
1.实训目标
(1)掌握以Exlipse创建MapReduce工程
2.实训环境
(1)使用CentOS的Linux操作系统搭建的3个节点
(2)使用Eclipse软件作为编程软件
(3)使用插件hadoop-eclipse-plugin-2.x.x.jar
3.实训内容
(1)配置MapReduce环境
(2)新建MapReduce工程
4.实训步骤
4.1配置MapReduce环境
(1)添加Hadoop插件

找到eclipse的安装路径,然后将插件移动到这个路径下

(2)增加Map/Reduce功能区
打开eclipse进行以下操作


(3)增加Hadoop集群的连接
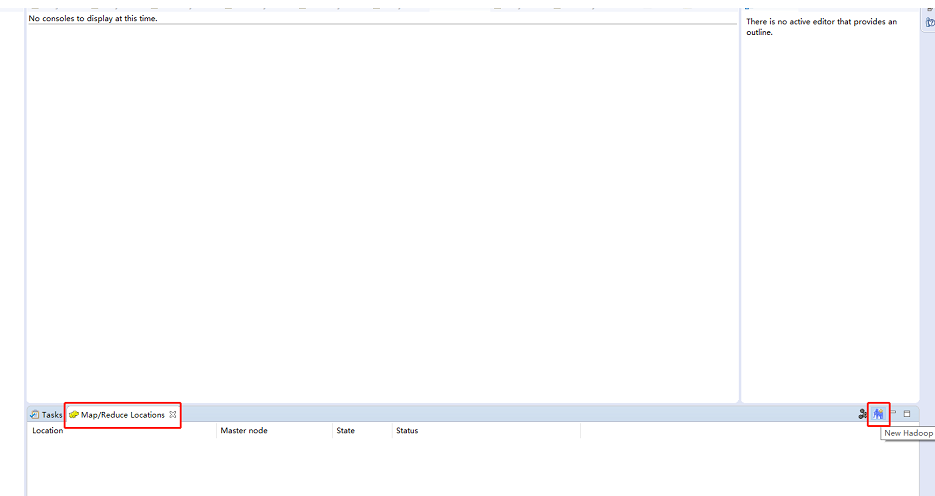
单击下图所示界面右下方的蓝色小象图标(其右上方右+号),就会弹出连接Hadoop集群的配置窗口。
在VMware的Hadoop集群里输入以下代码,查看hdfs端口号(先启动集群)
hdfs getconf -confKey fs.default.name

配置namenode节点的ip(自己的虚拟机IP)地址及端口。

相关的Hadoop集群的连接信息有以下各项。
Location name:命名新建的Hadoop连接名称,如Hadoop Cluster。
Map/Reduce Master:填写Hadoop集群的ResourceManager的IP和端口。
DFS Master:填写Hadoop集群的NameNode的IP地址和连接端口。
填写完以上信息后,单击“Finish”按钮。
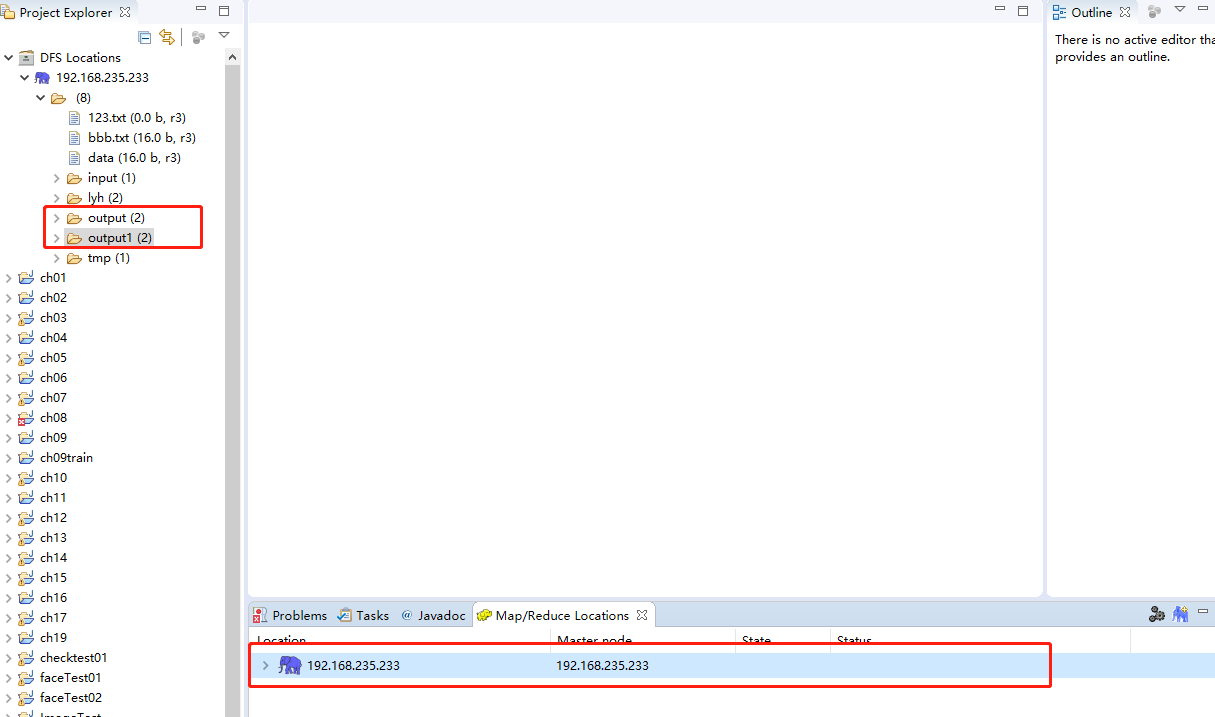
(4)浏览HDFS上的目录及文件
在配置完Hadoop集群连接后,确认Hadoop集群已经启动,就可以在Eclipse界面浏览HDFS上的目录及文件,如下图所示。还可以通过鼠标来执行文件操作,例如文件的上传和删除等。需要注意的事,每次执行操作后,需要刷新HDFS列表,从而获得文件目录的最新状态。
4.2新建MapReduce工程
(1)导入MapReduce运行依赖的相关JAR包
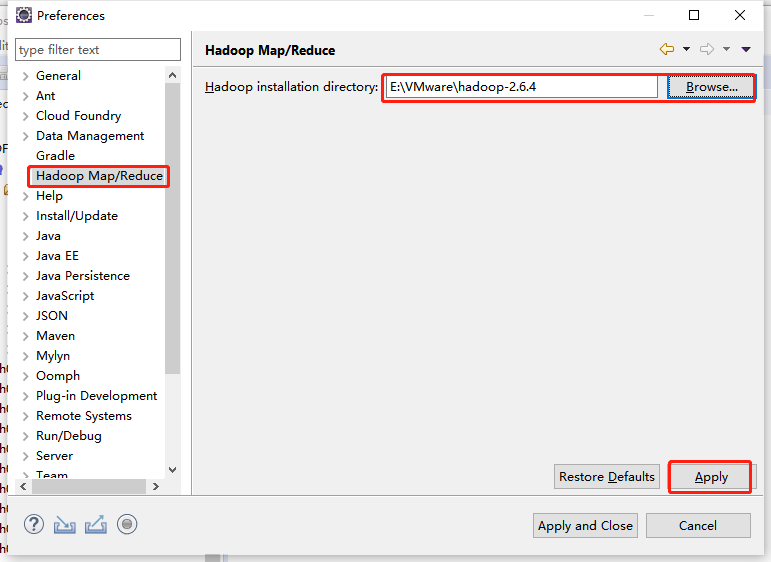
在主菜单上单击“Window”并选择“Preferences”,例如下图所示Preference界面中,选择“Hadoop Map/Reduce”,单击“Browse...”按钮,再选中Hadoop的安装文件夹路径(相应版本的Hadoop安装包需要预先解压再本地电脑上)。最后单击“Apply”按钮并单击确定。
(2)创建MapReduce工程
从菜单栏开始,单击“File”菜单,选择“New”命令,在出现的选项中单击“Project”项,再选择“Map/Reduce Project”选项。
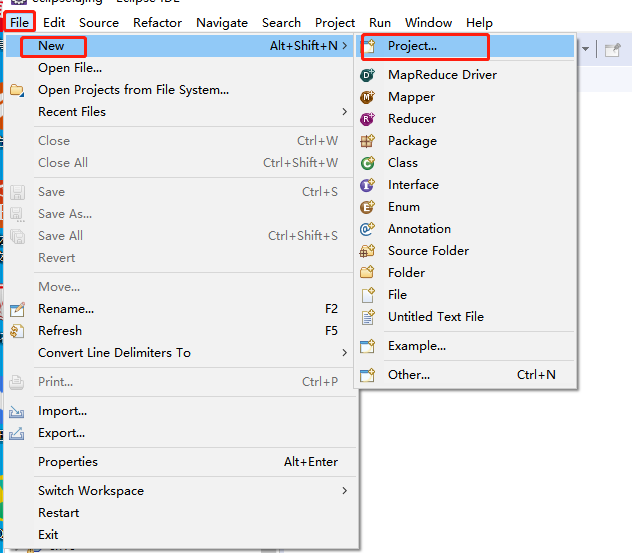
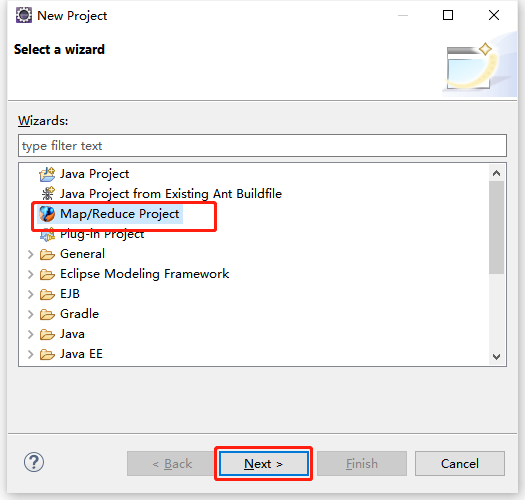
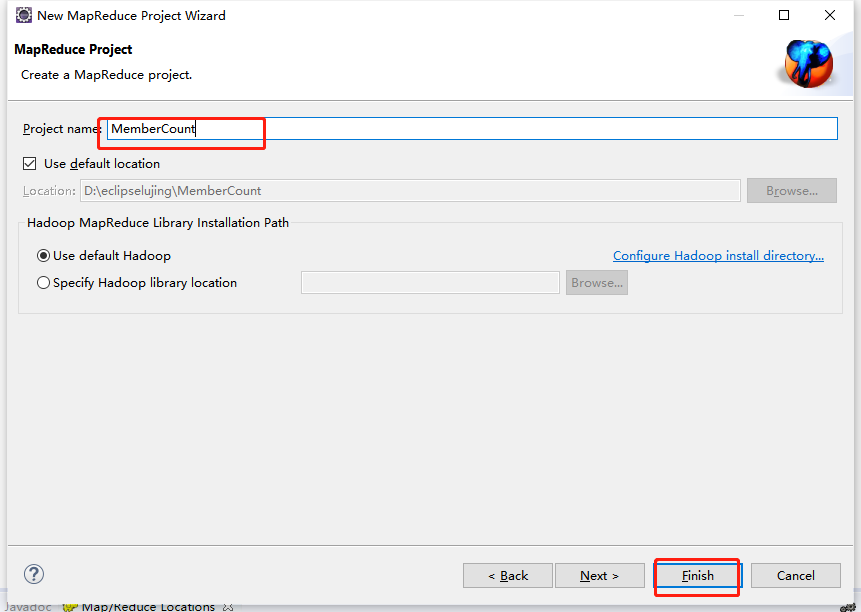
在"MapReduce Project"的创建界面中,填写工程名“MemberCount”,然后单击“Finish”按钮。
在主界面左侧的“Project Explorer”栏,可以看到已经创建好的工程MemberCount,Map Reduce编程所需要的JAR包已经全部自动导入。新工程已创建完成,接下来就可以正式进行MapReduce编程工作了。
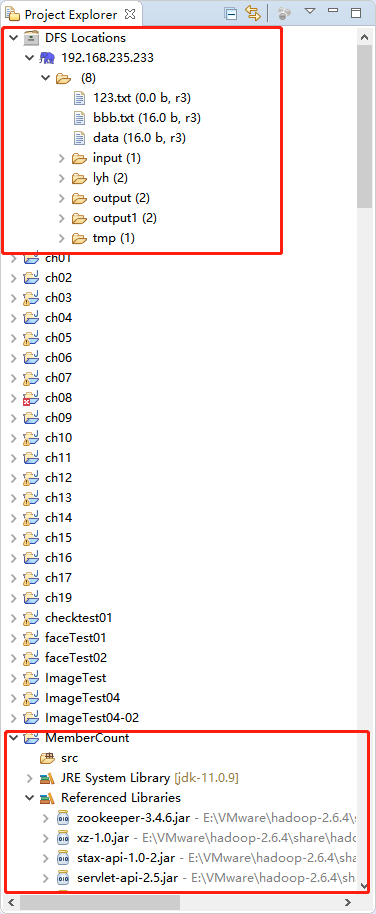
创建完成MapReduce工程
(3)在Hadoop上完成词频统计实例
1.VMware里面启动集群,在根目录下面创建一个文本,里面填写一些文本

2.在集群里面创建一个input文件夹
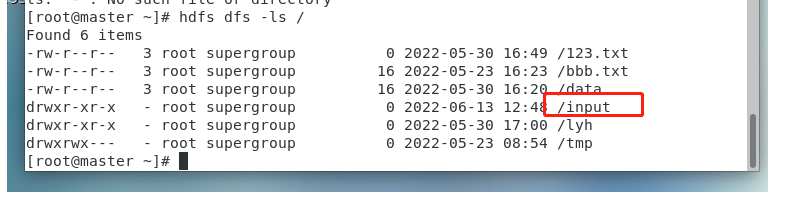
3.然后把本地的a.txt文本上传到集群上的input文件夹里面
hdfs dfs -put /a.txt /input/a.txt
4.输入命令进行词频统计
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar wordcount /input /output

5.然后就会在集群里面产生一个output文件,里面有两个文本

6.执行命令查看词频统计结果
hdfs dfs -cat /output/part-r-00000
注意:误删了output里面的文本的话的不能恢复的,可以删掉原来的output文件,重新创建一个,重新进行词频统计即可。
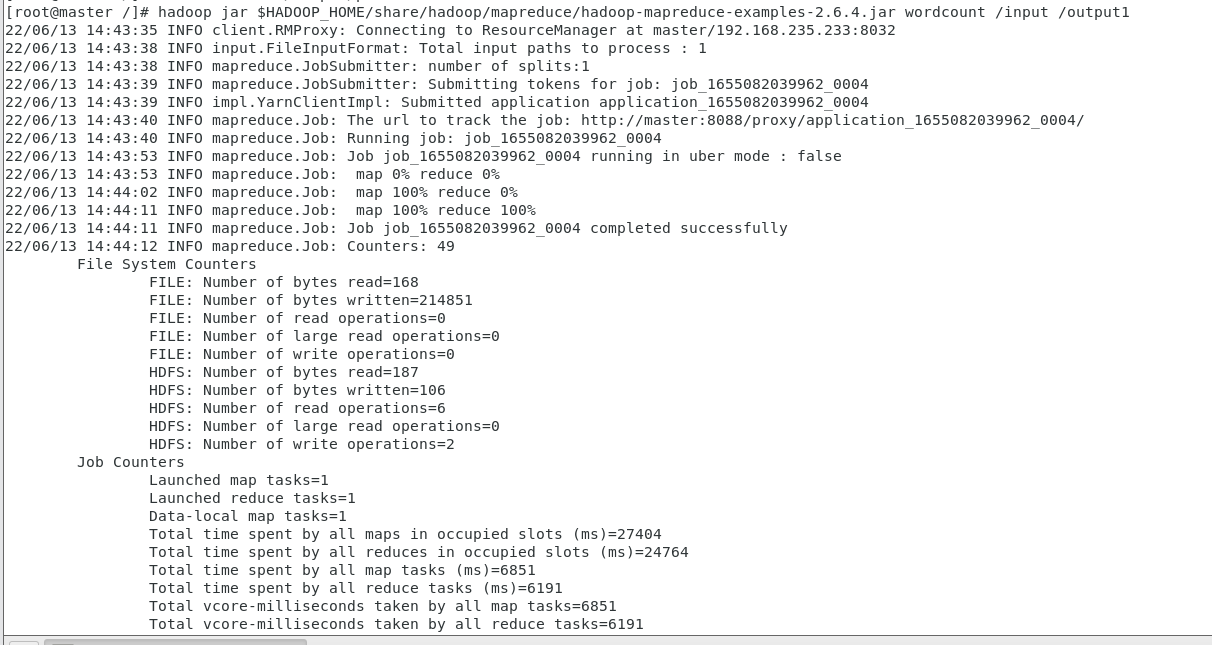
8.如果想要做另一个文本的词频统计,需要把后面的output改个名字,就是从新统计的意思
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar wordcount /input /output1

5.解析wordcount的代码 ,描述他是怎么工作的。并且上传到集群完成一次完整的Wordcount
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples; //包
import java.io.IOException; //数据的输入与输出
import java.util.StringTokenizer; //对String字符处理
import org.apache.hadoop.conf.Configuration; //基础conf
import org.apache.hadoop.fs.Path; //文件系统
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text; //数据输入输出(IO)
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer; //MapReduce(对数据的拆分,对数据的归类)
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper /*泛型类*/
<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1); //写整型的时候,初值为1
private Text word = new Text(); //文本对象word
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
/*字符串分隔,把单词拆出来
Hello Hadoop Hello world
hello 1 hadoop 1 hello 1 world 1
(用空格替换逗号跟句号)或者重写Tokenizer,把逗号句号替换添加进去
*/
while (itr.hasMoreTokens()) { //做一个循环判断,是否还有Token(分隔符)
word.set(itr.nextToken()); //如果有,就再读一个,从当前分隔符读到下一个分//隔符,实际就是读了一个单词
context.write(word, one); //输出这个单词
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result); //输出结果 hello 2 hadoop 1 world 1
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); //实例化conf(读取命令行的命令,以数组的方式返回路径)
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
} //判断IO的路径,如果只有一个路径,长度是小于2的,你的输出(1)包含两//个(输入和输出IO),防止出现读取的异常。
Job job = new Job(conf, "word count"); //所有的工作都是用Job来完成的,实例化Job
job.setJarByClass(WordCount.class); //打jar包
job.setMapperClass(TokenizerMapper.class); //指定Map类型
job.setCombinerClass(IntSumReducer.class); //指定Combiner
job.setReducerClass(IntSumReducer.class); //指定Reduce的类型
job.setOutputKeyClass(Text.class); //设置最终key的类型
job.setOutputValueClass(IntWritable.class); //设置最终value的类型
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} //任务提交
}

/***
* ,%%%%%%%%,
* ,%%/\%%%%/\%%
* ,%%%\c "" J/%%%
* %. %%%%/ o o \%%%
* `%%. %%%% _ |%%%
* `%% `%%%%(__Y__)%%'
* // ;%%%%`\-/%%%'
* (( / `%%%%%%%'
* \\ .' |
* \\ / \ | |
* \\/ ) | |
* \ /_ | |__
* (___________))))))) 攻城湿
*/
版权归原作者 鸷鸟之不群 所有, 如有侵权,请联系我们删除。