
一、概述:
一个Flink程序由多个任务(Source、Transformation和Sink)组成。一个任务由多个并行实例(线程)来执行,一个任务的并行实例(线程)数目被称为该任务的并行度。
二、TaskManager和Slot
Flink是一个分布式流处理框架,它基于TaskManager和Slot来实现任务的执行。TaskManager是Flink中负责运行任务的工作进程,而Slot是TaskManager中可用的资源。

TaskManager在Flink集群中分布式运行,每个TaskManager可以运行多个Slot。Slot是TaskManager中的资源分配单位,每个Slot可以运行一个Flink任务。TaskManager会根据需要动态分配Slot,以满足任务执行的需求。
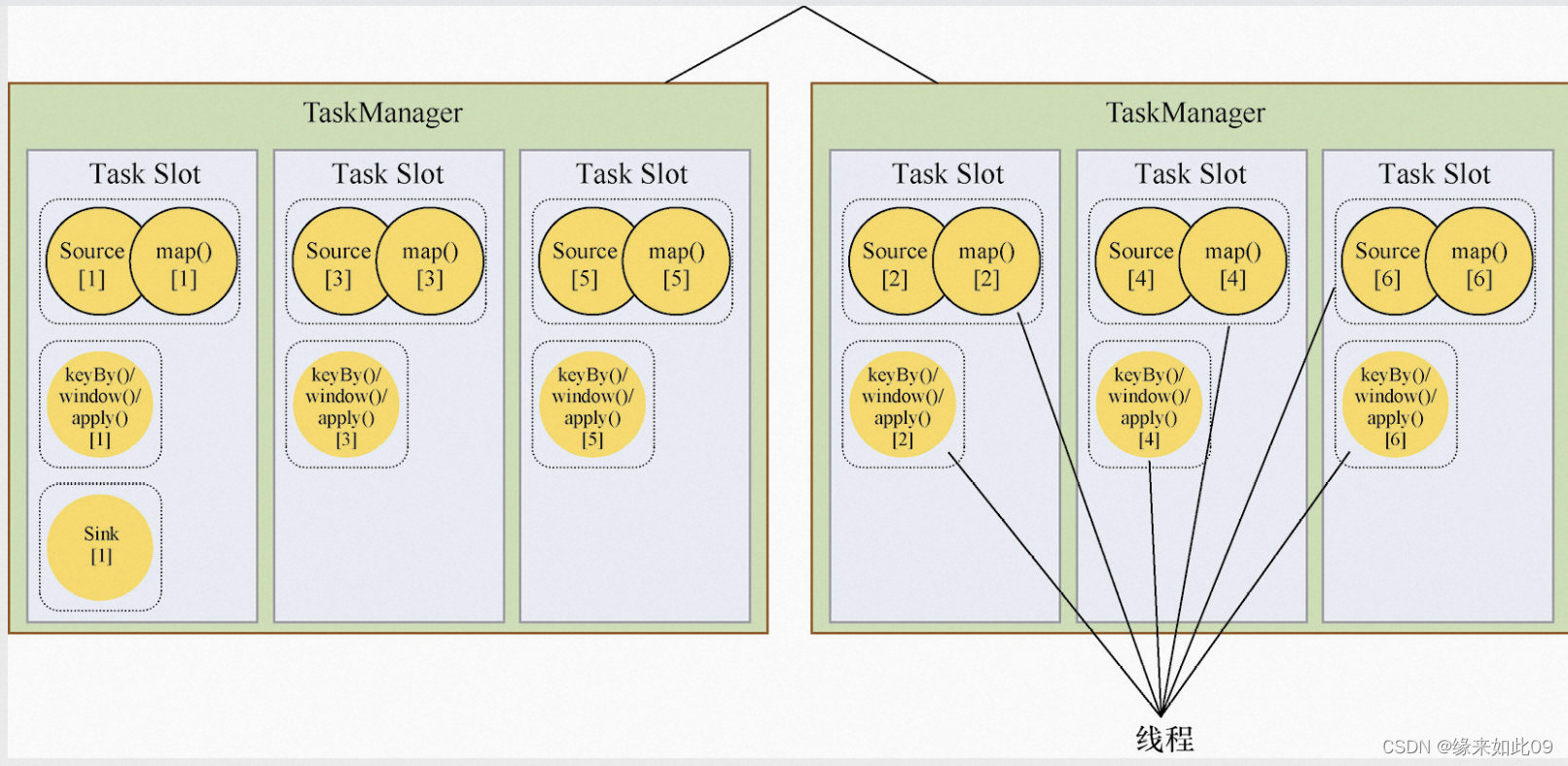
在Flink中,任务是按照任务图来执行的。任务图是一个有向无环图,其中每个节点代表一个任务,边表示任务之间的依赖关系。当一个任务需要运行时,Flink会检查当前所有TaskManager中的空闲Slot,并将任务分配到其中一个空闲的Slot中运行。如果没有足够的空闲Slot,Flink会向集群中添加新的TaskManager,以提供更多的资源。
在任务执行期间,TaskManager会将任务状态存储在内存中,并定期将状态写入磁盘以防止数据丢失。如果一个TaskManager出现故障,Flink会自动将该TaskManager上的任务重新分配到其他TaskManager上继续执行,以确保任务的高可用性。
总之,TaskManager和Slot是Flink中关键的资源管理器,它们可以动态分配和管理任务执行所需的资源,以提高Flink任务的性能和可靠性。
三、并行度的设置:
一个任务的并行度设置可以从4个层面指定。
(1)Operator Level(算子层面)
(2)Execution Environment Level(执行环境层面)
(3)Client Level(客户端层面)
(4)System Level(系统层面)
这些并行度的优先级为Operator Level>Execution Environment Level>ClientLevel>System Level
四、如何设置合适的并行度
- 数据源的并行度:数据源的并行度应该等于或大于最终算子的并行度,以充分利用系统资源。
- 算子逻辑的复杂度:算子逻辑越复杂,相应的并行度就需要更高才能提供足够的吞吐量。因此,在确定算子并行度时,应该考虑算子逻辑的复杂度。
- 系统资源的可用性:在确定算子并行度时,应该考虑系统可用的资源。例如,如果系统的CPU和内存资源有限,那么高并行度可能会导致任务竞争和低性能。
- 数据倾斜:数据倾斜是指数据分布不均衡,这可能会导致某些算子的并行度成为瓶颈。在这种情况下,可以通过调整算子的并行度来解决数据倾斜问题。
- 实验调整:最终的并行度设置可能需要通过实验来进行调整。可以通过监视和调整算子的并行度来观察和优化作业性能。
五、并行度设置不合理会导致哪些问题:
1.反压:Flink中某些算子的并行度设置过小可能会导致反压的情况。反压是指某个算子的输出速度超过了下游算子的处理速度,导致下游算子的任务堆积和延迟。这可能会导致整个作业的性能下降和任务失败。
2.过高的并行度设置可能会导致资源浪费。如果某个算子的并行度设置过高,该算子可能会占用过多的系统资源,从而影响整个作业的性能。此外,过高的并行度设置还可能会导致任务之间的竞争,从而影响系统的稳定性。
3.过高或过低的并行度设置还可能会导致数据倾斜。如果某个算子的并行度设置过高或过低,可能会导致数据倾斜,从而影响整个作业的性能。过高的并行度设置可能会导致某些子任务负载过重,从而导致数据倾斜。过低的并行度设置可能会导致某些子任务负载过轻,从而导致数据倾斜。
版权归原作者 缘来如此09 所有, 如有侵权,请联系我们删除。