
📢📢📢📣📣📣
作者:IT邦德
中国DBA联盟(ACDU)成员,10余年DBA工作经验,
Oracle、PostgreSQL ACE
CSDN博客专家及B站知名UP主,全网粉丝10万+
擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复,
安装迁移,性能优化、故障应急处理
文章目录
前言
本文详细的阐述了PostgreSQL分区表的细节,分享给大家
1.何为分区表
分而治之是分区表最大的特点,将表数据分成更小的物理分片,减少搜索范围,以此可以查询提高性能。分区表是关系型数据库中比较常见的对大表的优化方式,数据库管理系统一般都提供了分区管理,而业务可以直接访问分区表而不需要调整业务架构,当然好的性能需要合理的分区访问方式。
2.分区表的特点
分区的具体好处是:改善查询性能、增强可用性、维护方便、均衡I/O
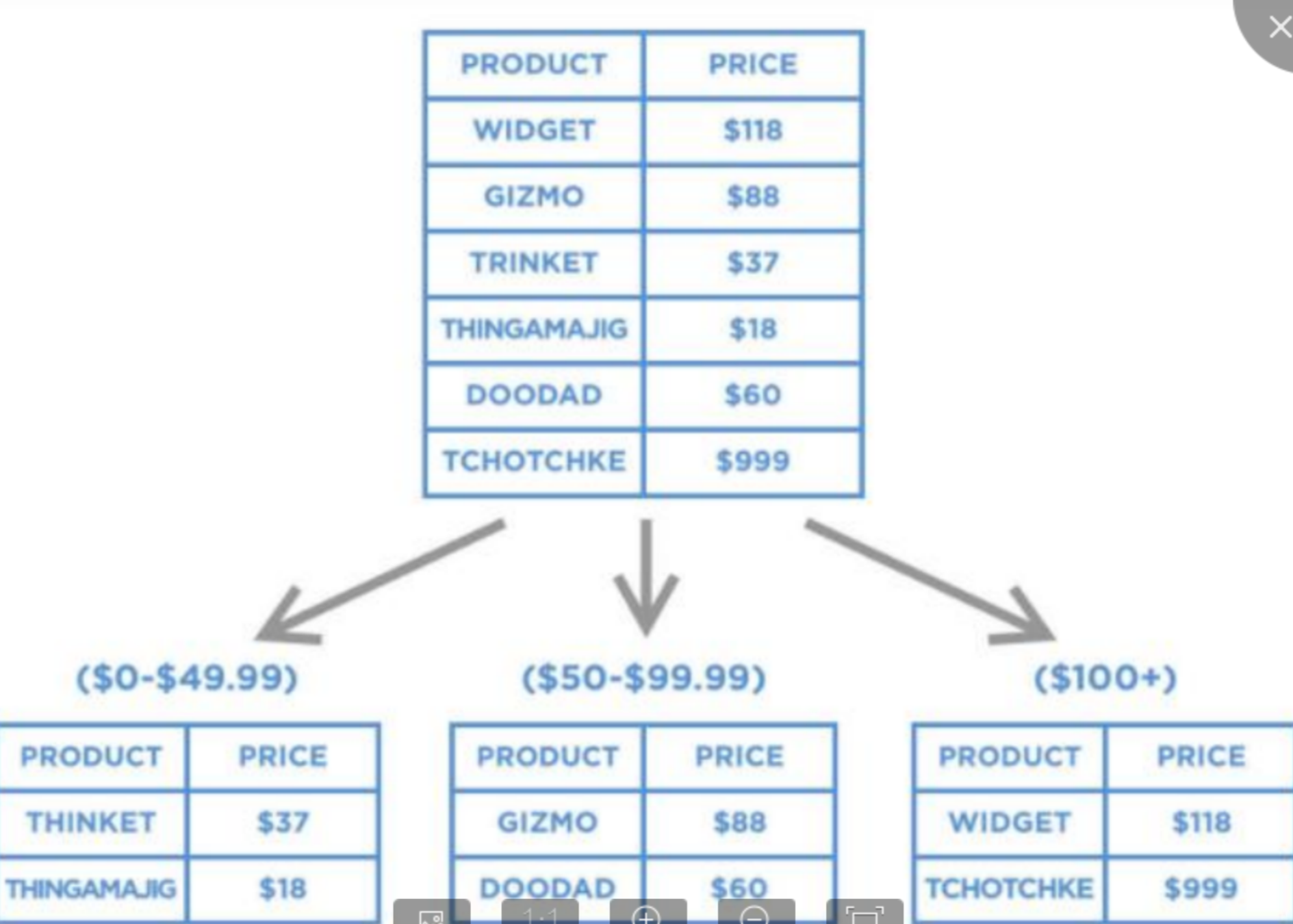
3.声明分区表分类
声明分区也叫原生分区,从PG10版本开始支持,相当于“官方支持”的分区表,也是最为推荐的分区方式。
声明分区只支持4种分区方式:range分区、list分区、hash分区、混合分区表
3.1 range分区
range分区表以范围进行分区,分区边界为[t1,t2)
--创建主表
CREATE TABLE PUBLIC.RANPARTITION1
(
id int,
name varchar(50) NULL,
DATE_CREATED timestamp NOT NULL DEFAULT now()
) PARTITION BY RANGE(DATE_CREATED);
alter table public.RANPARTITION1 add primary key(id,DATE_CREATED)
--创建分区表
create table RANPARTITION1_202401 partition of RANPARTITION1 for values from ('2024-01-01 00:00:00') to ('2024-02-01 00:00:00');
create table RANPARTITION1_202402 partition of RANPARTITION1 for values from ('2024-02-01 00:00:00') to ('2024-03-01 00:00:00');
--往分区表添加一些数据
INSERT INTO RANPARTITION1
SELECT random() * 10000, md5(g::text),g
FROM generate_series('2024-01-01'::date, '2024-02-28'::date, '1 minute') as g;
range分区的from t1 to t2,为[t1,t2)范围,下边界包含上边界不包含。
查看分区表,每个分区也是单独的表
postgres=# \d+ RANPARTITION1
postgres=# \d+ RANPARTITION1_202401
分区上的主键、索引、字段null/CHECK约束自动创建。
由于分区也是独立的表,约束和索引也可以单独在分区上创建。
3.2. list分区
list分区以指定的分区值将数据存放到对应的分区上
--创建主表
CREATE TABLE part_list (
city_id int not null,
name varchar(30),
population int
) PARTITION BY LIST (name);
Create index part_list_idx on part_list (name);
--创建分区表
CREATE TABLE p1_list PARTITION OF part_list FOR VALUES IN ('fujian', 'zhejiang');
CREATE TABLE p2_list PARTITION OF part_list FOR VALUES IN ('shandong', 'jiangxi');
-插入数据
insert into part_list (city_id,name,population) values(1,'fujian',10);
insert into part_list (city_id,name,population) values(2,'zhejiang',20);
insert into part_list (city_id,name,population) values(3,'shandong',10);
insert into part_list (city_id,name,population) values(4,'jiangxi',20);
--查看数据
SELECT tableoid::regclass,* FROM part_list;
list分区表可以创建null分区
3.3 hash分区
hash分区将数据散列存储在各个分区上,以打散热点数据存放到对应的分区上,然后把满足条件的行存放在该分区中,最常见的是平均的把数据放在不同的分区
--创建主表
CREATE TABLE part_hash
(order_id int,
name varchar(10))
PARTITION BY HASH (order_id);
Create index part_hash_idx on part_hash (order_id);
--创建分区表
CREATE TABLE p1_hash PARTITION OF part_hash FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE p2_hash PARTITION OF part_hash FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE p3_hash PARTITION OF part_hash FOR VALUES WITH (MODULUS 3, REMAINDER 2);
每个Hash分区需指定"模"(modulus)和"余"(remainder),
数据在哪个分区(partition index)的计算公式:
partition index = abs(hashfunc(key)) % modulus
--插入数据
insert into part_hash values(generate_series(1,10000),'a');
--查询数据
SELECT tableoid::regclass,count(*) FROM part_hash group by tableoid::regclass;
--查看执行计划
explain select * from part_hash where order_id=1000;
3.4 混合分区
分区下面也可以建立分区构成级联模式,子分区可以有不同的分区方式,这样的分区成为混合分区。

--创建一个混合分区:
create table part_1000(id bigserial not null,name varchar(10),createddate timestamp) partition by range(createddate);
create table part_2401 partition of part_1000 for values from ('2024-01-01 00:00:00') to ('2024-02-01 00:00:00') partition by list(name) ;
create table part_2402 partition of part_1000 for values from ('2024-02-01 00:00:00') to ('2024-03-01 00:00:00') partition by list(name) ;
create table part_2403 partition of part_1000 for values from ('2024-03-01 00:00:00') to ('2024-04-01 00:00:00') partition by list(name) ;
create table part_3001 partition of part_2401 FOR VALUES IN ('abc');
create table part_3002 partition of part_2401 FOR VALUES IN ('def');
create table part_3003 partition of part_2401 FOR VALUES IN ('jkl');
\d+只能看到下一级的分区
\d+ part_1000
\d+ part_2001
--此时插入一条数据
insert into part_1000 values(random() * 10000,'abc','2024-01-01 08:00:00');
声明分区特性小结
• 分区表的分区本身也是表,这个特性比较特殊。这不仅仅造成pg可以灵活的操作子分区,更重要的是功能和特性上的影响。
• truncate,vacuum,analyze分区表会执行所有分区。truncate only不能在父表上执行,但可以在存数据的子表上执行,仅清除这个子分区。
• range,hash分区的分区键可以有多个列,list分区的分区键只能是单个列或表达式。
• 分区父表本身是空的,最底层子分区可以存储数据
• default分区表会接收不在声明的范围中的数据;如果没有default分区,插入范围外的数据会直接报错
• 如果要新增分区,需要注意default分区中是否有这个新增分区的数据
• partition of创建的分区会自动创建分区表上的索引、约束、行级触发器
• attach不会处理任何索引、约束等等对象
4.继承分区表
继承分区也是官方支持的,它利用了PGSQL的继承表特性来实现分区表的功能。继承分区表会比声明分区表更灵活。 继承分区表的实现需要到了PGSQL中的2个功能:继承表和写入重定向。写入重定向可以通过rule或者trigger来实现。
1.创建父表
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
);
2.创建继承表,指定约束范围
CREATE TABLE measurement_202409 (
CHECK ( logdate >= DATE '2024-09-01' AND logdate < DATE '2024-10-01' )
) INHERITS (measurement);
CREATE TABLE measurement_202410 (
CHECK ( logdate >= DATE '2024-10-01' AND logdate < DATE '2024-11-01' )
) INHERITS (measurement);
3.创建规则或触发器,将插入数据重定向到对应的继承表中
CREATE OR REPLACE FUNCTION measurement_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF ( NEW.logdate >= DATE '2024-09-01' AND
NEW.logdate < DATE '2024-10-01' ) THEN
INSERT INTO measurement_202409 VALUES (NEW.*);
ELSIF ( NEW.logdate >= DATE '2024-10-01' AND
NEW.logdate < DATE '2024-11-01' ) THEN
INSERT INTO measurement_202410 VALUES (NEW.*);
ELSE
RAISE EXCEPTION 'Date out of range. Fix the measurement_insert_trigger() function!';
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
CREATE TRIGGER insert_measurement_trigger
BEFORE INSERT ON measurement
FOR EACH ROW EXECUTE FUNCTION measurement_insert_trigger();
--插入范围外的数据会报错
=> insert into measurement values(1001, now() - interval '80' day ,1,1);
--插入数据会重定向到子表上
=> insert into measurement values(1001,now(),1,1);
除了触发器,PGSQL还可以用rule来重定向插入。 rule语句参考
CREATE RULE measurement_insert_202409 AS
ON INSERT TO measurement WHERE
( logdate >= DATE '2024-09-01' AND logdate < DATE '2024-10-01' )
DO INSTEAD
INSERT INTO measurement_202410 VALUES (NEW.*);
CREATE RULE measurement_insert_202410 AS
ON INSERT TO measurement WHERE
( logdate >= DATE '2024-10-01' AND logdate < DATE '2024-11-01' )
DO INSTEAD
INSERT INTO measurement_202410 VALUES (NEW.*);
规则和触发器的差异:
• rule性能相较trigger更差,但在批量插入时,由于rule只有一次检查,性能会比trigger更好,但其他情况下trigger更好
• COPY不会触发rule,但会触发trigger。rule时可以将数据直接COPY到子表中
• 当插入范围外数据时,rule会将数据插入到父表中,trigger则会直接报错
4.分区的索引一般都是必不可少,继承表的索引需要手动在子表上创建
CREATE INDEX idx_measurement_202409_logdate ON measurement_202409 (logdate);
CREATE INDEX idx_measurement_202410_logdate ON measurement_202410 (logdate);
将一个继承分区做成普通表
ALTER TABLE measurement_202409 NO INHERIT measurement;
将一个含有数据的普通表当成子表加入到继承分区表中
CREATE TABLE measurement_202411
(LIKE measurement INCLUDING DEFAULTS INCLUDING CONSTRAINTS);
ALTER TABLE measurement_202411 ADD CONSTRAINT measurement_202411_logdate_check
CHECK ( logdate >= DATE '2024-11-01' AND logdate < DATE '2024-12-01' );
--insert into measurement_202411 values(2001,'20241110',3,3);
ALTER TABLE measurement_202411 INHERIT measurement;
继承分区表特性小结
• 继承分区要比声明分区更灵活,但一些声明分区的特性也无法使用
• 子表会继承父表上的约束,所以如果不是全局约束不要在父表上设置
• 索引不会继承,索引只能在子表上一个个地创建
• 声明分区只能有range、list、hash分区,继承分区可以更多,也可以是自定义的分区方式。
• 删除一个子表不会导致触发器失效。PGSQL没有像ORACLE那样失效对象的概念(索引有失效的概念)
• 一般来说使用trigger的插入重定向比rule效率更好
• 新增分区时,如果触发器函数中没有该分区的规则,则需要更新触发器函数。
• 继承分区可以多重继承
• 约束排除不能在执行时进行排除,所以建议使用固定值进行查询
• 使用继承分区表时,同样不要创建太多的子分区
版权归原作者 IT邦德 所有, 如有侵权,请联系我们删除。