Master- 主要负责整个集群的资源的调度和分配,并进行集群的监控等职责,接收所有程序的提交,分配Task任务给从节点
- Worker:分布式资源管理的从节点- YARN:NodeManager- Standalone:Worker- 管理单个机器的资源,分配相应的资源来运行计算进程Executor
2.2 程序结构层面概念(Application、Driver、Executor)
- Application:Spark的应用程序- 由用户基于Spark API开发好的Spark程序- 任何一个Spark程序都包含一个Driver进程以及至少1个Executor进程
- Driver:Spark程序的驱动进程- 每个Spark程序都包含一个Driver进程- Driver启动以后会执行代码去构建SparkContext以及调用SparkContext来实现Driver功能- 功能:申请资源启动Executor计算进程、负责解析、调度分配、监控Task
- Executor:Spark程序的执行进程- 每个Spark程序都包含至少一个Executor进程- 由Driver向ClusterManager申请在Worker节点上启动Executor,并且给所有Executor分配Task任务- 功能:每个Executor启动以后会向Driver注册,接受Driver的Task分配,并负责运行Task- 注意:每个程序拥有自己的Executor,不同程序的Executor不能共享
2.3 程序运行层面概念(Job、Stage、Task)
- Job:Spark程序用于返回结果的最小单元,触发执行Task的最小单元- job的构建由行动算子来决定,Driver会解析代码,每遇到一个行动算子,就会构建一个job- 一个Spark的Application中可以包含多个job,每个job可以由多个Task运行来完成job
- Stage- Driver会调用DAGScheduler组件为每个job根据回溯算法【理解根据RDD依赖关系倒推】来构建DAG图- 构建DAG图的过程中将job整体的实现过程会划分Stage,根据Shuffle划分(也就是宽窄依赖划分),Stage个数为:Shuffle数+1- 物理上真正执行的时候,按照编号从小到大依次执行每个Stage,每个Stage内部都直接在内存中由统一的Task完成- 为什么需要有多个Stage:Shuffle过程的中间结果是写入磁盘,由不同的Task来完成
- Task:Spark中运行计算任务的最小单元,正常情况下:每个Task处理1个分区的数据,占用1核CPU- Driver解析代码,触发job,构建DAG图,划分Stage,每一个Stage对对应一个TaskSet集合- Stage:逻辑计划,每个Stage都在内存中完成一部分转换任务,由Task来实现- TaskSet:物理计划,Task集合,会根据Stage中最后一个RDD的分区个数来决定包含多个Task
3. Spark 集群模式
3.1 Standalone架构
3.1.1 Standalone架构概述
Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。Standalone集群是Spark自己研发的,类似Hadoop YARN的,一个管理集群资源和调度资源的架构。
主节点Master(管理节点): 一个JVM Process进程,主要负责整个集群的资源的调度和分配,并进行集群的监控等职责,接收所有程序的提交,分配Task任务给从节点。
从节点Workers(计算节点): 一个JVM Process进程,管理单个机器的资源,分配相应的资源来运行Executors 进程 ;资源信息包含内存Memory和CPU Cores核数。一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
3.1.2 Standalone 与 Yarn 的共性
MR on YARNSpark on StandaloneResourceManagerMasterNodeManagerWorkerAppMasterDriver计算进程:MapTask、ReduceTaskExecutortask 线程
3.1.3 单点故障(SPOF)问题
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群 一样,存在着Master单点故障(SPOF)问题。可以通过Zookeeper的master高可用解决!
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。
3.1.4 Standalone中的两种部署模式
- client 模式

- cluster 模式

3.2 Spark on YARN架构
3.2.1 Spark on YARN架构概述
主节点ResourceManage 代替了 Master ,从节点NodeManage 代替了 Workers
3.2.2 Spark on YARN中的两种部署模式
- Client 模式
 详细流程:- AppMaster与Driver共存: AppMaster运行在NodeManager上:负责申请资源,启动Executors、反馈结果;Driver运行在客户端机器上,运行在客户端进程内部:负责解析、调度和监控Task
详细流程:- AppMaster与Driver共存: AppMaster运行在NodeManager上:负责申请资源,启动Executors、反馈结果;Driver运行在客户端机器上,运行在客户端进程内部:负责解析、调度和监控Task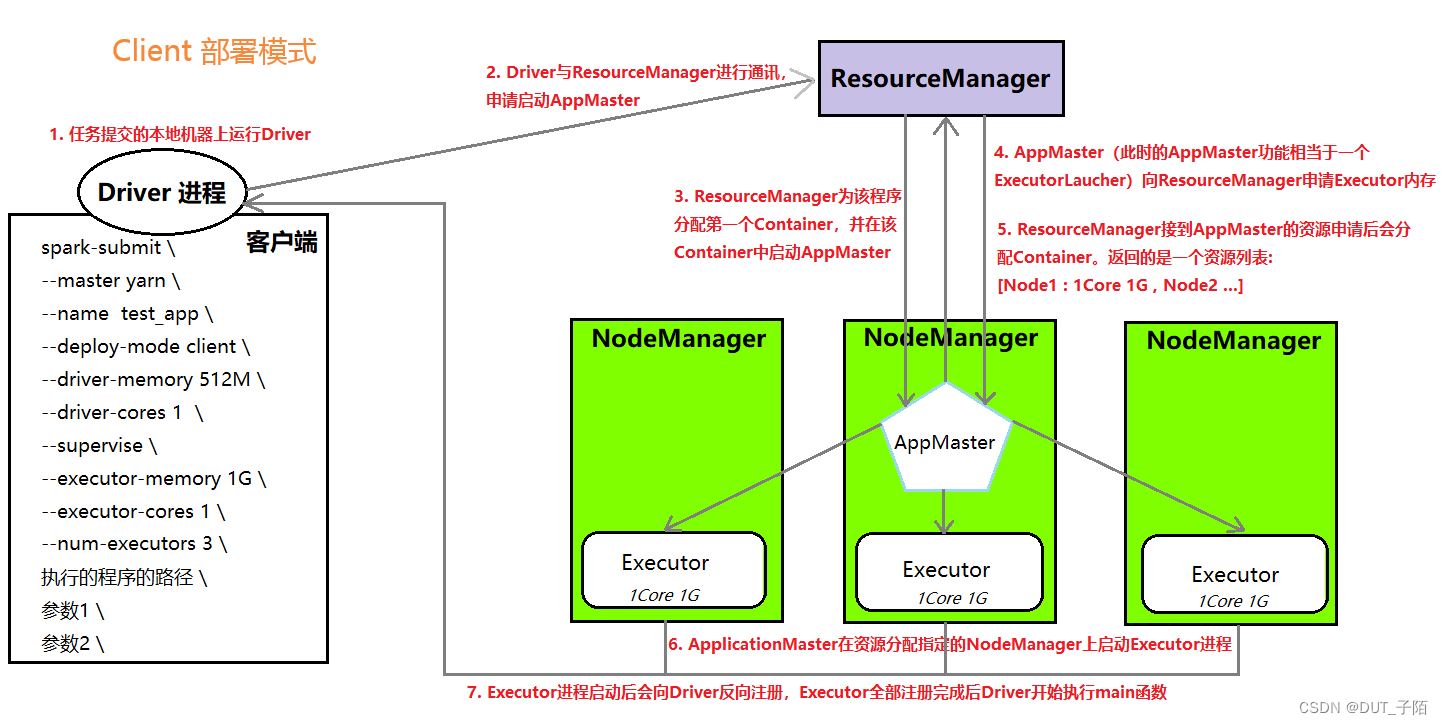
- cluster 模式
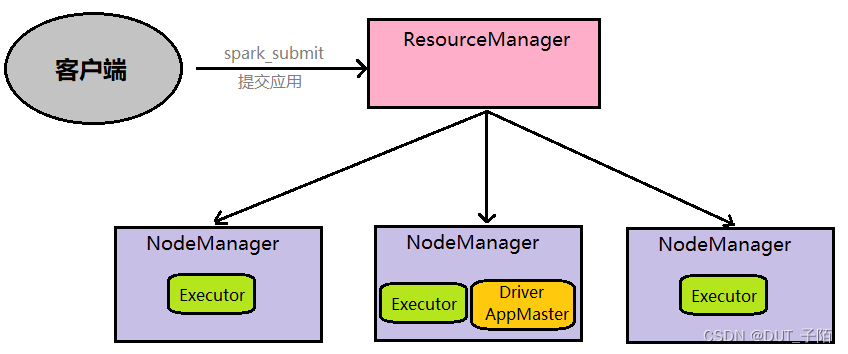 详细流程:****AppMaster与Driver合并: Driver以子进程的方式运行在AppMaster进程内部,整体负责实现资源申请、Task的解析、调度和监控
详细流程:****AppMaster与Driver合并: Driver以子进程的方式运行在AppMaster进程内部,整体负责实现资源申请、Task的解析、调度和监控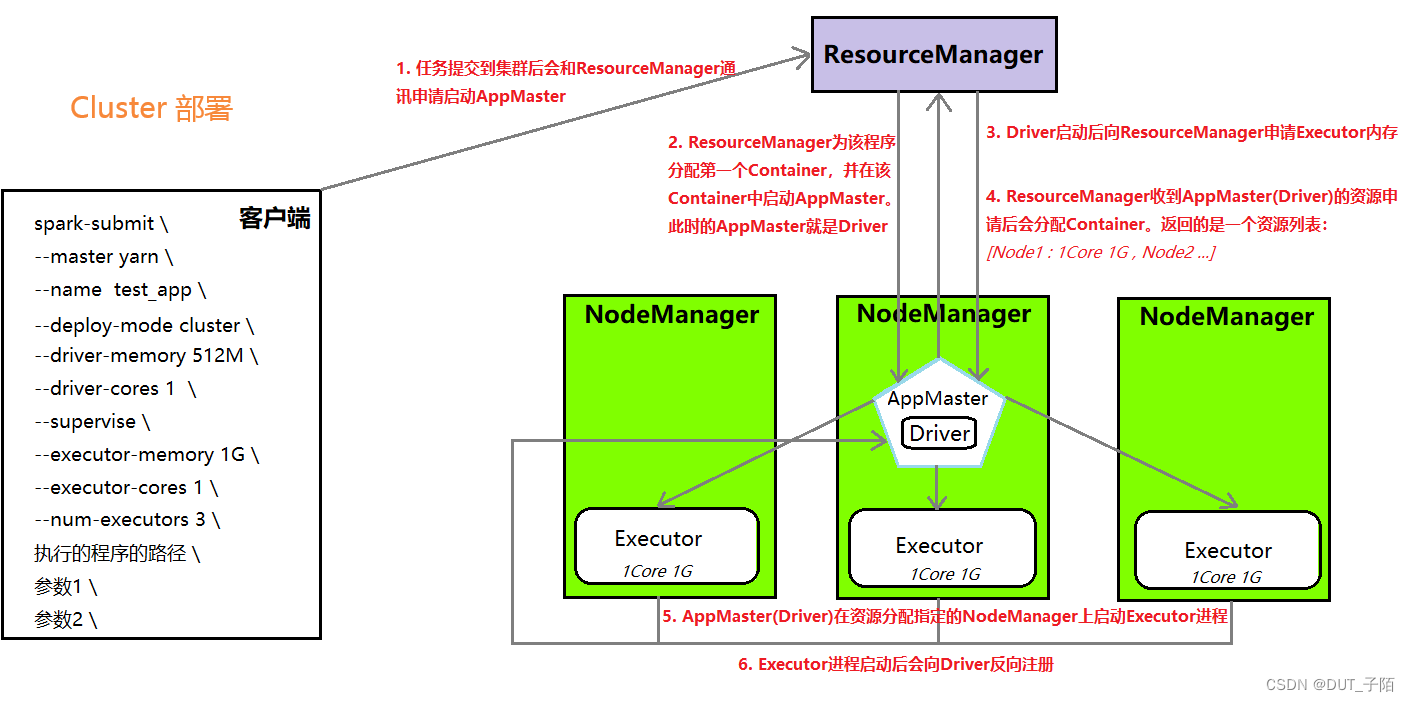
4. Spark中的宽窄依赖
4.1 依赖关系
RDD会不断进行转换处理,得到新的RDD,每个RDD之间就产生了依赖关系。
例如:A调用转换算子产生了B,那么我们称A为父RDD,称B为子RDD
4.2宽窄依赖
- 窄依赖 (Narrow Dependencies):父RDD的一个分区的数据只给了子RDD的一个分区【不用调用分区器】
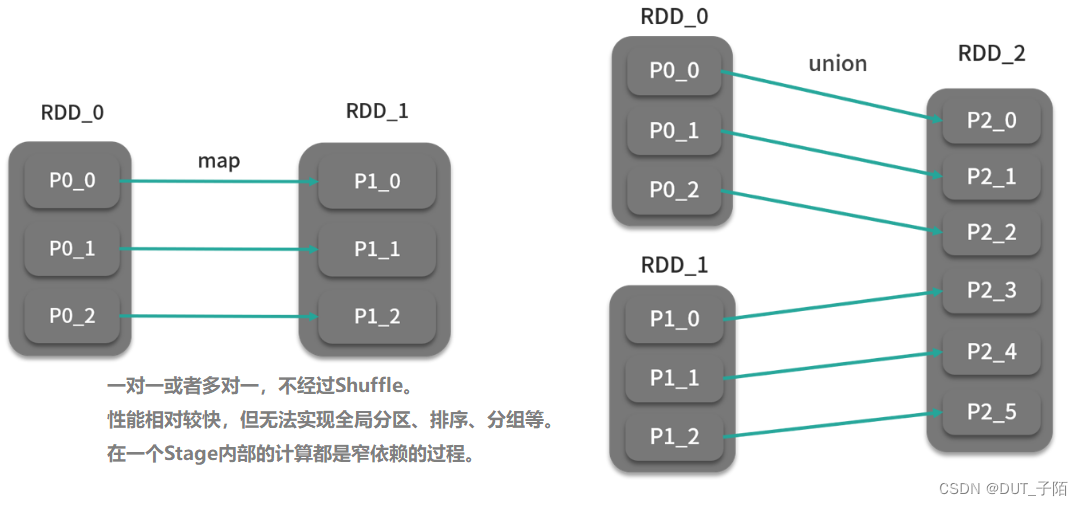
- 宽依赖 (Wide/Shuffle Dependencies):父RDD的一个分区的数据给了子RDD的多个分区【需要调用Shuffle的分区器来实现】
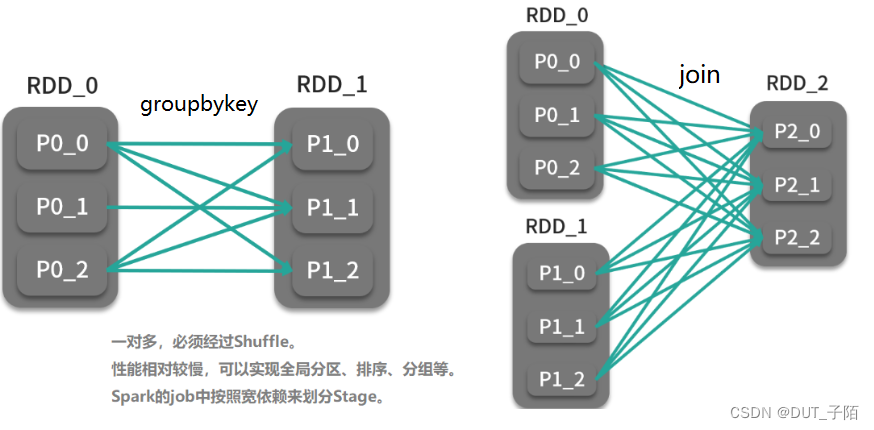
4.3 设计对RDD的宽窄依赖标记的好处
- 提高数据容错的性能,避免分区数据丢失时,需要重新构建整个RDD - 场景:如果子RDD的某个分区的数据丢失- 不标记:不清楚父RDD与子RDD数据之间的关系,必须重新构建整个父RDD所有数据- 标记了:父RDD一个分区只对应子RDD的一个分区,按照对应关系恢复父RDD的对应分区即可
- 提高数据转换的性能,将连续窄依赖操作使用同一个Task都放在内存中直接转换 - 场景:如果RDD需要多个map、flatMap、filter、reduceByKey、sortByKey等算子的转换操作- 不标记:每个转换不知道会不会经过Shuffle,都使用不同的Task来完成,每个Task的结果要保存到磁盘- 标记了:多个连续窄依赖算子放在一个Stage中,共用一套Task在内存中完成所有转换,性能更快
5. Spark应用执行流程
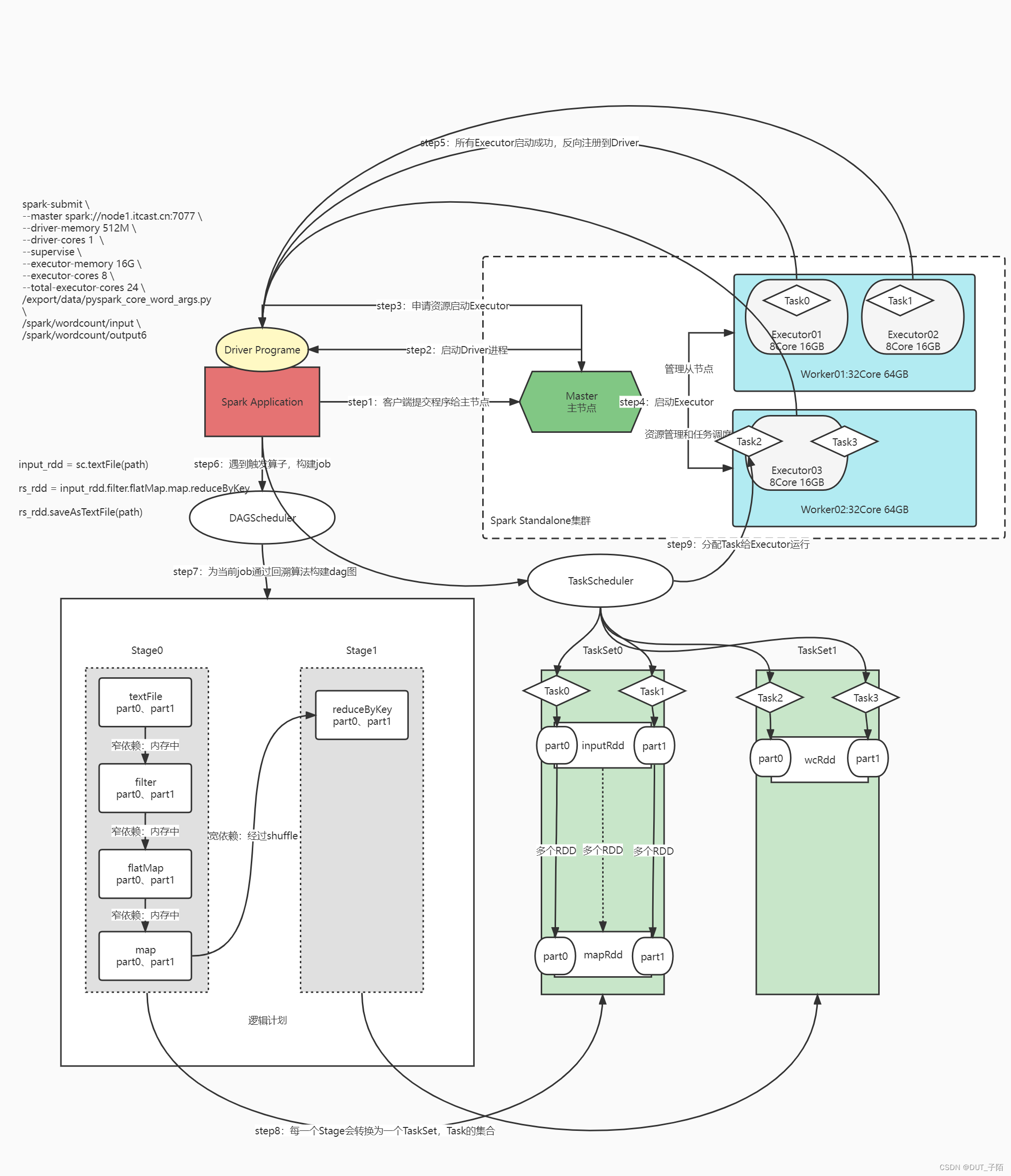
- 先启动分布式资源管理的集群:Spark Standalone / YARN
- 客户端提交用户开发好的Spark Application程序给ClusterManager
- ClusterManager根据配置参数运行程序,启动Driver进程
- Driver进程向主节点提交申请启动Executor进程
- 主节点根据资源配置和请求,在从节点上启动Executor进程
- 所有Executor启动成功以后,会向Driver反向注册,等待分配Task
- Driver解析代码,直到遇到触发算子,开始触发job的运行
- Driver会调用DAGScheduler组件为当前这个job通过回溯算法构建DAG图,并划分Stage
- Driver会将这个job中每个Stage转换为TaskSet:TaskSet就是Task的集合
- Driver调用TaskManager将Task调度分配到Executor中运行
6. Spark的Shuffle设计
Shuffle的本质是基于磁盘来解决分布式的全局分组、全局排序、重新分区 (调大) 的问题。
Spark2.0版本后,所有Shuffle方式全部统一到Sort Shuffle实现。
6.1 Shuffle 类型
Shuffle分为Shuffle Write 和 Shuffle Read:
- Shuffle Write:类似于Map端Shuffle过程,将当前Stage的结果进行分区、排序后写入HDFS。种类分为三种,Spark会根据条件自动判断走哪一种Shuffle Write - SortShuffleWriter:类似于MR的过程,排序,生成一个整体基于分区和分区内部有序的文件和一个索引文件- BypassMergeSortShuffleWriter:先为每个分区生成一个文件,最后合并为一个大文件,分区内部不排序- UnsafeShuffleWriter:钨丝计划方案,使用压缩指针存储元数据,溢写合并使用fastMerge提升效率
- Shuffle Read:类似于Reduce端Shuffle过程,读取上一个Stage的结果,进行排序、分组等操作。Shuffle Read具体的功能由算子来决定,不同的算子在经过shuffle时功能不一样 - repartition:只重新分区,不排序、不分组- sortByKey:重新分区,分区内部排序,不分组- groupByKey:重新分区,分组,不会排序
6.2 SortShuffleWriter
Stage输出的结果先写入内存缓冲区,内存中排序以后,生成小文件,小文件合并成整体有序的大文件以及索引文件。类似于MR中 溢写小文件–小文件合并成大文件。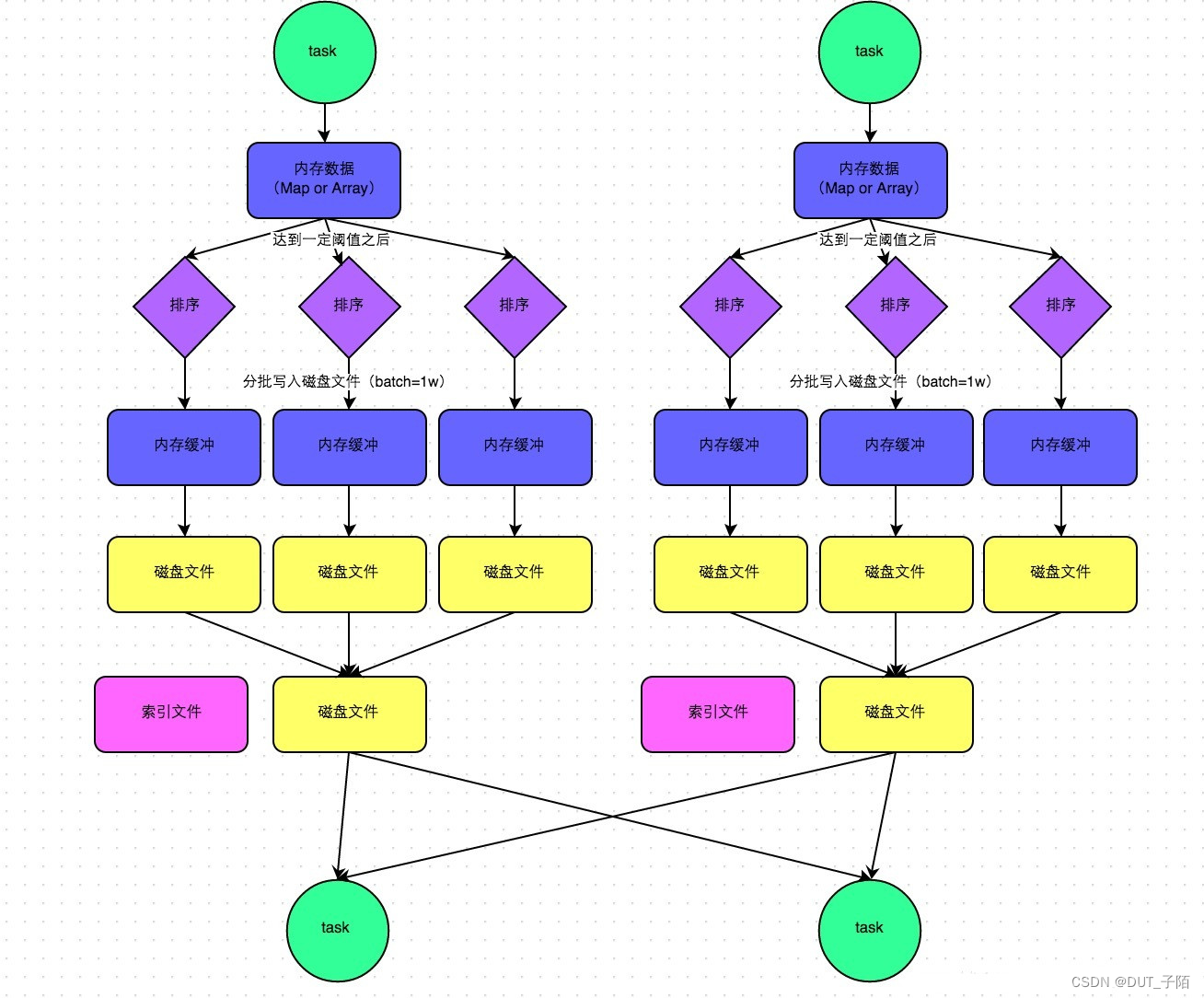
版权归原作者 DUT_子陌 所有, 如有侵权,请联系我们删除。