
Zookeeper--简介
概述:
它是一款非常好用的 大数据分布式协调服务组件, 主要是用来帮助我们管理大数据进群的, 例如: 主备切换, 选举机制, 全局数据一致性...
吉祥物是: 1个拿着铁锹的小人.
本质:
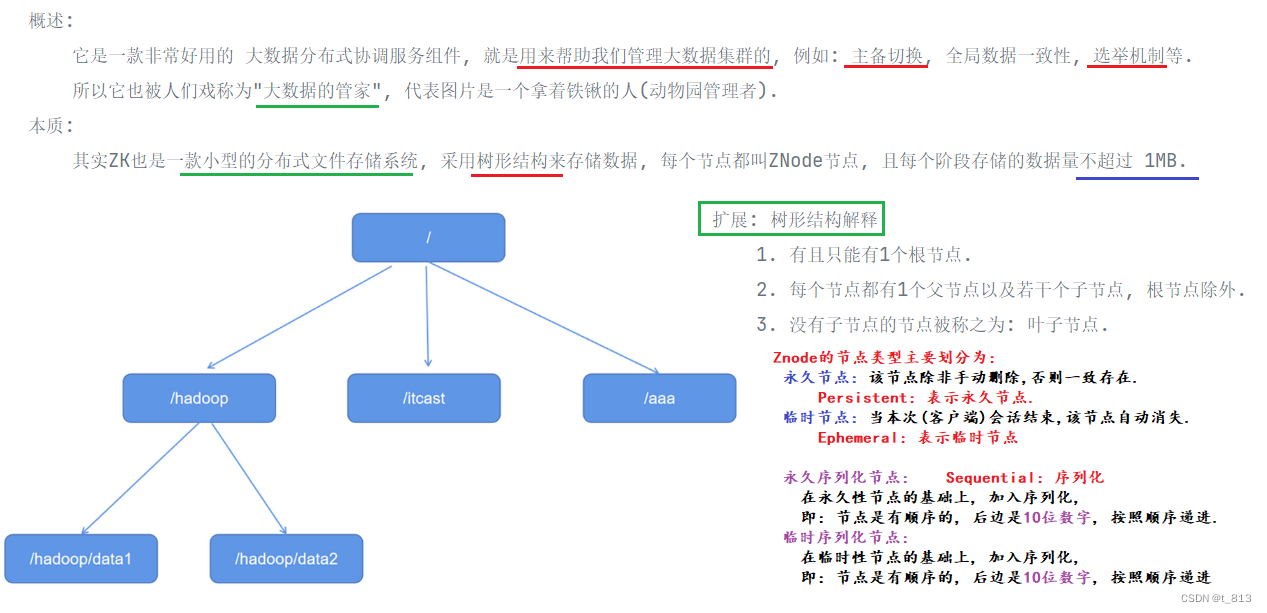
ZK本身也是1个小型的分布式文件存储系统, 采用ZNode节点的方式来存储数据, 底层是: 树形结构. 每个节点的大小不能超过: 1MB.
回顾: 树形结构特点:
1. 有且只能有1个根节点.
2. 每个节点都有若干个子节点及1个父节点(根节点除外)
3. 没有子节点的节点称之为: 叶子节点.
Znode节点的分类:
永久(无序)节点: Persistent
客户端的会话结束, 节点依旧存在.
临时(无序)节点: Ephemeral
客户端的会话结束, 节点小时(会被自动删除).
永久有序节点:
Persistent + Sequential
客户端的会话结束, 节点依旧存在, 会在节点名后边加10位数字, 升序递增. 0000000000, 0000000001...
临时有序节点:
Ephemeral + Sequential
客户端的会话结束, 节点消失, 会在节点名后边加10位数字, 升序递增. 0000000000, 0000000001...
细节:
临时节点不能有子节点.
Zookeeper--环境准备及架构介绍
环境准备
环境准备:
1. 三台虚拟机都需要安装: Zookeeper环境, 这个不用做了, 我给你装好了.
2. 三台虚拟机都要配置path环境变量, 这个我没做, 需要你手动做.
echo 'export ZOOKEEPER_HOME=/export/server/zookeeper' >> /etc/profile
echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile
source /etc/profile
3. 分别在三台虚拟机中启动, 并查看 Zookeeper节点信息即可.
zkServer.sh start | status | stop -- 启动, 查看状态, 关闭
zkCli.sh -- 打开ZK的客户端.
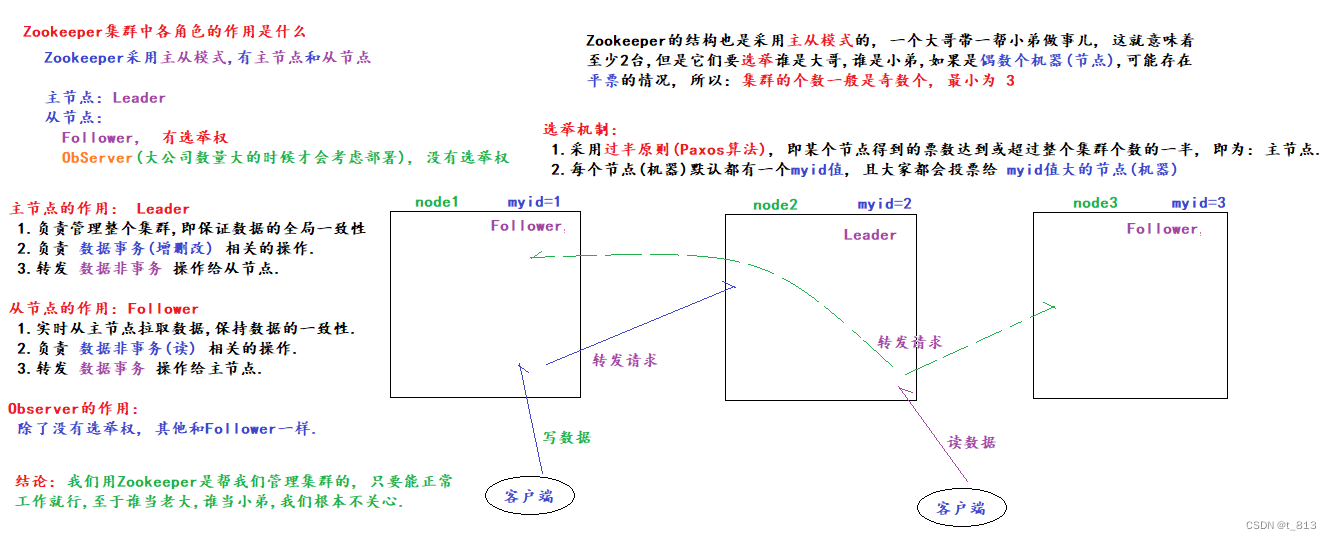
Zookeeper架构图
ZK的架构介绍:
Leader: 主节点
1. 管理整个ZK集群, 负责: 全局数据一致性.
2. 负责处理 数据事务操作(增, 删, 改)
3. 负责转发 数据非事务操作(查) 给 Follower
Follower:
1. 实时和Leader同步, 保证: 全局数据一致性.
2. 负责处理 数据非事务操作(查)
3. 负责转发 数据事务操作(增, 删, 改) 给 Leader
4. 有选举权.
ObServer:
除了没有选举权, 剩下的和 Follower一样. 大公司, 大规模集群, 才会考虑部署ObServer.
Zookeeper--Shell操作
连接客户端的方式:
zkCli.sh 连接本地(本机)
zkCli.sh -server node2 连接node2机器
常用Shell命令:
help -- 查看ZK支持的所有Shell命令
create [-s] [-e] path data -- Sequential(有序), Ephemeral(临时), 创建节点.
delete path [version] -- 删除节点, 只能删除(叶子节点)
rmr path -- 删除节点及其字节
set path data [version] -- 修改节点的内容
get path [watch] -- 查看节点内容
ls path [watch] -- 查看节点简单信息
ls2 path [watch] -- 查看节点详细信息
history -- 查看历史命令
redo 历史命令编号 -- 根据编号, 重新执行对应的 命令.
ZK的可视化工具
即: ZooInspector.zip, 解压即可直接用. 建议和你的其他软件放到一起.
Zookeeper--数据模型
- Znode兼具有文件 和 目录的功能, 既能存储数据, 也能有子级.
- Znode操作具有原子性, 无论在哪台机器修改了节点值, 其它机器再查也是修改后的.
- Znode存储数据有大小限制, 每个节点不超过1MB.
细节: 我们用ZK不是用它存数据的功能, 而是管理大数据集群.- Znode节点必须通过 绝对路径的写法才可以获取, 即: /aa
Zookeeper--特点
- 全局数据一致性. 你访问哪台机器, 看到的数据都是一样的.
- 可靠性.
- 顺序性. 全局有序, 偏序.
- 数据更新原子性.
- 实时性.
Zookeeper--watch监听机制
- 先注册, 后监听.
- 当事件触发后, 会将触发结果告知 监听者.
- 异步发送监听结果的.
- 监听是一次性触发, 之后在触发响应的内容, 也不会给 监听者发送消息了.
问题: watch监听机制, 有什么用?
答案: 它(watch监听机制) 结合临时节点一起用, 可以实现: 主备切换.
Zookeeper--选举机制
原则:
过半原则, 某个机器获取的票数超过集群总数的一半, 它就是Leader, 剩下的是Follower.
选举机制的方式:
新集群: 参考myid值, 优先投票给myid值大的机器.
旧集群: 参考(节点)最后一次更新的事务id, 优先投票给事务id大的节点(机器), 如果事务id一致, 则参考 myid值, 投票给myid值大的机器.
版权归原作者 t_813 所有, 如有侵权,请联系我们删除。