
一、Kafka事务性消息
1.1 介绍Kafka事务性消息
Kafka事务性消息是一项关键的功能,为确保数据一致性提供了重要的支持。在本部分,我们将深入了解Kafka事务性消息的基本概念。
Kafka事务性消息的概念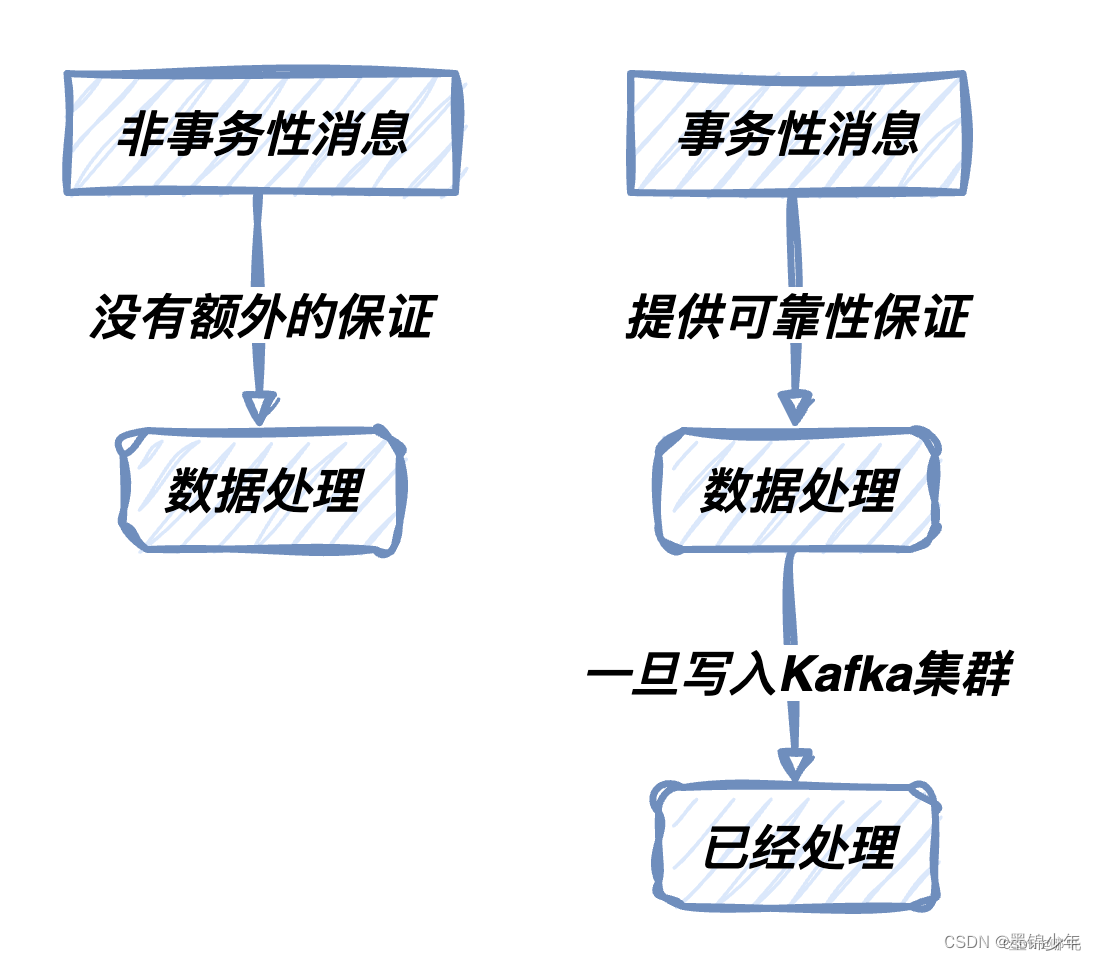
Kafka事务性消息是一种机制,用于确保消息的可靠性传递和处理。与非事务性消息相比,它们在数据处理中提供了额外的保证。一旦消息被写入Kafka集群,它们将被认为是已经处理,无论发生了什么。
事务性消息的特性
Kafka事务性消息具有以下关键特性:
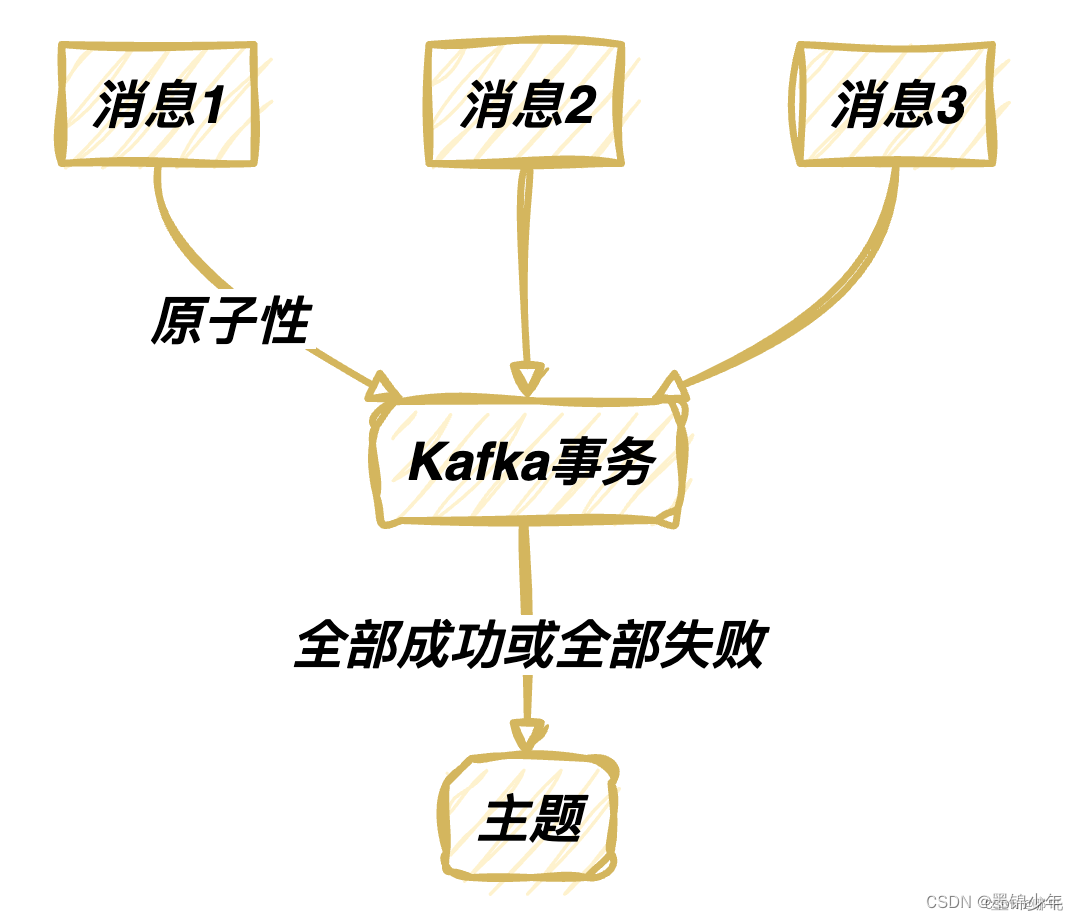
原子性:事务性消息要么完全成功,要么完全失败。这确保了消息不会被部分处理。
可靠性:一旦消息被写入Kafka,它们将被视为已经处理,即使发生了应用程序或系统故障
顺序性:事务性消息在单个分区内保持顺序。这对于需要按顺序处理的应用程序至关重要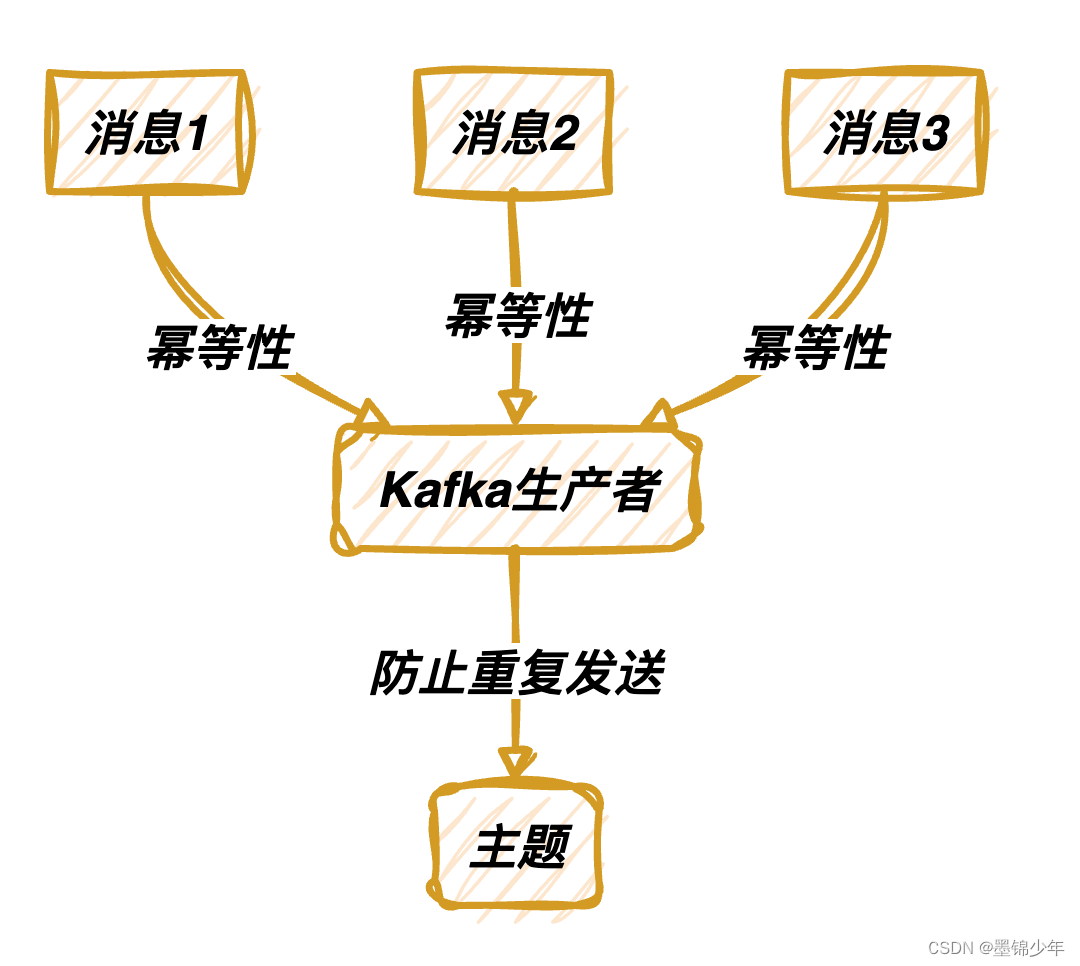
幂等性:Kafka生产者可以配置为幂等,确保相同的消息不会被重复发送。
Exactly Once语义:事务性消息支持"仅一次"语义,即消息要么完全到达一次,要么不到达。
1.2 事务性消息的应用场景
事务性消息在多种应用场景中发挥着关键作用。以下是一些常见的应用场景,其中事务性消息特别有用:
金融交易处理:在金融领域,每笔交易都必须具备原子性,确保不发生不一致或重复的交易。事务性消息可用于记录和处理金融交易,保证交易的完整性。
订单处理:在电子商务平台上,订单处理必须是可靠的,以确保订单的创建、支付和发货不会出现问题。事务性消息可用于跟踪和处理订单的不同阶段,从而确保订单流程的一致性。
库存管理:对于企业,库存管理是至关重要的。事务性消息可用于跟踪库存的变化,以确保库存的准确性和可靠性。
日志记录:在大数据和日志记录应用中,日志的完整性是至关重要的。事务性消息可用于确保日志的完整性,即使在日志处理集群发生故障时也能保持一致性。
系统通知:对于需要向用户发送通知或提醒的应用程序,确保通知的可靠发送至关重要。事务性消息可用于实现这一目标
1.3 Kafka事务性消息的优势
相对于非事务性消息,Kafka事务性消息具有明显的优势,特别是在需要数据一致性的应用场景中。以下是Kafka事务性消息的优势:
数据一致性:事务性消息可确保消息要么被完全处理,要么不被处理。这消除了数据处理中的不一致性,有助于维护数据一致性。
可靠性:一旦消息被写入Kafka,它们将被视为已经处理,即使发生了应用程序或系统故障。这确保了消息的可靠传递。
幂等性:Kafka生产者可以配置为幂等,这意味着相同的消息不会被重复发送。这有助于减少不必要的消息传递,避免数据重复。
Exactly Once语义:事务性消息支持"仅一次"语义,即消息要么完全到达一次,要么不到达。这是某些应用程序所需的高级语义。
错误处理:事务性消息提供了一种处理错误的机制,以确保消息可以被恢复或重试,而不会丢失。
二、Kafka事务性消息的使用
在这一部分,我们将深入研究如何使用Kafka事务性消息来确保数据的一致性。
2.1 配置Kafka以支持事务性消息
配置Kafka以支持事务性消息对于确保消息在传递和处理过程中的一致性非常重要。在本节中,我们将详细讨论如何配置Kafka以支持事务性消息,包括生产者和消费者的设置。
生产者配置
在生产者端,需要进行一些特定的配置以启用事务性消息。以下是一些关键的配置参数:
acks:这是有关生产者接收到确认之后才认为消息发送成功的设置。对于事务性消息,通常将其设置为acks=all,以确保消息仅在事务完全提交后才被视为成功发送。
transactional.id:这是用于标识生产者实例的唯一ID。在配置文件中设置transactional.id是启用事务性消息的关键步骤。
enable.idempotence:幂等性是指相同的消息不会被重复发送。对于事务性消息,通常将其设置为enable.idempotence=true,以确保消息不会重复发送。
acks=all
transactional.id=my-transactional-id
enable.idempotence=true
消费者配置
在消费者端,同样需要进行适当的配置以确保正确处理事务性消息。以下是一些消费者的重要配置参数:
isolation.level:这是用于控制消费者的隔离级别的设置。对于事务性消息,通常将其设置为isolation.level=read_committed,以确保只读取已经提交的事务消息。
auto.offset.reset:这是消费者启动时从哪里开始读取消息的设置。通常将其设置为auto.offset.reset=earliest,以确保不会错过任何已提交的消息。
配置Kafka以支持事务性消息是确保消息可靠传递和处理的关键步骤。这些配置设置可以确保在生产和消费事务性消息时的正确行为。
2.2 生产者:发送事务性消息
在这一部分,我们将深入研究如何使用Kafka生产者来发送事务性消息。发送事务性消息是确保数据一致性的关键步骤,需要特别小心。以下是详细的步骤和示例:
创建Kafka生产者
首先,我们需要创建一个 Kafka 生产者的实例。这个生产者实例将负责将消息发送到 Kafka 主题。创建生产者需要配置参数,包括 Kafka 集群的地址、消息的键和值的序列化器、事务ID 等。
下面是一个创建 Kafka 生产者的示例:
2.2 生产者:发送事务性消息
在这一部分,我们将深入研究如何使用Kafka生产者来发送事务性消息。发送事务性消息是确保数据一致性的关键步骤,需要特别小心。以下是详细的步骤和示例:
创建Kafka生产者
首先,我们需要创建一个 Kafka 生产者的实例。这个生产者实例将负责将消息发送到 Kafka 主题。创建生产者需要配置参数,包括 Kafka 集群的地址、消息的键和值的序列化器、事务ID 等。
下面是一个创建 Kafka 生产者的示例:
```java
importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.Producer;importorg.apache.kafka.clients.producer.ProducerConfig;importjava.util.Properties;publicclassMyKafkaProducer{publicstaticProducer<String,String>createProducer(){Properties properties =newProperties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"my-transactional-id");returnnewKafkaProducer<>(properties);}}
开始事务
在准备发送事务性消息之前,我们需要明确地开始一个事务。这通过调用 beginTransaction 方法来实现。一旦事务开始,所有后续的消息发送将包含在这个事务中。
producer.beginTransaction();
发送消息
在事务内,我们可以开始发送消息。这些消息将被包含在事务中,只有在事务成功提交时才会真正写入 Kafka 主题。
producer.send(new ProducerRecord<>(“my-topic”, “key1”, “value1”));
producer.send(new ProducerRecord<>(“my-topic”, “key2”, “value2”));
提交或中止事务
事务性消息的一个关键特性是它们要么完全成功,要么完全失败。因此,在消息发送后,我们需要根据消息的处理结果来决定是提交事务还是中止事务。这可以通过调用 commitTransaction 或 abortTransaction 方法来实现。
try {
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// 处理异常,通常中止事务并重试
producer.close();
} catch (CommitFailedException e) {
// 事务提交失败,通常中止事务并重试
producer.close();
}
2.3 消费者:处理事务性消息
在这一部分,我们将深入研究如何使用 Kafka 消费者来处理事务性消息。正确处理事务性消息对于保证数据一致性至关重要。以下是详细的步骤和示例:
创建 Kafka 消费者
首先,我们需要创建一个 Kafka 消费者的实例。这个消费者实例将负责从 Kafka 主题中读取消息。创建消费者需要配置参数,包括 Kafka 集群的地址、消息的键和值的反序列化器、消费者组 ID 等。
importorg.apache.kafka.clients.consumer.Consumer;importorg.apache.kafka.clients.consumer.ConsumerConfig;importorg.apache.kafka.clients.consumer.ConsumerRecords;importorg.apache.kafka.clients.consumer.KafkaConsumer;importjava.time.Duration;importjava.util.Collections;importjava.util.Properties;publicclassMyKafkaConsumer{publicstaticConsumer<String,String>createConsumer(){Properties properties =newProperties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"my-consumer-group");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");returnnewKafkaConsumer<>(properties);}}
订阅主题
消费者需要明确地订阅包含事务性消息的主题。这通过调用 subscribe 方法来实现。一旦订阅,消费者将开始接收该主题上的消息。
consumer.subscribe(Collections.singletonList(“my-topic”));
处理消息
一旦事务性消息到达,消费者需要确保消息被正确处理。这通常涉及到处理消息的逻辑,确保数据的一致性。处理消息的逻辑将根据具体的应用和需求而异。
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
String key = record.key();
String value = record.value();
// 处理消息的逻辑
}
提交位移
消费者需要负责提交消息的位移,以便正确跟踪已处理的消息。这通过调用 commitSync 或 commitAsync 方法来实现。位移的提交确保了消息不会被重复处理。
consumer.commitSync();
1
上述步骤提供了一个基本的示例,演示了如何使用 Kafka 消费者处理事务性消息。消费者的正确配置和消息处理确保了消息的可靠性和一致性。在实际应用中,处理消息的逻辑将更加复杂,以满足特定的需求
版权归原作者 墨锦少年 所有, 如有侵权,请联系我们删除。