

图像标注的任务让我们可以构建和训练一个为任何给定图像生成字幕的神经网络。在设计时使用了解码器的来完成文字的生成。当我们描述了每个解码器的工作原理时,我发现当它们被可视化时,更容易理解它们。
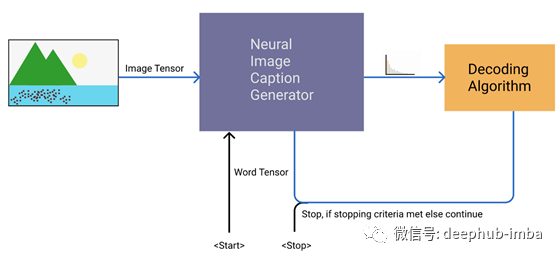
图像标注任务流程图
与翻译模型类似,我们的图像字幕模型通过输入图像张量和特殊的句首标记(即<start>)来启动字幕生成过程。这个模型生成了我们单词的概率分布(实际上是logits)。橙色方框显示解码算法的选择,帮助我们选择使用哪个单词。然后,选择的单词和图像再次传递给模型,直到我们满足停止条件,即我们获得特殊的句子结束标记(即<STOP>)作为下一个单词,或者我们超过了预先定义的步骤数。一个步骤是将图像和单词的张量传递给字幕生成器模型,并使用解码算法选择单词。
在这篇文章中,我们关注的是橙色的盒子。帮助我们从整个词汇表的概率分布中选择单词的解码算法。
GREEDY DECODER(贪心解码器)
这是最直接的方法,我们选择的词有最高的可能性(贪婪的行动)。虽然它可以生成单词序列,但与其他解码算法相比,输出的质量往往较低。
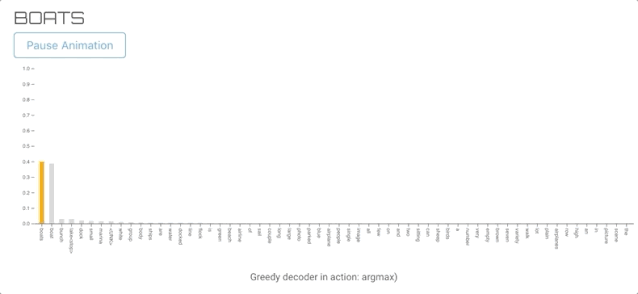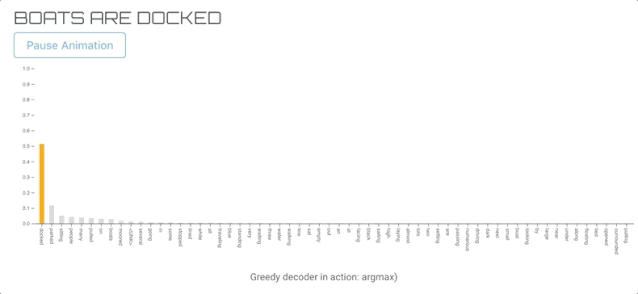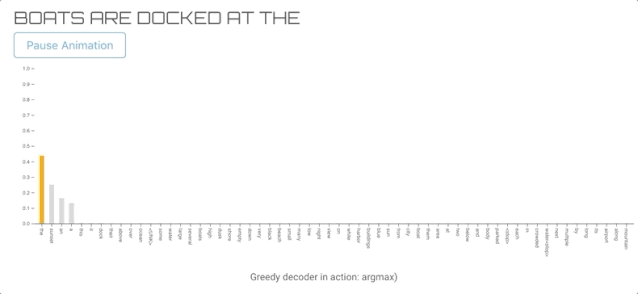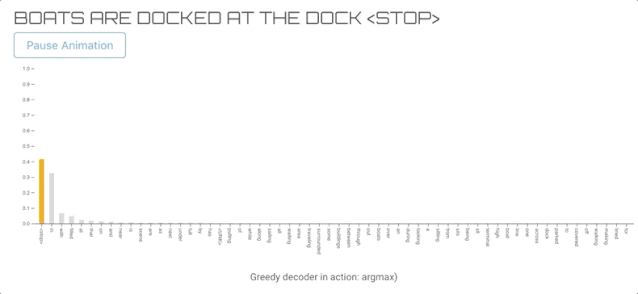
所以我们选择了前60个单词来可视化。另外,它导致标签在每个时间步上切换。
BEAM SEARCH(定向搜索解码器)
在贪婪解码器中,我们在每一步都考虑一个字。如果我们可以在每一步跟踪多个单词并使用它们来生成多个假设会怎样呢?
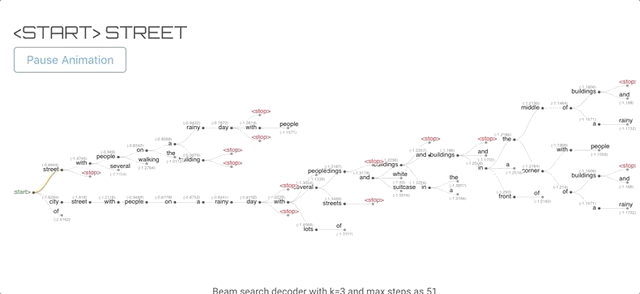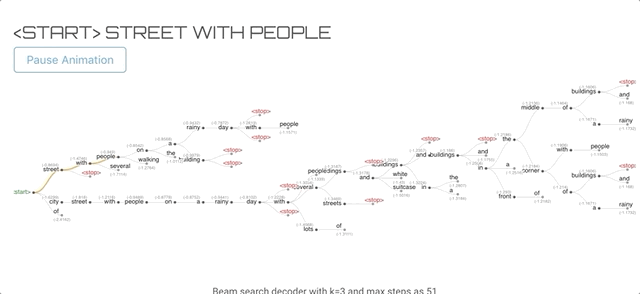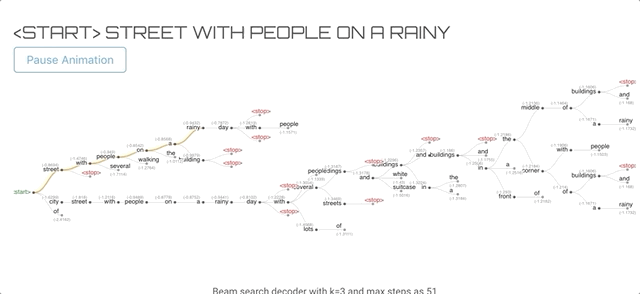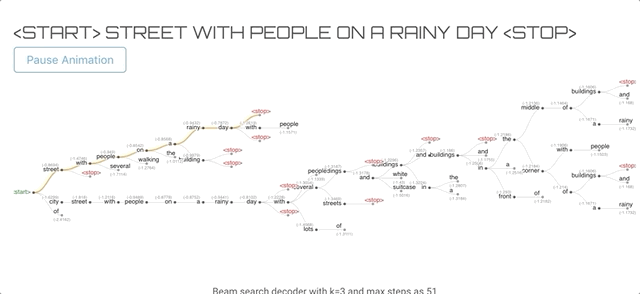
这正是定向搜索算法所做的,我们定义了每一步需要保留多少个单词(k)。该算法跟踪k个单词及其得分,每个单词都是从之前得分最高的k个单词中获得种子。分数是由到目前为止生成的假设的概率的和计算出来的。
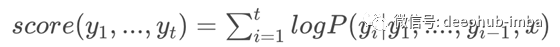
其中t为步长,x为输入图像,y为生成的单词。停止条件与贪心搜索相同,贪心搜索假设在遇到<stop>或超出预先定义的最大步数时停止。</stop>最终的结果是一个单词树多个假设),然后选择得分最高的一个作为最终的解。
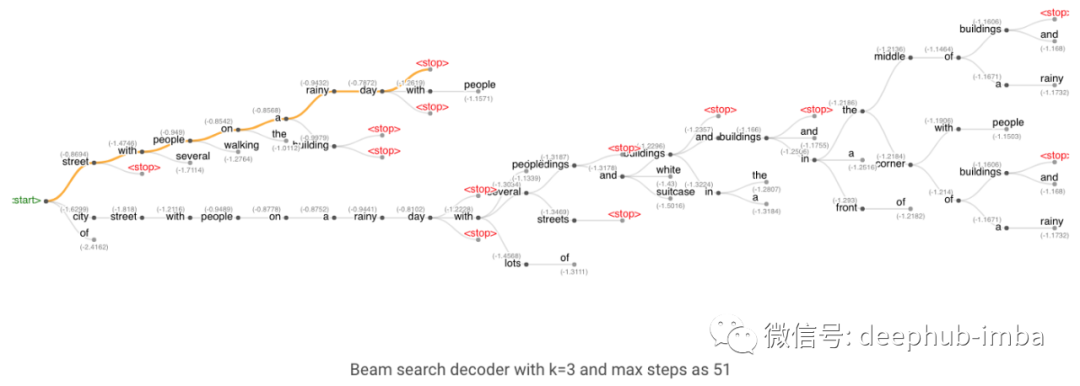
单词树结构,橙色表示最终的解
当我们使用k=1时,它的工作方式和贪婪解码器算法一样,同样会产生低质量的输出。当我们增加k时,算法开始产生更好的质量的输出,尽管在更大的k时,输出变得非常短。另外,注意增加k是计算密集型的,因为我们需要在每一步跟踪k个单词。
例如一下图片

使用训练好的模型后生成文字的过程
开始和停止单词以绿色和红色突出显示,灰色文本显示该步骤或时间点的序列得分。
PURE SAMPLING DECODER(纯采样解码器)
纯采样译码器与贪婪搜索译码器非常相似,但不是从概率最高的单词中抽取,而是从整个词汇表的概率分布中随机抽取单词。纯抽样和Top-K抽样(下面)等抽样方法提供了更好的多样性,通常被认为更能生成自然语言。

上图的文字描述生成过程
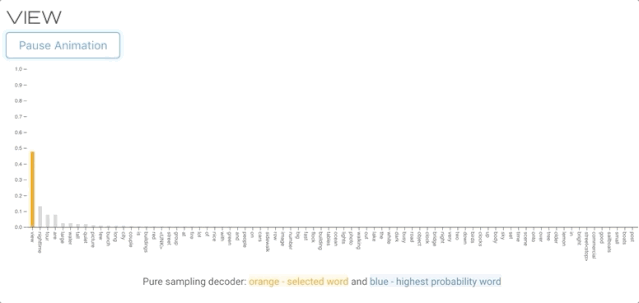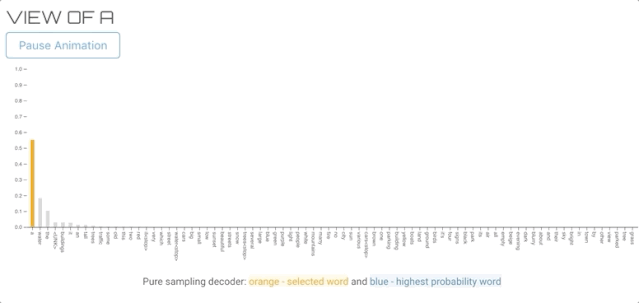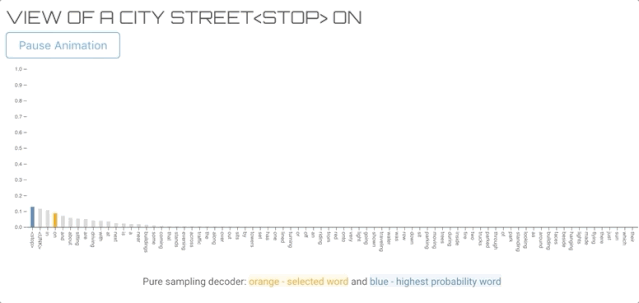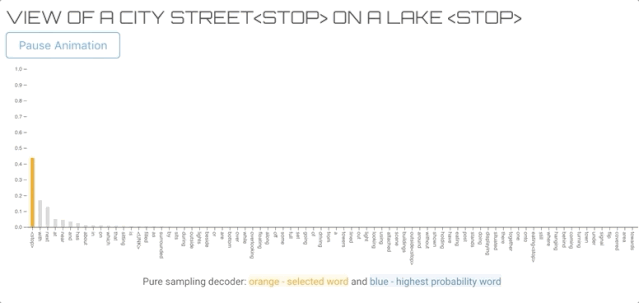
您可能已经注意到解码器没有在“street<stop>”处停止,这是因为我们的stop条件需要精确的“<stop>”令牌。</stop></stop>
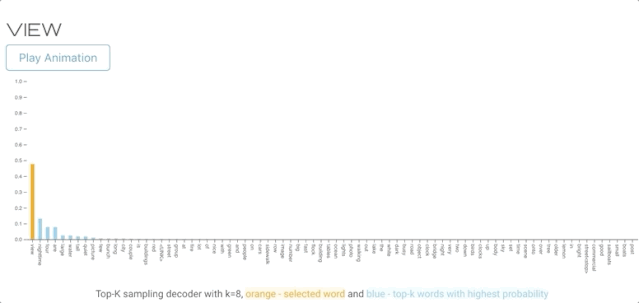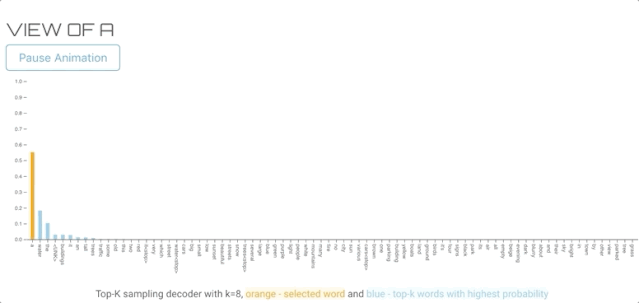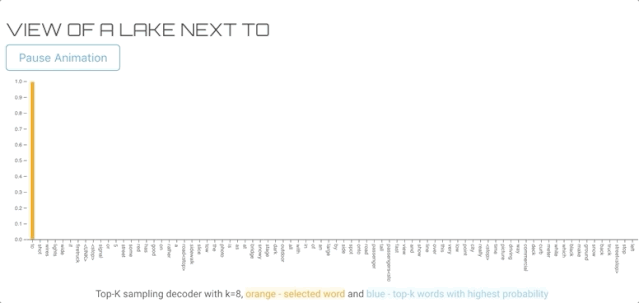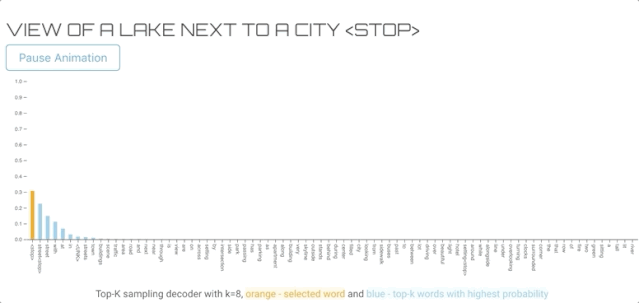
TOP-K SAMPLING DECODER(TOP-K抽样解码器)
该方法类似于纯采样译码器,但不是使用整个概率分布,而是只对top-k个可能单词进行采样。如果我们用k=1,它和贪婪搜索是一样的如果我们用词汇表的总长度作为k,那么它可以作为纯采样解码器。下面的可视化使用与纯采样示例相同的输入图像。
结论
这就是我在关于神经图像标题生成的文章中使用的各种解码算法的可视化。下面是最后一个示例,显示了四个解码器对同一输入图像的输出。
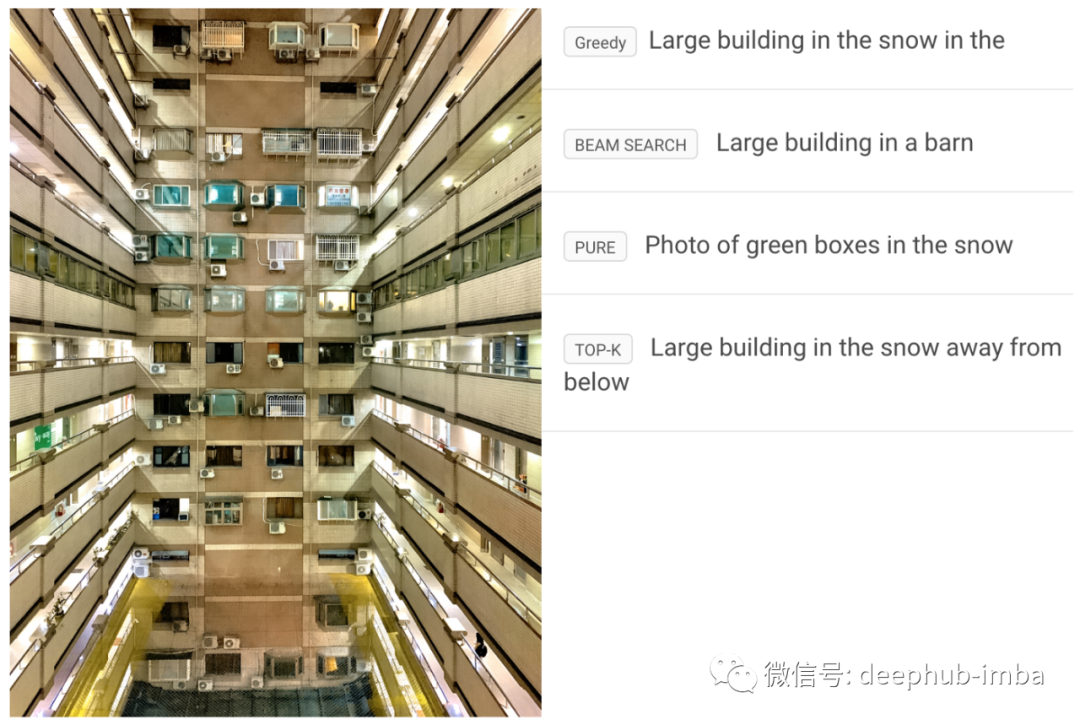
虽然这里生成的字幕的整体质量不如基于注意力的模式好,但我们可以看到不同的解码器对于结果的影响。
作者:Katnoria
原文地址:https://www.katnoria.com/nlg-decoders/
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********